Center for Hearing Loss Help
Help for your hearing loss, tinnitus and other ear conditions
FREE Subscription to: Hearing Loss Help
Your email address will never be rented, traded or sold!

Help, I’ve Memorized the Word List!—Understanding Hearing Loss Speech Testing
Question : Whenever I have my hearing tested, it seems the audiologist uses the same list of words each time. I can understand this for people who have never been tested before, but when I get my hearing tested regularly, isn’t this sort of ridiculous? I mean, I’ve half-memorized the word list so I’m not getting fair test results, am I?—D. P.
Answer : I understand your concerns, but your questions reflect a fundamental misunderstanding of the whole audiometric testing process. When you go to your audiologist for a complete audiological evaluation, your audiologist performs a whole battery of tests. The speech audiometry portion of your audiological evaluation consists of not just one, but two “word” tests—the Speech Reception Threshold (SRT) test and the Speech Discrimination (SD) or Word Recognition (WR) test. The SRT and the SD/WR tests are entirely different tests—each with totally different objectives. Unfortunately, many people somehow “smoosh” these two tests together in their minds, hence the confusion and concern expressed in your questions. Let me explain.
Speech Reception Threshold (SRT) Testing
The purpose of the Speech Reception Threshold (SRT) test, sometimes called the speech-recognition threshold test, is to determine the softest level at which you just begin to recognize speech. That’s it. It has nothing to do with speech discrimination.
Audiologists determine your Speech Reception Threshold by asking you to repeat a list of easy-to-distinguish, familiar spondee words. (Spondee words are two-syllable words that have equal stress on each syllable. You’ll notice that when you repeat a spondee, you speak each syllable at the same volume and take the same length of time saying each syllable.) Here are examples of some of the spondee words used in SRT testing: baseball, cowboy, railroad, hotdog, ice cream, airplane, outside and cupcake.
When you take the SRT test, your audiologist will tell you, “Say the word ‘baseball.’ Say the word ‘cowboy.’ Say the word ‘hotdog.'” etc. As she does this, she varies the volume to find the softest sound level in decibels at which you can just hear and correctly repeat 50% of these words. This level is your SRT score expressed in decibels (dB). You will have a separate SRT test for each ear. 1
If your SRT is 5 dB (normal), you can understand speech perfectly at 21 feet and still catch some words at over 100 feet. If you have a mild hearing loss—or example a SRT of 30 dB—you could only hear perfectly at 1 foot but could still hear some words at 18 feet. If your SRT is 60 dB (a moderately severe hearing loss), you would need the speaker to be only 1 inch from your ear in order to hear perfectly and within 1 foot to still hear some of the words correctly. 2
Now, to address your concerns about memorizing the words in the word lists. For the record, you should be familiar with all the spondee words in the list before testing commences because this familiarization results in an SRT that is 4 to 5 dB better than that obtained if you didn’t know them. 3
Bet you didn’t know this, but there are actually two standardized spondee word lists—not just one. Each list consists of 18 words. These words are “phonetically dissimilar and homogeneous in terms of intelligibility.” 3 That is just a fancy-pants way of saying that all these words sound different, yet are equally easy to understand. Spondees are an excellent choice for determining your Speech Reception Threshold because they are so easy to understand at faint hearing levels. 3
Let me emphasize again, you are supposed to know these words. They are not supposed to be a secret. However, this doesn’t mean that because you know a number of the words on this list, that you have memorized them. In fact, it would be difficult since there are two different SRT word lists, and your audiologist may go from top to bottom, or bottom to top, or in random order. Thus, although you are generally familiar with these words, and can even recite a number of them from memory, you still don’t know the exact order you’ll be hearing them so you cannot cheat. Thus, you can set your mind at rest. Your SRT scores are still perfectly valid even though the words “railroad,” “cowboy” and “hotdog” are almost certainly going to be in one of those lists.
Why is knowing your Speech Reception Threshold important? In addition to determining the softest level at which you can hear and repeat words, your SRT is also used to confirm the results of your pure-tone threshold test. For example, there is a high correlation between your SRT results and the average of your pure-tone thresholds at 500, 1000, and 2000 Hz. In fact, your SRT and 3-frequency average should be within 6 dB of each other. 4 Furthermore, your Speech Reception Threshold determines the appropriate gain needed when selecting the right hearing aid for your hearing loss. 4
Discrimination Testing
The purpose of Speech Discrimination (SD) testing (also called Word Recognition (WR) testing) is to determine how well you hear and understand speech when the volume is set at your Most Comfortable Level (MCL).
To do this, your audiologist says a series of 50 single-syllable phonetically-balanced (PB) words. (Phonetically-balanced just means that the percent of time any given sound appears on the list is equal to its occurrence in the English language. 5 For this test, your audiologist will say, “Say the word ‘come.’ Say the word ‘high.’ Say the word ‘chew.’ Say the word ‘knees,'” and so on. You repeat back what you think you hear.
During this test, your audiologist keeps her voice (or a recording on tape or CD) at the same loudness throughout. Each correct response is worth 2%. She records the percentage of the words you correctly repeat for each ear.
For the best results, the Speech Discrimination word list is typically read at 40 decibels above your SRT level (although it may range from 25-50 dB above your SRT level, depending on how you perceive sound). 4
Your Speech Discrimination score is an important indicator of how much difficulty you will have communicating and how well you may do if you wear a hearing aid. If your speech discrimination is poor, speech will sound garbled to you.
For example, a Speech Discrimination score of 100% indicates that you heard and repeated every word correctly. If your score was 0%, it means that you cannot understand speech no matter how loud it is 1 —speech will be just so much gibberish to you. Scores over 90% are excellent and are considered to be normal. Scores below 90% indicate a problem with word recognition. 3 If your score is under 50%, your word discrimination is poor. This indicates that you will have significant trouble following a conversation, even when it is loud enough for you to hear. 2 Thus, hearing aids will only be of very limited benefit in helping you understand speech. If your speech discrimination falls below 40%, you may be eligible for a cochlear implant.
Incidentally, people with conductive hearing losses frequently show excellent speech discrimination scores when the volume is set at their most comfortable level. On the other hand, people with sensorineural hearing losses typically have poorer discrimination scores. People with problems in the auditory parts of their brains tend to have even poorer speech discrimination scores, even though they may have normal auditory pure-tone thresholds. 3
Unlike the SRT word lists (railroad, cowboy, hotdog, etc.), where everyone seems to remember some of the words, I have never come across a person who has memorized any of the words in the speech discrimination lists. In fact, as the initial questions indicated, people mistakenly think the SRT words are used for speech discrimination. This is just not true. In truth, the SD words are so unprepossessing and “plain Jane” that few can even remember one of them! They just don’t stick in your mind!
For example, one Speech Discrimination list includes words such as: “are,” “bar,” “clove,” “dike,” “fraud,” “hive,” “nook,” “pants,” “rat,” “slip,” “there,” “use,” “wheat” and 37 others. How many of you remember any of these words?
One person asked, “Why aren’t there several different word lists to use?” Then our audiologists would find out if we really heard them.”
Surprise! This is what they already do. There are not just one, but many phonetically-balanced word lists already in existence. In case you are interested, the Harvard Psycho-Acoustic Laboratory developed the original PB word lists. There are 20 of these lists, collectively referred to as the PB-50 lists. These 20 PB-50 lists each contain 50 single-syllable words comprising a total of 1,000 different monosyllabic words . Several years later, the Central Institute for the Deaf (CID) developed four 50-word W-22 word lists, using 120 of the same words used in the PB-50 lists and adding 80 other common words. Furthermore, Northwestern University developed yet four more word lists 6 (devised from a grouping of 200 consonant-nucleus-consonant (CNC] words). These lists are called the Northwestern University Test No. 6 (NU-6). 4
As you now understand, your audiologist has a pool of over 1,000 words in 28 different lists from which to choose, thus making memorizing them most difficult. (In actual practice, audiologists use the W-22 and NU-6 lists much more commonly than the original PB-50 lists.) In addition to choosing any one of the many speech discrimination word lists available to her, your audiologist may go from top to bottom, or bottom to top so you still don’t know what word is coming next. Thus you can rest assured that your word discrimination test is valid. Your memory has not influenced any of the results.
In addition to determining how well you recognize speech, Speech Discrimination testing has another use. Your audiologist uses it to verify that your hearing aids are really helping you. She does this by testing you first without your hearing aids on to set the baseline Speech Discrimination score. Then she tests you with your hearing aids on. If your hearing aids are really helping you understand speech better, your Speech Discrimination scores should be significantly higher than without them on. If the scores are lower, your audiologist needs to “tweak” them or try different hearing aids.
To Guess or Not To Guess, That is the Question
One person asked, “Do audiologists want us to guess at the word if we are not sure what the word is? Wouldn’t it be better to say what we really hear instead of trying to guess what the word is?”
Good question. Your audiologist wants you to just repeat what you hear. If you hear what sounds like a proper word, say it. If it is gibberish and not any word you know, either repeat the gibberish sounds you heard, or just say that you don’t have a clue what the word is supposed to be. If you don’t say anything when you are not completely certain of the word, you are skewing the results because sometimes you will hear the word correctly, but by not repeating what you thought you heard, you are deliberately lowering your discrimination score.
Another person remarked, “I remember a while back; when I was taking the word test, there was a word that sounded like the 4 letter word that begins with an ‘F’. I knew it wasn’t that word, and I would not say ‘F***.'” In that case, if you are not comfortable repeating what you “heard,” just say it sounded like a “dirty” word and you don’t want to repeat it. You audiologist will know you got it wrong as there are no “dirty” words on the PB lists.
____________________
1 ASHA. 2005. http://www.asha.org/public/hearing/testing/assess.htm .
2 Olsson, Robert. 1996. Do You Have a Hearing Loss? In: How-To Guide For Families Coping With Hearing Loss. http://www.earinfo.com . p. 3.
3 Pachigolla, Ravi, MD & Jeffery T. Vrabec, MD. 2000. Assessment of Peripheral and Central Auditory Function. Dept. of Otolaryngology. UTMB. http://www.utmb.edu/otoref/Grnds/Auditory-assessment/200003/Auditory_Assess_200003.htm .
4 Smoski, Walter J. Ph.D. Associate Professor, Department of Speech Pathology and Audiology, Illinois State University. http://www.emedicine.com/ent/topic371.htm .
5 Audiologic Consultants. 2005. http://www.audiologicconsultants.com/hearing_evaluations.htm
6 Thompson, Sadi. 2002. Comparison of Word Familiarity: Conversational Words v. NU-6 list Words. Dept. Sp. Ed. & Comm. Dis. University of Nebraska-Lincoln. Lincoln, NE. http://www.audiologyonline.com/articles/arc_disp.asp?id=350 .
February 24, 2016 at 10:54 PM
Thanks for the explanation. It is really very helpful.
September 2, 2023 at 8:01 AM
Great article and very well written.
My question concerns the doubling of the SRT decibel. In my case, that meant the discrimination testing was at 80 decibels. I scored 80R/70L. But I was wondering how accurate this is, as I can’t think of anyone who actually speaks routinely at that volume!
September 2, 2023 at 8:52 AM
Discrimination (word recognition) testing is always done at your most comfortable listening level. If it were done at the level people speak, you wouldn’t hear much of anything. The idea is to see how well you can understand speech WHEN YOU CAN COMFORTABLY HEAR IT.
This tells the audiologist whether hearing aids will help you–when the sounds are amplified to your most comfortable level. In your case (and mine too) hearing aids will help you a lot (at least in quiet conditions). But, if you’re like me, you’ll still want to speechread to fill in words that you miss.
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Ototoxic Drugs Exposed
Learn More | Add to Cart—Printed | Add to Cart—eBook
Contacta HLD3 Hearing Loop System
Learn More | Add to Cart
Say Good Bye to Meniere’s Disease

Severe Meniere’s disease is not something you ever want to experience. In this book, not only will you learn what it’s like to have Meniere’s disease, but you will learn about the latest discovery of the underlying cause of Meniere’s disease and the simple treatment that let’s you wave good bye to your Meniere’s disease.
© Copyright Center for Hearing Loss Help 2024 · Help for your hearing loss, tinnitus and other ear conditions ™
Center for Hearing Loss Help, Neil G. Bauman, Ph.D. 1013 Ridgeway Drive, Lynden, WA 98264-1057 USA Email: neil@hearinglosshelp.com · Phone: 360-778-1266 (M-F 9:00 AM-5:00 PM PST) · FAX: 360-389-5226
"The wages of sin is death, but the gift of God is eternal life [which also includes perfect hearing] through Jesus Christ our Lord." [Romans 6:23]
"But know this, in the last days perilous times will come" [2 Timothy 3:1]. "For there will be famines, pestilences, and [severe] earthquakes in various places" [Matthew 24:7], "distress of nations, the sea and the waves roaring"—tsunamis, hurricanes—Luke 21:25, but this is good news if you have put your trust in the Lord Jesus Christ, for "when these things begin to happen, lift up your heads [and rejoice] because your redemption draws near" [Luke 21:28].
- Audiometers
- Hearing Aid Test Systems
- Newborn Hearing Screening
- TeleAudiology
- Occupational Health - Industrial
- Otoacoustic Emissions - OAE
- Sound Rooms - Suites
- System Software
- Tympanometry - Middle Ear Analyzers
- Vestibular - Balance
- Vision Screeners
- VRA - COR Systems
- Calibration Services
- Repair Services
- Preventative Maintenance Services
- Download Center
- National Conferences
- Pre-recorded Webinars

