

The Ultimate Guide To Speech Recognition With Python
Table of Contents
How Speech Recognition Works – An Overview
Picking a python speech recognition package, installing speechrecognition, the recognizer class, supported file types, using record() to capture data from a file, capturing segments with offset and duration, the effect of noise on speech recognition, installing pyaudio, the microphone class, using listen() to capture microphone input, handling unrecognizable speech, putting it all together: a “guess the word” game, recap and additional resources, appendix: recognizing speech in languages other than english.
Watch Now This tutorial has a related video course created by the Real Python team. Watch it together with the written tutorial to deepen your understanding: Speech Recognition With Python
Have you ever wondered how to add speech recognition to your Python project? If so, then keep reading! It’s easier than you might think.
Far from a being a fad, the overwhelming success of speech-enabled products like Amazon Alexa has proven that some degree of speech support will be an essential aspect of household tech for the foreseeable future. If you think about it, the reasons why are pretty obvious. Incorporating speech recognition into your Python application offers a level of interactivity and accessibility that few technologies can match.
The accessibility improvements alone are worth considering. Speech recognition allows the elderly and the physically and visually impaired to interact with state-of-the-art products and services quickly and naturally—no GUI needed!
Best of all, including speech recognition in a Python project is really simple. In this guide, you’ll find out how. You’ll learn:
- How speech recognition works,
- What packages are available on PyPI; and
- How to install and use the SpeechRecognition package—a full-featured and easy-to-use Python speech recognition library.
In the end, you’ll apply what you’ve learned to a simple “Guess the Word” game and see how it all comes together.
Free Bonus: Click here to download a Python speech recognition sample project with full source code that you can use as a basis for your own speech recognition apps.
Before we get to the nitty-gritty of doing speech recognition in Python, let’s take a moment to talk about how speech recognition works. A full discussion would fill a book, so I won’t bore you with all of the technical details here. In fact, this section is not pre-requisite to the rest of the tutorial. If you’d like to get straight to the point, then feel free to skip ahead.
Speech recognition has its roots in research done at Bell Labs in the early 1950s. Early systems were limited to a single speaker and had limited vocabularies of about a dozen words. Modern speech recognition systems have come a long way since their ancient counterparts. They can recognize speech from multiple speakers and have enormous vocabularies in numerous languages.
The first component of speech recognition is, of course, speech. Speech must be converted from physical sound to an electrical signal with a microphone, and then to digital data with an analog-to-digital converter. Once digitized, several models can be used to transcribe the audio to text.
Most modern speech recognition systems rely on what is known as a Hidden Markov Model (HMM). This approach works on the assumption that a speech signal, when viewed on a short enough timescale (say, ten milliseconds), can be reasonably approximated as a stationary process—that is, a process in which statistical properties do not change over time.
In a typical HMM, the speech signal is divided into 10-millisecond fragments. The power spectrum of each fragment, which is essentially a plot of the signal’s power as a function of frequency, is mapped to a vector of real numbers known as cepstral coefficients. The dimension of this vector is usually small—sometimes as low as 10, although more accurate systems may have dimension 32 or more. The final output of the HMM is a sequence of these vectors.
To decode the speech into text, groups of vectors are matched to one or more phonemes —a fundamental unit of speech. This calculation requires training, since the sound of a phoneme varies from speaker to speaker, and even varies from one utterance to another by the same speaker. A special algorithm is then applied to determine the most likely word (or words) that produce the given sequence of phonemes.
One can imagine that this whole process may be computationally expensive. In many modern speech recognition systems, neural networks are used to simplify the speech signal using techniques for feature transformation and dimensionality reduction before HMM recognition. Voice activity detectors (VADs) are also used to reduce an audio signal to only the portions that are likely to contain speech. This prevents the recognizer from wasting time analyzing unnecessary parts of the signal.
Fortunately, as a Python programmer, you don’t have to worry about any of this. A number of speech recognition services are available for use online through an API, and many of these services offer Python SDKs .
A handful of packages for speech recognition exist on PyPI. A few of them include:
- google-cloud-speech
- pocketsphinx
- SpeechRecognition
- watson-developer-cloud
Some of these packages—such as wit and apiai—offer built-in features, like natural language processing for identifying a speaker’s intent, which go beyond basic speech recognition. Others, like google-cloud-speech, focus solely on speech-to-text conversion.
There is one package that stands out in terms of ease-of-use: SpeechRecognition.
Recognizing speech requires audio input, and SpeechRecognition makes retrieving this input really easy. Instead of having to build scripts for accessing microphones and processing audio files from scratch, SpeechRecognition will have you up and running in just a few minutes.
The SpeechRecognition library acts as a wrapper for several popular speech APIs and is thus extremely flexible. One of these—the Google Web Speech API—supports a default API key that is hard-coded into the SpeechRecognition library. That means you can get off your feet without having to sign up for a service.
The flexibility and ease-of-use of the SpeechRecognition package make it an excellent choice for any Python project. However, support for every feature of each API it wraps is not guaranteed. You will need to spend some time researching the available options to find out if SpeechRecognition will work in your particular case.
So, now that you’re convinced you should try out SpeechRecognition, the next step is getting it installed in your environment.
SpeechRecognition is compatible with Python 2.6, 2.7 and 3.3+, but requires some additional installation steps for Python 2 . For this tutorial, I’ll assume you are using Python 3.3+.
You can install SpeechRecognition from a terminal with pip:
Once installed, you should verify the installation by opening an interpreter session and typing:
Note: The version number you get might vary. Version 3.8.1 was the latest at the time of writing.
Go ahead and keep this session open. You’ll start to work with it in just a bit.
SpeechRecognition will work out of the box if all you need to do is work with existing audio files. Specific use cases, however, require a few dependencies. Notably, the PyAudio package is needed for capturing microphone input.
You’ll see which dependencies you need as you read further. For now, let’s dive in and explore the basics of the package.
All of the magic in SpeechRecognition happens with the Recognizer class.
The primary purpose of a Recognizer instance is, of course, to recognize speech. Each instance comes with a variety of settings and functionality for recognizing speech from an audio source.
Creating a Recognizer instance is easy. In your current interpreter session, just type:
Each Recognizer instance has seven methods for recognizing speech from an audio source using various APIs. These are:
- recognize_bing() : Microsoft Bing Speech
- recognize_google() : Google Web Speech API
- recognize_google_cloud() : Google Cloud Speech - requires installation of the google-cloud-speech package
- recognize_houndify() : Houndify by SoundHound
- recognize_ibm() : IBM Speech to Text
- recognize_sphinx() : CMU Sphinx - requires installing PocketSphinx
- recognize_wit() : Wit.ai
Of the seven, only recognize_sphinx() works offline with the CMU Sphinx engine. The other six all require an internet connection.
A full discussion of the features and benefits of each API is beyond the scope of this tutorial. Since SpeechRecognition ships with a default API key for the Google Web Speech API, you can get started with it right away. For this reason, we’ll use the Web Speech API in this guide. The other six APIs all require authentication with either an API key or a username/password combination. For more information, consult the SpeechRecognition docs .
Caution: The default key provided by SpeechRecognition is for testing purposes only, and Google may revoke it at any time . It is not a good idea to use the Google Web Speech API in production. Even with a valid API key, you’ll be limited to only 50 requests per day, and there is no way to raise this quota . Fortunately, SpeechRecognition’s interface is nearly identical for each API, so what you learn today will be easy to translate to a real-world project.
Each recognize_*() method will throw a speech_recognition.RequestError exception if the API is unreachable. For recognize_sphinx() , this could happen as the result of a missing, corrupt or incompatible Sphinx installation. For the other six methods, RequestError may be thrown if quota limits are met, the server is unavailable, or there is no internet connection.
Ok, enough chit-chat. Let’s get our hands dirty. Go ahead and try to call recognize_google() in your interpreter session.
What happened?
You probably got something that looks like this:
You might have guessed this would happen. How could something be recognized from nothing?
All seven recognize_*() methods of the Recognizer class require an audio_data argument. In each case, audio_data must be an instance of SpeechRecognition’s AudioData class.
There are two ways to create an AudioData instance: from an audio file or audio recorded by a microphone. Audio files are a little easier to get started with, so let’s take a look at that first.
Working With Audio Files
Before you continue, you’ll need to download an audio file. The one I used to get started, “harvard.wav,” can be found here . Make sure you save it to the same directory in which your Python interpreter session is running.
SpeechRecognition makes working with audio files easy thanks to its handy AudioFile class. This class can be initialized with the path to an audio file and provides a context manager interface for reading and working with the file’s contents.
Currently, SpeechRecognition supports the following file formats:
- WAV: must be in PCM/LPCM format
- FLAC: must be native FLAC format; OGG-FLAC is not supported
If you are working on x-86 based Linux, macOS or Windows, you should be able to work with FLAC files without a problem. On other platforms, you will need to install a FLAC encoder and ensure you have access to the flac command line tool. You can find more information here if this applies to you.
Type the following into your interpreter session to process the contents of the “harvard.wav” file:
The context manager opens the file and reads its contents, storing the data in an AudioFile instance called source. Then the record() method records the data from the entire file into an AudioData instance. You can confirm this by checking the type of audio :
You can now invoke recognize_google() to attempt to recognize any speech in the audio. Depending on your internet connection speed, you may have to wait several seconds before seeing the result.
Congratulations! You’ve just transcribed your first audio file!
If you’re wondering where the phrases in the “harvard.wav” file come from, they are examples of Harvard Sentences. These phrases were published by the IEEE in 1965 for use in speech intelligibility testing of telephone lines. They are still used in VoIP and cellular testing today.
The Harvard Sentences are comprised of 72 lists of ten phrases. You can find freely available recordings of these phrases on the Open Speech Repository website. Recordings are available in English, Mandarin Chinese, French, and Hindi. They provide an excellent source of free material for testing your code.
What if you only want to capture a portion of the speech in a file? The record() method accepts a duration keyword argument that stops the recording after a specified number of seconds.
For example, the following captures any speech in the first four seconds of the file:
The record() method, when used inside a with block, always moves ahead in the file stream. This means that if you record once for four seconds and then record again for four seconds, the second time returns the four seconds of audio after the first four seconds.
Notice that audio2 contains a portion of the third phrase in the file. When specifying a duration, the recording might stop mid-phrase—or even mid-word—which can hurt the accuracy of the transcription. More on this in a bit.
In addition to specifying a recording duration, the record() method can be given a specific starting point using the offset keyword argument. This value represents the number of seconds from the beginning of the file to ignore before starting to record.
To capture only the second phrase in the file, you could start with an offset of four seconds and record for, say, three seconds.
The offset and duration keyword arguments are useful for segmenting an audio file if you have prior knowledge of the structure of the speech in the file. However, using them hastily can result in poor transcriptions. To see this effect, try the following in your interpreter:
By starting the recording at 4.7 seconds, you miss the “it t” portion a the beginning of the phrase “it takes heat to bring out the odor,” so the API only got “akes heat,” which it matched to “Mesquite.”
Similarly, at the end of the recording, you captured “a co,” which is the beginning of the third phrase “a cold dip restores health and zest.” This was matched to “Aiko” by the API.
There is another reason you may get inaccurate transcriptions. Noise! The above examples worked well because the audio file is reasonably clean. In the real world, unless you have the opportunity to process audio files beforehand, you can not expect the audio to be noise-free.
Noise is a fact of life. All audio recordings have some degree of noise in them, and un-handled noise can wreck the accuracy of speech recognition apps.
To get a feel for how noise can affect speech recognition, download the “jackhammer.wav” file here . As always, make sure you save this to your interpreter session’s working directory.
This file has the phrase “the stale smell of old beer lingers” spoken with a loud jackhammer in the background.
What happens when you try to transcribe this file?
So how do you deal with this? One thing you can try is using the adjust_for_ambient_noise() method of the Recognizer class.
That got you a little closer to the actual phrase, but it still isn’t perfect. Also, “the” is missing from the beginning of the phrase. Why is that?
The adjust_for_ambient_noise() method reads the first second of the file stream and calibrates the recognizer to the noise level of the audio. Hence, that portion of the stream is consumed before you call record() to capture the data.
You can adjust the time-frame that adjust_for_ambient_noise() uses for analysis with the duration keyword argument. This argument takes a numerical value in seconds and is set to 1 by default. Try lowering this value to 0.5.
Well, that got you “the” at the beginning of the phrase, but now you have some new issues! Sometimes it isn’t possible to remove the effect of the noise—the signal is just too noisy to be dealt with successfully. That’s the case with this file.
If you find yourself running up against these issues frequently, you may have to resort to some pre-processing of the audio. This can be done with audio editing software or a Python package (such as SciPy ) that can apply filters to the files. A detailed discussion of this is beyond the scope of this tutorial—check out Allen Downey’s Think DSP book if you are interested. For now, just be aware that ambient noise in an audio file can cause problems and must be addressed in order to maximize the accuracy of speech recognition.
When working with noisy files, it can be helpful to see the actual API response. Most APIs return a JSON string containing many possible transcriptions. The recognize_google() method will always return the most likely transcription unless you force it to give you the full response.
You can do this by setting the show_all keyword argument of the recognize_google() method to True.
As you can see, recognize_google() returns a dictionary with the key 'alternative' that points to a list of possible transcripts. The structure of this response may vary from API to API and is mainly useful for debugging.
By now, you have a pretty good idea of the basics of the SpeechRecognition package. You’ve seen how to create an AudioFile instance from an audio file and use the record() method to capture data from the file. You learned how to record segments of a file using the offset and duration keyword arguments of record() , and you experienced the detrimental effect noise can have on transcription accuracy.
Now for the fun part. Let’s transition from transcribing static audio files to making your project interactive by accepting input from a microphone.
Working With Microphones
To access your microphone with SpeechRecognizer, you’ll have to install the PyAudio package . Go ahead and close your current interpreter session, and let’s do that.
The process for installing PyAudio will vary depending on your operating system.
Debian Linux
If you’re on Debian-based Linux (like Ubuntu) you can install PyAudio with apt :
Once installed, you may still need to run pip install pyaudio , especially if you are working in a virtual environment .
For macOS, first you will need to install PortAudio with Homebrew, and then install PyAudio with pip :
On Windows, you can install PyAudio with pip :
Testing the Installation
Once you’ve got PyAudio installed, you can test the installation from the console.
Make sure your default microphone is on and unmuted. If the installation worked, you should see something like this:
Shell A moment of silence, please... Set minimum energy threshold to 600.4452854381937 Say something! Copied! Go ahead and play around with it a little bit by speaking into your microphone and seeing how well SpeechRecognition transcribes your speech.
Note: If you are on Ubuntu and get some funky output like ‘ALSA lib … Unknown PCM’, refer to this page for tips on suppressing these messages. This output comes from the ALSA package installed with Ubuntu—not SpeechRecognition or PyAudio. In all reality, these messages may indicate a problem with your ALSA configuration, but in my experience, they do not impact the functionality of your code. They are mostly a nuisance.
Open up another interpreter session and create an instance of the recognizer class.
Now, instead of using an audio file as the source, you will use the default system microphone. You can access this by creating an instance of the Microphone class.
If your system has no default microphone (such as on a Raspberry Pi ), or you want to use a microphone other than the default, you will need to specify which one to use by supplying a device index. You can get a list of microphone names by calling the list_microphone_names() static method of the Microphone class.
Note that your output may differ from the above example.
The device index of the microphone is the index of its name in the list returned by list_microphone_names(). For example, given the above output, if you want to use the microphone called “front,” which has index 3 in the list, you would create a microphone instance like this:
For most projects, though, you’ll probably want to use the default system microphone.
Now that you’ve got a Microphone instance ready to go, it’s time to capture some input.
Just like the AudioFile class, Microphone is a context manager. You can capture input from the microphone using the listen() method of the Recognizer class inside of the with block. This method takes an audio source as its first argument and records input from the source until silence is detected.
Once you execute the with block, try speaking “hello” into your microphone. Wait a moment for the interpreter prompt to display again. Once the “>>>” prompt returns, you’re ready to recognize the speech.
If the prompt never returns, your microphone is most likely picking up too much ambient noise. You can interrupt the process with Ctrl + C to get your prompt back.
To handle ambient noise, you’ll need to use the adjust_for_ambient_noise() method of the Recognizer class, just like you did when trying to make sense of the noisy audio file. Since input from a microphone is far less predictable than input from an audio file, it is a good idea to do this anytime you listen for microphone input.
After running the above code, wait a second for adjust_for_ambient_noise() to do its thing, then try speaking “hello” into the microphone. Again, you will have to wait a moment for the interpreter prompt to return before trying to recognize the speech.
Recall that adjust_for_ambient_noise() analyzes the audio source for one second. If this seems too long to you, feel free to adjust this with the duration keyword argument.
The SpeechRecognition documentation recommends using a duration no less than 0.5 seconds. In some cases, you may find that durations longer than the default of one second generate better results. The minimum value you need depends on the microphone’s ambient environment. Unfortunately, this information is typically unknown during development. In my experience, the default duration of one second is adequate for most applications.
Try typing the previous code example in to the interpeter and making some unintelligible noises into the microphone. You should get something like this in response:
Audio that cannot be matched to text by the API raises an UnknownValueError exception. You should always wrap calls to the API with try and except blocks to handle this exception .
Note : You may have to try harder than you expect to get the exception thrown. The API works very hard to transcribe any vocal sounds. Even short grunts were transcribed as words like “how” for me. Coughing, hand claps, and tongue clicks would consistently raise the exception.
Now that you’ve seen the basics of recognizing speech with the SpeechRecognition package let’s put your newfound knowledge to use and write a small game that picks a random word from a list and gives the user three attempts to guess the word.
Here is the full script:
Let’s break that down a little bit.
The recognize_speech_from_mic() function takes a Recognizer and Microphone instance as arguments and returns a dictionary with three keys. The first key, "success" , is a boolean that indicates whether or not the API request was successful. The second key, "error" , is either None or an error message indicating that the API is unavailable or the speech was unintelligible. Finally, the "transcription" key contains the transcription of the audio recorded by the microphone.
The function first checks that the recognizer and microphone arguments are of the correct type, and raises a TypeError if either is invalid:
The listen() method is then used to record microphone input:
The adjust_for_ambient_noise() method is used to calibrate the recognizer for changing noise conditions each time the recognize_speech_from_mic() function is called.
Next, recognize_google() is called to transcribe any speech in the recording. A try...except block is used to catch the RequestError and UnknownValueError exceptions and handle them accordingly. The success of the API request, any error messages, and the transcribed speech are stored in the success , error and transcription keys of the response dictionary, which is returned by the recognize_speech_from_mic() function.
You can test the recognize_speech_from_mic() function by saving the above script to a file called “guessing_game.py” and running the following in an interpreter session:
The game itself is pretty simple. First, a list of words, a maximum number of allowed guesses and a prompt limit are declared:
Next, a Recognizer and Microphone instance is created and a random word is chosen from WORDS :
After printing some instructions and waiting for 3 three seconds, a for loop is used to manage each user attempt at guessing the chosen word. The first thing inside the for loop is another for loop that prompts the user at most PROMPT_LIMIT times for a guess, attempting to recognize the input each time with the recognize_speech_from_mic() function and storing the dictionary returned to the local variable guess .
If the "transcription" key of guess is not None , then the user’s speech was transcribed and the inner loop is terminated with break . If the speech was not transcribed and the "success" key is set to False , then an API error occurred and the loop is again terminated with break . Otherwise, the API request was successful but the speech was unrecognizable. The user is warned and the for loop repeats, giving the user another chance at the current attempt.
Once the inner for loop terminates, the guess dictionary is checked for errors. If any occurred, the error message is displayed and the outer for loop is terminated with break , which will end the program execution.
If there weren’t any errors, the transcription is compared to the randomly selected word. The lower() method for string objects is used to ensure better matching of the guess to the chosen word. The API may return speech matched to the word “apple” as “Apple” or “apple,” and either response should count as a correct answer.
If the guess was correct, the user wins and the game is terminated. If the user was incorrect and has any remaining attempts, the outer for loop repeats and a new guess is retrieved. Otherwise, the user loses the game.
When run, the output will look something like this:
In this tutorial, you’ve seen how to install the SpeechRecognition package and use its Recognizer class to easily recognize speech from both a file—using record() —and microphone input—using listen(). You also saw how to process segments of an audio file using the offset and duration keyword arguments of the record() method.
You’ve seen the effect noise can have on the accuracy of transcriptions, and have learned how to adjust a Recognizer instance’s sensitivity to ambient noise with adjust_for_ambient_noise(). You have also learned which exceptions a Recognizer instance may throw— RequestError for bad API requests and UnkownValueError for unintelligible speech—and how to handle these with try...except blocks.
Speech recognition is a deep subject, and what you have learned here barely scratches the surface. If you’re interested in learning more, here are some additional resources.
For more information on the SpeechRecognition package:
- Library reference
- Troubleshooting page
A few interesting internet resources:
- Behind the Mic: The Science of Talking with Computers . A short film about speech processing by Google.
- A Historical Perspective of Speech Recognition by Huang, Baker and Reddy. Communications of the ACM (2014). This article provides an in-depth and scholarly look at the evolution of speech recognition technology.
- The Past, Present and Future of Speech Recognition Technology by Clark Boyd at The Startup. This blog post presents an overview of speech recognition technology, with some thoughts about the future.
Some good books about speech recognition:
- The Voice in the Machine: Building Computers That Understand Speech , Pieraccini, MIT Press (2012). An accessible general-audience book covering the history of, as well as modern advances in, speech processing.
- Fundamentals of Speech Recognition , Rabiner and Juang, Prentice Hall (1993). Rabiner, a researcher at Bell Labs, was instrumental in designing some of the first commercially viable speech recognizers. This book is now over 20 years old, but a lot of the fundamentals remain the same.
- Automatic Speech Recognition: A Deep Learning Approach , Yu and Deng, Springer (2014). Yu and Deng are researchers at Microsoft and both very active in the field of speech processing. This book covers a lot of modern approaches and cutting-edge research but is not for the mathematically faint-of-heart.
Throughout this tutorial, we’ve been recognizing speech in English, which is the default language for each recognize_*() method of the SpeechRecognition package. However, it is absolutely possible to recognize speech in other languages, and is quite simple to accomplish.
To recognize speech in a different language, set the language keyword argument of the recognize_*() method to a string corresponding to the desired language. Most of the methods accept a BCP-47 language tag, such as 'en-US' for American English, or 'fr-FR' for French. For example, the following recognizes French speech in an audio file:
Only the following methods accept a language keyword argument:
- recognize_bing()
- recognize_google()
- recognize_google_cloud()
- recognize_ibm()
- recognize_sphinx()
To find out which language tags are supported by the API you are using, you’ll have to consult the corresponding documentation . A list of tags accepted by recognize_google() can be found in this Stack Overflow answer .
🐍 Python Tricks 💌
Get a short & sweet Python Trick delivered to your inbox every couple of days. No spam ever. Unsubscribe any time. Curated by the Real Python team.

