Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.

7.2 Correlational Research
Learning objectives.
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of nonexperimental research.
What Is Correlational Research?
Correlational research is a type of nonexperimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variable do not apply to this kind of research.
The other reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, Allen Kanner and his colleagues thought that the number of “daily hassles” (e.g., rude salespeople, heavy traffic) that people experience affects the number of physical and psychological symptoms they have (Kanner, Coyne, Schaefer, & Lazarus, 1981). But because they could not manipulate the number of daily hassles their participants experienced, they had to settle for measuring the number of daily hassles—along with the number of symptoms—using self-report questionnaires. Although the strong positive relationship they found between these two variables is consistent with their idea that hassles cause symptoms, it is also consistent with the idea that symptoms cause hassles or that some third variable (e.g., neuroticism) causes both.
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure 7.2 “Results of a Hypothetical Study on Whether People Who Make Daily To-Do Lists Experience Less Stress Than People Who Do Not Make Such Lists” shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. It is how the study is conducted.
Figure 7.2 Results of a Hypothetical Study on Whether People Who Make Daily To-Do Lists Experience Less Stress Than People Who Do Not Make Such Lists

Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated. However, because some approaches to data collection are strongly associated with correlational research, it makes sense to discuss them here. The two we will focus on are naturalistic observation and archival data. A third, survey research, is discussed in its own chapter.
Naturalistic Observation
Naturalistic observation is an approach to data collection that involves observing people’s behavior in the environment in which it typically occurs. Thus naturalistic observation is a type of field research (as opposed to a type of laboratory research). It could involve observing shoppers in a grocery store, children on a school playground, or psychiatric inpatients in their wards. Researchers engaged in naturalistic observation usually make their observations as unobtrusively as possible so that participants are often not aware that they are being studied. Ethically, this is considered to be acceptable if the participants remain anonymous and the behavior occurs in a public setting where people would not normally have an expectation of privacy. Grocery shoppers putting items into their shopping carts, for example, are engaged in public behavior that is easily observable by store employees and other shoppers. For this reason, most researchers would consider it ethically acceptable to observe them for a study. On the other hand, one of the arguments against the ethicality of the naturalistic observation of “bathroom behavior” discussed earlier in the book is that people have a reasonable expectation of privacy even in a public restroom and that this expectation was violated.
Researchers Robert Levine and Ara Norenzayan used naturalistic observation to study differences in the “pace of life” across countries (Levine & Norenzayan, 1999). One of their measures involved observing pedestrians in a large city to see how long it took them to walk 60 feet. They found that people in some countries walked reliably faster than people in other countries. For example, people in the United States and Japan covered 60 feet in about 12 seconds on average, while people in Brazil and Romania took close to 17 seconds.
Because naturalistic observation takes place in the complex and even chaotic “real world,” there are two closely related issues that researchers must deal with before collecting data. The first is sampling. When, where, and under what conditions will the observations be made, and who exactly will be observed? Levine and Norenzayan described their sampling process as follows:
Male and female walking speed over a distance of 60 feet was measured in at least two locations in main downtown areas in each city. Measurements were taken during main business hours on clear summer days. All locations were flat, unobstructed, had broad sidewalks, and were sufficiently uncrowded to allow pedestrians to move at potentially maximum speeds. To control for the effects of socializing, only pedestrians walking alone were used. Children, individuals with obvious physical handicaps, and window-shoppers were not timed. Thirty-five men and 35 women were timed in most cities. (p. 186)
Precise specification of the sampling process in this way makes data collection manageable for the observers, and it also provides some control over important extraneous variables. For example, by making their observations on clear summer days in all countries, Levine and Norenzayan controlled for effects of the weather on people’s walking speeds.