Am I Doing it Right? Word Recognition Test Edition
Word recognition testing evaluates a patient's ability to identify one-syllable words presented above their hearing threshold, providing a Word Recognition Score (WRS). Word recognition testing is a routine part of a comprehensive hearing assessment and in an ENT practice, the WRS can be an indication of a more serious problem that needs further testing. Unfortunately, the common way WRS is measured may give inaccurate results. Let's talk about why that is.
The Problems with Word Recognition Testing
One of the key variables to consider when performing word recognition testing is at what level to present the words. A common practice is setting the loudness of the words at 30 to 40 dB above the patient's Speech Reception Threshold (SRT), known as "SRT + 30 or +40 dB." Some also set the level to the patient's subjective "Most Comfortable Level" (MCL). Clinicians often use one of these methods, assuming it ensures optimal performance. However, some research suggests that utilizing this method may not capture the maximum performance (PBmax) for those with hearing loss. Consequently, this approach does not necessarily guarantee the most accurate WRS measurement. This fact prompts the question: Does this traditional method align with best practices and evidence-based approaches? Let's explore this further.
Audibility and Speech Audiometry
Audibility significantly impacts word recognition scores. Using only the SRT +30 dB or +40 dB method or MCL may not be the best strategy, as the audiogram configuration can affect whether words are presented at an effective level. Studies suggest that raising the presentation level could enhance WRS in some instances. Since the SRT +30 dB or 40 dB method or MCL does not offer the best results, let's explore two methods supported by current research.
Alternative Word Recognition Methods Explained
In a 2009 study, Guthrie and Mackersie compared various presentation levels to find the one that maximized word recognition in people with different hearing loss patterns. The Uncomfortable Loudness Level – 5 dB (UCL-5dB) method and the 2KHz Sensation Level method were found to have the highest average scores. Let's look at each of these methods separately.
Uncomfortable Loudness Level – 5dB (UCL-5dB)
The Uncomfortable Loudness Level (UCL) refers to the intensity level at which sounds become uncomfortably loud for an individual. In the UCL-5 dB method, the presentation level for word recognition testing is set to 5 decibels below the measured UCL. This method aims to find the test subject's most comfortable and effective presentation level. While UCL-5 may be louder than the patient prefers, setting the presentation level slightly below the uncomfortable loudness threshold ensures that the speech stimuli are audible without causing discomfort. Patients with mild to moderate and moderately severe hearing loss obtained their best WRS at this level.
2KHz Sensation Level (SL)
The 2KHz Sensation Level method for WRS testing involves determining the presentation level for speech stimuli based on the individual's hearing threshold at 2,000 Hertz (2KHz). Once determined, the words are presented at a variable Sensation Level (SL) relative to the patient's hearing threshold at 2KHz. In this case, SL is the difference between the hearing threshold at 2KHz and the loudness level of the words for the word recognition test. The 2KHz Sensation Level (SL) method is convenient for busy clinics as it avoids the need to measure the UCL. This method involves using variable SL values determined in the following way:
- 2KHz threshold <50dB HL: 25dB SL
- 2KHz threshold 50-55dB HL: 20dB SL
- 2KHz threshold 60-65dB HL: 15dB SL
- 2KHz threshold 70-75dB HL: 10dB SL
This method tailors the presentation level to the individual's specific frequency sensitivity. It allows for a more personalized and precise word recognition testing approach, considering the individual's hearing characteristics at a specific frequency of 2 kHz. Ensuring the accuracy of WRS test results is crucial by employing research-backed methods. Another important aspect of best practice is carefully selecting the word list and ensuring the appropriate number of words is used during the test. Let's delve deeper into exploring WRS test materials.
WRS Test Materials
Nu-6 and cid w-22.
These are two standardized word lists and the most used lists when performing the WR test. Each is comprised of 50 words; however, many hearing care professionals present only half of the list to save valuable clinical time. This approach may be invalid and unreliable. Why?
Research has shown that the words comprising the first half of these standardized lists are more difficult to understand than the second. Rintleman showed that the average difference between ears when presenting the first half to one ear and the second half to another was 16%. A solution lies in using re-ordered lists by difficulty, offering a screening approach. Hurley and Sells' 2003 study provides a valid alternative, potentially saving substantial testing time.
Auditec NU-6 Ordered by Difficulty
Hornsby and Mueller (2013) propose using the Hurley and Sells Auditec NU-6 Ordered by Difficulty list (Version II) via recorded word lists. The list comprises four sets of 50 words each. The examiner can conclude the test after the initial 10 or 25 words or complete all 50 words. Studies have shown that approximately 25% of patients require only a 10-word list. Instructions accompany the list.
Interpreting Word Recognition Test Results
Otolaryngologists often compare the WRS between ears to determine if additional testing is needed to rule out certain medical conditions. The American Academy of Otolaryngology recommends referring patients for further testing when the WRS between ears shows an asymmetry of 15% or greater. This asymmetry is not significant enough to warrant a referral for additional testing. What constitutes a significant difference? Thornton and Raffin (1978) developed a statistical model against which the WRS can be plotted to determine what is statistically significant based on "critical difference tables." Linda Thibodeau developed the SPRINT chart to aid in interpreting WR tests. It utilizes data from Thornton and Raffin and that obtained by Dubno et al. This chart helps evaluate the asymmetry and determine if a WRS is close to PBMax.
Word Recognition Testing Best Practice
Here are some dos and don'ts from an Audiology Online presentation by Muellar and Hornsby.
- Always use recorded materials, such as the shortened-interval Auditec recording of the NU-6.
- Choose a presentation level to maximize audibility without causing loudness discomfort, utilizing either UCL-5 or the 2KHz –SL method.
- Use the Thornton and Raffin data, incorporated into Thibodeau's SPRINT chart, to determine when a difference is significant.
- Use the Judy Dubno data in Thibodeau's SPRINT chart to determine when findings are "normal."
- Utilize the Ordered-by-Difficulty version of the Auditec NU-6 and employ the 10-word and 25-word screenings.
Word Recognition Testing Don'ts
- Avoid live-voice testing.
- Steer clear of using a presentation of SRT+30 or SRT+40.
- Avoid making random guesses regarding when two scores are different.
- Refrain from conducting one-half list per ear testing unless using the Ordered-by-Difficulty screening.
In conclusion, adopting modern methods and evidence-based practices can improve the accuracy, efficiency, and validity of word recognition testing. Staying informed and using best practices is crucial for mastering this critical aspect of hearing assessments and giving your patients the best possible care.
Other Good Reads: A Quick Guide to Speech Audiometry Using the GSI Pello Audiometer
Follow us on Social!
If you haven't already, make sure to subscribe to our newsletter to keep up-to-date with our latest resources and product information.
- Word Recognition Test Edition >
e3 Diagnostics represents
- Expertise: Personalized consultation
- Excellence: World-leading technology and service
- Everywhere: Relationships that go beyond a sale
Corporate Office
(800) 323-4371
info @e3diagnostics.com
MON - FRI: 8am-5pm CST
Find Local Office
Shop Online
Browse our audiology supplies web shop today and stock up on products from the industry’s best brands!
© 2013-2024 e3 Diagnostics. All Rights Reserved. [email protected] | Privacy Policy | Terms of Use | 3333 N Kennicott Ave., Arlington Heights, IL. 60004
- Audiometers
- Tympanometers
- Hearing Aid Fitting
- Research Systems
- Research Unit
- ACT Research
- Our History
- Distributors
- Sustainability
- Environmental Sustainability
Training in Speech Audiometry
- Why Perform Functional Hearing Tests?
- Performing aided speech testing to validate pediatric hearing devices
Speech Audiometry: An Introduction
Description, table of contents, what is speech audiometry, why perform speech audiometry.
- Contraindications and considerations
Audiometers that can perform speech audiometry
How to perform speech audiometry, results interpretation, calibration for speech audiometry.
Speech audiometry is an umbrella term used to describe a collection of audiometric tests using speech as the stimulus. You can perform speech audiometry by presenting speech to the subject in both quiet and in the presence of noise (e.g. speech babble or speech noise). The latter is speech-in-noise testing and is beyond the scope of this article.
Speech audiometry is a core test in the audiologist’s test battery because pure tone audiometry (the primary test of hearing sensitivity) is a limited predictor of a person’s ability to recognize speech. Improving an individual’s access to speech sounds is often the main motivation for fitting them with a hearing aid. Therefore, it is important to understand how a person with hearing loss recognizes or discriminates speech before fitting them with amplification, and speech audiometry provides a method of doing this.
A decrease in hearing sensitivity, as measured by pure tone audiometry, results in greater difficulty understanding speech. However, the literature also shows that two individuals of the same age with similar audiograms can have quite different speech recognition scores. Therefore, by performing speech audiometry, an audiologist can determine how well a person can access speech information.
Acquiring this information is key in the diagnostic process. For instance, it can assist in differentiating between different types of hearing loss. You can also use information from speech audiometry in the (re)habilitation process. For example, the results can guide you toward the appropriate amplification technology, such as directional microphones or remote microphone devices. Speech audiometry can also provide the audiologist with a prediction of how well a subject will hear with their new hearing aids. You can use this information to set realistic expectations and help with other aspects of the counseling process.
Below are some more examples of how you can use the results obtained from speech testing.
Identify need for further testing
Based on the results from speech recognition testing, it may be appropriate to perform further testing to get more information on the nature of the hearing loss. An example could be to perform a TEN test to detect a dead region or to perform the Audible Contrast Threshold (ACT™) test .
Inform amplification decisions
You can use the results from speech audiometry to determine whether binaural amplification is the most appropriate fitting approach or if you should consider alternatives such as CROS aids.
You can use the results obtained through speech audiometry to discuss and manage the amplification expectations of patients and their communication partners.
Unexpected asymmetric speech discrimination, significant roll-over , or particularly poor speech discrimination may warrant further investigation by a medical professional.
Non-organic hearing loss
You can use speech testing to cross-check the results from pure tone audiometry for suspected non‑organic hearing loss.
Contraindications and considerations when performing speech audiometry
Before speech audiometry, it is important that you perform pure tone audiometry and otoscopy. Results from these procedures can reveal contraindications to performing speech audiometry.
Otoscopic findings
Speech testing using headphones or inserts is generally contraindicated when the ear canal is occluded with:
- Foreign body
- Or infective otitis externa
In these situations, you can perform bone conduction speech testing or sound field testing.
Audiometric findings
Speech audiometry can be challenging to perform in subjects with severe-to-profound hearing losses as well as asymmetrical hearing losses where the level of stimulation and/or masking noise required is beyond the limits of the audiometer or the patient's uncomfortable loudness levels (ULLs).
Subject variables
Depending on the age or language ability of the subject, complex words may not be suitable. This is particularly true for young children and adults with learning disabilities or other complex presentations such as dementia and reduced cognitive function.
You should also perform speech audiometry in a language which is native to your patient. Speech recognition testing may not be suitable for patients with expressive speech difficulties. However, in these situations, speech detection testing should be possible.
Before we discuss speech audiometry in more detail, let’s briefly consider the instrumentation to deliver the speech stimuli. As speech audiometry plays a significant role in diagnostic audiometry, many audiometers include – or have the option to include – speech testing capabilities.
Table 1 outlines which audiometers from Interacoustics can perform speech audiometry.
| Clinical audiometer | |
| Diagnostic audiometer | |
| Diagnostic audiometer | |
| Equinox 2.0 | PC-based audiometer |
| Portable audiometer | |
| Hearing aid fitting system | |
| Hearing aid fitting system |
Table 1: Audiometers from Interacoustics that can perform speech audiometry.
Because speech audiometry uses speech as the stimulus and languages are different across the globe, the way in which speech audiometry is implemented varies depending on the country where the test is being performed. For the purposes of this article, we will start with addressing how to measure speech in quiet using the international organization of standards ISO 8252-3:2022 as the reference to describe the terminology and processes encompassing speech audiometry. We will describe two tests: speech detection testing and speech recognition testing.
Speech detection testing
In speech detection testing, you ask the subject to identify when they hear speech (not necessarily understand). It is the most basic form of speech testing because understanding is not required. However, it is not commonly performed. In this test, words are normally presented to the ear(s) through headphones (monaural or binaural testing) or through a loudspeaker (binaural testing).
Speech detection threshold (SDT)
Here, the tester will present speech at varying intensity levels and the patient identifies when they can detect speech. The goal is to identify the level at which the patient detects speech in 50% of the trials. This is the speech detection threshold. It is important not to confuse this with the speech discrimination threshold. The speech discrimination threshold looks at a person’s ability to recognize speech and we will explain it later in this article.
The speech detection threshold has been found to correlate well with the pure tone average, which is calculated from pure tone audiometry. Because of this, the main application of speech detection testing in the clinical setting is confirmation of the audiogram.
Speech recognition testing
In speech recognition testing, also known as speech discrimination testing, the subject must not only detect the speech, but also correctly recognize the word or words presented. This is the most popular form of speech testing and provides insights into how a person with hearing loss can discriminate speech in ideal conditions.
Across the globe, the methods of obtaining this information are different and this often leads to confusion about speech recognition testing. Despite there being differences in the way speech recognition testing is performed, there are some core calculations and test parameters which are used globally.
Speech recognition testing: Calculations
There are two main calculations in speech recognition testing.
1. Speech recognition threshold (SRT)
This is the level in dB HL at which the patient recognizes 50% of the test material correctly. This level will differ depending on the test material used. Some references describe the SRT as the speech discrimination threshold or SDT. This can be confusing because the acronym SDT belongs to the speech detection threshold. For this reason, we will not use the term discrimination but instead continue with the term speech recognition threshold.
2. Word recognition score (WRS)
In word recognition testing, you present a list of phonetically balanced words to the subject at a single intensity and ask them to repeat the words they hear. You score if the patient repeats these words correctly or incorrectly. This score, expressed as a percentage of correct words, is calculated by dividing the number of words correctly identified by the total number of words presented.
In some countries, multiple word recognition scores are recorded at various intensities and plotted on a graph. In other countries, a single word recognition score is performed using a level based on the SRT (usually presented 20 to 40 dB louder than the SRT).
Speech recognition testing: Parameters
Before completing a speech recognition test, there are several parameters to consider.
1. Test transducer
You can perform speech recognition testing using air conduction, bone conduction, and speakers in a sound-field setup.
2. Types of words
Speech recognition testing can be performed using a variety of different words or sentences. Some countries use monosyllabic words such as ‘boat’ or ‘cat’ whereas other countries prefer to use spondee words such as ‘baseball’ or ‘cowboy’. These words are then combined with other words to create a phonetically balanced list of words called a word list.
3. Number of words
The number of words in a word list can impact the score. If there are too few words in the list, then there is a risk that not enough data points are acquired to accurately calculate the word recognition score. However, too many words may lead to increased test times and patient fatigue. Word lists often consist of 10 to 25 words.
You can either score words as whole words or by the number of phonemes they contain.
An example of scoring can be illustrated by the word ‘boat’. When scoring using whole words, anything other than the word ‘boat’ would result in an incorrect score.
However, in phoneme scoring, the word ‘boat’ is broken down into its individual phonemes: /b/, /oa/, and /t/. Each phoneme is then scored as a point, meaning that the word boat has a maximum score of 3. An example could be that a patient mishears the word ‘boat’ and reports the word to be ‘float’. With phoneme scoring, 2 points would be awarded for this answer whereas in word scoring, the word float would be marked as incorrect.
5. Delivery of material
Modern audiometers have the functionality of storing word lists digitally onto the hardware of the device so that you can deliver a calibrated speech signal the same way each time you test a patient. This is different from the older methods of testing using live voice or a CD recording of the speech material. Using digitally stored and calibrated speech material in .wav files provides the most reliable and repeatable results as the delivery of the speech is not influenced by the tester.
6. Aided or unaided
You can perform speech recognition testing either aided or unaided. When performing aided measurements, the stimulus is usually played through a loudspeaker and the test is recorded binaurally.
Global examples of how speech recognition testing is performed and reported
Below are examples of how speech recognition testing is performed in the US and the UK. This will show how speech testing varies across the globe.
Speech recognition testing in the US: Speech tables
In the US, the SRT and WRS are usually performed as two separate tests using different word lists for each test. The results are displayed in tables called speech tables.
The SRT is the first speech test which is performed and typically uses spondee words (a word with two equally stressed syllables, such as ‘hotdog’) as the stimulus. During this test, you present spondee words to the patient at different intensities and a bracketing technique establishes the threshold at where the patient correctly identifies 50% of the words.
In the below video, we can see how an SRT is performed using spondee words.
Below, you can see a table showing the results from an SRT test (Figure 1). Here, we can see that the SRT has been measured in each ear. The table shows the intensity at which the SRT was found as well as the transducer, word list, and the level at which masking noise was presented (if applicable). Here we see an unaided SRT of 30 dB HL in both the left and right ears.

Once you have established the intensity of the SRT in dB HL, you can use it to calculate the intensity to present the next list of words to measure the WRS. In WRS testing, it is common to start at an intensity of between 20 dB and 40 dB louder than the speech recognition threshold and to use a different word list from the SRT. The word lists most commonly used in the US for WRS are the NU-6 and CID-W22 word lists.
In word recognition score testing, you present an entire word list to the test subject at a single intensity and score each word based on whether the subject can correctly repeat it or not. The results are reported as a percentage.
The video below demonstrates how to perform the word recognition score.
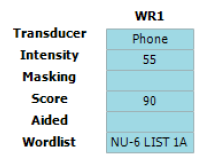
Below is an image of a speech table showing the word recognition score in the left ear using the NU‑6 word list at an intensity of 55 dB HL (Figure 2). Here we can see that the patient in this example scored 90%, indicating good speech recognition at moderate intensities.
Speech recognition testing in the UK: Speech audiogram
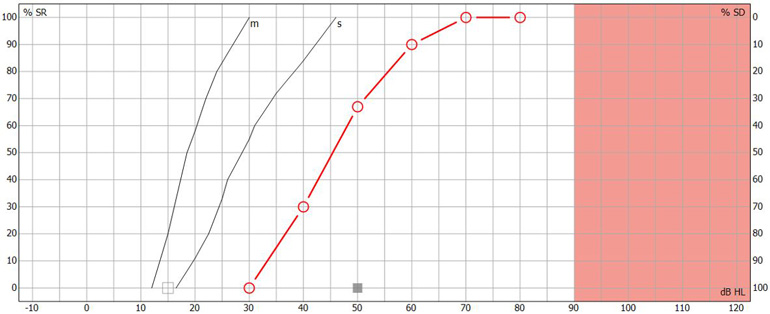
In the UK, speech recognition testing is performed with the goal of obtaining a speech audiogram. A speech audiogram is a graphical representation of how well an individual can discriminate speech across a variety of intensities (Figure 3).
In the UK, the most common method of recording a speech audiogram is to present several different word lists to the subject at varying intensities and calculate multiple word recognition scores. The AB (Arthur Boothroyd) word lists are the most used lists. The initial list is presented around 20 to 30 dB sensation level with subsequent lists performed at quieter intensities before finally increasing the sensation level to determine how well the patient can recognize words at louder intensities.
The speech audiogram is made up of plotting the WRS at each intensity on a graph displaying word recognition score in % as a function of intensity in dB HL. The following video explains how it is performed.
Below is an image of a completed speech audiogram (Figure 4). There are several components.
Point A on the graph shows the intensity in dB HL where the person identified 50% of the speech material correctly. This is the speech recognition threshold or SRT.
Point B on the graph shows the maximum speech recognition score which informs the clinician of the maximum score the subject obtained.
Point C on the graph shows the reference speech recognition curve; this is specific to the test material used (e.g., AB words) and method of presentation (e.g., headphones), and shows a curve which describes the median speech recognition scores at multiple intensities for a group of normal hearing individuals.