About David Amos

David is a writer, programmer, and mathematician passionate about exploring mathematics through code.
Each tutorial at Real Python is created by a team of developers so that it meets our high quality standards. The team members who worked on this tutorial are:

Master Real-World Python Skills With Unlimited Access to Real Python
Join us and get access to thousands of tutorials, hands-on video courses, and a community of expert Pythonistas:
Join us and get access to thousands of tutorials, hands-on video courses, and a community of expert Pythonistas:
What Do You Think?
What’s your #1 takeaway or favorite thing you learned? How are you going to put your newfound skills to use? Leave a comment below and let us know.
Commenting Tips: The most useful comments are those written with the goal of learning from or helping out other students. Get tips for asking good questions and get answers to common questions in our support portal . Looking for a real-time conversation? Visit the Real Python Community Chat or join the next “Office Hours” Live Q&A Session . Happy Pythoning!
Keep Learning
Related Topics: advanced data-science machine-learning
Recommended Video Course: Speech Recognition With Python
Keep reading Real Python by creating a free account or signing in:
Already have an account? Sign-In
Almost there! Complete this form and click the button below to gain instant access:
Get a Full Python Speech Recognition Sample Project (Source Code / .zip)
🔒 No spam. We take your privacy seriously.

Speech recognition, also known as automatic speech recognition (ASR), computer speech recognition or speech-to-text, is a capability that enables a program to process human speech into a written format.
While speech recognition is commonly confused with voice recognition, speech recognition focuses on the translation of speech from a verbal format to a text one whereas voice recognition just seeks to identify an individual user’s voice.
IBM has had a prominent role within speech recognition since its inception, releasing of “Shoebox” in 1962. This machine had the ability to recognize 16 different words, advancing the initial work from Bell Labs from the 1950s. However, IBM didn’t stop there, but continued to innovate over the years, launching VoiceType Simply Speaking application in 1996. This speech recognition software had a 42,000-word vocabulary, supported English and Spanish, and included a spelling dictionary of 100,000 words.
While speech technology had a limited vocabulary in the early days, it is utilized in a wide number of industries today, such as automotive, technology, and healthcare. Its adoption has only continued to accelerate in recent years due to advancements in deep learning and big data. Research (link resides outside ibm.com) shows that this market is expected to be worth USD 24.9 billion by 2025.
Explore the free O'Reilly ebook to learn how to get started with Presto, the open source SQL engine for data analytics.
Register for the guide on foundation models
Many speech recognition applications and devices are available, but the more advanced solutions use AI and machine learning . They integrate grammar, syntax, structure, and composition of audio and voice signals to understand and process human speech. Ideally, they learn as they go — evolving responses with each interaction.
The best kind of systems also allow organizations to customize and adapt the technology to their specific requirements — everything from language and nuances of speech to brand recognition. For example:
- Language weighting: Improve precision by weighting specific words that are spoken frequently (such as product names or industry jargon), beyond terms already in the base vocabulary.
- Speaker labeling: Output a transcription that cites or tags each speaker’s contributions to a multi-participant conversation.
- Acoustics training: Attend to the acoustical side of the business. Train the system to adapt to an acoustic environment (like the ambient noise in a call center) and speaker styles (like voice pitch, volume and pace).
- Profanity filtering: Use filters to identify certain words or phrases and sanitize speech output.
Meanwhile, speech recognition continues to advance. Companies, like IBM, are making inroads in several areas, the better to improve human and machine interaction.
The vagaries of human speech have made development challenging. It’s considered to be one of the most complex areas of computer science – involving linguistics, mathematics and statistics. Speech recognizers are made up of a few components, such as the speech input, feature extraction, feature vectors, a decoder, and a word output. The decoder leverages acoustic models, a pronunciation dictionary, and language models to determine the appropriate output.
Speech recognition technology is evaluated on its accuracy rate, i.e. word error rate (WER), and speed. A number of factors can impact word error rate, such as pronunciation, accent, pitch, volume, and background noise. Reaching human parity – meaning an error rate on par with that of two humans speaking – has long been the goal of speech recognition systems. Research from Lippmann (link resides outside ibm.com) estimates the word error rate to be around 4 percent, but it’s been difficult to replicate the results from this paper.
Various algorithms and computation techniques are used to recognize speech into text and improve the accuracy of transcription. Below are brief explanations of some of the most commonly used methods:
- Natural language processing (NLP): While NLP isn’t necessarily a specific algorithm used in speech recognition, it is the area of artificial intelligence which focuses on the interaction between humans and machines through language through speech and text. Many mobile devices incorporate speech recognition into their systems to conduct voice search—e.g. Siri—or provide more accessibility around texting.
- Hidden markov models (HMM): Hidden Markov Models build on the Markov chain model, which stipulates that the probability of a given state hinges on the current state, not its prior states. While a Markov chain model is useful for observable events, such as text inputs, hidden markov models allow us to incorporate hidden events, such as part-of-speech tags, into a probabilistic model. They are utilized as sequence models within speech recognition, assigning labels to each unit—i.e. words, syllables, sentences, etc.—in the sequence. These labels create a mapping with the provided input, allowing it to determine the most appropriate label sequence.
- N-grams: This is the simplest type of language model (LM), which assigns probabilities to sentences or phrases. An N-gram is sequence of N-words. For example, “order the pizza” is a trigram or 3-gram and “please order the pizza” is a 4-gram. Grammar and the probability of certain word sequences are used to improve recognition and accuracy.
- Neural networks: Primarily leveraged for deep learning algorithms, neural networks process training data by mimicking the interconnectivity of the human brain through layers of nodes. Each node is made up of inputs, weights, a bias (or threshold) and an output. If that output value exceeds a given threshold, it “fires” or activates the node, passing data to the next layer in the network. Neural networks learn this mapping function through supervised learning, adjusting based on the loss function through the process of gradient descent. While neural networks tend to be more accurate and can accept more data, this comes at a performance efficiency cost as they tend to be slower to train compared to traditional language models.
- Speaker Diarization (SD): Speaker diarization algorithms identify and segment speech by speaker identity. This helps programs better distinguish individuals in a conversation and is frequently applied at call centers distinguishing customers and sales agents.
A wide number of industries are utilizing different applications of speech technology today, helping businesses and consumers save time and even lives. Some examples include:
Automotive: Speech recognizers improves driver safety by enabling voice-activated navigation systems and search capabilities in car radios.
Technology: Virtual agents are increasingly becoming integrated within our daily lives, particularly on our mobile devices. We use voice commands to access them through our smartphones, such as through Google Assistant or Apple’s Siri, for tasks, such as voice search, or through our speakers, via Amazon’s Alexa or Microsoft’s Cortana, to play music. They’ll only continue to integrate into the everyday products that we use, fueling the “Internet of Things” movement.
Healthcare: Doctors and nurses leverage dictation applications to capture and log patient diagnoses and treatment notes.
Sales: Speech recognition technology has a couple of applications in sales. It can help a call center transcribe thousands of phone calls between customers and agents to identify common call patterns and issues. AI chatbots can also talk to people via a webpage, answering common queries and solving basic requests without needing to wait for a contact center agent to be available. It both instances speech recognition systems help reduce time to resolution for consumer issues.
Security: As technology integrates into our daily lives, security protocols are an increasing priority. Voice-based authentication adds a viable level of security.
Convert speech into text using AI-powered speech recognition and transcription.
Convert text into natural-sounding speech in a variety of languages and voices.
AI-powered hybrid cloud software.
Enable speech transcription in multiple languages for a variety of use cases, including but not limited to customer self-service, agent assistance and speech analytics.
Learn how to keep up, rethink how to use technologies like the cloud, AI and automation to accelerate innovation, and meet the evolving customer expectations.
IBM watsonx Assistant helps organizations provide better customer experiences with an AI chatbot that understands the language of the business, connects to existing customer care systems, and deploys anywhere with enterprise security and scalability. watsonx Assistant automates repetitive tasks and uses machine learning to resolve customer support issues quickly and efficiently.
Speech Recognition: Everything You Need to Know in 2024
AIMultiple team adheres to the ethical standards summarized in our research commitments.
Speech recognition, also known as automatic speech recognition (ASR) , enables seamless communication between humans and machines. This technology empowers organizations to transform human speech into written text. Speech recognition technology can revolutionize many business applications , including customer service, healthcare, finance and sales.
In this comprehensive guide, we will explain speech recognition, exploring how it works, the algorithms involved, and the use cases of various industries.
If you require training data for your speech recognition system, here is a guide to finding the right speech data collection services.
What is speech recognition?
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text.
Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents, dialects, and speech patterns.
What are the features of speech recognition systems?
Speech recognition systems have several components that work together to understand and process human speech. Key features of effective speech recognition are:
- Audio preprocessing: After you have obtained the raw audio signal from an input device, you need to preprocess it to improve the quality of the speech input The main goal of audio preprocessing is to capture relevant speech data by removing any unwanted artifacts and reducing noise.
- Feature extraction: This stage converts the preprocessed audio signal into a more informative representation. This makes raw audio data more manageable for machine learning models in speech recognition systems.
- Language model weighting: Language weighting gives more weight to certain words and phrases, such as product references, in audio and voice signals. This makes those keywords more likely to be recognized in a subsequent speech by speech recognition systems.
- Acoustic modeling : It enables speech recognizers to capture and distinguish phonetic units within a speech signal. Acoustic models are trained on large datasets containing speech samples from a diverse set of speakers with different accents, speaking styles, and backgrounds.
- Speaker labeling: It enables speech recognition applications to determine the identities of multiple speakers in an audio recording. It assigns unique labels to each speaker in an audio recording, allowing the identification of which speaker was speaking at any given time.
- Profanity filtering: The process of removing offensive, inappropriate, or explicit words or phrases from audio data.
What are the different speech recognition algorithms?
Speech recognition uses various algorithms and computation techniques to convert spoken language into written language. The following are some of the most commonly used speech recognition methods:
- Hidden Markov Models (HMMs): Hidden Markov model is a statistical Markov model commonly used in traditional speech recognition systems. HMMs capture the relationship between the acoustic features and model the temporal dynamics of speech signals.
- Estimate the probability of word sequences in the recognized text
- Convert colloquial expressions and abbreviations in a spoken language into a standard written form
- Map phonetic units obtained from acoustic models to their corresponding words in the target language.
- Speaker Diarization (SD): Speaker diarization, or speaker labeling, is the process of identifying and attributing speech segments to their respective speakers (Figure 1). It allows for speaker-specific voice recognition and the identification of individuals in a conversation.
Figure 1: A flowchart illustrating the speaker diarization process