The second issue is measurement. What specific behaviors will be observed? In Levine and Norenzayan’s study, measurement was relatively straightforward. They simply measured out a 60-foot distance along a city sidewalk and then used a stopwatch to time participants as they walked over that distance. Often, however, the behaviors of interest are not so obvious or objective. For example, researchers Robert Kraut and Robert Johnston wanted to study bowlers’ reactions to their shots, both when they were facing the pins and then when they turned toward their companions (Kraut & Johnston, 1979). But what “reactions” should they observe? Based on previous research and their own pilot testing, Kraut and Johnston created a list of reactions that included “closed smile,” “open smile,” “laugh,” “neutral face,” “look down,” “look away,” and “face cover” (covering one’s face with one’s hands). The observers committed this list to memory and then practiced by coding the reactions of bowlers who had been videotaped. During the actual study, the observers spoke into an audio recorder, describing the reactions they observed. Among the most interesting results of this study was that bowlers rarely smiled while they still faced the pins. They were much more likely to smile after they turned toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.

Naturalistic observation has revealed that bowlers tend to smile when they turn away from the pins and toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.
sieneke toering – bowling big lebowski style – CC BY-NC-ND 2.0.
When the observations require a judgment on the part of the observers—as in Kraut and Johnston’s study—this process is often described as coding . Coding generally requires clearly defining a set of target behaviors. The observers then categorize participants individually in terms of which behavior they have engaged in and the number of times they engaged in each behavior. The observers might even record the duration of each behavior. The target behaviors must be defined in such a way that different observers code them in the same way. This is the issue of interrater reliability. Researchers are expected to demonstrate the interrater reliability of their coding procedure by having multiple raters code the same behaviors independently and then showing that the different observers are in close agreement. Kraut and Johnston, for example, video recorded a subset of their participants’ reactions and had two observers independently code them. The two observers showed that they agreed on the reactions that were exhibited 97% of the time, indicating good interrater reliability.
Archival Data
Another approach to correlational research is the use of archival data , which are data that have already been collected for some other purpose. An example is a study by Brett Pelham and his colleagues on “implicit egotism”—the tendency for people to prefer people, places, and things that are similar to themselves (Pelham, Carvallo, & Jones, 2005). In one study, they examined Social Security records to show that women with the names Virginia, Georgia, Louise, and Florence were especially likely to have moved to the states of Virginia, Georgia, Louisiana, and Florida, respectively.
As with naturalistic observation, measurement can be more or less straightforward when working with archival data. For example, counting the number of people named Virginia who live in various states based on Social Security records is relatively straightforward. But consider a study by Christopher Peterson and his colleagues on the relationship between optimism and health using data that had been collected many years before for a study on adult development (Peterson, Seligman, & Vaillant, 1988). In the 1940s, healthy male college students had completed an open-ended questionnaire about difficult wartime experiences. In the late 1980s, Peterson and his colleagues reviewed the men’s questionnaire responses to obtain a measure of explanatory style—their habitual ways of explaining bad events that happen to them. More pessimistic people tend to blame themselves and expect long-term negative consequences that affect many aspects of their lives, while more optimistic people tend to blame outside forces and expect limited negative consequences. To obtain a measure of explanatory style for each participant, the researchers used a procedure in which all negative events mentioned in the questionnaire responses, and any causal explanations for them, were identified and written on index cards. These were given to a separate group of raters who rated each explanation in terms of three separate dimensions of optimism-pessimism. These ratings were then averaged to produce an explanatory style score for each participant. The researchers then assessed the statistical relationship between the men’s explanatory style as college students and archival measures of their health at approximately 60 years of age. The primary result was that the more optimistic the men were as college students, the healthier they were as older men. Pearson’s r was +.25.
This is an example of content analysis —a family of systematic approaches to measurement using complex archival data. Just as naturalistic observation requires specifying the behaviors of interest and then noting them as they occur, content analysis requires specifying keywords, phrases, or ideas and then finding all occurrences of them in the data. These occurrences can then be counted, timed (e.g., the amount of time devoted to entertainment topics on the nightly news show), or analyzed in a variety of other ways.
Key Takeaways
- Correlational research involves measuring two variables and assessing the relationship between them, with no manipulation of an independent variable.