Having this displayed on a single graph can provide a quick and easy way to determine and analyze the ability of the person to hear speech and compare their results to a normative group. Lastly, you can use the speech audiogram to identify roll-over. Roll-over occurs when the speech recognition deteriorates at loud intensities and can be a sign of retro-cochlear hearing loss. We will discuss this further in the interpretation section.
Masking in speech recognition testing
Just like in audiometry, cross hearing can also occur in speech audiometry. Therefore, it is important to mask the non-test ear when testing monaurally. Masking is important because word recognition testing is usually performed at supra-threshold levels. Speech encompasses a wide spectrum of frequencies, so the use of narrowband noise as a masking stimulus is not appropriate, and you need to modify the masking noise for speech audiometry. In speech audiometry, speech noise is typically used to mask the non-test ear.
There are several approaches to calculating required masking noise level. An equation by Coles and Priede (1975) suggests one approach which applies to all types of hearing loss (sensorineural, conductive, and mixed):
- Masking level = D S plus max ABG NT minus 40 plus E M
It considers the following factors.
1. Dial setting
D S is the level of dial setting in dB HL for presentation of speech to the test ear.
2. Air-bone gap
Max ABG NT is the maximum air-bone gap between 250 to 4000 Hz in the non‑test ear.
3. Interaural attenuation
Interaural attenuation: The value of 40 comes from the minimum interaural attenuation for masking in audiometry using headphones (for insert earphones, this would be 55 dB).
4. Effective masking
E M is effective masking. Modern audiometers are calibrated in E M , so you don’t need to include this in the calculation. However, if you are using an old audiometer calibrated to an older calibration standard, then you should calculate the E M .
You can calculate it by measuring the difference in the speech dial setting presented to normal listeners at a level that yields a score of 95% in quiet and the noise dial setting presented to the same ear that yields a score less than 10%.
You can use the results from speech audiometry for many purposes. The below section describes these applications.
1. Cross-check against pure tone audiometry results
The cross-check principle in audiology states that no auditory test result should be accepted and used in the diagnosis of hearing loss until you confirm or cross-check it by one or more independent measures (Hall J. W., 3rd, 2016). Speech-in-quiet testing serves this purpose for the pure tone audiogram.
The following scores and their descriptions identify how well the speech detection threshold and the pure tone average correlate (Table 2).
| 6 dB or less | Good |
| 7 to 12 dB | Adequate |
| 13 dB or more | Poor |
Table 2: Correlation between speech detection threshold and pure tone average.
If there is a poor correlation between the speech detection threshold and the pure tone average, it warrants further investigation to determine the underlying cause or to identify if there was a technical error in the recordings of one of the tests.
2. Detect asymmetries between ears
Another core use of speech audiometry in quiet is to determine the symmetry between the two ears and whether it is appropriate to fit binaural amplification. Significant differences between ears can occur when there are two different etiologies causing hearing loss.
An example of this could be a patient with sensorineural hearing loss who then also contracts unilateral Meniere’s disease . In this example, it would be important to understand if there are significant differences in the word recognition scores between the two ears. If there are significant differences, then it may not be appropriate for you to fit binaural amplification, where other forms of amplification such as contralateral routing of sound (CROS) devices may be more appropriate.
3. Identify if further testing is required
The results from speech audiometry in quiet can identify whether further testing is required. This could be highlighted in several ways.
One example could be a severe difference in the SRT and the pure tone average. Another example could be significant asymmetries between the two ears. Lastly, very poor speech recognition scores in quiet might also be a red flag for further testing.
In these examples, the clinician might decide to perform a test to detect the presence of cochlear dead regions such as the TEN test or an ACT test to get more information.
4. Detect retro-cochlear hearing loss
In subjects with retro-cochlear causes of hearing loss, speech recognition can begin to deteriorate as sounds are made louder. This is called ‘roll-over’ and is calculated by the following equation:
- Roll-over index = (maximum score minus minimum score) divided by maximum score
If roll-over is detected at a certain value (the value is dependent on the word list chosen for testing but is commonly larger than 0.4), then it is considered to be a sign of retro-cochlear pathology. This could then have an influence on the fitting strategy for patients exhibiting these results.
It is important to note however that as the cross-check principle states, you should interpret any roll-over with caution and you should perform additional tests such as acoustic reflexes , the reflex decay test, or auditory brainstem response measurements to confirm the presence of a retro-cochlear lesion.
5. Predict success with amplification
The maximum speech recognition score is a useful measure which you can use to predict whether a person will benefit from hearing aids. More recent, and advanced tests such as the ACT test combined with the Acceptable Noise Level (ANL) test offer good alternatives to predicting hearing success with amplification.
Just like in pure tone audiometry, the stimuli which are presented during speech audiometry require annual calibration by a specialized technician ster. Checking of the transducers of the audiometer to determine if the speech stimulus contains any distortions or level abnormalities should also be performed daily. This process replicates the daily checks a clinicians would do for pure tone audiometry. If speech is being presented using a sound field setup, then you can use a sound level meter to check if the material is being presented at the correct level.
The next level of calibration depends on how the speech material is delivered to the audiometer. Speech material can be presented in many ways including live voice, CD, or installed WAV files on the audiometer. Speech being presented as live voice cannot be calibrated but instead requires the clinician to use the VU meter on the audiometer (which indicates the level of the signal being presented) to determine if they are speaking at the correct intensity. Speech material on a CD requires daily checks and is also performed using the VU meter on the audiometer. Here, a speech calibration tone track on the CD is used, and the VU meter is adjusted accordingly to the desired level as determined by the manufacturer of the speech material.
The most reliable way to deliver a speech stimulus is through a WAV file. By presenting through a WAV file, you can skip the daily tone-based calibration as this method allows you to calibrate the speech material as part of the annual calibration process. This saves the clinician time and ensures the stimulus is calibrated to the same standard as the pure tones in their audiometer. To calibrate the WAV file stimulus, the speech material is calibrated against a speech calibration tone. This is stored on the audiometer. Typically, a 1000 Hz speech tone is used for the calibration and the calibration process is the same as for a 1000 Hz pure tone calibration.
Lastly, if the speech is being presented through the sound field, a calibration professional should perform an annual sound field speaker calibration using an external free field microphone aimed directly at the speaker from the position of the patient’s head.
Coles, R. R., & Priede, V. M. (1975). Masking of the non-test ear in speech audiometry . The Journal of laryngology and otology , 89 (3), 217–226.
Graham, J. Baguley, D. (2009). Ballantyne's Deafness, 7th Edition. Whiley Blackwell.
Hall J. W., 3rd (2016). Crosscheck Principle in Pediatric Audiology Today: A 40-Year Perspective . Journal of audiology & otology , 20 (2), 59–67.
Katz, J. (2009). Handbook of Clinical Audiology. Wolters Kluwer.
Killion, M. C., Niquette, P. A., Gudmundsen, G. I., Revit, L. J., & Banerjee, S. (2004). Development of a quick speech-in-noise test for measuring signal-to-noise ratio loss in normal-hearing and hearing-impaired listeners . The Journal of the Acoustical Society of America , 116 (4), 2395–2405.
Stach, B.A (1998). Clinical Audiology: An Introduction, Cengage Learning.

Popular Academy Advancements
What is nhl-to-ehl correction, getting started: assr, what is the ce-chirp® family of stimuli, nhl-to-ehl correction for abr stimuli.
- Find a distributor
- Customer stories
- Made Magazine
- ABR equipment
- OAE devices
- Hearing aid fitting systems
- Balance testing equipment
Certificates
- Privacy policy
- Cookie Policy
0845 123 5342
Soundbyte Solutions
Automated Speech Test Systems
- Description
- Specification
- Customisation
- Customisation Samples
- Calibration
- Parrotplus RFQ
- Parrotplus Add Tests RFQ
- Spare Parts RFQ
- Accessories RFQ
- Equipment Repair Form
- Parrot Downloads
- ParrotPlus Downloads
- Phoenix Downloads
- Testimonials
- McCormick Toy Test
- English as an Additional Language Toy Test
- Manchester Picture Test
- Manchester Junior Word List
AB Short Word List
- BKB Sentence Test
Related Pages
The AB short word list test first devised by Arthur Boothroyd in 1968, is widely used in the UK as a speech recognition test and for rehabilitation. The Parrot AB test consists of 8 word lists, with each list containing 10 words. Each word has three phonemes constructed as consonant – vowel – consonant with 30 phonemes, 10 vowels and 20 consonants present in each list. The new Parrot AB combines the digital reliability of the Parrot with the benefits of the AB short word list. These include:
- The large number of words which diminishes the effects of learning factors
- 80 separate words have been recorded on the Parrot: these can be played at differing sound levels at the touch of a button
- There is a high inter list equivalence as the recognition score is based on the phonemes correct out of 30
We use a subset (8 lists) of the original 15 word lists. The lists that have been selected as being the most relevant (after consultation with a wide range of audiology professionals), are: 2,5,6,8,11,13,14,15.
| List 1 (2) | List 2 (5) | List 3 (6) | List 4 (8) | List 5 (11) | List 6 (13) | List 7 (14) | List 8 (15) |
|---|---|---|---|---|---|---|---|
| Fish | Fib | Fill | Bath | Man | Kiss | Wish | Hug |
| Duck | Thatch | Catch | Hum | Hip | Buzz | Dutch | Dish |
| Gap | Sum | Thumb | Dip | Thug | Hash | Jam | Ban |
| Cheese | Heel | Heap | Five | Ride | Thieve | Heath | Rage |
| Rail | Wide | Wise | Ways | Siege | Gate | Laze | Chief |
| Hive | Rake | Rave | Reach | Veil | Wife | Bike | Pies |
| Bone | Goes | Goat | Joke | Chose | Pole | Rove | Wet |
| Wedge | Shop | Shone | Noose | Shoot | Wretch | Pet | Cove |
| Moss | Vet | Bed | Got | Web | Dodge | Fog | Loose |
| Tooth | June | Juice | Shell | Cough | Moon | Soon | Moth |
The child should repeat the word exactly as they hear it. If they are not sure of the word they should guess it, and if only part of a word is heard, then they should say that part. Present all the words in the list at the same sound level. Make a note of the result of each presentation on the results sheet. The test can be conducted aided and/or unaided. Use a different word list for each test.
Three points are assigned to each word in the AB word lists, one for each phoneme. Only when a phoneme is entirely correct, does it obtain a score of 1. For example:
Test Word MAN Response PAN
YUU Score = 2
Test Word SHOOT Response SHOOTS
UUY Score = 2 as an addition counts as an error
For each word list a percentage score is obtained by calculating the points awarded out of 30. Therefore, if a child scores 20 in one list presentation, the percentage score is (20/30) x 100% = 66%.
Quick Links
- Accessories
The Discrimination Score is the percentage of words repeated correctly: Discrimination % at HL = 100 x Number of Correct Responses/Number of Trials.
WRS = Word Recognition Score, SRS = Speech Reception Score, Speech Discrimination Score. These terms are interchangeable and describe the patient’s capability to correctly repeat a list of phonetically balanced (PB) words at a comfortable level. The score is a percentage of correct responses and indicates the patient’s ability to understand speech.
Word Recognition Score (WRS)
WRS, or word recognition score, is a type of speech audiometry that is designed to measure speech understanding. Sometimes it is called word discrimination. The words used are common and phonetically balanced and typically presented at a level that is comfortable for the patient. The results of WRS can be used to help set realistic expectations and formulate a treatment plan.
Speech In Noise Test
Speech in noise testing is a critical component to a comprehensive hearing evaluation. When you test a patient's ability to understand speech in a "real world setting" like background noise, the results influence the diagnosis, the recommendations, and the patient's understanding of their own hearing loss.
Auditory Processing
Sometimes, a patient's brain has trouble making sense of auditory information. This is called an auditory processing disorder. It's not always clear that this lack of understanding is a hearing issue, so it requires a very specialized battery of speech tests to identify what kind of processing disorder exists and develop recommendations to improve the listening and understanding for the patient.
QuickSIN is a quick sentence in noise test that quantifies how a patient hears in noise. The patient repeats sentences that are embedded in different levels of restaurant noise and the result is an SNR loss - or Signal To Noise ratio loss. Taking a few additional minutes to measure the SNR loss of every patient seen in your clinic provides valuable insights on the overall status of the patient' s auditory system and allows you to counsel more effectively about communication in real-world situations. Using the Quick SIN to make important decisions about hearing loss treatment and rehabilitation is a key differentiator for clinicians who strive to provide patient-centered care.

BKB-SIN is a sentence in noise test that quantifies how patients hear in noise. The patient repeats sentences that are embedded in different levels of restaurant noise an the result is an SNR loss - or signal to noise ratio loss. This test is designed to evaluate patients of many ages and has normative corrections for children and adults. Taking a few additional minutes to measure the SNR loss of every patient seen in your clinic is a key differentiator for clinicians who strive to provide patient-centered care.
- Education >
- Testing Guides >
- Speech Audiometry >
GRASON-STADLER
- Our Approach
- Cookie Policy
- AMTAS Pro
Corporate Headquarters 10395 West 70th St. Eden Prairie, MN 55344
General Inquires +1 800-700-2282 +1 952-278-4402 [email protected] (US) [email protected] (International)
Technical Support Hardware: +1 877-722-4490 Software: +1 952-278-4456
DISTRIBUTOR LOGIN
- GSI Extranet
- Request an Account
- Forgot Password?
Get Connected
- Distributor Locator
© Copyright 2024
American Speech-Language-Hearing Association
- Certification
- Publications
- Continuing Education
- Practice Management
- Audiologists
- Speech-Language Pathologists
- Academic & Faculty
- Audiology & SLP Assistants
- Speech Testing
Types of Tests
- Auditory Brainstem Response (ABR)
- Otoacoustic Emissions (OAEs)
- Pure-Tone Testing
- Tests of the Middle Ear
About Speech Testing
An audiologist may do a number of tests to check your hearing. Speech testing will look at how well you listen to and repeat words. One test is the speech reception threshold, or SRT.
The SRT is for older children and adults who can talk. The results are compared to pure-tone test results to help identify hearing loss.
How Speech Testing Is Done
The audiologist will say words to you through headphones, and you will repeat the words. The audiologist will record the softest speech you can repeat. You may also need to repeat words that you hear at a louder level. This is done to test word recognition.
Speech testing may happen in a quiet or noisy place. People who have hearing loss often say that they have the most trouble hearing in noisy places. So, it is helpful to test how well you hear in noise.
Learn more about hearing testing .
To find an audiologist near you, visit ProFind .

In the Public Section
- Hearing & Balance
- Speech, Language & Swallowing
- About Health Insurance
- Adding Speech & Hearing Benefits
- Advocacy & Outreach
- Find a Professional
- Advertising Disclaimer
- Advertise with us
ASHA Corporate Partners
- Become A Corporate Partner

The American Speech-Language-Hearing Association (ASHA) is the national professional, scientific, and credentialing association for 234,000 members, certificate holders, and affiliates who are audiologists; speech-language pathologists; speech, language, and hearing scientists; audiology and speech-language pathology assistants; and students.
- All ASHA Websites
- Work at ASHA
- Marketing Solutions
Information For
Get involved.
- ASHA Community
- Become a Mentor
- Become a Volunteer
- Special Interest Groups (SIGs)
Connect With ASHA
American Speech-Language-Hearing Association 2200 Research Blvd., Rockville, MD 20850 Members: 800-498-2071 Non-Member: 800-638-8255
MORE WAYS TO CONNECT
Media Resources
- Press Queries
Site Help | A–Z Topic Index | Privacy Statement | Terms of Use © 1997- American Speech-Language-Hearing Association
Masks Strongly Recommended but Not Required in Maryland
Respiratory viruses continue to circulate in Maryland, so masking remains strongly recommended when you visit Johns Hopkins Medicine clinical locations in Maryland. To protect your loved one, please do not visit if you are sick or have a COVID-19 positive test result. Get more resources on masking and COVID-19 precautions .
- Vaccines
- Masking Guidelines
- Visitor Guidelines
Speech Audiometry

Speech audiometry involves two different tests:
One checks how loud speech needs to be for you to hear it.
The other checks how clearly you can understand and distinguish different words when you hear them spoken.
What Happens During the Test
The tests take 10-15 minutes. You are seated in a sound booth and wear headphones. You will hear a recording of a list of common words spoken at different volumes, and be asked to repeat those words.
Your audiologist will ask you to repeat a list of words to determine your speech reception threshold (SRT) or the lowest volume at which you can hear and recognize speech.
Then, the audiologist will measure speech discrimination — also called word recognition ability. He or she will either say words to you or you will listen to a recording, and then you will be asked to repeat the words. The audiologist will measure your ability to understand speech at a comfortable listening level.
Getting Speech Audiology Test Results
The audiologist will share your test results with you at the completion of testing. Speech discrimination ability is typically measured as a percentage score.
Find a Doctor
Specializing In:
- Sudden Hearing Loss
- Hearing Aids
- Hearing Disorders
- Hearing Loss
- Hearing Restoration
- Implantable Hearing Devices
- Cochlear Implantation
Find a Treatment Center
- Otolaryngology-Head and Neck Surgery
Find Additional Treatment Centers at:
- Howard County Medical Center
- Sibley Memorial Hospital
- Suburban Hospital

Request an Appointment

The Hidden Risks of Hearing Loss

Hearing Loss in Children

What Is an Audiologist
Related Topics
- Aging and Hearing
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Improve recognition accuracy with phrase list
- 1 contributor
A phrase list is a list of words or phrases provided ahead of time to help improve their recognition. Adding a phrase to a phrase list increases its importance, thus making it more likely to be recognized.
Examples of phrases include:
- Geographical locations
- Words or acronyms unique to your industry or organization
Phrase lists are simple and lightweight:
- Just-in-time : A phrase list is provided just before starting the speech recognition, eliminating the need to train a custom model.
- Lightweight : You don't need a large data set. Provide a word or phrase to boost its recognition.
For supported phrase list locales, see Language and voice support for the Speech service .
You can use phrase lists with the Speech Studio , Speech SDK , or Speech Command Line Interface (CLI) . The Batch transcription API doesn't support phrase lists.
You can use phrase lists with both standard and custom speech . There are some situations where training a custom model that includes phrases is likely the best option to improve accuracy. For example, in the following cases you would use custom speech:
- If you need to use a large list of phrases. A phrase list shouldn't have more than 500 phrases.
- If you need a phrase list for languages that aren't currently supported.
Try it in Speech Studio
You can use Speech Studio to test how phrase list would help improve recognition for your audio. To implement a phrase list with your application in production, you use the Speech SDK or Speech CLI.
For example, let's say that you want the Speech service to recognize this sentence: "Hi Rehaan, I'm Jessie from Contoso bank."
You might find that a phrase is incorrectly recognized as: "Hi everyone , I'm Jesse from can't do so bank ."
In the previous scenario, you would want to add "Rehaan", "Jessie", and "Contoso" to your phrase list. Then the names should be recognized correctly.
Now try Speech Studio to see how phrase list can improve recognition accuracy.
You may be prompted to select your Azure subscription and Speech resource, and then acknowledge billing for your region.
- Go to Real-time Speech to text in Speech Studio .
- You test speech recognition by uploading an audio file or recording audio with a microphone. For example, select record audio with a microphone and then say "Hi Rehaan, I'm Jessie from Contoso bank. " Then select the red button to stop recording.
- You should see the transcription result in the Test results text box. If "Rehaan", "Jessie", or "Contoso" were recognized incorrectly, you can add the terms to a phrase list in the next step.
- Select Show advanced options and turn on Phrase list .