- Dynamic Time Warping (DTW): Speech recognition algorithms use Dynamic Time Warping (DTW) algorithm to find an optimal alignment between two sequences (Figure 2).
Figure 2: A speech recognizer using dynamic time warping to determine the optimal distance between elements

5. Deep neural networks: Neural networks process and transform input data by simulating the non-linear frequency perception of the human auditory system.
6. Connectionist Temporal Classification (CTC): It is a training objective introduced by Alex Graves in 2006. CTC is especially useful for sequence labeling tasks and end-to-end speech recognition systems. It allows the neural network to discover the relationship between input frames and align input frames with output labels.
Speech recognition vs voice recognition
Speech recognition is commonly confused with voice recognition, yet, they refer to distinct concepts. Speech recognition converts spoken words into written text, focusing on identifying the words and sentences spoken by a user, regardless of the speaker’s identity.
On the other hand, voice recognition is concerned with recognizing or verifying a speaker’s voice, aiming to determine the identity of an unknown speaker rather than focusing on understanding the content of the speech.
What are the challenges of speech recognition with solutions?
While speech recognition technology offers many benefits, it still faces a number of challenges that need to be addressed. Some of the main limitations of speech recognition include:
Acoustic Challenges:
- Assume a speech recognition model has been primarily trained on American English accents. If a speaker with a strong Scottish accent uses the system, they may encounter difficulties due to pronunciation differences. For example, the word “water” is pronounced differently in both accents. If the system is not familiar with this pronunciation, it may struggle to recognize the word “water.”
Solution: Addressing these challenges is crucial to enhancing speech recognition applications’ accuracy. To overcome pronunciation variations, it is essential to expand the training data to include samples from speakers with diverse accents. This approach helps the system recognize and understand a broader range of speech patterns.
- For instance, you can use data augmentation techniques to reduce the impact of noise on audio data. Data augmentation helps train speech recognition models with noisy data to improve model accuracy in real-world environments.
Figure 3: Examples of a target sentence (“The clown had a funny face”) in the background noise of babble, car and rain.

Linguistic Challenges:
- Out-of-vocabulary words: Since the speech recognizers model has not been trained on OOV words, they may incorrectly recognize them as different or fail to transcribe them when encountering them.
Figure 4: An example of detecting OOV word
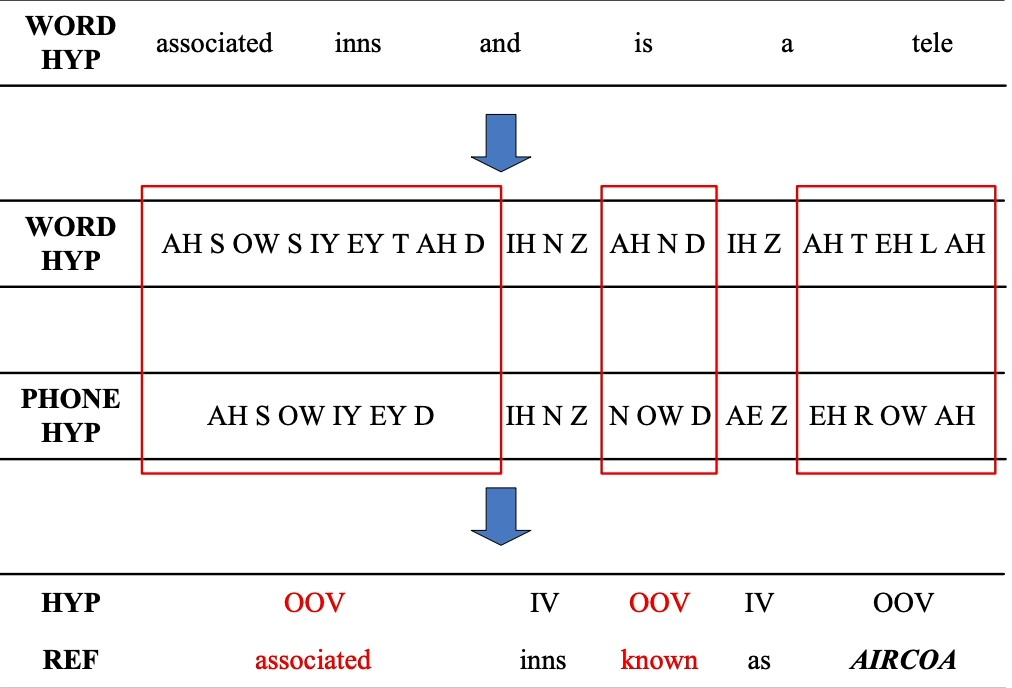
Solution: Word Error Rate (WER) is a common metric that is used to measure the accuracy of a speech recognition or machine translation system. The word error rate can be computed as:
Figure 5: Demonstrating how to calculate word error rate (WER)

- Homophones: Homophones are words that are pronounced identically but have different meanings, such as “to,” “too,” and “two”. Solution: Semantic analysis allows speech recognition programs to select the appropriate homophone based on its intended meaning in a given context. Addressing homophones improves the ability of the speech recognition process to understand and transcribe spoken words accurately.
Technical/System Challenges:
- Data privacy and security: Speech recognition systems involve processing and storing sensitive and personal information, such as financial information. An unauthorized party could use the captured information, leading to privacy breaches.
Solution: You can encrypt sensitive and personal audio information transmitted between the user’s device and the speech recognition software. Another technique for addressing data privacy and security in speech recognition systems is data masking. Data masking algorithms mask and replace sensitive speech data with structurally identical but acoustically different data.
Figure 6: An example of how data masking works

- Limited training data: Limited training data directly impacts the performance of speech recognition software. With insufficient training data, the speech recognition model may struggle to generalize different accents or recognize less common words.
Solution: To improve the quality and quantity of training data, you can expand the existing dataset using data augmentation and synthetic data generation technologies.
13 speech recognition use cases and applications
In this section, we will explain how speech recognition revolutionizes the communication landscape across industries and changes the way businesses interact with machines.
Customer Service and Support
- Interactive Voice Response (IVR) systems: Interactive voice response (IVR) is a technology that automates the process of routing callers to the appropriate department. It understands customer queries and routes calls to the relevant departments. This reduces the call volume for contact centers and minimizes wait times. IVR systems address simple customer questions without human intervention by employing pre-recorded messages or text-to-speech technology . Automatic Speech Recognition (ASR) allows IVR systems to comprehend and respond to customer inquiries and complaints in real time.
- Customer support automation and chatbots: According to a survey, 78% of consumers interacted with a chatbot in 2022, but 80% of respondents said using chatbots increased their frustration level.
- Sentiment analysis and call monitoring: Speech recognition technology converts spoken content from a call into text. After speech-to-text processing, natural language processing (NLP) techniques analyze the text and assign a sentiment score to the conversation, such as positive, negative, or neutral. By integrating speech recognition with sentiment analysis, organizations can address issues early on and gain valuable insights into customer preferences.
- Multilingual support: Speech recognition software can be trained in various languages to recognize and transcribe the language spoken by a user accurately. By integrating speech recognition technology into chatbots and Interactive Voice Response (IVR) systems, organizations can overcome language barriers and reach a global audience (Figure 7). Multilingual chatbots and IVR automatically detect the language spoken by a user and switch to the appropriate language model.
Figure 7: Showing how a multilingual chatbot recognizes words in another language
- Customer authentication with voice biometrics: Voice biometrics use speech recognition technologies to analyze a speaker’s voice and extract features such as accent and speed to verify their identity.
Sales and Marketing:
- Virtual sales assistants: Virtual sales assistants are AI-powered chatbots that assist customers with purchasing and communicate with them through voice interactions. Speech recognition allows virtual sales assistants to understand the intent behind spoken language and tailor their responses based on customer preferences.
- Transcription services : Speech recognition software records audio from sales calls and meetings and then converts the spoken words into written text using speech-to-text algorithms.
Automotive:
- Voice-activated controls: Voice-activated controls allow users to interact with devices and applications using voice commands. Drivers can operate features like climate control, phone calls, or navigation systems.
- Voice-assisted navigation: Voice-assisted navigation provides real-time voice-guided directions by utilizing the driver’s voice input for the destination. Drivers can request real-time traffic updates or search for nearby points of interest using voice commands without physical controls.
Healthcare:
- Recording the physician’s dictation
- Transcribing the audio recording into written text using speech recognition technology
- Editing the transcribed text for better accuracy and correcting errors as needed
- Formatting the document in accordance with legal and medical requirements.
- Virtual medical assistants: Virtual medical assistants (VMAs) use speech recognition, natural language processing, and machine learning algorithms to communicate with patients through voice or text. Speech recognition software allows VMAs to respond to voice commands, retrieve information from electronic health records (EHRs) and automate the medical transcription process.
- Electronic Health Records (EHR) integration: Healthcare professionals can use voice commands to navigate the EHR system , access patient data, and enter data into specific fields.
Technology:
- Virtual agents: Virtual agents utilize natural language processing (NLP) and speech recognition technologies to understand spoken language and convert it into text. Speech recognition enables virtual agents to process spoken language in real-time and respond promptly and accurately to user voice commands.
Further reading
- Top 5 Speech Recognition Data Collection Methods in 2023
- Top 11 Speech Recognition Applications in 2023
External Links
- 1. Databricks
- 2. PubMed Central
- 3. Qin, L. (2013). Learning Out-of-vocabulary Words in Automatic Speech Recognition . Carnegie Mellon University.
- 4. Wikipedia

Next to Read
Top 10 text to speech software analysis in 2024, top 5 speech recognition data collection methods in 2024, top 4 speech recognition challenges & solutions in 2024.
Your email address will not be published. All fields are required.
Related research

Why Should You Use Cloud Inference (Inference as a Service) in 2024?
What is a Lexicon in Speech Recognition?
Rev › Blog › Resources › Other Resources › A.I. & Speech Recognition › What is a Lexicon in Speech Recognition?
A key part of any automatic speech recognition system is the lexicon . The lexicon can be tricky to define because it’s sometimes used to mean different things depending on the context. In its most basic form, a lexicon is simply a set of words with their pronunciations broken down into phonemes , i.e. units of word pronunciation.
In many ways it is like a dictionary for pronunciation. The other way that the word lexicon is used is to refer to the finite state transducer which results from the lexicon preparation, sometimes referred to as “L.FST”. A finite state transducer is a finite state automaton which maps two sets of symbols together. In the case of the lexicon, such a transducer maps the word symbols to their respective pronunciations.
Defining the FST
The lexicon can be viewed as a Finite State Transducer along with a set of transition probabilities which specify the probability of transitioning between word phoneme states. The classic setup for this is to assign one state to each phoneme. Then, the probabilities of transitioning between states are specified by phoneme likelihoods, usually computed from some large corpus.
However, in many practical cases, we actually desire a more granular representation of phonemes. This is because phones can vary widely in length, lasting up to one second, and also in acoustic energy. Even between speakers, the length of a fixed phone can vary by up to 40-130 times. What’s more, certain sounds such as consonants and diphthongs have large variations in their acoustic waveforms.
For this reason, it doesn’t make sense to average the energy over the entire phone as this leads to a loss of information. Thus, many times we will assign three states per phone – a beginning, middle, and end state. This allows the model to capture information related to the varying acoustic energies within the phone. Additionally, “blank” phone states can be added to capture silence in between sequences of speech.
Variations in Spelling and Pronunciation
The reason why the lexicon is such an important piece of the speech recognition pipeline is because it gives a way of discriminating between different pronunciations and spellings of words. Many word components which are spelled the same have different pronunciations in different contexts.
For example, consider “ough” as in through, dough, cough, rough, bough, thorough, enough, etc. The pronunciation cannot be known from the spelling. In this case, the correct pronunciation for a given word will be determined contextually from the lexicon and the state transition probabilities which it encodes between word/phoneme states.
In other cases, even where the spelling of the word is the same, the pronunciation cannot be readily inferred. Take the case of the word “neural” which can be pronounced either as N UR UL or N Y UR UL depending on which part of the country you are from. For tricky edge cases like these, a quality lexicon will encode both pronunciation variants as well as give some probability as to the likelihood of each.
Finally, there can be variations of pronunciation within even the same speaker which can be attributed to how fast they’re talking or even just simple slips of the tongue. An example of this might be a shortening of a word such as when “accented” is pronounced without the T during rapid speech (AE K S EH N IH D). Another example might be an elision of words such as “New Orleans” being pronounced as “n’orleans” or “nawlins”. Thus, the lexicon can be important for representing other pronunciation phenomena that help deal with real speech in the wild.
How the Lexicon Is Used

Lexicon Resources
So how do we, for each word, get its constituent phones? Well, if you’re a linguist, you can author such a set yourself. However, for the vast majority of us it’s better to download an open source lexicon. One of the most popular such resources is the CMU Pronouncing Dictionary, often abbreviated as CMUdict. This resource contains four files: a set of 39 phone (phoneme) symbols as defined in ARPABET , a file containing the assignment of these symbols to their type, such as “vowel”, “fricative”, “stop”, or “aspirate”, a file giving pronunciations of various punctuation marks, and then the core dictionary giving pronunciations of standard English words, broken down by phone. Here is an example entry taken from that dictionary in order to give you an idea of what the data looks like:
abalone AE2 B AH0 L OW1 N IY0
As you can see, it has the word “abalone” broken down into its constituent sounds. Such a file would get fed into the ASR to create the lexicon HMM as described in the first section.
Rev AI Speech Recognition Accuracy
Due to the amount of raw data transcribed by Rev’s 60,000+ human professional transcriptionists, Rev has the most accurate speech recognition system and speech-to-text API. Rev consistently beats Google, Amazon, and Microsoft in accuracy tests .