- Correlational research is not defined by where or how the data are collected. However, some approaches to data collection are strongly associated with correlational research. These include naturalistic observation (in which researchers observe people’s behavior in the context in which it normally occurs) and the use of archival data that were already collected for some other purpose.
Discussion: For each of the following, decide whether it is most likely that the study described is experimental or correlational and explain why.
- An educational researcher compares the academic performance of students from the “rich” side of town with that of students from the “poor” side of town.
- A cognitive psychologist compares the ability of people to recall words that they were instructed to “read” with their ability to recall words that they were instructed to “imagine.”
- A manager studies the correlation between new employees’ college grade point averages and their first-year performance reports.
- An automotive engineer installs different stick shifts in a new car prototype, each time asking several people to rate how comfortable the stick shift feels.
- A food scientist studies the relationship between the temperature inside people’s refrigerators and the amount of bacteria on their food.
- A social psychologist tells some research participants that they need to hurry over to the next building to complete a study. She tells others that they can take their time. Then she observes whether they stop to help a research assistant who is pretending to be hurt.
Kanner, A. D., Coyne, J. C., Schaefer, C., & Lazarus, R. S. (1981). Comparison of two modes of stress measurement: Daily hassles and uplifts versus major life events. Journal of Behavioral Medicine, 4 , 1–39.
Kraut, R. E., & Johnston, R. E. (1979). Social and emotional messages of smiling: An ethological approach. Journal of Personality and Social Psychology, 37 , 1539–1553.
Levine, R. V., & Norenzayan, A. (1999). The pace of life in 31 countries. Journal of Cross-Cultural Psychology, 30 , 178–205.
Pelham, B. W., Carvallo, M., & Jones, J. T. (2005). Implicit egotism. Current Directions in Psychological Science, 14 , 106–110.
Peterson, C., Seligman, M. E. P., & Vaillant, G. E. (1988). Pessimistic explanatory style is a risk factor for physical illness: A thirty-five year longitudinal study. Journal of Personality and Social Psychology, 55 , 23–27.
Research Methods in Psychology Copyright © 2016 by University of Minnesota is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Methodology
- Correlational Research | Guide, Design & Examples
Correlational Research | Guide, Design & Examples
Published on 5 May 2022 by Pritha Bhandari . Revised on 5 December 2022.
A correlational research design investigates relationships between variables without the researcher controlling or manipulating any of them.
A correlation reflects the strength and/or direction of the relationship between two (or more) variables. The direction of a correlation can be either positive or negative.
Table of contents
Correlational vs experimental research, when to use correlational research, how to collect correlational data, how to analyse correlational data, correlation and causation, frequently asked questions about correlational research.
Correlational and experimental research both use quantitative methods to investigate relationships between variables. But there are important differences in how data is collected and the types of conclusions you can draw.
Prevent plagiarism, run a free check.
Correlational research is ideal for gathering data quickly from natural settings. That helps you generalise your findings to real-life situations in an externally valid way.
There are a few situations where correlational research is an appropriate choice.
To investigate non-causal relationships
You want to find out if there is an association between two variables, but you don’t expect to find a causal relationship between them.
Correlational research can provide insights into complex real-world relationships, helping researchers develop theories and make predictions.
To explore causal relationships between variables
You think there is a causal relationship between two variables, but it is impractical, unethical, or too costly to conduct experimental research that manipulates one of the variables.
Correlational research can provide initial indications or additional support for theories about causal relationships.
To test new measurement tools
You have developed a new instrument for measuring your variable, and you need to test its reliability or validity .
Correlational research can be used to assess whether a tool consistently or accurately captures the concept it aims to measure.
There are many different methods you can use in correlational research. In the social and behavioural sciences, the most common data collection methods for this type of research include surveys, observations, and secondary data.
It’s important to carefully choose and plan your methods to ensure the reliability and validity of your results. You should carefully select a representative sample so that your data reflects the population you’re interested in without bias .