- Use the microphone to test recognition again. Otherwise you can select the retry arrow next to your audio file to re-run your audio. The terms "Rehaan", "Jessie", or "Contoso" should be recognized.
Implement phrase list
With the Speech SDK you can add phrases individually and then run speech recognition.
With the Speech CLI you can include a phrase list in-line or with a text file along with the recognize command.
Try recognition from a microphone or an audio file.
You can also add a phrase list using a text file that contains one phrase per line.
Allowed characters include locale-specific letters and digits, white space characters, and special characters such as +, -, $, :, (, ), {, }, _, ., ?, @, \, ’, &, #, %, ^, *, `, <, >, ;, /. Other special characters are removed internally from the phrase.
Check out more options to improve recognition accuracy.
Custom speech
Was this page helpful?
Additional resources
Toggle Menu
Tous droits réservés © NeurOreille (loi sur la propriété intellectuelle 85-660 du 3 juillet 1985). Ce produit ne peut être copié ou utilisé dans un but lucratif.
Journey into the world of hearing
Speech audiometry
Authors: Benjamin Chaix Rebecca Lewis Contributors: Diane Lazard Sam Irving
Facebook Twitter Google+
Speech audiometry is routinely carried out in the clinic. It is complementary to pure tone audiometry, which only gives an indication of absolute perceptual thresholds of tonal sounds (peripheral function), whereas speech audiometry determines speech intelligibility and discrimination (between phonemes). It is of major importance during hearing aid fitting and for diagnosis of certain retrocochlear pathologies (tumour of the auditory nerve, auditory neuropathy, etc.) and tests both peripheral and central systems.
Speech audiogram
Normal hearing and hearing impaired subjects.
The speech recognition threshold (SRT) is the lowest level at which a person can identify a sound from a closed set list of disyllabic words.
The word recognition score (WRS) testrequires a list of single syllable words unknown to the patient to be presented at the speech recognition threshold + 30 dBHL. The number of correct words is scored out of the number of presented words to give the WRS. A score of 85-100% correct is considered normal when pure tone thresholds are normal (A), but it is common for WRS to decrease with increasing sensorineural hearing loss.
The curve 'B', on the other hand, indicates hypoacusis (a slight hearing impairment), and 'C' indicates a profound loss of speech intelligibility with distortion occurring at intensities greater than 80 dB HL.
It is important to distinguish between WRS, which gives an indication of speech comprehension, and SRT, which is the ability to distinguish phonemes.
Phonetic materials and testing conditions
Various tests can be carried out using lists of sentences, monosyllabic or dissyllabic words, or logatomes (words with no meaning, also known as pseudowords). Dissyllabic words require mental substitution (identification by context), the others do not.
A few examples
|
|
| ||
|
Laud Boat Pool Nag Limb Shout Sub Vine Dime Goose |
Pick Room Nice Said Fail South White Keep Dead Loaf | Greyhound Schoolboy Inkwell Whitewash Pancake Mousetrap Eardrum Headlight Birthday Duck pond | |
The test stimuli can be presented through headphones to test each ear separately, or in freefield in a sound attenuated booth to allow binaural hearing to be tested with and without hearing aids or cochlear implants. Test material is adapted to the individual's age and language ability.
What you need to remember
In the case of a conductive hearing loss:
- the response curve has a normal 'S' shape, there is no deformation
- there is a shift to the right compared to the reference (normal threshold)
- there is an increase in the threshold of intelligibility
In the case of sensorineural hearing loss:
- there is an increased intelligibility threshold
- the curve can appear normal except in the higher intensity regions, where deformations indicate distortions
Phonetic testing is also carried out routinely in the clinic (especially in the case of rehabilitation after cochlear implantation). It is relatively long to carry out, but enables the evaluation of the real social and linguistic handicaps experienced by hearing impaired individuals. Cochlear deficits are tested using the “CNC (Consonant Nucleus Consonant) Test” (short words requiring little mental recruitment - errors are apparent on each phoneme and not over the complete word) and central deficits are tested with speech in noise tests, such as the “HINT (Hearing In Noise Test)” or “QuickSIN (Quick Speech In Noise)” tests, which are sentences carried out in noise.
Speech audiometry generally confirms pure tone audiometry results, and provides insight to the perceptual abilities of the individual. The intelligibility threshold is generally equivalent to the average of the intensity of frequencies 500, 1000 and 2000 Hz, determined by tonal audiometry (conversational frequencies). In the case of mismatch between the results of these tests, the diagnostic test used, equipment calibration or the reliability of the responses should be called into question.
Finally, remember that speech audiometry is a more sensitive indicator than pure tone audiometry in many cases, including rehabilitation after cochlear implantation.
Last update: 16/04/2020 8:57 pm
Connexion | Powered by eZPublish - Ligams
Loading metrics
Open Access
Peer-reviewed
Research Article
Language models outperform cloze predictability in a cognitive model of reading
Roles Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Visualization, Writing – original draft, Writing – review & editing
* E-mail: [email protected]
Affiliation Department of Education, Vrije Universiteit Amsterdam, and LEARN! Research Institute, Amsterdam, The Netherlands
Roles Conceptualization, Methodology, Supervision, Writing – review & editing
Affiliation Department of Experimental and Applied Psychology, Vrije Universiteit Amsterdam, Amsterdam, The Netherlands
Roles Conceptualization, Formal analysis, Funding acquisition, Methodology, Project administration, Software, Validation, Writing – review & editing
- Adrielli Tina Lopes Rego,
- Joshua Snell,
- Martijn Meeter
- Published: September 25, 2024
- https://doi.org/10.1371/journal.pcbi.1012117
- Peer Review
- Reader Comments
This is an uncorrected proof.
Although word predictability is commonly considered an important factor in reading, sophisticated accounts of predictability in theories of reading are lacking. Computational models of reading traditionally use cloze norming as a proxy of word predictability, but what cloze norms precisely capture remains unclear. This study investigates whether large language models (LLMs) can fill this gap. Contextual predictions are implemented via a novel parallel-graded mechanism, where all predicted words at a given position are pre-activated as a function of contextual certainty, which varies dynamically as text processing unfolds. Through reading simulations with OB1-reader, a cognitive model of word recognition and eye-movement control in reading, we compare the model’s fit to eye-movement data when using predictability values derived from a cloze task against those derived from LLMs (GPT-2 and LLaMA). Root Mean Square Error between simulated and human eye movements indicates that LLM predictability provides a better fit than cloze. This is the first study to use LLMs to augment a cognitive model of reading with higher-order language processing while proposing a mechanism on the interplay between word predictability and eye movements.
Author summary
Reading comprehension is a crucial skill that is highly predictive of later success in education. One aspect of efficient reading is our ability to predict what is coming next in the text based on the current context. Although we know predictions take place during reading, the mechanism through which contextual facilitation affects oculomotor behaviour in reading is not yet well-understood. Here, we model this mechanism and test different measures of predictability (computational vs. empirical) by simulating eye movements with a cognitive model of reading. Our results suggest that, when implemented with our novel mechanism, a computational measure of predictability provides better fits to eye movements in reading than a traditional empirical measure. With this model, we scrutinize how predictions about upcoming input affects eye movements in reading, and how computational approaches to measuring predictability may support theory testing. Modelling aspects of reading comprehension and testing them against human behaviour contributes to the effort of advancing theory building in reading research. In the longer term, more understanding of reading comprehension may help improve reading pedagogies, diagnoses and treatments.
Citation: Lopes Rego AT, Snell J, Meeter M (2024) Language models outperform cloze predictability in a cognitive model of reading. PLoS Comput Biol 20(9): e1012117. https://doi.org/10.1371/journal.pcbi.1012117
Editor: Ronald van den Berg, Stockholm University, SWEDEN
Received: April 26, 2024; Accepted: September 9, 2024; Published: September 25, 2024
Copyright: © 2024 Lopes Rego et al. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Data Availability: All the relevant data and source code used to produce the results and analyses presented in this manuscript are available on a Github repository at https://github.com/dritlopes/OB1-reader-model .
Funding: This study was supported by the Nederlandse Organisatie voor Wetenschappelijk Onderzoek (NWO) Open Competition-SSH (Social Sciences and Humanities) ( https://www.nwo.nl ), 406.21.GO.019 to MM. The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Competing interests: The authors declare that no competing interests exist.
Introduction
Humans can read remarkably efficiently. What underlies efficient reading has been subject of considerable interest in psycholinguistic research. A prominent hypothesis is that we can generally keep up with the rapid pace of language input because language processing is predictive, i.e., as reading unfolds, the reader anticipates some information about the upcoming input [ 1 – 3 ]. Despite general agreement that this is the case, it remains unclear how to best operationalize contextual predictions [ 3 , 4 ]. In current models of reading [ 5 – 9 ]), the influence of prior context on word recognition is operationalized using cloze norming, which is the proportion of participants that complete a textual sequence by answering a given word. However, cloze norming has both theoretical and practical limitations, which are outlined below [ 4 , 10 , 11 ]. To address these concerns, in the present work we explore the use of Large Language Models (LLMs) as an alternative means to account for contextual predictions in computational models of reading. In the remainder of this section, we discuss the limitations of the current implementation of contextual predictions in models of reading, which includes the use of cloze norming, as well as the potential benefits of LLM outputs as a proxy of word predictability. We also offer a novel parsimonious account of how these predictions gradually unfold during text processing.
Computational models of reading are formalized theories about the cognitive mechanisms that may take place during reading. The most prominent type of model are models of eye-movement control in text reading (see [ 12 ] for a detailed overview). These attempt to explain how the brain guides the eyes, by combining perceptual, oculomotor, and linguistic processes. Despite the success of these models in simulating some word-level effects on reading behaviour, the implementation of contextual influences on the recognition of incoming linguistic input is yet largely simplified. Word predictability affects lexical access of the upcoming word by modulating either its recognition threshold (e.g. E-Z Reader [ 5 ] and OB1-reader [ 6 ]) or its activation (e.g. SWIFT [ 7 ]). This process is embedded in the “familiarity check” of the E-Z Reader model and the “rate of activation” in the SWIFT model. One common assumption among models is that the effect of predictability depends on certain word-processing stages. In the case of the E-Z Reader model, the effect of predictability of word n on its familiarity check depends on the completion of “lexical access” of word n-1 . That is, predictability of word n facilitates its processing only if the preceding word has been correctly recognized and integrated into the current sentence representation [ 13 ]. In the case of the SWIFT model, the modulation of predictability on the rate of activation of word n depends on whether the processing of word n is on its “parafoveal preprocessing” stage, where activation increases more slowly the higher the predictability, or its “lexical completion” stage, where activation decreases more slowly the higher the predictability [ 12 ]. These models ignore the predictability of words that do not appear in the stimulus text, even though they may have been predicted at a given text position and assume a one-to-one match between the input and the actual text for computing predictability values. Because the models do not provide a deeper account of language processing at the syntactic and semantic levels, they cannot allow predictability to vary dynamically as text processing unfolds. Instead, predictability is computed prior to the simulations and fixed.
What is more, the pre-determined, fixed predictability value in such models is conventionally operationalized with cloze norming [ 14 ]. Cloze predictability is obtained by having participants write continuations of an incomplete sequence, and then taking the proportion of participants that have answered a given word as the cloze probability of that word. The assumption is that the participants draw on their individual lexical probability distributions to fill in the blank, and that cloze reflects some overall subjective probability distribution. For example, house may be more probable than place to complete I met him at my for participant A, but not for participant B. However, scientists have questioned this assumption [ 4 , 10 , 11 ]. The cloze task is an offline and untimed task, leaving ample room for participants to consciously reflect on sequence completion and adopt strategic decisions [ 4 ]. This may be quite different from normal reading where only ~200ms is spent on each word [ 15 ]. Another issue is that cloze cannot provide estimates for low-probability continuations, in contrast with behavioural evidence showing predictability effects of words that never appear among cloze responses, based on other estimators, such as part-of-speech [ 10 , 16 ]. Thus, cloze completions likely do not perfectly match the rapid predictions that are made online as reading unfolds.
Predictability values generated by LLMs may be a suitable methodological alternative to cloze completion probabilities. LLMs are computational models whose task is to assign probabilities to sequences of words [ 17 ]. Such models are traditionally trained to accurately predict a token given its contextual sequence, similarly to a cloze task. An important difference, however, is that whereas cloze probability is an average across participants, probabilities derived from LLMs are relative to every other word in the model’s vocabulary. This allows LLMs to better capture the probability of words that rarely or never appear among cloze responses, potentially revealing variation in the lower range [ 18 ]. In addition, LLMs may offer a better proxy of semantic and syntactic contextual effects, as they computationally define predictability and how it is learned from experience. The model learns lexical knowledge from the textual data, which can be seen as analogous to the language experience of humans. The meaning of words are determined by the contexts in which they appear ( distributional hypothesis [ 19 ]) and the consolidated knowledge is used to predict the next lexical item in a sequence [ 11 ]. The advantage of language models in estimating predictability is also practical: it has been speculated that millions of samples per context would be needed in a cloze task to reach the precision of language models in reflecting language statistics [ 20 ], which is hardly feasible. And even if such an extremely large sample would be reached, we would still need the assumption that cloze-derived predictions match real-time predictions in language comprehension, which is questionable [ 4 , 21 ].
Importantly, language models have been shown to perform as well as, or even outperform, predictability estimates derived from cloze tasks in fitting reading data. Shain and colleagues [ 20 ] found robust word predictability effects across six corpora of eye-movements using surprisal estimates from various language models, with GPT-2 providing the best fit. The effect was qualitatively similar when using cloze estimates in the corpus for which they were available. Another compelling bit of evidence comes from Hofmann and colleagues [ 11 ], who compared cloze completion probabilities with three different language models (ngram model, recurrent neural network and topic model) in predicting eye movements. They tested the hypothesis that each language model is more suitable for capturing a different cognitive process in reading, which in turn is reflected by early versus late eye-movement measures. Item-level analyses showed that the correlations of each eye movement measure were stronger with each language model than with cloze. In addition, fixation-event based analyses revealed that the ngram model better captured lag effects on early measures (replicating the results from Smith and Levy [ 10 ]), while the recurrent neural network more consistently yielded lag effects on late measure. A more recent study [ 22 ] found neural evidence for the advantage of language models over cloze, by showing that predictions from LLMs (GPT-3, ROBERTa and ALBERT) matched N400 amplitudes more closely than cloze-derived predictions. Such evidence has led to the belief that language models may be suitable for theory development in models of eye-movement control in reading [ 11 ].
The present study marks an important step in exploring the potential of language models in advancing our understanding of the reading brain [ 23 , 24 ], and more specifically, of LLMs’ ability to account for contextual predictions in models of eye-movement control in reading [ 11 ]. We investigate whether a model of eye-movement control in reading can more accurately simulate reading behaviour using predictability derived from transformer-based LLMs or from cloze. We hypothesize that LLM-derived probabilities capture semantic and syntactic integration of the previous context, which in turn affects processing of upcoming bottom-up input. This effect is expected to be captured in the early reading measures (see Methods ). Since predictability may also reflect semantic and syntactic integration of the predicted word with the previous context [ 18 ], late measures are also evaluated.
Importantly however, employing LLM-generated predictions is only one part of the story. A cognitive theory of reading also has to make clear how those predictions operate precisely: i.e., when, where, how, and why do predictions affect processing of upcoming text? The aforementioned models have been agnostic about this. Aiming to fill this gap, our answer, as implemented in the updated OB1-reader model, is as follows.
We propose that making predictions about upcoming words affects their recognition through graded and parallel activation. Predictability is graded because it modulates activation of all words predicted to be at a given position in the parafovea to the extent of each word’s likelihood. This means that higher predictability leads to a stronger activation of all words predicted to be at a given position in the parafovea. Predictability is also parallel, because predictions can be made about multiple text positions simultaneously. Note that this is in line with the parallel structure of the OB1-reader, and this is an important contrasting point with serial processing models, such as E-Z Reader, which assume that words are processed one at a time. The predictability mechanism as proposed here is thus, in principle, not compatible with serial models of word processing. With each processing cycle, this predictability-derived activation is summed to the activity resulting from visual processing of the previous cycle and weighted by the predictability of the previous word, which in turn reflects the prediction certainty up to the current cycle (see Methods for more detailed explanation). In this way, predictability gradually and dynamically affects words in parallel, including non-text words in the model’s lexicon.
Importantly, the account of predictability as predictive activation proposed here diverges from the proportional pre-activation account of predictability by Brothers and Kuperberg [ 25 ] in two ways. First, they define predictive pre-activation as the activation of linguistic features (orthographic, syntactic and semantic). However, the evidence is mixed as to whether we predict specific words [ 10 ] or more abstract categories [ 26 ]. Expectations are likely built about different levels of linguistic representations, but here predictive activation is limited to words, and this activation is roughly proportional to each word’s predictability (thus we agree with the proportionality suggested by Brothers and Kuperberg [ 25 ]). Second, predictive activation would be prior to the word’s availability in the bottom-up input. We note that predictability without parafoveal preview is debatable. Most studies claim that predictability effects only occur with parafoveal preview [ 27 ], but Parker and colleagues [ 28 ] showed predictability effects without parafoveal preview using a novel experimental paradigm. In OB1-reader, predictions are made about words within parafoveal preview, which means that bottom-up input is available when predictions are made about words in the parafovea. Since OB1-reader processes multiple words in parallel, predictions are generated about the identity of all words in the parafovea while their orthographic input is being processed and their recognition has not been completed.
In sum, the model assumptions regarding predictability include predictability being: (i) graded, i.e. more than one word can be predicted at each text position; (ii) parallel, i.e. predictions can be made about multiple text positions simultaneously; (iii) parafoveal, i.e. predictions are made about the words in the parafovea; (iv) dynamic, i.e. predictability effects change according to the certainty of the predictions previously made; and (v) lexical, i.e. predictions are made about words as defined by text spaces and not about other abstract categories.
Assuming that predictability during reading is graded, parallel, parafoveal, dynamic, and lexical, we hypothesize that OB1-reader achieves a better fit to human oculomotor data with LLM-derived predictions than with cloze-derived predictions. To test this hypothesis, we ran reading simulations with OB1-reader either using LLM-derived predictability or cloze-derived predictability to activate words in the model’s lexicon prior to fixation. The resulting reading measures were compared with measures derived from eye-tracking data to evaluate the model’s fit to human data. To our knowledge, this is the first study to combine a language model with a computational cognitive model of eye-movement control in reading to test whether the output of LLMs is a suitable proxy for word predictability in such models.
For the reading simulations, we used OB1-reader [ 6 ] (see Model Description in Methods for more details on this model). In each processing cycle from OB1-reader’s reading simulation, the predictability values were used to activate the predicted words in the upcoming position (see Predictability Implementation in Methods for a detailed description). Each simulation consisted in processing all the 55 passages from the Provo Corpus [ 29 ] (see Eye-tracking and Cloze Norming in Methods for more details on the materials). The predictability values were derived from three different estimators: cloze, GPT-2 [ 30 ] and LLaMA [ 31 ]. The cloze values were taken from the Provo Corpus (see Eye-tracking and Cloze Norming in Methods for more details on Cloze Norming). The LLM values were generated from GPT-2 and LLaMA. We compare the performance of a simpler transformer-based language model, i.e. GPT-2, with a more complex one, i.e. LLaMA. Both models are transformer-based, auto-regressive LLMs, which differ in size and next-word prediction accuracy, among other aspects. The version of GPT-2 used has 124 million parameters and 50k vocabulary size. The version of LLaMA used has a much higher number of parameters, 7 billion, but a smaller vocabulary size, 32k. Importantly, LLaMA yields a higher next-word prediction accuracy on the Provo passages, 76% against 64% by GPT-2 (see Language Models in Methods for more details on these models).
We ran 100 simulations per condition in a “3x3 + 1” design: three predictability estimators (cloze, GPT-2 and LLaMA), three predictability weights (low = 0.05, medium = 0.1, and high = 0.2) and a baseline (no predictability). For the analysis, we considered eye-movement measures at word-level. The early eye-movement measures of interest were (i) skipping, i.e. the proportion of participants who skipped the word on first pass; (ii) first fixation duration, i.e. the duration of the first fixation on the word; and (iii) gaze duration, i.e. the sum of fixations on the word before the eyes move forward. The late eye-movement measures of interest were (iv) total reading time, i.e. the sum of fixation durations on the word; and (v) regression, i.e. the proportion of participants who fixated the word after the eyes have already passed the text region the word is located.
To evaluate the model simulations, we used the reading time data from the Provo corpus [ 29 ] and computed the Root Mean Squared Error (RMSE) between each eye-movement measure from each simulation by OB1-reader and each eye-movement measure from the Provo corpus averaged over participants. To check whether the simulated eye movements across predictability estimators were significantly different ( p < = .05), we ran the Wilcoxon T-test from the Scipy python library.
In addition, we conducted a systematic analysis on the hits and failures of the simulation model across predictability conditions to better understand what drives the differences in model fit between LLMs and cloze predictability. The analysis consisted of comparing simulated eye movements and empirical eye movements on different word-based features, namely length, frequency, predictability, word id (position in the sentence), and word type (content, function, and other). In particular, word type was defined according to the word’s part-of-speech tag. For instance, verbs, adjectives, and nouns were considered content words, whereas articles, particles, and pronouns were considered function words (see Reading Simulations in Methods for more details).
Fit across eye-movement measures
In line with our hypotheses, OB1-reader simulations were closer to the human eye-movements with LLM predictability than with cloze predictability. Fig 1 shows the standardized RMSE of each condition averaged over eye movement measures and predictability weights. To attest the predictability implementation proposed in OB1-reader, we compared the RMSE scores between predictability conditions and baseline. All predictability conditions reduced the error relative to the baseline, which confirms the favourable effect of word predictability on fitting word-level eye movement measures in OB1-reader. When comparing the RMSE scores across predictability conditions, the larger language model LLaMA yielded the least error. When comparing the error among predictability weights (see Fig 2 ), LLaMA yielded the least error in all weight conditions, while GPT-2 produced less error than cloze only with the low predictability weight. These results suggest that language models, especially with a higher parameter count and prediction accuracy, are good word predictability estimators for modelling eye movements in reading [ 32 ]. Note that the model’s average word recognition accuracy was stable across predictability conditions (cloze = .91; GPT-2 = .92; LLaMA = .93). We now turn to the results for each individual type of eye movement ( Fig 3 ).
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
RMSE scores are standardized using the human averages and standard deviations as reference. The minimum RMSE value is 1, meaning no difference between eye movements from corpus and eye movements from simulations. Each data point here represents the RMSE score of one simulation averaged over words.
https://doi.org/10.1371/journal.pcbi.1012117.g001
RMSE scores averaged over eye movement measures. * means p-value < = .05, ** means p-value < = .01, and *** means p-value < = .001.
https://doi.org/10.1371/journal.pcbi.1012117.g002
In the y-axis, eye movement measures are represented with the abbreviations SK (skipping), FFD (first fixation duration), GD (gaze duration), TRT (total reading time), and RG (regression).
https://doi.org/10.1371/journal.pcbi.1012117.g003
First fixation duration
RMSE scores for item-level first fixation duration revealed that predictability from LLaMA yielded the best fit compared to GPT-2 and cloze. LLaMA also yielded the least error in each weight condition (see Fig 4A ). When comparing simulated and observed values ( S1 Fig ), first fixation durations are consistently longer in the model simulations. As for predictability effects ( S1 Fig ), the relation between predictability and first fixation duration seemed to be weakly facilitatory, with more predictability leading to slightly shorter first fixation duration in both the Provo Corpus and the OB1-reader simulations. This relation occurred in all predictability conditions, suggesting that the LLMs capture a similar relation between predictability and eye movements as cloze norming, and that this relation also exist for eye movements in the Provo Corpus.
* means p-value < = .05, ** means p-value < = .01, and *** means p-value < = .001. a RMSE scores for first fixation duration. b RMSE scores for gaze duration. c RMSE scores for skipping rates. d RMSE scores for total reading time. e RMSE scores for regression rates.
https://doi.org/10.1371/journal.pcbi.1012117.g004
Our systematic analysis showed that, across predictability conditions, the model generated more error with longer, infrequent, more predictable, as well as the initial words of the passage compared to the final words ( S2 Fig ). More importantly, the advantage of LLaMA relative to the other predictability conditions in fitting first fixation duration seems to stem from LLaMA providing better fits for highly predictable words. When comparing simulated and human first fixation durations ( S3 Fig ), we observed that the difference (i.e. simulated durations are longer) is more pronounced for longer and infrequent words. Another observation is that, across predictability conditions, the model fails to capture wrap-up effects (i.e. longer reaction times towards the end of the sequence), which seems to occur in the human data, but not in the model data.
Gaze duration
LLaMA produced the least averaged error in fitting gaze duration. GPT-2 produced either similar fits to cloze or a slightly worse fit than cloze (see Fig 4B ). All predictability conditions reduce error compared to the baseline, confirming the benefit of word predictability for predicting gaze duration. Higher predictability shortened gaze duration ( S4 Fig ) in both the model simulations (OB1-reader) and in the empirical data (Provo Corpus), and, similarly to first fixation duration, simulated gaze durations were consistently longer than the observed gaze durations. Also consistent with first fixation durations, more error is observed for longer, infrequent words. However, differently from the pattern observed with first fixation duration, gaze durations are better fit by the model for more predictable words and initial words in a passage. LLMs, especially LLaMA, generate slightly less error across predictability values, and LLaMA is slightly better at fitting gaze durations of words positioned closer to the end of the passages ( S5 Fig ). Simulated values are longer than human values, especially with long words ( S6 Fig ).
Unexpectedly, skipping rates showed increasing error with predictability compared to the baseline. RMSE scores were higher in the LLaMA condition for all weights (see Fig 4C ). These results show no evidence of skipping being more accurately simulated with any of the predictability estimations tested in this study. While OB1-reader produced sizable predictability effects on skipping rates, these effects seem to be very slight in the empirical data ( S7 Fig ). Another unexpected result was a general trend for producing more error for short, frequent and predictable words, with LLaMA generating more error in fitting highly predictable words than GPT-2 and cloze ( S8 Fig ). Moreover, the model generated more error in fitting function words than content words, which is the inverse trend relative to reading times, for which more error is observed with content words than function words ( S9 Fig ). A closer inspection of this pattern reveals that the model skips generally less than humans; especially longer, infrequent, and final content words. However, the reverse is seen for function words, which the model skips more often than humans do ( S10 Fig ).
Total reading time
Improvement in RMSE relative to the baseline was seen for total reading time in all conditions. LLaMA showed the best performance, with lower error compared to cloze and GPT-2, especially in the low and high weight conditions (see Fig 4D ). Higher predictability led to shorter total reading time, and this was reproduced by OB1 reader in all conditions. LLaMA showed trend lines for the relation between predictability and total reading time that parallel those seen in the data, suggesting a better qualitative fit than for either cloze or GPT-2 ( S11 Fig ). Similarly to the error patterns with gaze duration, the model generated more error with longer, infrequent, less predictable and final words across predictability conditions ( S12 Fig ). Also consistent with the results for gaze duration, total reading times from the simulations are longer than those of humans, particularly for longer and infrequent words ( S13 Fig ).
Lastly, RMSE for regression was reduced in all predictability conditions compared to the baseline. The lowest error is generated with LLaMA-generated word predictability across predictability weights (see Fig 4E ). Predictability effects on regression are in the expected direction, with higher predictability associated with lower regression rate, but this effect is amplified in the simulations (OB1-reader) relative to the empirical data (Provo Corpus) as indicated by the steeper trend lines in the simulated regression rates ( S14 Fig ). Similarly to the error patterns for skipping, the model generated more error with shorter, frequent and initial words. In contrast, error decreases as predictability increases in the simulations by the LLMs, especially by LLaMA, which generated less error with highly predictable words ( S15 Fig ). LLaMA is also slightly better at fitting regression to function words ( S9 Fig ). Furthermore, fitting simulated regression rates to word length, frequency and position showed similar trends as fitting the human regression rates, with steeper trend lines for the simulated values ( S16 Fig ).
The current paper is the first to reveal that large language models (LLMs) can complement cognitive models of reading at the functional level. While previous studies have shown that LLMs provide predictability estimates that can fit reading behaviour as good as or better than cloze norming, here we go a step further by showing that language models may outperform cloze norming when used in a cognitive model of reading and tested in terms of simulation fits. Our results suggest that LLMs can provide the basis for a more sophisticated account of syntactic and semantic processes in models of reading comprehension. Word predictability from language models improves fit to eye-movements in reading.
Word predictability from language models improves fit to eye-movements in reading
Using predictability values generated from LLMs (especially LLaMA) to regulate word activation in a cognitive model of eye-movement control in reading (OB1-reader) reduced error between the simulated eye-movements and the corpus eye-movements, relative to using no predictability or to using cloze predictability. Late eye-movement measures (total reading time and regression) showed the most benefit in reducing error in the LLM predictability conditions, with decreasing error the higher the predictability weight. One interpretation of this result is that predictability reflects the ease of integrating the incoming bottom-up input with the previously processed context, with highly predictable words being more readily integrated with the previously processed context than highly unpredictable words [ 33 ]. We emphasize, however, that we do not implement a mechanism for word integration or sentence processing in OB1-reader, and so cannot support this interpretation from the findings at that level.