More Caption & Subtitle Articles
Everybody’s Favorite Speech-to-Text Blog
We combine AI and a huge community of freelancers to make speech-to-text greatness every day. Wanna hear more about it?
Automatic Speech Recognition

What is Automatic Speech Recognition?
Automatic Speech Recognition (ASR), also known as speech-to-text, is the process by which a computer or electronic device converts human speech into written text. This technology is a subset of computational linguistics that deals with the interpretation and translation of spoken language into text by computers. It enables humans to speak commands into devices, dictate documents, and interact with computer-based systems through natural language.
How Does Automatic Speech Recognition Work?
ASR systems typically involve several processing stages to accurately transcribe speech. The process begins with the acoustic signal being captured by a microphone. This signal is then digitized and processed to filter out noise and improve clarity.
The core of ASR technology involves two main models:
- Acoustic Model: This model is trained to recognize the basic units of sound in speech, known as phonemes. It maps segments of audio to these phonemes and considers variations in pronunciation, accent, and intonation.
- Language Model: This model is used to understand the context and semantics of the spoken words. It predicts the sequence of words that form a sentence, based on the likelihood of word sequences in the language. This helps in distinguishing between words that sound similar but have different meanings.
Once the audio has been processed through these models, the ASR system generates a transcription of the spoken words. Advanced systems may also include additional components, such as a dialogue manager in interactive voice response systems, or a natural language understanding module to interpret the intent behind the words.
Challenges in Automatic Speech Recognition
Despite significant advancements, ASR systems face numerous challenges that can affect their accuracy and performance:
- Variability in Speech: Differences in accents, dialects, and individual speaker characteristics can make it difficult for ASR systems to accurately recognize words.
- Background Noise: Noisy environments can interfere with the system's ability to capture clear audio, leading to transcription errors.
- Homophones and Context: Words that sound the same but have different meanings can be challenging for ASR systems to differentiate without understanding the context.
- Continuous Speech: Unlike written text, spoken language does not have clear boundaries between words, making it challenging to segment speech accurately.
- Colloquialisms and Slang: Everyday speech often includes informal language and slang, which may not be present in the training data used for ASR models.
Applications of Automatic Speech Recognition
ASR technology has a wide range of applications across various industries:
- Virtual Assistants: Devices like smartphones and smart speakers use ASR to enable voice commands and provide user assistance.
- Accessibility: ASR helps individuals with disabilities by enabling voice control over devices and converting speech to text for those who are deaf or hard of hearing.
- Transcription Services: ASR is used to automatically transcribe meetings, lectures, and interviews, saving time and effort in documentation.
- Customer Service: Call centers use ASR to route calls and handle inquiries through interactive voice response systems.
- Healthcare: ASR enables hands-free documentation for medical professionals, allowing them to dictate notes and records.
The Future of Automatic Speech Recognition
The future of ASR is promising, with ongoing research focused on improving accuracy, reducing latency, and understanding natural language more effectively. As machine learning algorithms become more sophisticated, we can expect ASR systems to become more reliable and integrated into an even broader array of applications, making human-computer interaction more seamless and natural.
Automatic Speech Recognition technology has revolutionized the way we interact with machines, making it possible to communicate with computers using our most natural form of communication: speech. While challenges remain, the continuous improvements in ASR systems are opening up new possibilities for innovation and convenience in our daily lives.
The world's most comprehensive data science & artificial intelligence glossary
Please sign up or login with your details
Generation Overview
AI Generator calls
AI Video Generator calls
AI Chat messages
Genius Mode messages
Genius Mode images
AD-free experience
Private images
- Includes 500 AI Image generations, 1750 AI Chat Messages, 30 AI Video generations, 60 Genius Mode Messages and 60 Genius Mode Images per month. If you go over any of these limits, you will be charged an extra $5 for that group.
- For example: if you go over 500 AI images, but stay within the limits for AI Chat and Genius Mode, you'll be charged $5 per additional 500 AI Image generations.
- Includes 100 AI Image generations and 300 AI Chat Messages. If you go over any of these limits, you will have to pay as you go.
- For example: if you go over 100 AI images, but stay within the limits for AI Chat, you'll have to reload on credits to generate more images. Choose from $5 - $1000. You'll only pay for what you use.
Out of credits
Refill your membership to continue using DeepAI
Share your generations with friends
Speech Recognition

What Is Speech Recognition?
Speech recognition is the technology that allows a computer to recognize human speech and process it into text. It’s also known as automatic speech recognition ( ASR ), speech-to-text, or computer speech recognition.
Speech recognition systems rely on technologies like artificial intelligence (AI) and machine learning (ML) to gain larger samples of speech, including different languages, accents, and dialects. AI is used to identify patterns of speech, words, and language to transcribe them into a written format.
In this blog post, we’ll take a deeper dive into speech recognition and look at how it works, its real-world applications, and how platforms like aiOla are using it to change the way we work.

Basic Speech Recognition Concepts
To start understanding speech recognition and all its applications, we need to first look at what it is and isn’t. While speech recognition is more than just the sum of its parts, it’s important to look at each of the parts that contribute to this technology to better grasp how it can make a real impact. Let’s take a look at some common concepts.
Speech Recognition vs. Speech Synthesis
Unlike speech recognition, which converts spoken language into a written format through a computer, speech synthesis does the same in reverse. In other words, speech synthesis is the creation of artificial speech derived from a written text, where a computer uses an AI-generated voice to simulate spoken language. For example, think of the language voice assistants like Siri or Alexa use to communicate information.
Phonetics and Phonology
Phonetics studies the physical sound of human speech, such as its acoustics and articulation. Alternatively, phonology looks at the abstract representation of sounds in a language including their patterns and how they’re organized. These two concepts need to be carefully weighed for speech AI algorithms to understand sound and language as a human might.
Acoustic Modeling
In acoustic modeling , the acoustic characteristics of audio and speech are looked at. When it comes to speech recognition systems, this process is essential since it helps analyze the audio features of each word, such as the frequency in which it’s used, the duration of a word, or the sounds it encompasses.
Language Modeling
Language modeling algorithms look at details like the likelihood of word sequences in a language. This type of modeling helps make speech recognition systems more accurate as it mimics real spoken language by looking at the probability of word combinations in phrases.
Speaker-Dependent vs. Speaker-Independent Systems
A system that’s dependent on a speaker is trained on the unique voice and speech patterns of a specific user, meaning the system might be highly accurate for that individual but not as much for other people. By contrast, a system that’s independent of a speaker can recognize speech for any number of speakers, and while more versatile, may be slightly less accurate.
How Does Speech Recognition Work?
There are a few different stages to speech recognition, each one providing another layer to how language is processed by a computer. Here are the different steps that make up the process.
- First, raw audio input undergoes a process called preprocessing , where background noise is removed to enhance sound quality and make recognition more manageable.
- Next, the audio goes through feature extraction , where algorithms identify distinct characteristics of sounds and words.
- Then, these extracted features go through acoustic modeling , which as we described earlier, is the stage where acoustic and language models decide the most accurate visual representation of the word. These acoustic modeling systems are based on extensive datasets, allowing them to learn the acoustic patterns of different spoken words.
- At the same time, language modeling looks at the structure and probability of words in a sequence, which helps provide context.
- After this, the output goes into a decoding sequence, where the speech recognition system matches data from the extracted features with the acoustic models. This helps determine the most likely word sequence.
- Finally, the audio and corresponding textual output go through post-processing , which refines the output by correcting errors and improving coherence to create a more accurate transcription.
When it comes to advanced systems, all of these stages are done nearly instantaneously, making this process almost invisible to the average user. All of these stages together have made speech recognition a highly versatile tool that can be used in many different ways, from virtual assistants to transcription services and beyond.
Types of Speech Recognition Systems
Speech recognition technology is used in many different ways today, transforming the way humans and machines interact and work together. From professional settings to helping us make our lives a little easier, this technology can take on many forms. Here are some of them.
Virtual Assistants
In 2022, 62% of US adults used a voice assistant on various mobile devices. Siri, Google Assistant, and Alexa are all examples of speech recognition in our daily lives. These applications respond to vocal commands and can interact with humans through natural language in order to complete tasks like sending messages, answering questions, or setting reminders.
Voice Search
Search engines like Google can be searched using voice instead of typing in a query, often with voice assistants. This allows users to conveniently search for a quick answer without sorting through content when they need to be hands-free, like when driving or multitasking. This technology has become so popular over the last few years that now 50% of US-based consumers use voice search every single day.
Transcription Services
Speech recognition has completely changed the transcription industry. It has enabled transcription services to automate the process of turning speech into text, increasing efficiency in many fields like education, legal services, healthcare, and even journalism.
Accessibility
With speech recognition, technologies that may have seemed out of reach are now accessible to people with disabilities. For example, for people with motor impairments or who are visually impaired, AI voice-to-text technology can help with the hands-free operation of things like keyboards, writing assistance for dictation, and voice commands to control devices.
Automotive Systems
Speech recognition is keeping drivers safer by giving them hands-free control over in-car features. Drivers can make calls, adjust the temperature, navigate, or even control the music without ever removing their hands from the wheel and instead just issuing voice commands to a speech-activated system.
How Does aiOla Use Speech Recognition?
aiOla’s AI-powered speech platform is revolutionizing the way certain industries work by bringing advanced speech recognition technology to companies in fields like aviation, fleet management, food safety, and manufacturing.
Traditionally, many processes in these industries were manual, forcing organizations to use a lot of time, budget, and resources to complete mission-critical tasks like inspections and maintenance. However, with aiOla’s advanced speech system, these otherwise labor and resource-intensive tasks can be reduced to a matter of minutes using natural language.
Rather than manually writing to record data during inspections, inspectors can speak about what they’re verifying and the data gets stored instantly. Similarly, through dissecting speech, aiOla can help with predictive maintenance of essential machinery, allowing food manufacturers to produce safer items and decrease downtime.
Since aiOla’s speech recognition platform understands over 100 languages and countless accents, dialects, and industry-specific jargon, the system is highly accurate and can help turn speech into action to go a step further and automate otherwise manual tasks.
Embracing Speech Recognition Technology
Looking ahead, we can only expect the technology that relies on speech recognition to improve and become more embedded into our day-to-day. Indeed, the market for this technology is expected to grow to $19.57 billion by 2030 . Whether it’s refining virtual assistants, improving voice search, or applying speech recognition to new industries, this technology is here to stay and enhance our personal and professional lives.
aiOla, while also a relatively new technology, is already making waves in industries like manufacturing, fleet management, and food safety. Through technological advancements in speech recognition, we only expect aiOla’s capabilities to continue to grow and support a larger variety of businesses and organizations.
Schedule a demo with one of our experts to see how aiOla’s AI speech recognition platform works in action.
What is speech recognition software? Speech recognition software is a technology that enables computers to convert speech into written words. This is done through algorithms that analyze audio signals along with AI, ML, and other technologies. What is a speech recognition example? A relatable example of speech recognition is asking a virtual assistant like Siri on a mobile device to check the day’s weather or set an alarm. While speech recognition can complete a lot more advanced tasks, this exemplifies how this technology is commonly used in everyday life. What is speech recognition in AI? Speech recognition in AI refers to how artificial intelligence processes are used to aid in recognizing voice and language using advanced models and algorithms trained on vast amounts of data. What are some different types of speech recognition? A few different types of speech recognition include speaker-dependent and speaker-independent systems, command and control systems, and continuous speech recognition. What is the difference between voice recognition and speech recognition? Speech recognition converts spoken language into text, while voice recognition works to identify a speaker’s unique vocal characteristics for authentication purposes. In essence, voice recognition is more tied to identity rather than transcription.
Ready to put your speech in motion? We’re listening.

Share your details to schedule a call
We will contact you soon!
SpeechRecognition 3.10.4
pip install SpeechRecognition Copy PIP instructions
Released: May 5, 2024
Library for performing speech recognition, with support for several engines and APIs, online and offline.
Verified details
Maintainers.

Unverified details
Project links, github statistics.
- Open issues:
View statistics for this project via Libraries.io , or by using our public dataset on Google BigQuery
License: BSD License (BSD)
Author: Anthony Zhang (Uberi)
Tags speech, recognition, voice, sphinx, google, wit, bing, api, houndify, ibm, snowboy
Requires: Python >=3.8
Classifiers
- 5 - Production/Stable
- OSI Approved :: BSD License
- MacOS :: MacOS X
- Microsoft :: Windows
- POSIX :: Linux
- Python :: 3
- Python :: 3.8
- Python :: 3.9
- Python :: 3.10
- Python :: 3.11
- Multimedia :: Sound/Audio :: Speech
- Software Development :: Libraries :: Python Modules
Project description

UPDATE 2022-02-09 : Hey everyone! This project started as a tech demo, but these days it needs more time than I have to keep up with all the PRs and issues. Therefore, I’d like to put out an open invite for collaborators - just reach out at me @ anthonyz . ca if you’re interested!
Speech recognition engine/API support:
Quickstart: pip install SpeechRecognition . See the “Installing” section for more details.
To quickly try it out, run python -m speech_recognition after installing.
Project links:
Library Reference
The library reference documents every publicly accessible object in the library. This document is also included under reference/library-reference.rst .
See Notes on using PocketSphinx for information about installing languages, compiling PocketSphinx, and building language packs from online resources. This document is also included under reference/pocketsphinx.rst .
You have to install Vosk models for using Vosk. Here are models avaiable. You have to place them in models folder of your project, like “your-project-folder/models/your-vosk-model”
See the examples/ directory in the repository root for usage examples:
First, make sure you have all the requirements listed in the “Requirements” section.
The easiest way to install this is using pip install SpeechRecognition .
Otherwise, download the source distribution from PyPI , and extract the archive.
In the folder, run python setup.py install .
Requirements
To use all of the functionality of the library, you should have:
The following requirements are optional, but can improve or extend functionality in some situations:
The following sections go over the details of each requirement.
The first software requirement is Python 3.8+ . This is required to use the library.
PyAudio (for microphone users)
PyAudio is required if and only if you want to use microphone input ( Microphone ). PyAudio version 0.2.11+ is required, as earlier versions have known memory management bugs when recording from microphones in certain situations.
If not installed, everything in the library will still work, except attempting to instantiate a Microphone object will raise an AttributeError .
The installation instructions on the PyAudio website are quite good - for convenience, they are summarized below:
PyAudio wheel packages for common 64-bit Python versions on Windows and Linux are included for convenience, under the third-party/ directory in the repository root. To install, simply run pip install wheel followed by pip install ./third-party/WHEEL_FILENAME (replace pip with pip3 if using Python 3) in the repository root directory .
PocketSphinx-Python (for Sphinx users)
PocketSphinx-Python is required if and only if you want to use the Sphinx recognizer ( recognizer_instance.recognize_sphinx ).
PocketSphinx-Python wheel packages for 64-bit Python 3.4, and 3.5 on Windows are included for convenience, under the third-party/ directory . To install, simply run pip install wheel followed by pip install ./third-party/WHEEL_FILENAME (replace pip with pip3 if using Python 3) in the SpeechRecognition folder.
On Linux and other POSIX systems (such as OS X), follow the instructions under “Building PocketSphinx-Python from source” in Notes on using PocketSphinx for installation instructions.
Note that the versions available in most package repositories are outdated and will not work with the bundled language data. Using the bundled wheel packages or building from source is recommended.
Vosk (for Vosk users)
Vosk API is required if and only if you want to use Vosk recognizer ( recognizer_instance.recognize_vosk ).
You can install it with python3 -m pip install vosk .
You also have to install Vosk Models:
Here are models avaiable for download. You have to place them in models folder of your project, like “your-project-folder/models/your-vosk-model”
Google Cloud Speech Library for Python (for Google Cloud Speech API users)
Google Cloud Speech library for Python is required if and only if you want to use the Google Cloud Speech API ( recognizer_instance.recognize_google_cloud ).
If not installed, everything in the library will still work, except calling recognizer_instance.recognize_google_cloud will raise an RequestError .
According to the official installation instructions , the recommended way to install this is using Pip : execute pip install google-cloud-speech (replace pip with pip3 if using Python 3).
FLAC (for some systems)
A FLAC encoder is required to encode the audio data to send to the API. If using Windows (x86 or x86-64), OS X (Intel Macs only, OS X 10.6 or higher), or Linux (x86 or x86-64), this is already bundled with this library - you do not need to install anything .
Otherwise, ensure that you have the flac command line tool, which is often available through the system package manager. For example, this would usually be sudo apt-get install flac on Debian-derivatives, or brew install flac on OS X with Homebrew.
Whisper (for Whisper users)
Whisper is required if and only if you want to use whisper ( recognizer_instance.recognize_whisper ).
You can install it with python3 -m pip install SpeechRecognition[whisper-local] .
Whisper API (for Whisper API users)
The library openai is required if and only if you want to use Whisper API ( recognizer_instance.recognize_whisper_api ).
If not installed, everything in the library will still work, except calling recognizer_instance.recognize_whisper_api will raise an RequestError .
You can install it with python3 -m pip install SpeechRecognition[whisper-api] .
Troubleshooting
The recognizer tries to recognize speech even when i’m not speaking, or after i’m done speaking..
Try increasing the recognizer_instance.energy_threshold property. This is basically how sensitive the recognizer is to when recognition should start. Higher values mean that it will be less sensitive, which is useful if you are in a loud room.
This value depends entirely on your microphone or audio data. There is no one-size-fits-all value, but good values typically range from 50 to 4000.
Also, check on your microphone volume settings. If it is too sensitive, the microphone may be picking up a lot of ambient noise. If it is too insensitive, the microphone may be rejecting speech as just noise.
The recognizer can’t recognize speech right after it starts listening for the first time.
The recognizer_instance.energy_threshold property is probably set to a value that is too high to start off with, and then being adjusted lower automatically by dynamic energy threshold adjustment. Before it is at a good level, the energy threshold is so high that speech is just considered ambient noise.
The solution is to decrease this threshold, or call recognizer_instance.adjust_for_ambient_noise beforehand, which will set the threshold to a good value automatically.
The recognizer doesn’t understand my particular language/dialect.
Try setting the recognition language to your language/dialect. To do this, see the documentation for recognizer_instance.recognize_sphinx , recognizer_instance.recognize_google , recognizer_instance.recognize_wit , recognizer_instance.recognize_bing , recognizer_instance.recognize_api , recognizer_instance.recognize_houndify , and recognizer_instance.recognize_ibm .
For example, if your language/dialect is British English, it is better to use "en-GB" as the language rather than "en-US" .
The recognizer hangs on recognizer_instance.listen ; specifically, when it’s calling Microphone.MicrophoneStream.read .
This usually happens when you’re using a Raspberry Pi board, which doesn’t have audio input capabilities by itself. This causes the default microphone used by PyAudio to simply block when we try to read it. If you happen to be using a Raspberry Pi, you’ll need a USB sound card (or USB microphone).
Once you do this, change all instances of Microphone() to Microphone(device_index=MICROPHONE_INDEX) , where MICROPHONE_INDEX is the hardware-specific index of the microphone.
To figure out what the value of MICROPHONE_INDEX should be, run the following code:
This will print out something like the following:
Now, to use the Snowball microphone, you would change Microphone() to Microphone(device_index=3) .
Calling Microphone() gives the error IOError: No Default Input Device Available .
As the error says, the program doesn’t know which microphone to use.
To proceed, either use Microphone(device_index=MICROPHONE_INDEX, ...) instead of Microphone(...) , or set a default microphone in your OS. You can obtain possible values of MICROPHONE_INDEX using the code in the troubleshooting entry right above this one.
The program doesn’t run when compiled with PyInstaller .
As of PyInstaller version 3.0, SpeechRecognition is supported out of the box. If you’re getting weird issues when compiling your program using PyInstaller, simply update PyInstaller.
You can easily do this by running pip install --upgrade pyinstaller .
On Ubuntu/Debian, I get annoying output in the terminal saying things like “bt_audio_service_open: […] Connection refused” and various others.
The “bt_audio_service_open” error means that you have a Bluetooth audio device, but as a physical device is not currently connected, we can’t actually use it - if you’re not using a Bluetooth microphone, then this can be safely ignored. If you are, and audio isn’t working, then double check to make sure your microphone is actually connected. There does not seem to be a simple way to disable these messages.
For errors of the form “ALSA lib […] Unknown PCM”, see this StackOverflow answer . Basically, to get rid of an error of the form “Unknown PCM cards.pcm.rear”, simply comment out pcm.rear cards.pcm.rear in /usr/share/alsa/alsa.conf , ~/.asoundrc , and /etc/asound.conf .
For “jack server is not running or cannot be started” or “connect(2) call to /dev/shm/jack-1000/default/jack_0 failed (err=No such file or directory)” or “attempt to connect to server failed”, these are caused by ALSA trying to connect to JACK, and can be safely ignored. I’m not aware of any simple way to turn those messages off at this time, besides entirely disabling printing while starting the microphone .
On OS X, I get a ChildProcessError saying that it couldn’t find the system FLAC converter, even though it’s installed.
Installing FLAC for OS X directly from the source code will not work, since it doesn’t correctly add the executables to the search path.
Installing FLAC using Homebrew ensures that the search path is correctly updated. First, ensure you have Homebrew, then run brew install flac to install the necessary files.
To hack on this library, first make sure you have all the requirements listed in the “Requirements” section.
To install/reinstall the library locally, run python -m pip install -e .[dev] in the project root directory .
Before a release, the version number is bumped in README.rst and speech_recognition/__init__.py . Version tags are then created using git config gpg.program gpg2 && git config user.signingkey DB45F6C431DE7C2DCD99FF7904882258A4063489 && git tag -s VERSION_GOES_HERE -m "Version VERSION_GOES_HERE" .
Releases are done by running make-release.sh VERSION_GOES_HERE to build the Python source packages, sign them, and upload them to PyPI.
To run all the tests:
To run static analysis:
To ensure RST is well-formed:
Testing is also done automatically by GitHub Actions, upon every push.
FLAC Executables
The included flac-win32 executable is the official FLAC 1.3.2 32-bit Windows binary .
The included flac-linux-x86 and flac-linux-x86_64 executables are built from the FLAC 1.3.2 source code with Manylinux to ensure that it’s compatible with a wide variety of distributions.
The built FLAC executables should be bit-for-bit reproducible. To rebuild them, run the following inside the project directory on a Debian-like system:
The included flac-mac executable is extracted from xACT 2.39 , which is a frontend for FLAC 1.3.2 that conveniently includes binaries for all of its encoders. Specifically, it is a copy of xACT 2.39/xACT.app/Contents/Resources/flac in xACT2.39.zip .
Please report bugs and suggestions at the issue tracker !
How to cite this library (APA style):
Zhang, A. (2017). Speech Recognition (Version 3.8) [Software]. Available from https://github.com/Uberi/speech_recognition#readme .
How to cite this library (Chicago style):
Zhang, Anthony. 2017. Speech Recognition (version 3.8).
Also check out the Python Baidu Yuyin API , which is based on an older version of this project, and adds support for Baidu Yuyin . Note that Baidu Yuyin is only available inside China.
Copyright 2014-2017 Anthony Zhang (Uberi) . The source code for this library is available online at GitHub .
SpeechRecognition is made available under the 3-clause BSD license. See LICENSE.txt in the project’s root directory for more information.
For convenience, all the official distributions of SpeechRecognition already include a copy of the necessary copyright notices and licenses. In your project, you can simply say that licensing information for SpeechRecognition can be found within the SpeechRecognition README, and make sure SpeechRecognition is visible to users if they wish to see it .
SpeechRecognition distributes source code, binaries, and language files from CMU Sphinx . These files are BSD-licensed and redistributable as long as copyright notices are correctly retained. See speech_recognition/pocketsphinx-data/*/LICENSE*.txt and third-party/LICENSE-Sphinx.txt for license details for individual parts.
SpeechRecognition distributes source code and binaries from PyAudio . These files are MIT-licensed and redistributable as long as copyright notices are correctly retained. See third-party/LICENSE-PyAudio.txt for license details.
SpeechRecognition distributes binaries from FLAC - speech_recognition/flac-win32.exe , speech_recognition/flac-linux-x86 , and speech_recognition/flac-mac . These files are GPLv2-licensed and redistributable, as long as the terms of the GPL are satisfied. The FLAC binaries are an aggregate of separate programs , so these GPL restrictions do not apply to the library or your programs that use the library, only to FLAC itself. See LICENSE-FLAC.txt for license details.
Project details
Release history release notifications | rss feed.
May 5, 2024
Mar 30, 2024
Mar 28, 2024
Dec 6, 2023
Mar 13, 2023
Dec 4, 2022
Dec 5, 2017
Jun 27, 2017
Apr 13, 2017
Mar 11, 2017
Jan 7, 2017
Nov 21, 2016
May 22, 2016
May 11, 2016
May 10, 2016
Apr 9, 2016
Apr 4, 2016
Apr 3, 2016
Mar 5, 2016
Mar 4, 2016
Feb 26, 2016
Feb 20, 2016
Feb 19, 2016
Feb 4, 2016
Nov 5, 2015
Nov 2, 2015
Sep 2, 2015
Sep 1, 2015
Aug 30, 2015
Aug 24, 2015
Jul 26, 2015
Jul 12, 2015
Jul 3, 2015
May 20, 2015
Apr 24, 2015
Apr 14, 2015
Apr 7, 2015
Apr 5, 2015
Apr 4, 2015
Mar 31, 2015
Dec 10, 2014
Nov 17, 2014
Sep 11, 2014
Sep 6, 2014
Aug 25, 2014
Jul 6, 2014
Jun 10, 2014
Jun 9, 2014
May 29, 2014
Apr 23, 2014
Download files
Download the file for your platform. If you're not sure which to choose, learn more about installing packages .
Source Distribution
Uploaded May 5, 2024 Source
Built Distribution
Uploaded May 5, 2024 Python 2 Python 3
Hashes for speechrecognition-3.10.4.tar.gz
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | ||
| MD5 | ||
| BLAKE2b-256 |
Hashes for SpeechRecognition-3.10.4-py2.py3-none-any.whl
| Algorithm | Hash digest | |
|---|---|---|
| SHA256 | ||
| MD5 | ||
| BLAKE2b-256 |
- português (Brasil)
Supported by

Speech Recognition
Speech recognition is the capability of an electronic device to understand spoken words. A microphone records a person's voice and the hardware converts the signal from analog sound waves to digital audio. The audio data is then processed by software , which interprets the sound as individual words.
A common type of speech recognition is "speech-to-text" or "dictation" software, such as Dragon Naturally Speaking, which outputs text as you speak. While you can buy speech recognition programs, modern versions of the Macintosh and Windows operating systems include a built-in dictation feature. This capability allows you to record text as well as perform basic system commands.
In Windows, some programs support speech recognition automatically while others do not. You can enable speech recognition for all applications by selecting All Programs → Accessories → Ease of Access → Windows Speech Recognition and clicking "Enable dictation everywhere." In OS X, you can enable dictation in the "Dictation & Speech" system preference pane. Simply check the "On" button next to Dictation to turn on the speech-to-text capability. To start dictating in a supported program, select Edit → Start Dictation . You can also view and edit spoken commands in OS X by opening the "Accessibility" system preference pane and selecting "Speakable Items."
Another type of speech recognition is interactive speech, which is common on mobile devices, such as smartphones and tablets . Both iOS and Android devices allow you to speak to your phone and receive a verbal response. The iOS version is called "Siri," and serves as a personal assistant. You can ask Siri to save a reminder on your phone, tell you the weather forecast, give you directions, or answer many other questions. This type of speech recognition is considered a natural user interface (or NUI ), since it responds naturally to your spoken input .
While many speech recognition systems only support English, some speech recognition software supports multiple languages. This requires a unique dictionary for each language and extra algorithms to understand and process different accents. Some dictation systems, such as Dragon Naturally Speaking, can be trained to understand your voice and will adapt over time to understand you more accurately.
Test Your Knowledge
What is a person for whom a hardware device is designed for called?
Tech Factor
The tech terms computer dictionary.
The definition of Speech Recognition on this page is an original definition written by the TechTerms.com team . If you would like to reference this page or cite this definition, please use the green citation links above.
The goal of TechTerms.com is to explain computer terminology in a way that is easy to understand. We strive for simplicity and accuracy with every definition we publish. If you have feedback about this definition or would like to suggest a new technical term, please contact us .
Sign up for the free TechTerms Newsletter
You can unsubscribe or change your frequency setting at any time using the links available in each email. Questions? Please contact us .
We just sent you an email to confirm your email address. Once you confirm your address, you will begin to receive the newsletter.
If you have any questions, please contact us .
- Python for Machine Learning
- Machine Learning with R
- Machine Learning Algorithms
- Math for Machine Learning
- Machine Learning Interview Questions
- ML Projects
- Deep Learning
- Computer vision
- Data Science
- Artificial Intelligence
Speech Recognition Module Python
- PyTorch for Speech Recognition
- Python | Speech recognition on large audio files
- Speech Recognition in Python using CMU Sphinx
- Python | Face recognition using GUI
- What is Speech Recognition?
- Automatic Speech Recognition using CTC
- How to Set Up Speech Recognition on Windows?
- Python word2number Module
- Automatic Speech Recognition using Whisper
- 5 Best AI Tools for Speech Recognition in 2024
- Speech Recognition in Hindi using Python
- Speech Recognition in Python using Google Speech API
- Python text2digits Module
- Python Text To Speech | pyttsx module
- Python - Get Today's Current Day using Speech Recognition
- Python winsound module
- TextaCy module in Python
- Python subprocess module
- Restart your Computer with Speech Recognition
Speech recognition, a field at the intersection of linguistics, computer science, and electrical engineering, aims at designing systems capable of recognizing and translating spoken language into text. Python, known for its simplicity and robust libraries, offers several modules to tackle speech recognition tasks effectively. In this article, we’ll explore the essence of speech recognition in Python, including an overview of its key libraries, how they can be implemented, and their practical applications.
Key Python Libraries for Speech Recognition
- SpeechRecognition : One of the most popular Python libraries for recognizing speech. It provides support for several engines and APIs, such as Google Web Speech API, Microsoft Bing Voice Recognition, and IBM Speech to Text. It’s known for its ease of use and flexibility, making it a great starting point for beginners and experienced developers alike.
- PyAudio : Essential for audio input and output in Python, PyAudio provides Python bindings for PortAudio, the cross-platform audio I/O library. It’s often used alongside SpeechRecognition to capture microphone input for real-time speech recognition.
- DeepSpeech : Developed by Mozilla, DeepSpeech is an open-source deep learning-based voice recognition system that uses models trained on the Baidu’s Deep Speech research project. It’s suitable for developers looking to implement more sophisticated speech recognition features with the power of deep learning.
Implementing Speech Recognition with Python
A basic implementation using the SpeechRecognition library involves several steps:
- Audio Capture : Capturing audio from the microphone using PyAudio.
- Audio Processing : Converting the audio signal into data that the SpeechRecognition library can work with.
- Recognition : Calling the recognize_google() method (or another available recognition method) on the SpeechRecognition library to convert the audio data into text.
Here’s a simple example:
Practical Applications
Speech recognition has a wide range of applications:
- Voice-activated Assistants: Creating personal assistants like Siri or Alexa.
- Accessibility Tools: Helping individuals with disabilities interact with technology.
- Home Automation: Enabling voice control over smart home devices.
- Transcription Services: Automatically transcribing meetings, lectures, and interviews.
Challenges and Considerations
While implementing speech recognition, developers might face challenges such as background noise interference, accents, and dialects. It’s crucial to consider these factors and test the application under various conditions. Furthermore, privacy and ethical considerations must be addressed, especially when handling sensitive audio data.
Speech recognition in Python offers a powerful way to build applications that can interact with users in natural language. With the help of libraries like SpeechRecognition, PyAudio, and DeepSpeech, developers can create a range of applications from simple voice commands to complex conversational interfaces. Despite the challenges, the potential for innovative applications is vast, making speech recognition an exciting area of development in Python.
FAQ on Speech Recognition Module in Python
What is the speech recognition module in python.
The Speech Recognition module, often referred to as SpeechRecognition, is a library that allows Python developers to convert spoken language into text by utilizing various speech recognition engines and APIs. It supports multiple services like Google Web Speech API, Microsoft Bing Voice Recognition, IBM Speech to Text, and others.
How can I install the Speech Recognition module?
You can install the Speech Recognition module by running the following command in your terminal or command prompt: pip install SpeechRecognition For capturing audio from the microphone, you might also need to install PyAudio. On most systems, this can be done via pip: pip install PyAudio
Do I need an internet connection to use the Speech Recognition module?
Yes, for most of the supported APIs like Google Web Speech, Microsoft Bing Voice Recognition, and IBM Speech to Text, an active internet connection is required. However, if you use the CMU Sphinx engine, you do not need an internet connection as it operates offline.
Please Login to comment...
Similar reads.
- AI-ML-DS With Python
- Python Framework
- Python-Library
- Machine Learning
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
- Customer service and contact center
speech recognition
- Ben Lutkevich, Site Editor
- Karolina Kiwak
What is speech recognition?
Speech recognition, or speech-to-text, is the ability of a machine or program to identify words spoken aloud and convert them into readable text. Rudimentary speech recognition software has a limited vocabulary and may only identify words and phrases when spoken clearly. More sophisticated software can handle natural speech, different accents and various languages.
Speech recognition uses a broad array of research in computer science, linguistics and computer engineering. Many modern devices and text-focused programs have speech recognition functions in them to allow for easier or hands-free use of a device.
Speech recognition and voice recognition are two different technologies and should not be confused :
- Speech recognition is used to identify words in spoken language.
- Voice recognition is a biometric technology for identifying an individual's voice.
How does speech recognition work?
Speech recognition systems use computer algorithms to process and interpret spoken words and convert them into text. A software program turns the sound a microphone records into written language that computers and humans can understand, following these four steps:
- analyze the audio;
- break it into parts;
- digitize it into a computer-readable format; and
- use an algorithm to match it to the most suitable text representation.
Speech recognition software must adapt to the highly variable and context-specific nature of human speech. The software algorithms that process and organize audio into text are trained on different speech patterns, speaking styles, languages, dialects, accents and phrasings. The software also separates spoken audio from background noise that often accompanies the signal.
To meet these requirements, speech recognition systems use two types of models:
- Acoustic models. These represent the relationship between linguistic units of speech and audio signals.
- Language models. Here, sounds are matched with word sequences to distinguish between words that sound similar.
What applications is speech recognition used for?
Speech recognition systems have quite a few applications. Here is a sampling of them.
Mobile devices. Smartphones use voice commands for call routing, speech-to-text processing, voice dialing and voice search. Users can respond to a text without looking at their devices. On Apple iPhones, speech recognition powers the keyboard and Siri, the virtual assistant. Functionality is available in secondary languages, too. Speech recognition can also be found in word processing applications like Microsoft Word, where users can dictate words to be turned into text.