Notably, the benefit of predictability is less clear for early measures (skipping, first fixation duration and gaze duration) than for late measures across conditions. The more modest beneficial effect of predictability on simulating first-pass reading may be explained by comparing simulated and observed values. We found that OB1-reader consistently provides longer first-fixation and gaze durations. Slow first-pass reading might be due to free parameters of the model not yet being optimally fit. Estimating parameters in computational cognitive models is not a simple task, particularly for models with intractable likelihood for which computing the data likelihood requires integrating over various rules. Follow-up research should apply more sophisticated techniques for model parameter fitting, for instance using Artificial Neural Networks [ 34 ].
Moreover, predictability did not improve the fit to skipping. Even though adding predictability increases the average skipping rate (which causes the model to better approximate the average skipping rate of human readers) there nonetheless appears to be a mismatch between the model and the human data in terms of which individual words are skipped. One potential explanation involves the effect of word predictability on skipping being larger in OB1-reader than in human readers. The model skips highly predictable words more often than humans do. The high skipping rate seems to be related to the relatively slow first-pass reading observed in the simulations. The longer the model spends fixating a certain word, the more activity parafoveal words may receive, and thus the higher the chance that these are recognized while in the parafovea and are subsequently skipped. This effect can be more pronounced in highly predictable words, which receive more predictive activation under parafoveal preview. Thus, given the model’s assumption that early (i.e. in parafoveal preview) word recognition largely drives word skipping, predicative activation may lead OB1-reader to recognize highly predictable words in the parafovea and skip them. Parafoveal recognition either does not occur as often in humans, or does not cause human readers to skip those words as reliably as occurs in the model. It is also plausible that lexical retrieval prior to fixation is not the only factor driving skipping behaviour. More investigation is needed into the interplay between top-down feedback processes, such as predictability, and perception processes, such as visual word recognition, and the role of this interaction in saccade programming.
To better understand the potential differences between model and empirical data, as well as factors driving the higher performance of simulations using LLM-based predictability, we compared simulated and human eye movements in relation to word-based linguistic features. Across predictability conditions, we found reverse trends in simulating reading times and saccade patterns: while the reading times of longer, infrequent, and content words were more difficult for the model to simulate, more error was observed in fitting skipping and regression rates of shorter, frequent, and function words. A closer inspection of the raw differences between simulated and human data showed that the model was more critically slower than humans at first-pass reading of longer and infrequent words. It also skipped and regressed to longer, infrequent and content words less often than humans. The model, thus, seems to read more difficult words more “statically” (one-by-one) than humans do, with less room for “dynamic” reading (reading fast, skipping, and regressing for remembering or correcting).
When comparing LLMs to cloze, simulations using LLaMA-derived predictability showed an advantage at simulating gaze duration, total reading time and regression rates of highly predictable words, and a disadvantage at simulating skipping rates of highly predictable words. One potential explanation is that highly predictable words from the LLM are read faster, and thus are closer to human reading times, because LLaMA-derived likelihoods for highly predictable words are higher than those derived from GPT-2 and cloze ( S17 Fig ), providing more predictive activation to those words. LLaMA is also more accurate at predicting the next word in the Provo passages, which may allow the model to provide more predictive activation to the correct word in the passage ( S1 Appendix ). Next to faster reading, simulations using LLaMA may also skip highly predictable words more often, leading to increasing mismatch with the human data. This process was put forward before as the reason why the model may exaggerate the skipping of highly predictable words, and, since LLaMA provides higher values for highly predictable words and it is more accurate at predicting, the process is more pronounced in the LLaMA condition.
All in all, RMSE between simulated eye movements and corpus eye movements across eye movement measures indicated that LLMs can provide word predictability estimates which are better than cloze norming at fitting eye movements with a model of reading. Moreover, the least error across eye movement simulations occurred with predictability derived from a more complex language model (in this case, LLaMA), relative to a simpler language model (GPT-2) and cloze norming. Previous studies using transformer-based language models have shown mixed evidence for a positive relation between model quality and the ability of the predictability estimates to predict human reading behaviour [ 20 , 35 – 37 ]. Our results align with studies that have found language model word prediction accuracy, commonly operationalized as perplexity or cross-entropy, and model size, commonly operationalized as the number of parameters, to positively correlate with the model’s psychometric predictive power [ 32 , 35 ]. Note that number of parameters and next-word prediction accuracy are not the only differences between the models used. Further investigation is needed comparing more language models, and the same language model with one setting under scrutiny which varies systematically (e.g. all settings are the same except the parameter count), to help to determine which language model and settings are best for estimating predictability in reading simulations. Our results suggest that more complex pre-trained LLMs are more useful to this end.
Language models may aid our understanding of the cognitive mechanisms underlying reading
Improved fits aside, the broader, and perhaps more important, question is whether language models may provide a better account of the higher-order cognition involved in language comprehension. Various recent studies have claimed that deep language models offer a suitable “computational framework”, or “deeper explanation”, for investigating the neurobiological mechanisms of language [ 11 , 23 , 24 ], based on the correlation between model performance and human data. However, correlation between model and neural and behavioural data does not necessarily mean that the model is performing cognition, because the same input-output mappings can be performed by wholly different mechanisms (this is the “multiple realizability” principle) [ 38 ]. Consequently, claiming that our results show that LLMs constitute a “deeper explanation” for predictability in reading would be a logical fallacy. It at best is a failed falsification attempt, that is, we failed to show that language models are unsuitable for complementing cognitive models of reading. Our results rather suggest that language models might be useful in the search for explanatory theories about reading. Caution remains important when drawing parallels between separate implementations, such as between language models and human cognition [ 39 ].
The question is then how we can best interpret language models for cognitive theory building. If they resemble language processing in the human brain, how so? One option is to frame LLMs as good models of how language works in the brain, which implies that LLMs and language cognition are mechanistically equivalent. This is improbable however, given that LLMs are tools built to perform language tasks efficiently, with no theoretical, empirical or biological considerations about human cognition. It is highly unlikely that language processing in the human brain resembles a Transformer implemented on a serial processor. Indeed, some studies explicitly refrain from making such claims, despite referring to language models as a “deeper explanation” or “suitable computational framework” for understanding language cognition [ 11 , 23 ].
Another interpretation is that LLMs resemble the brain by performing the same task, namely to predict the upcoming linguistic input before they are perceived. Prediction as the basic mechanism underlying language is the core idea of Predictive Coding, a prominent theory in psycholinguistics [ 3 ] and in cognitive neuroscience [ 40 , 41 ]. However, shared tasks do not necessarily imply shared algorithms. For instance, it has been shown that more accuracy on next-word prediction was associated with worse encoding of brain responses, contrary to what the theory of predictive coding would imply [ 39 ].
Yet another possibility is that LLMs resemble human language cognition at a more abstract level: both systems encode linguistic features which are acquired through statistical learning on the basis of linguistic data. The similarities are then caused not by the algorithm, but by the features in the input which both systems learn to optimally encode. The capability of language models to encode linguistic knowledge has been taken as evidence that language—including grammar, morphology and semantics—may be acquired solely through exposure, without the need for, e.g., an in-built sense of grammar [ 42 ]. How humans acquire language has been a continuous debate between two camps: the proponents of universal grammar argue for the need of an innate, rule-based, domain-specific language system [ 43 , 44 ], whereas the proponents of usage-based theories emphasize the role of domain-general cognition (e.g. statistical learning, [ 45 ], and generalization, [ 46 ]) in learning from language experience. Studying large language models can only enlighten this debate if those models are taken to capture the essence of human learning from linguistic input.
In contrast, some studies criticize the use of language models to understand human processing altogether. Having found a linear relationship between predictability and reading times instead of a logarithmic relationship, Smith and Levy [ 10 ] and Brothers and Kuperberg [ 25 ] speculated the discrepancy to be due to the use of n-gram language models instead of cloze estimations. One argument was that language models and human readers are sensitive to distinct aspects of the previous linguistic context and that the interpretability and limited causal inference of language models are substantial downfalls. However, language models have become more powerful in causal inference and provide a more easily interpretable measure of predictability than does cloze. Additionally, contextualized word representations show that the previous linguistic context can be better captured by the state-of-the-art language models than by simpler architectures such as n-gram models. More importantly, neural networks allow for internal (e.g. architecture, representations) and external (e.g. input and output) probing: when certain input or architectural features can be associated with hypotheses about cognition, testing whether these features give rise to observed model behaviour can help adjudicate among different mechanistic explanations [ 24 ]. All in all, language models show good potential to be a valuable tool for investigating higher-level processing in reading. Combining language models, which are built with engineering goals in mind, with models of human cognition, might be a powerful method to test mechanistic accounts of reading comprehension. The current study is the first to apply this methodological strategy.
Finally, we emphasize that the LLM’s success is likely not only a function of the LLM itself, but also of the way in which its outputs are brought to bear in the computational model. The cognitive mechanism that we proposed, in which predictions gradually affect multiple words in parallel, may align better with LLMs than with cloze norms, because the outputs of the former are based on a continuous consideration of multiple words in parallel, while the outputs of the latter may be driven by a more serial approach. More investigation is needed as to what extent the benefit of LLMs is independent of the cognitive theory into which it is embedded. Comparing the effect of LLM-derived predictability in other models of reading, especially serial ones (e.g. E-Z Reader) could provide a clearer understanding of the generalizability of such approach.
Another potential venue for future investigations is whether transformer-based LLMs can account for early and late cognitive processes during reading by varying the size of the context window of the LLM. Hofmann et al. [ 11 ] have investigated a similar question, but using language model architectures which differ in how much of the context is considered, without including the transformer-based architecture nor performing reading simulations. We emphasize that such investigation would require careful thinking on how to align the context window of the LLM with that of the model of reading simulation. Follow-up work may address such gap.
The optimal method to investigate language comprehension may be by combining the ability of language models to functionally capture higher-order language cognition with the ability of cognitive models to mechanically capture low-order language perception. Computational models of reading, and more specifically, eye-movement control in reading, are built as a set of mathematical constructs to define and test explanatory theories or mechanism proposals regarding language processing during reading. As such, they are more interpretable and more resembling of theoretical and neurobiological accounts of cognition than LLMs. However, they often lack functional generalizability and accuracy. In contrast, large language models are built to efficiently perform natural language processing tasks, with little to no emphasizes on neurocognitive plausibility and interpretability. Interestingly, despite the reliance on performance over explanatory power and cognitive plausibility, LLMs have been shown to capture various aspects of natural language, in particular at levels of cognition considered higher order by brain and language researchers (e.g. semantics and discourse) and which models of eye-movement control in reading often lack. This remarkable ability of LLMs suggests that they offer a promising tool for expanding cognitive models of reading.
Eye-tracking and cloze norming
We use the full cloze completion and reading time data from the Provo corpus [ 29 ]. This corpus consists of data from 55 passages (2689 words in total) with an average of 50 words (range: 39–62) and 2.5 sentences (range: 1–5) per passage, taken from various genres, such as online news articles, popular science and fiction (see (a) below for an example passage). The Provo corpus had several advantages over other corpora; Sentences are presented as part of a multi-line passage instead of in isolation [ 47 ], which is closer to natural, continuous reading. In addition, Provo provides predictability norms for each word in the text, instead of only the final word [ 48 ], which is ideal for studies in which every word is examined. Finally, other cloze corpora tend to contain quite many constrained contexts (which are actually rare in natural reading), while this corpus provides a more naturalistic cloze probability distribution [ 29 ].
- There are now rumblings that Apple might soon invade the smart watch space, though the company is maintaining its customary silence. The watch doesn’t have a microphone or speaker, but you can use it to control the music on your phone. You can glance at the watch face to view the artist and title of a song.
In an online survey, 470 participants provided a cloze completion to each word position in each passage. Each participant was randomly assigned to complete 5 passages, resulting in 15 unique continuations filled in by 40 participants on average. All participants were English native speakers, ages 18–50, with at least some college experience. Another 85 native English-speaking university students read the same 55 passages while their eyes were tracked with a high-resolution, EyeLink 1000 eye-tracker.
The cloze probability of each continuation in the upcoming word position was equivalent to the proportion of participants that provided the continuation in the corresponding word position. Since the number of participants completing a sequence was a maximum of 43, the minimum cloze probability of a continuation was 0.023 (i.e. if each participant would give a different continuation). Words in a passage which did not appear among the responded continuations received cloze probability of 0. The cloze probabilities of each word in each passage and the corresponding continuations were used in the model to pre-activate each predicted word, as further explained in the sub-section “Predictability Implementation” under Methods.
The main measure of interest in this study is eye movements. During reading, our eyes make continuous and rapid movements, called saccades , separated by pauses in which the eyes remain stationary, called fixations . Reading in English consists of fixations of about 250ms on average, whereas a saccade typically lasts 15-40ms. Typically, about 10–15% are saccades to earlier parts of the text, called regressions , and about two thirds of the saccades skip words [ 49 ].
The time spent reading a word is associated with the ease of recognizing the word and integrating it with the previously read parts of the text [ 49 ]. The fixation durations and saccade origins and destinations are commonly used to compute word-based measures that reflect how long and how often each word was fixated. Measures that reflect early stages of word processing such as lexical retrieval include (i) skipping rate, (ii) first fixation duration (the duration of the first fixation on a word), and (iii) gaze duration (the sum of fixations on a word before the eyes move forward). Late measures include total reading time (iv) and (v) regression rate and are said to reflect full syntactic and semantic integration [ 50 ]. Facilitatory effects of word predictability are generally evidenced in both early measures and late measures: that is, predictable words are skipped more often and read more quickly [ 27 ].
The measures of interest readily provided in the eye-tracking portion of the corpus were first fixation duration, gaze duration, total reading time, skipping likelihood and regression likelihood. Those measures were reported by the authors to be predictable from the cloze probabilities, attesting the validity of the data collected. We refer the reader to [ 29 ] for more details on the corpus used.
Language models
Language model probabilities were obtained from two transformer-based language models: the smallest version available of the pre-trained LLaMA [ 31 ] (7 billion parameters, 32 hidden layers, 32 attention heads, 4096 hidden dimensions and 32k vocabulary size); and the smallest version of the pre-trained GPT-2 [ 30 ] (124 million parameters, 12 hidden layers, 12 attention heads, 768 hidden dimensions and 50k vocabulary size). Both models were freely accessible through the Hugging Face Transformers library at the time of the study. The models are auto regressive and thus trained on predicting a word based uniquely on its previous context. Given a sequence as input, the language model computes the likelihood of each word in the model’s vocabulary to follow the input sequence. The likelihood values are expressed in the form of logits in the model’s output vector, where each dimension contains the logit of a corresponding token in the model’s vocabulary. The logits are normalized using softmax operation to be between 0 and 1.
Since the language model outputs a likelihood for each token in the model’s vocabulary, we limited the sample to only the tokens with likelihood above a threshold. The threshold was defined according to two criteria: the number of predicted words by the language model should be close to the average number of cloze responses over text positions, and the threshold value should be sufficiently low in order to capture the usually lower probabilities of language models. We have attempted a few threshold values (low = 0.001, medium-low = 0.005, medium = 0.01, medium-high = 0.05, and high = 0.1). The medium threshold (0.01) provided the closest number of continuations and average top-1 predictability estimate to those of cloze. For example, using the medium threshold on GPT-2 predictions provided an average of approximately 10 continuations (range 0–36) and an average predictability of 0.29 for the top-1 prediction, which was the closest to the values from cloze (average of 15 continuations ranging from 0 to 38, and top-1 average predictability of 0.32). Low and medium-low provided a much higher number of continuations (averages of 75 and 19, ranging up to 201 and 61, respectively), whereas medium-high and high provided too few continuations compared to cloze (average of 2 and 1 continuations, ranging up to 12 and 5, respectively). The medium threshold was also optimal for LLaMA. Note that we have not applied softmax to the resulting sequence of predictability estimates. The highly long tail of predictability estimates excluded (approximately the size of the LLM vocabulary, i.e. ~50k estimates for GPT-2 and ~32k for LLaMA) meant that re-normalizing the top 10 to 15 estimates (the average number of continuations post threshold filtering) would remove most of the variation among the top estimates. For instance, in the first passage the second word position led to likelihoods for the top 12 predictions varying between .056 and .011. Applying softmax resulted in all estimates transformed to .08 when rounded to two decimals. Thus, even though it is common practice to re-normalize after filtering to ensure the values sum to one across different sources, we opted to use predictability estimates without post-filtering re-normalization.
Each sequence was tokenized with the corresponding model’s tokenizer before given as input, since the language models have their own tokenization (Byte-Pair Encoder [ 51 ]) and expect the input to be tokenized accordingly. Pre-processing the tokens and applying the threshold on the predictability values resulted in an average of 10 continuations per word position (range 1 to 26) with LLaMA and an average of 10 continuations per word position (range 1 to 36) with GPT-2. After tokenization, no trial (i.e. Provo passage) was longer than the maximum lengths allowed by LLaMA (2048 tokens) nor by GPT-2 (1024 tokens). Note that the tokens forming the language model’s vocabulary do not always match a word in OB1-reader’s vocabulary. This is because words can be represented as multi-tokens in the language model vocabulary. Additionally, OB1-reader’s vocabulary is pre-processed and limited to the text words plus the most frequent words in a frequency corpus [ 52 ]. 31% of the predicted tokens by LLaMA were not in OB1-reader’s vocabulary and 17% of words in the stimuli are split into multi-tokens in LLaMA’s vocabulary. With GPT-2, these percentages were 26% and 16%, respectively.
To minimize the impact of vocabulary misalignment, we considered a match between a word in the OB1-reader’s lexicon and a predicted token when the predicted token corresponded to the first token of the word as tokenized by the language model tokenizer. For instance, the word “customary” is split into the tokens “custom” and “ary” by LLaMA. If “custom” is among the top predictions from LLaMA, we used the predictability of “custom” as an estimate for the predictability of “customary”. We are aware that this design choice may overestimate the predictability of long words, as well as create discrepancies between different sources of predictability (as different language models have different tokenizers). However, in the proposed predictability mechanism, not only the text words are considered, but also all the words predicted at a given text position (above a pre-defined threshold). Other approaches that aggregate the predictability estimates over all tokens belonging to the word, instead of only the first token, would require computing next-token predictions repeatedly for each different predicted token for each text position, until we assume a word has been formed. To avoid these issues and since the proportion of text words which are split into more than one token by the language models is moderate (17% and 16% from LLaMA and GPT-2, respectively), we adopted the simpler first-token-only strategy.
Model description
In each fixation by OB1-reader (illustrated in Fig 5 ), the input consists of the fixated word n and the words n —1, n + 1, n + 2 and n + 3 processed in parallel. With each processing cycle, word activation is determined by excitation from constituent letters, inhibition from competing words and a passive decay over time.
https://doi.org/10.1371/journal.pcbi.1012117.g005
This diagram was taken from [ 12 ]. The model assumes that attention is allocated to multiple words in parallel, such that recognizing those words can be achieved concurrently. Open bigrams [ 53 ] from three to five words are activated simultaneously, modulated by the eccentricity of each letter, its distance from the focus of attention, and crowding exerted by its neighbouring letters. Each fixation sets off several word activation cycles of 25ms each. Within each cycle, the bigrams encoded from the visual input propagate activation to each lexicon word they are in. The activated words with bigram overlap inhibit each other. Lexical retrieval only occurs when a word of similar length to the word in the visual input reaches the recognition threshold, which depends on its frequency. Initiating a saccade is a stochastic decision, with successful word recognition increasing the likelihood of moving the “eyes”, that is, the letter position where the fixation point is simulated in the text. Word recognition also influences the size of the attention window, by increasing the attention window when successful. Once the saccade is initiated, the most visually salient word within the attention window becomes the saccade’s destination. With the change in the location of fixation, the activation of words no longer in the visual input decays, while words encoded in the new visual input receive activation.
The combinations of letters activate open bigrams, which are pair of letters within the same word and, in OB1-reader, up to three letters apart. The activation of an open bigram O ij thus equals the square root of the visual input v i and v j of the constituent letters i and j , as implemented in the original OB1-reader.
Predictability implementation
https://doi.org/10.1371/journal.pcbi.1012117.t001
With the described implementation, predictive activation exerts a facilitatory effect on word recognition through faster reading times and more likelihood of skipping. Words in the text which are predicted receive additional activation prior to their fixation, which allows for the activation threshold for lexical access to be reached more easily. Consequently, the predicted word may be recognized more readily and even before fixation. In addition, higher predictability may indirectly increase the likelihood of skipping, because more successful recognition in the model leads to a larger attention window. In contrast, activation of predicted words may exert an inhibitory effect on the recognition of words with low predictability, because activated, predicted words inhibit the words that they resemble orthographically, which may include the word that was truly in the text.
Reading simulations
The simulation input consisted of each of the 55 passages from the Provo corpus, with punctuation and trailing spaces removed and words lower-cased. The output of each model simulation mainly consisted of reading times, skipping and regression computed per simulated fixation. For evaluation, we transform the fixation-centered output into word-centered data, where each data point aggregates fixation information of each word in each passage. Using the word-centered data, we computed the eye-movement measures for each word in the corpus. Since the eye movement measures vary on scale (milliseconds for durations and likelihood for skipping and regression), we standardized the raw differences between simulated and human values based on the respective human average. Root Mean Square Error (RMSE) was then calculated between the simulated word-based eye-movement measures and the equivalent human data per simulation, and Wilcoxon t-test was run to compare the RMSE across conditions.
Finally, we compared the error in each condition across different word-based linguistic variables (length, frequency, predictability, part-of-speech category and position) to better understand the differences in performance. This analysis consisted of binning (20 bins of equal width) the continuous linguistic variables (length, frequency, predictability and position), computing the RMSE in each simulation for each bin, and averaging the RMSE for each bin over simulations. Part-of-speech tags were binned into three categories: content, consisting of the Spacy part-of-speech tags noun (NOUN), verb (VERB), adjective (ADJ), adverb (ADV) and proper noun (PROPN); function, consisting of the Spacy part-of-speech tags auxiliary (AUX), adposition (ADP), conjunction (CONJ, SCONJ, CCONJ), determiner (DET), particle (PART), and pronoun (PRON); and other, consisting of numeral (NUM), interjection (INTJ) and miscellaneous (X). See Fig 6 for an overview of the methodology. The code to run and evaluate the model simulations is fully available on the GitHub repository of this project.
(a) In OB1-reader, a model of eye-movements in reading, word predictability is computed for every word predicted in a condition (GPT-2, LLaMA, cloze) in each position in the current stimulus. The predictability of each predicted word ( pred w) is weighted by the predictability of the previous word ( pred w-1) and a free parameter ( c 4), and added to its current activation ( S w) at each cycle until recognition. The number of processing cycles by OB1-reader to achieve recognition determine the word’s reading time. (b) Eye movements simulated by the model are compared to the eye movements from the Provo Corpus by computing RMSE scores.
https://doi.org/10.1371/journal.pcbi.1012117.g006
Supporting information
S1 fig. relation between predictability and first fixation duration..
Predictability is computed from cloze norms, gpt2 or llama, and is displayed as a function of the weight attached to predictability in word activation (low, medium or high). First fixation duration is displayed in milliseconds.
https://doi.org/10.1371/journal.pcbi.1012117.s001
S2 Fig. Root Mean Square Error (RMSE) for first fixation durations in relation to word variables.
The word variables are frequency, length, predictability, and the position of the word in the passage (word_id).
https://doi.org/10.1371/journal.pcbi.1012117.s002
S3 Fig. Relation between word variables and first fixation duration.
The word variables are frequency, length, predictability, the position of the word in the passage (word_id), and type (function, content, or other). First fixation duration is displayed in milliseconds.
https://doi.org/10.1371/journal.pcbi.1012117.s003
S4 Fig. Relation between predictability and gaze duration.
Predictability is computed from cloze norms, gpt2 or llama, and is displayed as a function of the weight attached to predictability in word activation (low, medium or high). Gaze duration is displayed in milliseconds.
https://doi.org/10.1371/journal.pcbi.1012117.s004
S5 Fig. Root Mean Square Error (RMSE) for gaze durations in relation to word variables.
https://doi.org/10.1371/journal.pcbi.1012117.s005
S6 Fig. Relation between word variables and gaze duration.
The word variables are frequency, length, predictability, the position of the word in the passage (word_id), and type (function, content, or other). Gaze duration is displayed in milliseconds.
https://doi.org/10.1371/journal.pcbi.1012117.s006
S7 Fig. Relation between predictability values and skipping likelihood.
Predictability is computed from cloze norms, gpt2 or llama, and is displayed as a function of the weight attached to predictability in word activation (low, medium or high).
https://doi.org/10.1371/journal.pcbi.1012117.s007
S8 Fig. Root Mean Square Error (RMSE) for skipping likelihood in relation to word variables.
https://doi.org/10.1371/journal.pcbi.1012117.s008
S9 Fig. Root Mean Square Error (RMSE) for each eye movement measure in relation to word type (content, function or other).
https://doi.org/10.1371/journal.pcbi.1012117.s009
S10 Fig. Relation between word variables and skipping likelihood.
The word variables are frequency, length, predictability, the position of the word in the passage (word_id), and type (function, content, or other).
https://doi.org/10.1371/journal.pcbi.1012117.s010
S11 Fig. Relation between predictability and total reading time.
Predictability is computed from cloze norms, gpt2 or llama, and is displayed as a function of the weight attached to predictability in word activation (low, medium or high). Total reading time is displayed in milliseconds.
https://doi.org/10.1371/journal.pcbi.1012117.s011
S12 Fig. Root Mean Square Error (RMSE) for total reading time in relation to word variables.
https://doi.org/10.1371/journal.pcbi.1012117.s012
S13 Fig. Relation between word variables and total reading time.
The word variables are frequency, length, predictability, the position of the word in the passage (word_id), and type (function, content, or other). Total reading time is displayed in milliseconds.
https://doi.org/10.1371/journal.pcbi.1012117.s013
S14 Fig. Relation between predictability and regression likelihood.
https://doi.org/10.1371/journal.pcbi.1012117.s014
S15 Fig. Root Mean Square Error (RMSE) for regression likelihood in relation to word variables.
https://doi.org/10.1371/journal.pcbi.1012117.s015
S16 Fig. Relation between word variables and regression likelihood.
https://doi.org/10.1371/journal.pcbi.1012117.s016
S17 Fig. Distribution of predictability values by each predictor.
https://doi.org/10.1371/journal.pcbi.1012117.s017
S1 Appendix. Accuracy and Correlation Analyses.
https://doi.org/10.1371/journal.pcbi.1012117.s018
- View Article
- PubMed/NCBI
- Google Scholar
- 4. Smith N, Levy R. Cloze but no cigar: The complex relationship between cloze, corpus, and subjective probabilities in language processing. In: Proceedings of the Annual Meeting of the Cognitive Science Society. 2011.
- 12. Reichle ED. Computational models of reading: A handbook. Oxford University Press; 2021.
- 31. Touvron H, Lavril T, Izacard G, Martinet X, Lachaux MA, Lacroix T, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:230213971. 2023;
- 32. Wilcox EG, Meister CI, Cotterell R, Pimentel T. Language Model Quality Correlates with Psychometric Predictive Power in Multiple Languages. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 2023. p. 7503–11.
- 35. Goodkind A, Bicknell K. Predictive power of word surprisal for reading times is a linear function of language model quality. In: Proceedings of the 8th workshop on cognitive modeling and computational linguistics (CMCL 2018). 2018. p. 10–8.
- 37. De Varda A, Marelli M. Scaling in cognitive modelling: A multilingual approach to human reading times. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers). 2023. p. 139–49.
- 43. Chomsky N. Knowledge of language: Its nature, origin, and use. New York; 1986.
- 46. Goldberg AE. Explain me this: Creativity, competition, and the partial productivity of constructions. Princeton University Press; 2019.
- 51. Sennrich R, Haddow B, Birch A. Neural machine translation of rare words with subword units. arXiv preprint arXiv:150807909. 2015;
Copyright © 2024 AudiologyOnline - All Rights Reserved
- 20Q: Pediatric Speech Recognition Measures - What's Now and What's Next!
Andrea Hillock-Dunn, AuD, PhD
- 20Q with Gus Mueller
- Hearing Evaluation - Children
From the Desk of Gus Mueller
Dr. Raymond Carhart, the father (or grandfather) of audiology obtained his Master of Arts (1934) and Doctor of Philosophy (1936) degrees at Northwestern University. He joined the U.S. Army in the early 1940s and served as Director of the Acoustic Clinic at the Deshon General Hospital in Butler, Pennsylvania. He then returned to Northwestern, where he became Professor of Audiology in 1947. In the years that followed, Northwestern University dominated the academy scene in audiology, with many of the graduates going on to form their own programs, and become the “who’s who” of audiology for the next generation.

Gus Mueller
Although the list of superstar audiology graduates from those days at Northwestern is long, one student from the late 1940s who you do not hear as much about is Harriet Haskins. Like her mentor Carhart, she also was in the military during WWII, working as a WAVE at the Philadelphia Naval Station. Most of her later professional career was spent at Johns Hopkins Hospital in Baltimore. What makes all this relevant for this month’s 20Q is Harriet Haskin’s 1949 unpublished masters thesis from Northwestern: A phonetically balanced test of speech discrimination for children.
The PBK list developed by Haskins has certainly withstood the test of time, but it represents only a small sample of the speech recognition material available for the evaluation of the pediatric patient. To bring us up to date, we bring in an audiologist who works with these patients on a daily basis, and is involved in research regarding the efficiency of these different speech tests.
Andrea Hillock-Dunn, AuD, PhD, is the Associate Director of Pediatric Audiology and an Assistant Professor of Hearing and Speech Sciences at the Vanderbilt Bill Wilkerson Center. Dr. Hillock-Dunn is also involved in the training of AuD students, and is responsible for program administration and development in pediatric audiology. You’re probably familiar with her papers and publications dealing with early hearing detection and intervention, and auditory and audiovisual speech recognition in children with normal hearing and in those who are deaf or hard of hearing.
It’s been nearly 70 years since Harriet Haskins developed the PBK list, but the importance of valid and reliable speech recognition testing with the pediatric patient is as important now as it was then. This excellent 20Q article by Andrea offers guidance regarding how to conduct the testing correctly, reviews which tests are currently available, and provides a glimpse at which speech-related tests we might be using in the future.
Gus Mueller, PhD
Contributing Editor September, 2015
To browse the complete collection of 20Q with Gus Mueller CEU articles, please visit www.audiologyonline.com/20Q
Pediatric Speech Recognition Measures: What’s Now and What’s Next!