Education. Speech recognition software is used in language instruction. The software hears the user's speech and offers help with pronunciation.
Customer service. Automated voice assistants listen to customer queries and provides helpful resources.
Healthcare applications. Doctors can use speech recognition software to transcribe notes in real time into healthcare records.
Disability assistance. Speech recognition software can translate spoken words into text using closed captions to enable a person with hearing loss to understand what others are saying. Speech recognition can also enable those with limited use of their hands to work with computers, using voice commands instead of typing.
Court reporting. Software can be used to transcribe courtroom proceedings, precluding the need for human transcribers.
Emotion recognition. This technology can analyze certain vocal characteristics to determine what emotion the speaker is feeling. Paired with sentiment analysis, this can reveal how someone feels about a product or service.
Hands-free communication. Drivers use voice control for hands-free communication, controlling phones, radios and global positioning systems, for instance.

What are the features of speech recognition systems?
Good speech recognition programs let users customize them to their needs. The features that enable this include:
- Language weighting. This feature tells the algorithm to give special attention to certain words, such as those spoken frequently or that are unique to the conversation or subject. For example, the software can be trained to listen for specific product references.
- Acoustic training. The software tunes out ambient noise that pollutes spoken audio. Software programs with acoustic training can distinguish speaking style, pace and volume amid the din of many people speaking in an office.
- Speaker labeling. This capability enables a program to label individual participants and identify their specific contributions to a conversation.
- Profanity filtering. Here, the software filters out undesirable words and language.
What are the different speech recognition algorithms?
The power behind speech recognition features comes from a set of algorithms and technologies. They include the following:
- Hidden Markov model. HMMs are used in autonomous systems where a state is partially observable or when all of the information necessary to make a decision is not immediately available to the sensor (in speech recognition's case, a microphone). An example of this is in acoustic modeling, where a program must match linguistic units to audio signals using statistical probability.
- Natural language processing. NLP eases and accelerates the speech recognition process.
- N-grams. This simple approach to language models creates a probability distribution for a sequence. An example would be an algorithm that looks at the last few words spoken, approximates the history of the sample of speech and uses that to determine the probability of the next word or phrase that will be spoken.
- Artificial intelligence. AI and machine learning methods like deep learning and neural networks are common in advanced speech recognition software. These systems use grammar, structure, syntax and composition of audio and voice signals to process speech. Machine learning systems gain knowledge with each use, making them well suited for nuances like accents.
What are the advantages of speech recognition?
There are several advantages to using speech recognition software, including the following:
- Machine-to-human communication. The technology enables electronic devices to communicate with humans in natural language or conversational speech.
- Readily accessible. This software is frequently installed in computers and mobile devices, making it accessible.
- Easy to use. Well-designed software is straightforward to operate and often runs in the background.
- Continuous, automatic improvement. Speech recognition systems that incorporate AI become more effective and easier to use over time. As systems complete speech recognition tasks, they generate more data about human speech and get better at what they do.
What are the disadvantages of speech recognition?
While convenient, speech recognition technology still has a few issues to work through. Limitations include:
- Inconsistent performance. The systems may be unable to capture words accurately because of variations in pronunciation, lack of support for some languages and inability to sort through background noise. Ambient noise can be especially challenging. Acoustic training can help filter it out, but these programs aren't perfect. Sometimes it's impossible to isolate the human voice.
- Speed. Some speech recognition programs take time to deploy and master. The speech processing may feel relatively slow .
- Source file issues. Speech recognition success depends on the recording equipment used, not just the software.
The takeaway
Speech recognition is an evolving technology. It is one of the many ways people can communicate with computers with little or no typing. A variety of communications-based business applications capitalize on the convenience and speed of spoken communication that this technology enables.
Speech recognition programs have advanced greatly over 60 years of development. They are still improving, fueled in particular by AI.
Learn more about the AI-powered business transcription software in this Q&A with Wilfried Schaffner, chief technology officer of Speech Processing Solutions.
Continue Reading About speech recognition
- How can speech recognition technology support remote work?
- Automatic speech recognition may be better than you think
- Speech recognition use cases enable touchless collaboration
- Automated speech recognition gives CX vendor an edge
- Speech API from Mozilla's Web developer platform
Related Terms
Dig deeper on customer service and contact center.

7 ways AI is affecting the travel industry

natural language processing (NLP)

computational linguistics (CL)

Content lifecycle management is where business process management, content and records management intersect. Learn more about ...
As headless CMS rises in popularity, IT leaders might wonder if it's a fad or if it will permanently affect the content ...
Moving years' worth of SharePoint data out of on-premises storage to the cloud can be daunting, so choosing the correct migration...
Organizations have ramped up their use of communications platform as a service and APIs to expand communication channels between ...
Google will roll out new GenAI in Gmail and Docs first and then other apps throughout the year. In 2025, Google plans to ...
For successful hybrid meeting collaboration, businesses need to empower remote and on-site employees with a full suite of ...
KPIs and metrics are necessary to measure the quality of data. Organizations can use the dimensions of data quality to establish ...
The data management and analytics vendor's embeddable database now includes streaming capabilities via support for Kafka and ...
The vendor's latest update adds new customer insight capabilities, including an AI assistant, and industry-specific tools all ...
AI tools and systems are becoming an asset for many real estate endeavors. Explore seven top use cases for AI in the real estate ...
Learn the characteristics of supervised learning, unsupervised learning and semisupervised learning and how they're applied in ...
The GenAI pioneer went outside the AI realm for its second acquisition, looking to the smaller database analytics vendor for its ...
Epicor continues its buying spree with PIM vendor Kyklo, enabling manufacturers and distributors to gain visibility into what ...
Supply chains have a range of connection points -- and vulnerabilities. Learn which vulnerabilities hackers look for first and ...
As supplier relationships become increasingly complex and major disruptions continue, it pays to understand the top supply chain ...
How Does Speech Recognition Work? (9 Simple Questions Answered)
- by Team Experts
- July 2, 2023 July 3, 2023
Discover the Surprising Science Behind Speech Recognition – Learn How It Works in 9 Simple Questions!
Speech recognition is the process of converting spoken words into written or machine-readable text. It is achieved through a combination of natural language processing , audio inputs, machine learning , and voice recognition . Speech recognition systems analyze speech patterns to identify phonemes , the basic units of sound in a language. Acoustic modeling is used to match the phonemes to words , and word prediction algorithms are used to determine the most likely words based on context analysis . Finally, the words are converted into text.
What is Natural Language Processing and How Does it Relate to Speech Recognition?
How do audio inputs enable speech recognition, what role does machine learning play in speech recognition, how does voice recognition work, what are the different types of speech patterns used for speech recognition, how is acoustic modeling used for accurate phoneme detection in speech recognition systems, what is word prediction and why is it important for effective speech recognition technology, how can context analysis improve accuracy of automatic speech recognition systems, common mistakes and misconceptions.
Natural language processing (NLP) is a branch of artificial intelligence that deals with the analysis and understanding of human language. It is used to enable machines to interpret and process natural language, such as speech, text, and other forms of communication . NLP is used in a variety of applications , including automated speech recognition , voice recognition technology , language models, text analysis , text-to-speech synthesis , natural language understanding , natural language generation, semantic analysis , syntactic analysis, pragmatic analysis, sentiment analysis, and speech-to-text conversion. NLP is closely related to speech recognition , as it is used to interpret and understand spoken language in order to convert it into text.
Audio inputs enable speech recognition by providing digital audio recordings of spoken words . These recordings are then analyzed to extract acoustic features of speech, such as pitch, frequency, and amplitude. Feature extraction techniques , such as spectral analysis of sound waves, are used to identify and classify phonemes . Natural language processing (NLP) and machine learning models are then used to interpret the audio recordings and recognize speech. Neural networks and deep learning architectures are used to further improve the accuracy of voice recognition . Finally, Automatic Speech Recognition (ASR) systems are used to convert the speech into text, and noise reduction techniques and voice biometrics are used to improve accuracy .
Machine learning plays a key role in speech recognition , as it is used to develop algorithms that can interpret and understand spoken language. Natural language processing , pattern recognition techniques , artificial intelligence , neural networks, acoustic modeling , language models, statistical methods , feature extraction , hidden Markov models (HMMs), deep learning architectures , voice recognition systems, speech synthesis , and automatic speech recognition (ASR) are all used to create machine learning models that can accurately interpret and understand spoken language. Natural language understanding is also used to further refine the accuracy of the machine learning models .
Voice recognition works by using machine learning algorithms to analyze the acoustic properties of a person’s voice. This includes using voice recognition software to identify phonemes , speaker identification, text normalization , language models, noise cancellation techniques , prosody analysis , contextual understanding , artificial neural networks, voice biometrics , speech synthesis , and deep learning . The data collected is then used to create a voice profile that can be used to identify the speaker .
The different types of speech patterns used for speech recognition include prosody , contextual speech recognition , speaker adaptation , language models, hidden Markov models (HMMs), neural networks, Gaussian mixture models (GMMs) , discrete wavelet transform (DWT), Mel-frequency cepstral coefficients (MFCCs), vector quantization (VQ), dynamic time warping (DTW), continuous density hidden Markov model (CDHMM), support vector machines (SVM), and deep learning .
Acoustic modeling is used for accurate phoneme detection in speech recognition systems by utilizing statistical models such as Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs). Feature extraction techniques such as Mel-frequency cepstral coefficients (MFCCs) are used to extract relevant features from the audio signal . Context-dependent models are also used to improve accuracy . Discriminative training techniques such as maximum likelihood estimation and the Viterbi algorithm are used to train the models. In recent years, neural networks and deep learning algorithms have been used to improve accuracy , as well as natural language processing techniques .
Word prediction is a feature of natural language processing and artificial intelligence that uses machine learning algorithms to predict the next word or phrase a user is likely to type or say. It is used in automated speech recognition systems to improve the accuracy of the system by reducing the amount of user effort and time spent typing or speaking words. Word prediction also enhances the user experience by providing faster response times and increased efficiency in data entry tasks. Additionally, it reduces errors due to incorrect spelling or grammar, and improves the understanding of natural language by machines. By using word prediction, speech recognition technology can be more effective , providing improved accuracy and enhanced ability for machines to interpret human speech.
Context analysis can improve the accuracy of automatic speech recognition systems by utilizing language models, acoustic models, statistical methods , and machine learning algorithms to analyze the semantic , syntactic, and pragmatic aspects of speech. This analysis can include word – level , sentence- level , and discourse-level context, as well as utterance understanding and ambiguity resolution. By taking into account the context of the speech, the accuracy of the automatic speech recognition system can be improved.
- Misconception : Speech recognition requires a person to speak in a robotic , monotone voice. Correct Viewpoint: Speech recognition technology is designed to recognize natural speech patterns and does not require users to speak in any particular way.
- Misconception : Speech recognition can understand all languages equally well. Correct Viewpoint: Different speech recognition systems are designed for different languages and dialects, so the accuracy of the system will vary depending on which language it is programmed for.
- Misconception: Speech recognition only works with pre-programmed commands or phrases . Correct Viewpoint: Modern speech recognition systems are capable of understanding conversational language as well as specific commands or phrases that have been programmed into them by developers.
Speech Recognition: Definition, Importance and Uses

Transkriptor 2024-01-17
Speech recognition, known as voice recognition or speech-to-text, is a technological development that converts spoken language into written text. It has two main benefits, these include enhancing task efficiency and increasing accessibility for everyone including individuals with physical impairments.
The alternative of speech recognition is manual transcription. Manual transcription is the process of converting spoken language into written text by listening to an audio or video recording and typing out the content.
There are many speech recognition software, but a few names stand out in the market when it comes to speech recognition software; Dragon NaturallySpeaking, Google's Speech-to-Text and Transkriptor.
The concept behind "what is speech recognition?" pertains to the capacity of a system or software to understand and transform oral communication into written textual form. It functions as the fundamental basis for a wide range of modern applications, ranging from voice-activated virtual assistants such as Siri or Alexa to dictation tools and hands-free gadget manipulation.
The development is going to contribute to a greater integration of voice-based interactions into an individual's everyday life.

What is Speech Recognition?
Speech recognition, known as ASR, voice recognition or speech-to-text, is a technological process. It allows computers to analyze and transcribe human speech into text.
How does Speech Recognition work?
Speech recognition technology works similar to how a person has a conversation with a friend. Ears detect the voice, and the brain processes and understands.The technology does, but it involves advanced software as well as intricate algorithms. There are four steps to how it works.
The microphone records the sounds of the voice and converts them into little digital signals when users speak into a device. The software processes the signals to exclude other voices and enhance the primary speech. The system breaks down the speech into small units called phonemes.
Different phonemes give their own unique mathematical representations by the system. It is able to differentiate between individual words and make educated predictions about what the speaker is trying to convey.
The system uses a language model to predict the right words. The model predicts and corrects word sequences based on the context of the speech.
The textual representation of the speech is produced by the system. The process requires a short amount of time. However, the correctness of the transcription is contingent on a variety of circumstances including the quality of the audio.
What is the importance of Speech Recognition?
The importance of speech recognition is listed below.
- Efficiency: It allows for hands-free operation. It makes multitasking easier and more efficient.
- Accessibility: It provides essential support for people with disabilities.
- Safety: It reduces distractions by allowing hands-free phone calls.
- Real-time translation: It facilitates real-time language translation. It breaks down communication barriers.
- Automation: It powers virtual assistants like Siri, Alexa, and Google Assistant, streamlining many daily tasks.
- Personalization: It allows devices and apps to understand user preferences and commands.