Andrea Hillock-Dunn
Learning Objectives
- Readers will be able to explain reasons/rationale for conducting speech recognition testing with children.
- Readers will be able to discuss considerations for selecting appropriate speech recognition testing materials for children.
- Readers will be able to discuss how test and procedural variables impact the results and validity of speech recognition testing in children.
1. Why bother doing speech audiometry in kids at all? I can get everything I need from pure-tone thresholds, right?
Pure-tone thresholds are obviously extremely important, but we gain critical information from speech recognition testing as well. For example, speech testing can: a.) provide a cross-check for behavioral pure-tone data; b.) help quantify benefit from amplification and assist in determining programming and audiologic management decisions (e.g., consideration of alternative devices, FM, need for additional classroom supports, etc.); c.) provide a global metric for monitoring performance over time (sequential appointments); and, d.) identify abnormal system functioning not predicted from the audiogram and possible retrocochlear involvement (anomaly).
2. So it may be helpful to do unaided speech testing during an initial hearing evaluation to rule out some particular pathologies that need special attention?
That’s correct! Patients with Auditory Neuropathy Spectrum Disorder (ANSD) provide an excellent example of the potential disconnect between pure-tone detection ability and speech recognition. In a study by Rance and colleagues (1999), researchers found no significant correlation between closed-set speech recognition and behavioral thresholds in a group of ten children with ANSD. Berlin and colleagues (2010) also described pure-tone detection and word recognition abilities of children with ANSD between 4 and 18 years of age. Although pure-tone averages (PTAs) varied widely from near-normal to profound hearing loss, speech recognition ability was generally poor, especially in noise. Whereas 25 of 68 patients were able to complete open-set word recognition testing in quiet, only 5 could be tested in noise due to floor effects. Speech recognition testing may prove useful in detecting ANSD, especially testing in noise, where less overlap exists between performance of children with ANSD and cochlear loss (compared to quiet). If ANSD is suspected, speech scores should be considered in conjunction other audiologic findings such as OAEs, acoustic reflexes and ABR.
3. What about children with cochlear hearing loss? What does speech audiometry tell me that pure tone thresholds don’t in those cases?
In addition to identifying relatively rare retrocochlear disorders, speech testing may provide a more accurate predication of a child’s functional hearing abilities than the audiogram. Some of our recent data suggests that the audiogram, and even the traditional speech recognition measures commonly performed clinically, may not be maximally sensitive to receptive communication challenges of children with sensorineural hearing loss (SNHL) who use hearing aids (Hillock-Dunn, Taylor, Buss, & Leibold, 2015).
4. Really?
Yes, here are some details. We measured masked speech recognition in 16 school-age hearing aid users using an aided, adaptive spondee recognition task administered in two masker conditions: a.) steady noise, and b.) two-talker speech (Hillock-Dunn et al., 2015). We also pulled data from each child’s most recent clinical evaluation (i.e., PTA, SRT, better ear unaided Phonetically Balanced Kindergarten [PBK] word score in quiet), and analyzed parent responses on two subscales of the Children’s Abbreviated Profile of Hearing Aid Performance questionnaire (Kopun & Stelmachowicz, 1998). While traditional clinical measures were correlated with speech recognition performance in noise, none of the clinical measures were correlated with the aided spondee task in two-talker speech. Moreover, only performance in the two-talker speech masker was correlated with parent-reported speech recognition difficulties in real-world situations. We believe that these findings suggest that traditional clinical measures such as PTA, SRT (quiet) and word recognition (quiet) may underestimate the communication challenges of children with SNHL.
5. Why do you think that it was the SRT with the two-talker competing message that correlated with real world performance?
Not all competing background sounds are created equal! “Energetic” maskers impede speech recognition by causing peripheral interference via overlapping excitation patterns on the basilar membrane. Contrastingly, “informational” maskers are believed to produce both peripheral and central effects. They are associated with larger decrements in performance than peripheral effects and reflect difficulty disentangling the target from the background speech. An example of an energetic masker is fan noise or speech-shaped noise, and an example of an informational masker is competing speech produced by a small number of talkers.
In our study, the informational masker consisted of two women reading children’s books and the signal was a spondee. The spectrotemporal characteristics of the signal and masker were highly similar since both were speech, and the content in the masking stream was meaningful, making it especially detrimental to speech recognition. In such situations the listener must segregate the target from the masking speech and selectively attend to the signal while ignoring the background sound. A classic example of this challenge in everyday life is when a child is struggling to hear his or her teacher because of the chatter of other children in the classroom.
6. Classrooms are really rough, especially for younger children. Is a multi-talker babble even worse than the two-talker scenario?
Surprisingly, more talkers do not necessarily make the listening task harder when masker spectra and intensity levels are equated. Studies by Freyman, Balakrishnan, & Helfer ( 2004 ) and others show a nonlinear effect of talker number on masker effectiveness. While the SNR required for sentence recognition accuracy increases between 1 and 2 talkers, there’s generally a decline in masker difficulty as you move from 2 to 6 talkers, with it leveling off thereafter.
7. Why would it level off?
As you add talkers, the masking speech stream becomes more acoustically similar to noise. At some point, the further addition of talkers has minimal influence because the stimulus is already noise-like, and the perceptual or informational masking effect is negligible.
8. This all sounds very interesting, but complex maskers like that are not available in my clinic. That’s why I do my speech recognition testing in quiet.
There are commercially available speech-in-noise tests that can be used clinically with children such as the Words-in-Noise test (WIN; Wilson, 2003) and Bamford-Kowal-Bench Speech-in-Noise test (BKB-SIN; Etymōtic Research, 2005; Bench, Kowal, & Bamford, 1979). For a more comprehensive list of pediatric speech-in-noise measures and test considerations, the interested reader is referred to Table 1 of the article, "Speech perception in noise measures for children: A critical review and case studies" (Schafer, 2010).
9. Speaking of speech stimuli, can you talk about which speech tests I should use? How do I know what to use with a particular patient?
Great question! Choosing an appropriate word list is critical, and different tests are normed on different populations. A good starting point would be to consider the target population for which each test was developed and whether there is published data to which you can compare an individual child’s performance.
Also consider patient-specific factors such as expressive speech and language competency, cognitive development, etc. For example, you might choose a closed-set (point-to-picture) task for an older child with oral-motor issues or severe articulation deficits that could impact scoring accuracy on an open-set test requiring a verbal response. Likewise, the material selected should be appropriate for patients’ cognitive as opposed to chronological age. For example, a 16-year-old patient functioning at the developmental level of a 5-year-old should be tested with materials developed for younger children (e.g., PBK-50 words) as opposed to those for adolescents or adults (e.g., Northwestern University Auditory Test No. 6 [NU-6]).
10. Okay, so where can I find a speech materials hierarchy to help me determine which is a good test to start with for a given patient?
To my knowledge, currently there is no published hierarchy with a suggested test progression ordered by level of difficulty. However, Ryan McCreery and his colleagues developed an aided speech recognition battery for use with children 2 – 9 years of age who were enrolled in the Outcomes in Children with Hearing Loss (OCHL) multi-center grant. The test battery was described in a 2013 poster presented at the American Auditory Society meeting in Phoenix, AZ. With the permission of McCreery and colleagues, I’ve provided a sneak peek at their battery below.
OCHL Speech Hierarchy
- Test of auditory skills involving audiovisual presentation of 10-item lists of words familiar to most 2-year olds. Contains two parts: 1) Child repeats a word spoken by mom or examiner and utterance is scored on phoneme and word level, and 2) Child identifies word spoken from closed-set of 3 pictures.
- Closed-set, picture pointing task comprised of 1-, 2- or 3-syllable targets used to assess detection, pattern perception and word identification ability. Auditory-only presentation format. Low-verbal and standard options depending on developmental ability of child.
- Fifty-item, open-set test comprised of monosyllabic words selected based on language of typical 3-5 year-olds. Auditory-only presentation format. Items in “Easy” versus “Hard” lists differ according to the frequency with which they are produced in the English language and their acoustic-phonetic similarity.
- Fifty-item, open-set test including phonemically-balanced monosyllabic words that are based on vocabulary of normal hearing kindergarten children. Auditory-only presentation format.
- Ten-item, open-set test comprised of lists of consonant-vowel-consonant words administered in quiet or noise. Separate word and phoneme (consonant and vowel) scoring increases the number of data points. Although initially developed for adults, this has been successfully administered in children (McCreery et al., 2010).
Please note that this hierarchy is comprised of only word-level stimuli. Consider implementing sentence-level measures and testing in noise when children begin approaching ceiling on LNT, around 4 or 5 years of age. As I mentioned earlier, the Bamford-Kowal-Bench Speech-in-Noise Test (BKB-SIN, Etymotic Research, 2005) based on the Bamford-Kowal-Bench sentences (Bench, Kowal, & Bamford, 1979) has been normed on children as young as 6 years of age.
11. That’s helpful. So, do I follow the ages to know when to bump a child to a harder test, or do I wait until they get 100% correct on the test I’m using?
It depends on the number of words you administer, but for a 25-word list you should advance the child to a harder test once they achieve an accuracy score of roughly 85% or greater. Critical difference values based on adult data indicate that for 25 words, a score of 84% is not significantly different from 96% ( Thornton & Raffin , 1978 ). Children generally show greater score variability than adults, which results in wider confidence intervals. That means they need an even bigger score difference for there to be a significant change across conditions or over time!
12. Now I’m confused about how to report speech scores. Should I still label scores excellent, good, fair or poor?
That categorization is somewhat arbitrary and should probably be thrown out to avoid confusing patients and providers. As William Brandy states in the Handbook of Clinical Audiology , there is variability in labeling convention and differences across speech materials and test administration (e.g., presentation level) that can affect the comparability of scores ( p.107, Katz , 2002 ). For example, using some scales a left ear speech recognition score of 72% might be categorized as “fair” and a right ear score of 84% as “good” even though they aren’t significantly different from one another (even for a 50-word list).
13. With those categories I was using 12% is kind of a big deal. Explain again why you’re saying scores of 72% and 84% are equivocal. How are you defining a significant score difference?
The criterion for calling a difference “significant” depends on the number of words or items presented in the speech recognition test and the test score ( Raffin & Thornton , 1980 ; Thornton & Raffin, 1978 ). Thornton and Raffin (1978, 1980) published reference tables showing critical difference values for speech recognition scores derived to 10-, 25-, 50- and 100-word lists (assuming a 0.05 confidence level, meaning that differences this big or bigger could occur by chance 5 times per 100) . Returning to the example above, 72% is not significantly different from 84% for 25- or 50- word lists (p > 0.05). This difference is significant, however, for a 100 word list!
But, it’s not quite that simple. I mentioned that it’s not just about the number of words, but also performance score. So you need a larger critical difference at 50% correct, for example, than near ceiling or floor (i.e., the tails of the distribution) where the variability is reduced.
14. Wait - 100 words …What are you thinking?! Children can hardly sit still for 10 words per ear!
So, there is a test that you might try with older children and adolescents that could end up being only 10-words per ear. If you simply want to determine whether or not speech understanding is impaired consider the NU-6 word test ordered by difficulty ( Hurley & Sells, 2003 ). In that test, Hurley and Sells (2003) took the hardest NU-6 words and determined that if you administer those first and a patient (adult) gets 9/10 correct, word recognition is expected to be adequate and the test can be terminated. If they get > 1 word wrong, administer the next 15 words and so on. Similar abbreviated word recognition screening lists are also available with other materials (e.g., CID W-22 words) ( Runge & Hosford- Dunn , 1985 ). You might try this with children 10 years and older. Remember, however, and this is important—these tests are only valid if you use the exact same recording that was used when the word difficulty was determined by the researchers. For the commonly used NU-6 (used by Hurley and Sells), there is a recording available from Auditec of St. Louis with the words ordered appropriately.
15. Okay, thanks. But are most of the tests for younger kids especially long?
There are a number of pediatric speech recognition tests available (some which are included in the hierarchy above) that are comprised of fewer than 50 (and sometimes even 25) words. For example, the CASPA test has lists of only 10 words, but they can be scored phonemically, which increases the number of scored items to 30 (3 phonemes per target word). For tests with longer word lists, if abridged (e.g., ½) lists are used, it is important to recognize the impact on score interpretation and comparison. But, I can sympathize with you and appreciate the need for speed, especially with the super wiggly ones!
16. Can I use monitored live voice (MLV) to speed things up? That’s much faster than using recorded words.
Well, I hate to tell you, but as stated nicely by Hornsby and Mueller (2013), “the words are not the test” . It shouldn’t take much longer to use recorded materials, and your results will be more accurate and meaningful. Numerous studies have cited the drawbacks of live-voice presentation, which has been shown to be unreliable and limit cross score comparison (e.g., Brandy, 1966; Hood & Poole,1980). Furthermore, Mendell and Owen (2011) showed that the average increase in test time for administering a 50-word NU-6 list in recorded versus monitored live voice (MLV) format was only 49 seconds per ear! For a 25-word list, the difference would be even smaller!
17. What if I just bypass the carrier phrases to speed things up a bit?
That might not be a good idea. A recent study by Bonino et al. (2013) showed a significant carrier-phrase benefit in 5-10 year old children and adults (18-30 years) on an open-set speech recognition task (PBK-50 words) in multitalker babble and two-talker speech, but not speech-shaped noise. Bonino and colleagues theorized that the carrier phrase provided an auditory grouping cue that facilitated release from masking, subsequently improving speech recognition performance.
So, by removing the carrier phrase, you’re potentially making the test harder and limiting your ability to compare to data collected with a carrier phrase. If you do choose to adapt tests in such a way, document any change(s) to test administration so that it may be recreated later so that an individual’s scores might be compared over time.
18. Y ou’re telling me that I should always use recorded stimuli, present a lot of words, and always use carrier phrases. At least my VRA testing will still be fairly speedy.
Not so fast. Maybe you could add a little more depth to your VRA testing. Have you heard about Visual Reinforcement Infant Speech Discrimination (VRISD) ( Eilers , Wilson, & Moore, 1977 ) or Visual Reinforcement Assessment of the Perception of Speech Pattern Contrasts (VRA-SPAC) ( Eisenberg, Martinez, & Boothroyd, 2004 ). These procedures measure discrimination of speech feature contrasts using a VRA-style habituation procedure. Basically, a speech sound (e.g., /a/) is played repeatedly until the infant habituates (stops turning) to it. Then, the baby is trained to respond to a deviant, contrasting speech sound (e.g., /u/) by turning his or her head toward the visual reinforcer in the same fashion as for VRA. This procedure has the potential to provide information about receptive communication ability sooner, and requires no additional audiologic training to administer or score. However, it should be cautioned that not all normal hearing infants can accurately perform the task, and a recent study showed that some contrasts that were differentiated electrophysiologically did not produce a consistent behavioral discrimination response ( Cone , 2014 ).
19. You can measure speech feature discrimination electrophysiologically? How is that possible?
Yes! Speech feature discrimination has been measured with ABR, ASSR and CAEPs. In a recent paper, Cone (2015) reported vowel discrimination in infants using an oddball paradigm (repeating, frequent stimulus = standard; infrequent stimulus = deviant). The CAEP amplitude was greater to the deviant than standard vowel, and there were some correlations between CAEP measures (amp, latency) and behavioral vowel discrimination; however, the relationship between electrophysiologic and behavioral data remains complex.
20. Do you think we might start seeing increased speech testing of infants and toddlers in clinics before too long?
Although CAEP-based and VRA-style speech discrimination testing is not currently in widespread clinical use, they are receiving growing attention. With additional research on test parameters, administration and interpretation, I suspect we’ll begin to see increased clinical implementation. Hopefully, these tools will provide (earlier) insight into the speech recognition capabilities of infants and toddlers, particularly those with atypical retrocochlear or neurological functioning.
I also think we’ll see a growing movement toward the use of more realistic speech recognition materials, such as 2- or 3-talker maskers, in clinical assessment. Hopefully, this will result in more measures that are better able to approximate real-world communication ability, better address specific patient needs, and inform management considerations.
Bench, J., Kowal, A., & Bamford, J. (1979). The BKB (Bamford-Kowal-Bench) sentence lists for partially-hearing children. British Journal of Audiology, 13 (3), 108-112.
Berlin, C.I., Hood, L.J., Morlet, T., Wilensky, D., Li, L., Mattingly, K.R.,...Frisch, S.A. (2010). Multi-site diagnosis and management of 260 patients with auditory neuropathy/dys-synchrony (auditory neuropathy spectrum disorder). International Journal of Audiology, 49 (1), 30-43.
Boothroyd, A. (1999). Computer-assisted speech perception assessment (CASPA): Version.
Brandy, W.T. (1966). Reliability of voice tests of speech discrimination. Journal of Speech, Language, and Hearing Research, 9 (3), 461-465.
Cone, B.K. (2014). Infant cortical electrophysiology and perception of vowel contrasts. International Journal of Psychophysiology, 95 (2),65-76.
Eilers, R.E., Wilson, W.R., & Moore, J.M. (1977). Developmental changes in speech discrimination in infants. Journal of Speech, Language, and Hearing Research, 20 (4), 766-780.
Eisenberg, L.S., Martinez, A.S., & Boothroyd, A. (2004). Perception of phonetic contrasts in infants: Development of the VRASPAC. International Congress Series , 1273 , 364-367.
Ertmer, D., Miller, C., & Quesenberry, J. (2004). T he Open and Closed Set Test [Assessment procedure](Unpublished instrument). West Lafayette, IN: Purdue University.
Freyman, R.L., Balakrishnan, U., & Helfer, K.S. (2004). Effect of number of masking talkers and auditory priming on informational masking in speech recognition. The Journal of the Acoustical Society of America, 115 (5), 2246-2256.
Haskins, J. (1949). A phonetically balanced test of speech discrimination for children (unpublished master's thesis). Northwestern University, Evanston, IL.
Hillock-Dunn, A., Taylor, C., Buss, E., & Leibold, L J. (2015). Assessing speech perception in children with hearing loss: what conventional clinical tools may miss. Ear and Hearing, 36 (2), e57-60.
Hood, J.D., & Poole, J.P. (1980). Influence of the speaker and other factors affecting speech intelligibility. International Journal of Audiology, 19 (5), 434-455.
Hornsby, B., & Mueller, H.G. (2013, July). Monosyllabic word testing: Five simple steps to improve accuracy and efficiency. AudiologyOnline, Article 11978. Retrieved from www.audiologyonline.com
Hurley, R.M., & Sells, J.P. (2003). An abbreviated word recognition protocol based on item difficulty. Ear and Hearing, 24 (2), 111-118.
Katz, J. (Ed.). (2002). Handbook of clinical audiology (5 ed.). Baltimore, MD: Lippincott, Williams, and Wilkins.
Kirk, K.I., Pisoni, D.B., & Osberger, M.J. (1995). Lexical effects on spoken word recognition by pediatric cochlear implant users. Ear and Hearing, 16 (5), 470-481.
Kopun, J G., & Stelmachowicz, P.G. (1998). Perceived communication difficulties of children with hearing loss. American Journal of Audiology, 7 (1), 30-38.
McCreery, R., Ito, R., Spratford, M., Lewis, D., Hoover, B., & Stelmachowicz, P.G. (2010). Performance-intensity functions for normal-hearing adults and children using CASPA. Ear and Hearing, 31 (1), 95.
McCreery, R.W., Walker, E., Spratford, M., Hatala, E., & Jacobs, S. (2013). Aided speech recognition in noise for children with hearing loss . Poster presentation at the meeting of the American Auditory Society, Phoenix, AZ.
Mendel, L.L., & Owen, S.R. (2011). A study of recorded versus live voice word recognition. International Journal of Audiology, 50 (10), 688-693.
Moog, J.S., & Geers, A.E. (1990). Early speech perception test. St Louis, MO: Central Institute for the Deaf .
Raffin, M.J., & Thornton, A.R. (1980). Confidence levels for differences between speech-discrimination scores. A research note. Journal of Speech and Hearing Research, 23 (1), 5-18.
Rance, G., Beer, D.E., Cone-Wesson, B., Shepherd, R.K., Dowell, R. C., King, A. M.,..Clark, G.M. (1999). Clinical findings for a group of infants and young children with auditory neuropathy. Ear and Hearing, 20 (3), 238.
Runge, C.A., & Hosford-Dunn,H. (1985). Word recognition performance with modified CID W-22 word lists. Journal of Speech and Hearing Research, 28 (3), 355-362.
Schafer, E. (2010). Speech perception in noise measures for children: A critical review and case studies . Journal of Educational Audiology,16, 4-15.
Thornton, A.R., & Raffin, M.J. (1978). Speech-discrimination scores modeled as a binomial variable. Journal of Speech and Hearing Research , 21 (3), 507-518.
Wilson, R.H. (2003). Development of a speech-in-multitalker-babble paradigm to assess word-recognition performance. Journal of the American Academy of Audiology, 14 (9), 453-470.
Cite this Content as:
Hillock-Dunn, A. (2015, September). 20Q: pediatric speech recognition measures - what's now and what's next! AudiologyOnline , Article 14981. Retrieved from https://www.audiologyonline.com.

Andrea Hillock-Dunn, AuD, PhD is an Assistant Professor of Hearing and Speech Sciences and Associate Director of Pediatric Audiology at the Vanderbilt Bill Wilkerson Center. Her clinical and research interests include diagnosis and treatment of childhood hearing loss, newborn hearing screening, and auditory and audiovisual speech perception in children with normal and impaired hearing. Dr. Hillock-Dunn has a BS degree from Syracuse University, AuD from Northwestern University, PhD from Vanderbilt University and completed her postdoctoral training at the University of North Carolina in Chapel Hill.
Related Courses
20q: update on cochlear implants: hearing preservation, single-sided deafness, and personalized fitting, course: #38753 level: intermediate 2 hours, 20q: newborn hearing screening brochures - changes are needed, course: #37989 level: intermediate 1 hour, 20q: auditory issues in children with autism spectrum disorder - audiologists wanted, course: #36770 level: intermediate 1 hour, 20q: preschool hearing screening is essential for early identification of childhood hearing loss, course: #29394 level: introductory 1 hour, 20q: extended high frequency hearing loss - translating science into clinical practice, course: #37590 level: intermediate 1 hour.
Our site uses cookies to improve your experience. By using our site, you agree to our Privacy Policy .
IMAGES
VIDEO
COMMENTS
The critical difference range for a 50-word list for a score of 44% is from 26% to 62%. So now, by using 50 words, we are confident that our patient's word recognition scores really are different—the score of the opposite ear, 68%, falls outside of the critical range. They are not similar just due to chance. 27.
Word Recognition Score (WRS) tests assess a person's ability to recognize single-syllable words. An individual is able to identify a list of words presented at the speech recognition threshold of 30 dBHL with the help of this test. A good score on the WRS test indicates that the individual is able to recognize the majority of the words that ...
NU-6 list Words. Comparison of Word Familiarity: Conversational Words v. NU-6 list Words. This study was conducted to compare the Northwestern University Auditory Test No.6 (NU-6) word list, to common words used today, to assess whether the NU-6 lists represent familiar and common words used in 2002. Suprathreshold speech-recognition testing ...
The critical difference range for a 50-word list for a score of 44% is from 26% to 62%. So now, by using 50 words, we are confident that our patient's word recognition scores really are different—the score of the opposite ear, 68%, falls outside of the critical range. They are not similar just due to chance.
Discrimination Testing. The purpose of Speech Discrimination (SD) testing (also called Word Recognition (WR) testing) is to determine how well you hear and understand speech when the volume is set at your Most Comfortable Level (MCL). To do this, your audiologist says a series of 50 single-syllable phonetically-balanced (PB) words.
cessary to expand the test to 25 words. The patient may miss a maximum of three words in. er to pass the 25-word screening test. This result would also be indicative of. 96% or better score on a 50-word list. Finally, if more than three words are m. sed, the full 50-word list is required. In the Hurley and Sells study, approximately 25% of ...
One of the key variables to consider when performing word recognition testing is at what level to present the words. A common practice is setting the loudness of the words at 30 to 40 dB above the patient's Speech Reception Threshold (SRT), known as "SRT + 30 or +40 dB." Some also set the level to the patient's subjective "Most Comfortable ...
The word lists most commonly used in the US for WRS are the NU-6 and CID-W22 word lists. In word recognition score testing, you present an entire word list to the test subject at a single intensity and score each word based on whether the subject can correctly repeat it or not. The results are reported as a percentage.
The AB short word list test first devised by Arthur Boothroyd in 1968, is widely used in the UK as a speech recognition test and for rehabilitation. The Parrot AB test consists of 8 word lists, with each list containing 10 words. Each word has three phonemes constructed as consonant - vowel - consonant with 30 phonemes, 10 vowels and 20 ...
The left channel has List 7 of the Maryland CNC words; the right channel has List 4A of the CID W-22 words. The ISI is 4.2 s with 108 s/track. Tracks 11 and 12. The left channel has List 9 of the Maryland CNC words; the right channel has the Rush Hughes recording (Goetzinger, 1972; Heckendorf, et al., 1997) of List 8B of the Harvard PB-50 words ...
The word recognition test is a hearing test that is used to measure a person's ability to understand speech. The test is typically administered by an audiologist. The audiologist will present a list of words to the person being tested and ask them to repeat the words. The number of words that the person correctly repeats is then divided by ...
Word recognition scores (WRS) are used in order to assess a person's ability to understand a word. A patient is presented with a list of unknown single-syllable words at the speech recognition threshold of 30 dBHL. The number of words used in the test determines how the test scores are calculated.
Word Recognition. Instruct the patient that he or she is to repeat the words presented. Using either live voice or recorded speech, present the standardized PB word list of your choice. Present the words at a level comfortable to the patient; at least 30 dB and generally 35 to 50 dB above the 1000 Hz pure tone threshold.
Because 50-word lists take a long time, people often use half-lists or even shorter lists for the purpose of suprathreshold speech recognition testing. Let's look into this practice a little further. An early study was done by Thornton and Raffin (1978) using the Binomial Distribution Model.
Speech recognition threshold is the preferred term because it more accurately describes the listener's task. Spondaic words are the usual and recommended test material for the speech recognition threshold, Spondaic words are two-syllable words with equal stress on both syllables. It should be noted that other test materials can be used.
How Speech Testing Is Done. The audiologist will say words to you through headphones, and you will repeat the words. The audiologist will record the softest speech you can repeat. You may also need to repeat words that you hear at a louder level. This is done to test word recognition. Speech testing may happen in a quiet or noisy place.
Speech discrimination ability is typically measured as a percentage score. Request an Appointment. 443-997-6467 Maryland. 855-695-4872 Outside of Maryland. +1-410-502-7683 International. Find a Doctor. Speech audiometry involves two tests: one checks how loud speech needs to be for you to hear it and the other how clearly you can understand ...
AMERICAN JOURNAL OF SPEECH-LANGUAGE PATHOLOGY (AJSLP) JOURNAL OF SPEECH, LANGUAGE, AND HEARING RESEARCH (JSLHR) LANGUAGE, SPEECH, AND HEARING SERVICES IN SCHOOLS (LSHSS) ... judiciously chosen items can be used to test word recognition without compromising test accuracy. Data were analyzed by comparing each subject's performance on half- and 10 ...
Test level for full list=50 dB HL . 4. If performance improves by 6% or more at the first 6-dB increment, then word recognition is measured using another 25 words at an additional 6- ... (50 word) list. If speech recognition is worse than 94% after presentation of a full list, then a modified performance-intensity function must be ...
After this course, participants will be able to list common pitfalls in the way word recognition testing is often conducted and their potential clinical impact (i.e., why those should be avoided). checkmark. After this course, participants will be able to describe best practices in word recognition testing. Course created on February 17, 2020.
In this article. A phrase list is a list of words or phrases provided ahead of time to help improve their recognition. Adding a phrase to a phrase list increases its importance, thus making it more likely to be recognized. Examples of phrases include: Phrase lists are simple and lightweight: Just-in-time: A phrase list is provided just before ...
The speech recognition threshold (SRT) is the lowest level at which a person can identify a sound from a closed set list of disyllabic words.. The word recognition score (WRS) testrequires a list of single syllable words unknown to the patient to be presented at the speech recognition threshold + 30 dBHL.The number of correct words is scored out of the number of presented words to give the WRS.
The activation A p of w p as a result of w p being predicted from the previous context is defined as follows: where pred w is either the language model or cloze completion probability; pred w-1 is the predictability of the previous word, which varies as a function of recognition of that word; and c 1 is a free-scaling parameter. pred w-1 equals ...
Test of auditory skills involving audiovisual presentation of 10-item lists of words familiar to most 2-year olds. Contains two parts: 1) Child repeats a word spoken by mom or examiner and utterance is scored on phoneme and word level, and 2) Child identifies word spoken from closed-set of 3 pictures.