What are the Uses of Speech Recognition?
The 7 uses of speech recognition are listed below.
- Virtual Assistants. It includes powering voice-activated assistants like Siri, Alexa, and Google Assistant.
- Transcription services. It involves converting spoken content into written text for documentation, subtitles, or other purposes.
- Healthcare. It allows doctors and nurses to dictate patient notes and records hands-free.
- Automotive. It covers enabling voice-activated controls in vehicles, from playing music to navigation.
- Customer service. It embraces powering voice-activated IVRs in call centers.
- Educatio.: It is for easing in language learning apps, aiding in pronunciation, and comprehension exercises.
- Gaming. It includes providing voice command capabilities in video games for a more immersive experience.
Who Uses Speech Recognition?
General consumers, professionals, students, developers, and content creators use voice recognition software. Voice recognition sends text messages, makes phone calls, and manages their devices with voice commands. Lawyers, doctors, and journalists are among the professionals who employ speech recognition. Using speech recognition software, they dictate domain-specific information.
What is the Advantage of Using Speech Recognition?
The advantage of using speech recognition is mainly its accessibility and efficiency. It makes human-machine interaction more accessible and efficient. It reduces the human need which is also time-consuming and open to mistakes.
It is beneficial for accessibility. People with hearing difficulties use voice commands to communicate easily. Healthcare has seen considerable efficiency increases, with professionals using speech recognition for quick recording. Voice commands in driving settings help maintain safety and allow hands and eyes to focus on essential duties.
What is the Disadvantage of Using Speech Recognition?
The disadvantage of using speech recognition is its potential for inaccuracies and its reliance on specific conditions. Ambient noise or accents confuse the algorithm. It results in misinterpretations or transcribing errors.
These inaccuracies are problematic. They are crucial in sensitive situations such as medical transcribing or legal documentation. Some systems need time to learn how a person speaks in order to work correctly. Voice recognition systems probably have difficulty interpreting multiple speakers at the same time. Another disadvantage is privacy. Voice-activated devices may inadvertently record private conversations.
What are the Different Types of Speech Recognition?
The 3 different types of speech recognition are listed below.
- Automatic Speech Recognition (ASR)
- Speaker-Dependent Recognition (SDR)
- Speaker-Independent Recognition (SIR)
Automatic Speech Recognition (ASR) is one of the most common types of speech recognition . ASR systems convert spoken language into text format. Many applications use them like Siri and Alexa. ASR focuses on understanding and transcribing speech regardless of the speaker, making it widely applicable.
Speaker-Dependent recognition recognizes a single user's voice. It needs time to learn and adapt to their particular voice patterns and accents. Speaker-dependent systems are very accurate because of the training. However, they struggle to recognize new voices.
Speaker-independent recognition interprets and transcribes speech from any speaker. It does not care about the accent, speaking pace, or voice pitch. These systems are useful in applications with many users.
What Accents and Languages Can Speech Recognition Systems Recognize?
The accents and languages that speech recognition systems can recognize are English, Spanish, and Mandarin to less common ones. These systems frequently incorporate customized models for distinguishing dialects and accents. It recognizes the diversity within languages. Transkriptor, for example, as a dictation software, supports over 100 languages.
Is Speech Recognition Software Accurate?
Yes, speech recognition software is accurate above 95%. However, its accuracy varies depending on a number of things. Background noise and audio quality are two examples of these.
How Accurate Can the Results of Speech Recognition Be?
Speech recognition results can achieve accuracy levels of up to 99% under optimal conditions. The highest level of speech recognition accuracy requires controlled conditions such as audio quality and background noises. Leading speech recognition systems have reported accuracy rates that exceed 99%.
How Does Text Transcription Work with Speech Recognition?
Text transcription works with speech recognition by analyzing and processing audio signals. Text transcription process starts with a microphone that records the speech and converts it to digital data. The algorithm then divides the digital sound into small pieces and analyzes each one to identify its distinct tones.
Advanced computer algorithms aid the system for matching these sounds to recognized speech patterns. The software compares these patterns to a massive language database to find the words users articulated. It then brings the words together to create a logical text.
How are Audio Data Processed with Speech Recognition?
Speech recognition processes audio data by splitting sound waves, extracting features, and mapping them to linguistic parts. The system collects and processes continuous sound waves when users speak into a device. The software advances to the feature extraction stage.
The software isolates specific features of the sound. It focuses on phonemes that are crucial for identifying one phoneme from another. The process entails evaluating the frequency components.
The system then starts using its trained models. The software combines the extracted features to known phonemes by using vast databases and machine learning models.
The system takes the phonemes, and puts them together to form words and phrases. The system combines technology skills and language understanding to convert noises into intelligible text or commands.
What is the best speech recognition software?
The 3 best speech recognition software are listed below.
Transkriptor
- Dragon NaturallySpeaking
- Google's Speech-to-Text
However, choosing the best speech recognition software depends on personal preferences.

Transkriptor is an online transcription software that uses artificial intelligence for quick and accurate transcription. Users are able to translate their transcripts with a single click right from the Transkriptor dashboard. Transkriptor technology is available in the form of a smartphone app, a Google Chrome extension, and a virtual meeting bot. It is compatible with popular platforms like Zoom, Microsoft Teams, and Google Meet which makes it one of the Best Speech Recognition Software.
Dragon NaturallySpeaking allows users to transform spoken speech into written text. It offers accessibility as well as adaptations for specific linguistic languages. Users like software’s adaptability for different vocabularies.

Google's Speech-to-Text is widely used for its scalability, integration options, and ability to support multiple languages. Individuals use it in a variety of applications ranging from transcription services to voice-command systems.
Is Speech Recognition and Dictation the Same?
No, speech recognition and dictation are not the same. Their principal goals are different, even though both voice recognition and dictation make conversion of spoken language into text. Speech recognition is a broader term covering the technology's ability to recognize and analyze spoken words. It converts them into a format that computers understand.
Dictation refers to the process of speaking aloud for recording. Dictation software uses speech recognition to convert spoken words into written text.
What is the Difference between Speech Recognition and Dictation?
The difference between speech recognition and dictation are related to their primary purpose, interactions, and scope. Itss primary purpose is to recognize and understand spoken words. Dictation has a more definite purpose. It focuses on directly transcribing spoken speech into written form.
Speech Recognition covers a wide range of applications in terms of scope. It helps voice assistants respond to user questions. Dictation has a narrower scope.
It provides a more dynamic interactive experience, often allowing for two-way dialogues. For example, virtual assistants such as Siri or Alexa not only understand user requests but also provide feedback or answers. Dictation works in a more basic fashion. It's typically a one-way procedure in which the user speaks and the system transcribes without the program engaging in a response discussion.
Frequently Asked Questions
Transkriptor stands out for its ability to support over 100 languages and its ease of use across various platforms. Its AI-driven technology focuses on quick and accurate transcription.
Yes, modern speech recognition software is increasingly adept at handling various accents. Advanced systems use extensive language models that include different dialects and accents, allowing them to accurately recognize and transcribe speech from diverse speakers.
Speech recognition technology greatly enhances accessibility by enabling voice-based control and communication, which is particularly beneficial for individuals with physical impairments or motor skill limitations. It allows them to operate devices, access information, and communicate effectively.
Speech recognition technology's efficiency in noisy environments has improved, but it can still be challenging. Advanced systems employ noise cancellation and voice isolation techniques to filter out background noise and focus on the speaker's voice.
Speech to Text
Convert your audio and video files to text
Audio to Text
Video Transcription
Transcription Service
Privacy Policy
Terms of Service
Contact Information
© 2024 Transkriptor

CIC Text to Speech Engines Technical Reference
User-defined Dictionaries
Beginning with CIC 2019 R3, Interaction Text to Speech (ITTS) supports user-defined dictionaries. This feature allows you to define specific pronunciations of names and words to use for speech recognition and in the playing of prompts in speech synthesis.
Pronunciation Lexicon Specification (PLS) is a definition that allows automated speech recognition and text-to-speech engines to use external dictionaries during speech recognition and speech synthesis. For more information, see https://www.w3.org/TR/pronunciation-lexicon/ .
You can set specific word and name pronunciations in a lexicon file overriding default pronunciation, when it improves customer understanding or experience.
The VoiceXML standard supports a feature that can use external dictionaries with speech recognition and TTS engines. For speech recognition, you specify the dictionary in the grammar file in a specially-defined lexicon element. You can specify multiple dictionaries at different points in the IVR dialog flow. For TTS prompts, you specify the dictionary in the lexicon element defined inside a prompt element. For more information about definitions and the VoiceXML standard, see https://www.w3.org/TR/voicexml20/ .
In CIC, reference the VoiceXML document containing the lexicon in the Document URI field of a handler subroutine. For more information about handler setup, see the https://help.genesys.com/cic/mergedProjects/wh_tr/desktop/pdfs/voicexml_tr.pdf . For more information about specifying lexicons in grammar files, see https://www.w3.org/TR/speech-grammar/#S4.10 .
SSML: ITTS can receive Speech Synthesis Markup Language (SSML) documents or strings directly as input and process the specified prompts. You specify the user dictionary in a specially-defined lexicon element that must comply with SSML syntax. In CIC, the SSML string referencing the lexicon is a string variable in the Optional Parameters field of a handler subroutine. For more information, see https://www.w3.org/TR/speech-synthesis/#S3.1.4 .
Example of a lexicon file with an alternate pronunciation for the name Anna
Example of lexicon usage in SSML
Example of lexicon usage in VoiceXML
Copyright and trademark
- Cooperation Models
- Dedicated Team
- Fixed price projects
- Time & Material
- Web Application Development
- Software Development
- Mobile Application Development
- Software Development Outsourcing
- High-Converting Landing Page
- UI/UX Design
- QA Consulting
- C#/.NET Development
- JavaScript Development
- Progressive Web App Development
- React Native App Development
- Native App Development
filetypes:pdf|jpeg|png|doc|exe
Choose file (pdf,jpeg,png,doc,xls, max 5Mb)
Home » Blog » Voice User Interface and Speech Recognition
Voice User Interface and Speech Recognition
Hanna Skryl
Voice user interfaces (VUIs) are built to provide speech recognition capabilities to assist users in utilizing their smart devices, and generally, they are a cornerstone of the modern user experience. Voice recognition not only refers to the traditional functionality of text to speech but also to improved integration of voice into IoT applications, and many more.
VUIs can be an excellent foundation for building new types of applications that provide significant value to users and businesses. The second era of voice user interfaces that we live in is also the age of advances in technology, graphics processing, and cloud computing, which is all giving rise to AI and ML. And speech recognition technology is the technology that helps reveal the true potential of AI to the world. In this article, we’ll take a look at how speech recognition technology works, what features make it so appealing, and what challenges one has to be ready to face when diving into this exciting field.
How voice technology and speech recognition work
The first era of VUIs began in the early 2000s. Interactive voice response (IVR) systems that were capable of understanding human speech were growing in popularity then. They were not without flaws but what is important is that they paved the way for future developments in the field and laid the foundations for what we see in speech recognition today.
Simple IVR software allowed pre-recording commands and executed these commands upon receiving them from humans. However, if we talk about advanced IVR systems, we have to talk about the systems that included speech-recognition software allowing a caller to communicate with a computer using simple voice commands. It let serve high call volumes with decent efficiency. Routing callers to the right menu and to the operator or sales agent that were capable of assisting them. Phone banking, phone surveys, and televoting are the most common use cases of IVRs.
Voice technology, as we know it now, is the product of the second era of VUIs. Virtual assistants like Alexa, Siri, and Google Assistant are all products of the second era of voice user interfaces. So, how do they actually enable voice recognition?
In short, voice user interfaces work according to the following algorithm:
- Speech recognition software converts input analog waves into a digital format
- The audio input is broken down into separate sounds, phonemes
- The software analyzes each of them and compares to words from the dictionary
- Speech is converted to on-screen text or computer commands
This workflow is enabled by Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). Automatic Speech Recognition is the process of transforming spoken language into text. This step is known as transcription. The computer recognizes the words said. Next, we need to interpret what the computer heard and understood so that it could act upon those commands. Natural Language Understanding is what allows semantic interpretation. It is a branch of NLP and one of the key AI operations that helps interpret human language. Going beyond speech recognition, it is capable of determining the speaker’s intent. NLU recognizes patterns within a human language and lets a computer engage in a meaningful dialog with its users in a natural, interactive, conversational manner. This process can be reduced to four elements described in the scheme below.

The key success factor here is the correct interpretation of the command uttered. Accordingly, one will be able to take full advantage of voice technology only if the right technology framework is chosen for the tasks of ASR and NLU.
Benefits of voice user interfaces
User interfaces let people interact with computers of any type, including PCs, smartphones, tablets, and game consoles. Accordingly, modern UI designs are expected to give people the confidence to use computers as if they were their own personal assistants, responding to all sorts of requests and commands. This human-centric nature of UI designs is what drives innovation in the field. Thus, voice-enabled technology has become the next-generation interface paradigm, promising significant potential for improving user experience and productivity.

Voice-user interfaces empowered millions of people to gain better control over their homes, businesses, and phones. Of course, VUIs are different from graphical UIs. The same guidelines cannot be applied to them both. But voice-enabled UIs have a number of distinct advantages that are illustrated in the following examples:
1. Speed and efficiency
VUIs allow for hands-free interactions. This form of interaction removes the need to tap on the screen or press buttons. Speech is the primary mode of human communication. For centuries, people have been building relationships through speech. That is why technologies that enable customers to do the same are highly valued. Besides, dictating text messages was proven to be faster than typing, even for expert texters. Hands-free interactions save time and increase efficiency, at least in some cases.
With that in mind, a group of Microsoft researchers has recently presented the concept of place-onas. These place-onas serve as hypothetical archetypes of places in which the envisioned application is expected to be used. The examples include a place-ona 'in a library wearing headphones', a 'cooking' place-ona, a 'nightclub' place-ona, and a 'driving' place-ona. Their hands, eyes, and ears can be either free or busy, and their voice can be either restricted or free. This affects the possibility to use VUIs and is something the app development team must always keep in mind.
2. Intuitiveness and convenience
Quality VUIs have to provide intuitive user flow, and technological innovations promise to continue increasing the intuitiveness of voice interfaces. VUIs require less cognitive effort from a user than graphical UIs. Moreover, everyone – be it a little child or your grandmother – knows how to talk. So, designers of VUIs are generally better positioned compared to GUIs designers who risk delivering unintuitive menus and exposing users to the discomfort of poor interface design. It is probable that VUI creators won’t have to instruct customers on how to use the technology. Instead, people can ask their voice assistant if help is needed.
Voice is today’s vehicle for human-machine interactions. This democratizes the use of technology by letting users interact with their computers as if they were speaking with a friend. Still, there is a challenge of understanding users’ intent and responding appropriately to their commands. But a new lexicon of commonly-understood and intuitive cues for voice control is emerging to enable people to intuitively navigate between different AI systems.
3. More ‘human’ experiences and empathy
Experiences with accurate speech recognition software promise a more humane conversation. Today's consumers seek personality in voice-based man-machine interactions. On one hand, they want a machine that understands and expresses thoughts like their own – this is known as empathic language. On the other hand, they want a machine that speaks in their native language and that brings the speed, efficiency, and naturalness of spoken human interactions. The combination of the two allows recognizing personality in speech, including emotions, intentions, and features of the speech that the customer uses to express them.
Also, using voice, one can better convey the tone of a message. Tone and intonation play a large role in communication, and voice-enabled technology has this advantage over other standard technology choices. And it works both ways. Virtual assistants, when unable to understand the command, can reply in an easy-going way so that users don’t feel frustrated. Meanwhile, users are free to formulate commands as they will, and intelligent voice interfaces will react to the intonation, tone of the voice and choice of words. Besides, hearing the virtual assistant’s voice answering users’ commands or questions may bring comfort to those who feel low or vulnerable.
At the same time, however, voice-enabled technologies allow for natural language interaction, enabling users to focus on the intended message and not worry about being misunderstood or misrepresented.

Limitations to using voice user interfaces
All that said, speech recognition technology is still not a cure-all. Sometimes, it is more convenient for users to go for a traditional graphical interface instead. The following list will give you an idea of the presumable limitations in using voice-assisted applications:
Public spaces and privacy - The main problem with having a verbal interface is that users will sometimes find themselves in a position where they cannot speak freely. This can be due to physical reasons or privacy concerns. First, voice commands and voice-user interfaces both on mobile devices and computers can be used in different settings and in different contexts. However, it is a very impractical thing to do in public spaces. Voice can be limited due to environmental noise or someone else talking next to the person using the assistant. This may result in errors in communication n between a voice assistant and a user.
Second, VUIs make it harder to be private, and not only at the time of speaking but actually overall. It refers to overhearing dictated and arriving messages as well as voice assistants listening to its household 24/7, monitoring more and more elements of our daily lives.
Some users express discomfort talking to a computer - Another point of concern is that some people feel uncomfortable when they deal with a voice user interface. They might find it difficult to pick the right words to address assistants verbally or just speak out loud, even when nobody else is around. For them, it is unnatural to speak to a machine. So, every slight recognition error from a computer or their own inability to provide a computer with sufficient input information discourages these users from going on trying to perform tasks with voice interfaces. Voice interaction is something new and if a person has not been trained to use a voice-based interface, they might struggle with it.
Some users prefer texting - Although voice user interfaces are becoming more and more common, texting may still be the preferred method of communication for some people. A graphical interface allows users to type with more precision than interaction with a voice UI. Sometimes, it may take less time to communicate using voice, but young users are simply more accustomed to multitasking between different applications on their smart devices, some of which are navigated best manually. Some behavioral factors are also in play when it comes to using voice UI. Thus, people who prefer to communicate verbally will get used to VUIs faster and more zestfully.
The challenges of voice recognition technology adoption
Apart from the marketable advantages that new technology brings to the table, it also comes with certain challenges, especially in the areas of accuracy, integration with traditional technology, data privacy, and cost. Some of these challenges are already being overcome by many major technology vendors but there's always room for improvement.
Accuracy. Speech recognition technology is not 100% accurate. Although accuracy has been an issue since technology emergence, it is a moving target. Due to developments in the field of deep learning , speech recognition accuracy improvement is a rapid and dynamically evolving process. Therefore, the customer’s expectations regarding this matter are now as high as never before. Deep learning is moving toward solving such problems as voice systems’ performance in noisy environments. For instance, Google has already managed to achieve 95% machine learning word accuracy and expects to receive a variety of new data for training to overcome all the limitations to voice or speech recognition accuracy.
Integration. The integration of speech recognition technology poses another challenge to voice recognition technology adoption. Those who wish to make voice recognition part of their smart products or apps must understand the minimum requirements: the needed time and resources. Thus, it is essential to have a team whose skills allow simplifying the integration process. This will speed up the process and allow focusing on the bigger picture. Two major problems are the large complexity of the voice recognition technology and the significant increase in the computational power needed to perform automated speech recognition. The team has to be experts in speech recognition, computer vision, and machine learning technologies to implement voice recognition software in the most efficient way.
Data privacy. We’ve mentioned privacy-related challenges before in the context of limitations to using voice user interfaces. Adding an extra layer of security is the right call to make under these circumstances. Integrating voice recognition technology means entrusting third parties with a large amount of data that has to remain secure. So, addressing the challenges of voice recognition technology adoption, one must take care of building a strong end-to-end encryption infrastructure with full trust. Then, sending audios about personal or enterprise internal information, a user could be sure that their data remains confidential and speech recognition accuracy – still relatively high. Besides, encrypted data can be effectively used for training voice recognition models without sacrificing users’ privacy.
Cost. The adoption of voice technology is pricey. Yet, businesses that are resolved to implement speech recognition technology (so that accuracy and privacy characteristics were at their best) are normally expecting to pay a considerable amount of money for it. Decoding a human voice is no simple task. As a result, voice recognition systems become quite expensive to set up. However, opting for automatic voice recognition software, one can save their finances that could be otherwise spent to employ additional staff, such as transcriptionists or editors.
Voice user interfaces lie at the heart of the new UI paradigm. Experience designers, in particular, are always in search of innovative design techniques and VUIs are a natural place to start. Despite VUIs’ steady growth in popularity, some users still do not trust the technology and report difficulties in navigating and interacting with voice interfaces. At the same time, speech-enabled interfaces prove to be a powerful tool to bring users closer to the features and functions that businesses want them to experience. It is clear that we have yet work to do to bridge the gap between business requirements and the technical capabilities of speech interfaces. However, it is already within our reach to accept those challenges and do our best to create excellent experiences for our users.

© 2020, Vilmate LLC

Choose file (pdf,jpeg,png,doc,xls)
“I’m looking forward to keep on working with Vilmate”
A great technical team and a great partner we’ve been lucky to come across. We have been working together for many years and I’m looking forward to keep on working with Vilmate...
They are “our team” – not “Vilmate's team” and I like that a lot!
Mobile-Based Search Engine Dictionary for Information Technology Students
19 Pages Posted: 17 Oct 2019
Nemia Galang
President Ramon Magsaysay State University
Ruben D. Espejo, Jr.
Affiliation not provided to ssrn.
Date Written: October 4, 2019
Modern technology uses speech recognition software to speed up the process of gathering inputs from the user to save significant amount of time for every process. While this process is complex in and of itself, it is further complicated by the fact (the user) from different parts of the country have varying accent and pronounce the same words differently. Therefore, the proponent intends to create a more speaker-independent Speech Recognition Search Engine for I.T. Dictionary to maintain the speed and accuracy of transcription. An increasing number of people use their smart phones for a several of reason either to connect with friends, conduct e-commerce transactions, browse the Internet, etc. But for those who in the I.T Field, there is an urgent need for a dictionary, to embrace this new mode of information dissemination. Due to a variety of reasons, people in Information Technology Students or even Professionals finds all I.T terms difficult to memorize or just even understand. They prefer to use their mobile smart phone to get information quickly to get the immediate answer for their query. This research study is an attempt to provide a mobile application solution.
Keywords: Keywords: e-dictionary, word search, android-based application, mobile app
Suggested Citation: Suggested Citation
Nemia Galang (Contact Author)
President ramon magsaysay state university ( email ).
Philippines
Do you have a job opening that you would like to promote on SSRN?
Paper statistics, related ejournals, linguistic anthropology ejournal.
Subscribe to this fee journal for more curated articles on this topic
Communication & Technology eJournal
Educational & instructional communication ejournal, legal, medical & applied linguistics ejournal.
- Stack Overflow Public questions & answers
- Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers
- Talent Build your employer brand
- Advertising Reach developers & technologists worldwide
- Labs The future of collective knowledge sharing
- About the company
Collectives™ on Stack Overflow
Find centralized, trusted content and collaborate around the technologies you use most.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Get early access and see previews of new features.
Speech Recognition module is giving a dictionary as well as a list. Any solutions?
I tried to run the code. It worked very well but leaving a dictionary after being executed.
This is the code: Code for the wishMe function which is executed at the starting of the program
- artificial-intelligence
- speech-recognition
- post the code and not the pictures of code. Users need to be able to replicate the problem quickly, which text allows for (and pictures do not). stackoverflow.com/help/how-to-ask – D.L Commented Jan 3, 2023 at 10:48
It seems you make use of the package SpeechRecognition .
On line 54 of main.py you call r.recognize_google() . Looking at the source code of this method, on line 917 and 918 it shows that the authors of the package print the results when the method is called.
Unfortunately there is no easy way to suppress print statements in imported code. If it really bothers you, you can modify stdout like they suggest in this thread. Or you can fork the repository and change the source code so results only print when you want to.
Your Answer
Reminder: Answers generated by artificial intelligence tools are not allowed on Stack Overflow. Learn more
Sign up or log in
Post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged python-3.x artificial-intelligence speech-recognition or ask your own question .
- Featured on Meta
- Upcoming sign-up experiments related to tags
- The return of Staging Ground to Stack Overflow
- Policy: Generative AI (e.g., ChatGPT) is banned
- Should we burninate the [lib] tag?
Hot Network Questions
- Does John 14:13 mean if we literally pray for anything God will act?
- How exactly does a seashell make the humming sound?
- Isn't it problematic to look at the data to decide to use a parametric vs. non-parametric test?
- Any problem passing a Salesforce security review if LWCs are using GraphQL?
- C# Linked List implementation
- Short story about soldiers who are fighting against an enemy which turns out to be themselves
- In an interview how to ask about access to internal job postings?
- RAW, do transparent obstacles generally grant Total Cover?
- Will shading an AC condenser reduce cost or improve effectiveness?
- Can a unique position be deduced if pieces are replaced by checkers (can see piece color but not type)
- Is it legal to initialize an array via a functor which takes the array itself as a parameter by reference?
- Is it possible to animate a curve along it's own path?
- Is FDISK /MBR really undocumented, and why?
- Defining the probability space for rolling a dice infinitely many times
- Can a planet have a warm, tropical climate both at the poles and at the equator?
- Historically are there any documented attempts at finding algorithms that are asymptotically faster than the FFT for the Discrete Fourier Transform?
- HTTP: how likely are you to be compromised by using it just once?
- Frames given by SciDraw package are not closed
- Proper way to write C code that injects message into /var/log/messages?
- What gets to be called a "proper class?"
- Why inductor don't discharge completely even when the duty cycle is 50%?
- Proof/Reference to a claim about AC and definable real numbers
- Modify the width of each digit (0, 1, ..., 9) of a TTF font
- Design of very long serial signal systems
McDonald's is removing its AI drive-thru voice-ordering system from over 100 restaurants after its mishaps went viral
- McDonald's is removing its Automated Order Taker technology from over 100 restaurants.
- The fast-food chain collaborated with IBM in 2021 to develop and deploy the AI software.
- Videos showing flaws with the technology at McDonald's drive-thrus went viral in 2023.
The advent of generative AI was supposed to devastate jobs across industries, including restaurants.
Turns out it's not quite there yet.
McDonald's told franchise operators on Thursday that it is removing AI order-taking technology from over 100 drive-thrus, marking the end of a test period conducted with IBM.
A McDonald's spokesperson confirmed the decision to Business Insider in a statement, saying customers were introduced to the technology in 2021 when McDonald's entered a global partnership with IBM.
Under the partnership, IBM acquired McD Tech Labs, which McDonald's created after taking control of the AI speech company Apprente in 2019.
The two companies developed and deployed the technology during the test period to "determine if an automated voice ordering solution could simplify operations for crew and create a faster, improved experience for our fans."
McDonald's CEO Chris Kempczinski told CNBC in June 2021 that voice-recognition technology was accurate about 85% of the time, but human staff had to assist with about one in five orders.
Related stories
But the AI's failures went viral online.
Videos of drive-thru customers struggling to use the Automated Order Taker first gained attention on TikTok last year. Some customers said that the technology messed up their orders, causing frustration and annoyance.
One video showed a woman attempting to order water and a cup of vanilla ice cream. The AI system accounted for those items but incorrectly added four ketchup packets and three butter packets to her order.
In another video, a TikTok user said she ordered one large cup of sweet iced tea, but the AI-powered technology added nine cups of iced sweet tea instead.
Although McDonald's partnership with IBM on Automated Order Taker has ended, the food company said it would continue to explore how technology can improve its workflow.
"As we move forward, our work with IBM has given us the confidence that a voice ordering solution for drive-thru will be part of our restaurants' future," McDonald's told BI in the statement. "We see tremendous opportunity in advancing our restaurant technology and will continue to evaluate long-term, scalable solutions that will help us make an informed decision on a future voice ordering solution by the end of the year."
IBM said it would continue to work with McDonald's on other projects.
"This technology is proven to have some of the most comprehensive capabilities in the industry, fast and accurate in some of the most demanding conditions," the company said in a statement. "While McDonald's is reevaluating and refining its plans for AOT, we look forward to continuing to work with them on a variety of other projects."
The statement added that "IBM also is now in discussions and pilots with several Quick-Serve Restaurant clients who are interested in the AOT technology."
McDonald's began using AI technology at its restaurants as early as 2019, according to the National Restaurant News . It installed 700 AI-powered menu boards that included an automated suggestive-selling feature.
Watch: How Domino's makes 1 billion pizzas a year amid labor shortages
- Main content
COMMENTS
An in-depth tutorial on speech recognition with Python. Learn which speech recognition library gives the best results and build a full-featured "Guess The Word" game with it. ... Returns a dictionary with three keys: "success": ... If the "transcription" key of guess is not None, then the user's speech was transcribed and the inner loop is ...
Speech recognition is a capability that enables a program to process human speech into a written format. ... translation of speech from a verbal format to a text one whereas voice recognition just seeks to identify an individual user's voice. ... and included a spelling dictionary of 100,000 words. While speech technology had a limited ...
Speech recognition, also known as automatic speech recognition (ASR), speech-to-text (STT), and computer speech recognition, is a technology that enables a computer to recognize and convert spoken language into text. Speech recognition technology uses AI and machine learning models to accurately identify and transcribe different accents ...
A key part of any automatic speech recognition system is the lexicon. The lexicon can be tricky to define because it's sometimes used to mean different things depending on the context. In its most basic form, a lexicon is simply a set of words with their pronunciations broken down into phonemes, i.e. units of word pronunciation.
Speech recognition identifies the words a speaker says, while voice recognition recognizes the speaker's voice. Additionally, speech recognition takes normal human speech and uses NPL to respond in a way that mimics a real human response. Voice recognition technology is typically used on a computer, smartphone, or virtual assistant and uses ...
Automatic Speech Recognition (ASR), also known as speech-to-text, is the process by which a computer or electronic device converts human speech into written text. This technology is a subset of computational linguistics that deals with the interpretation and translation of spoken language into text by computers.
Speech recognition is an interdisciplinary subfield of computer science and computational linguistics that develops methodologies and technologies that enable the recognition and translation of spoken language into text by ... Speech recognition applications include voice user interfaces such as voice dialing (e.g. "call home"), call routing (e.g.
Speech recognition is the technology that allows a computer to recognize human speech and process it into text. It's also known as automatic speech recognition (ASR), speech-to-text, or computer speech recognition. Speech recognition systems rely on technologies like artificial intelligence (AI) and machine learning (ML) to gain larger ...
SpeechRecognition is a Python library that enables speech recognition with support for multiple engines and APIs, both online and offline.
Speech recognition is the capability of an electronic device to understand spoken words. A microphone records a person's voice and the hardware converts the signal from analog sound waves to digital audio. The audio data is then processed by software , which interprets the sound as individual words.
B) Right click or press and hold on the Speech Recognition notification area icon on the taskbar, and click/tap on Open the Speech Dictionary. 2. Click/tap on Change existing words. (see screenshot below) 3. Click/tap on Edit a word. (see screenshot below) 4.
Automatic Speech Recognition (ASR) is a technology that enables computers to understand and transcribe spoken language into text. It works by analyzing audio input, such as spoken words, and converting them into written text, typically in real-time. ASR systems use algorithms and machine learning techniques to recognize and interpret speech ...
Recognition: Calling the recognize_google () method (or another available recognition method) on the SpeechRecognition library to convert the audio data into text. Here's a simple example: Python. import speech_recognition as sr # Initialize recognizer class (for recognizing the speech) r = sr.Recognizer() # Reading Microphone as source ...
voice portal (vortal): A voice portal (sometimes called a vortal ) is a Web portal that can be accessed entirely by voice. Ideally, any type of information, service, or transaction found on the Internet could be accessed through a voice portal.
Speech recognition is the process of converting spoken words into written or machine-readable text. It is achieved through a combination of natural language processing, audio inputs, machine learning, and voice recognition. Speech recognition systems analyze speech patterns to identify phonemes, the basic units of sound in a language.
misheard or not recognized by using the "Speech Dictionary." Use the Speech Dictionary To use the Speech Dictionary, say "open Speech Dictionary." To add a word, click or say "Add a new word," and then follow the instructions in the wizard. To prevent a specific word from being dictated, click of say "prevent a word from
The importance of speech recognition is listed below. Efficiency: It allows for hands-free operation. It makes multitasking easier and more efficient. Accessibility: It provides essential support for people with disabilities. Safety: It reduces distractions by allowing hands-free phone calls.
However, pocketsphinx is very easy to use in terms of creating dictionaries from scratch and switching between different dictionaries on the fly programmatically. I'm trying to move over to vosk as a speech recognizer. And it does seem to decode speech much fast and more accurately. But thus far I haven't been able to find any information on ...
User-defined Dictionaries. Beginning with CIC 2019 R3, Interaction Text to Speech (ITTS) supports user-defined dictionaries. This feature allows you to define specific pronunciations of names and words to use for speech recognition and in the playing of prompts in speech synthesis. Pronunciation Lexicon Specification (PLS) is a definition that ...
In short, voice user interfaces work according to the following algorithm: Speech recognition software converts input analog waves into a digital format. The audio input is broken down into separate sounds, phonemes. The software analyzes each of them and compares to words from the dictionary. Speech is converted to on-screen text or computer ...
Otherwise, returns the raw API response as a JSON dictionary. Raises a ``speech_recognition.UnknownValueError`` exception if the speech is unintelligible. Raises a ``speech_recognition.RequestError`` exception if the speech recognition operation failed, if the key isn't valid, or if there is no internet connection.
Therefore, the proponent intends to create a more speaker-independent Speech Recognition Search Engine for I.T. Dictionary to maintain the speed and accuracy of transcription. An increasing number of people use their smart phones for a several of reason either to connect with friends, conduct e-commerce transactions, browse the Internet, etc.
It seems you make use of the package SpeechRecognition.. On line 54 of main.py you call r.recognize_google().Looking at the source code of this method, on line 917 and 918 it shows that the authors of the package print the results when the method is called.. Unfortunately there is no easy way to suppress print statements in imported code.
It let customers complete orders using AI voice recognition. ... In another video, a TikTok user said she ordered one large cup of sweet iced tea, but the AI-powered technology added nine cups of ...