In survey research , you can use questionnaires to measure your variables of interest. You can conduct surveys online, by post, by phone, or in person.
Surveys are a quick, flexible way to collect standardised data from many participants, but it’s important to ensure that your questions are worded in an unbiased way and capture relevant insights.
Naturalistic observation
Naturalistic observation is a type of field research where you gather data about a behaviour or phenomenon in its natural environment.
This method often involves recording, counting, describing, and categorising actions and events. Naturalistic observation can include both qualitative and quantitative elements, but to assess correlation, you collect data that can be analysed quantitatively (e.g., frequencies, durations, scales, and amounts).
Naturalistic observation lets you easily generalise your results to real-world contexts, and you can study experiences that aren’t replicable in lab settings. But data analysis can be time-consuming and unpredictable, and researcher bias may skew the interpretations.
Secondary data
Instead of collecting original data, you can also use data that has already been collected for a different purpose, such as official records, polls, or previous studies.
Using secondary data is inexpensive and fast, because data collection is complete. However, the data may be unreliable, incomplete, or not entirely relevant, and you have no control over the reliability or validity of the data collection procedures.
After collecting data, you can statistically analyse the relationship between variables using correlation or regression analyses, or both. You can also visualise the relationships between variables with a scatterplot.
Different types of correlation coefficients and regression analyses are appropriate for your data based on their levels of measurement and distributions .
Correlation analysis
Using a correlation analysis, you can summarise the relationship between variables into a correlation coefficient : a single number that describes the strength and direction of the relationship between variables. With this number, you’ll quantify the degree of the relationship between variables.
The Pearson product-moment correlation coefficient, also known as Pearson’s r , is commonly used for assessing a linear relationship between two quantitative variables.
Correlation coefficients are usually found for two variables at a time, but you can use a multiple correlation coefficient for three or more variables.
Regression analysis
With a regression analysis , you can predict how much a change in one variable will be associated with a change in the other variable. The result is a regression equation that describes the line on a graph of your variables.
You can use this equation to predict the value of one variable based on the given value(s) of the other variable(s). It’s best to perform a regression analysis after testing for a correlation between your variables.
It’s important to remember that correlation does not imply causation . Just because you find a correlation between two things doesn’t mean you can conclude one of them causes the other, for a few reasons.
Directionality problem
If two variables are correlated, it could be because one of them is a cause and the other is an effect. But the correlational research design doesn’t allow you to infer which is which. To err on the side of caution, researchers don’t conclude causality from correlational studies.
Third variable problem
A confounding variable is a third variable that influences other variables to make them seem causally related even though they are not. Instead, there are separate causal links between the confounder and each variable.
In correlational research, there’s limited or no researcher control over extraneous variables . Even if you statistically control for some potential confounders, there may still be other hidden variables that disguise the relationship between your study variables.
Although a correlational study can’t demonstrate causation on its own, it can help you develop a causal hypothesis that’s tested in controlled experiments.
A correlation reflects the strength and/or direction of the association between two or more variables.
- A positive correlation means that both variables change in the same direction.
- A negative correlation means that the variables change in opposite directions.
- A zero correlation means there’s no relationship between the variables.
A correlational research design investigates relationships between two variables (or more) without the researcher controlling or manipulating any of them. It’s a non-experimental type of quantitative research .
Controlled experiments establish causality, whereas correlational studies only show associations between variables.
- In an experimental design , you manipulate an independent variable and measure its effect on a dependent variable. Other variables are controlled so they can’t impact the results.
- In a correlational design , you measure variables without manipulating any of them. You can test whether your variables change together, but you can’t be sure that one variable caused a change in another.
In general, correlational research is high in external validity while experimental research is high in internal validity .
A correlation is usually tested for two variables at a time, but you can test correlations between three or more variables.
A correlation coefficient is a single number that describes the strength and direction of the relationship between your variables.
Different types of correlation coefficients might be appropriate for your data based on their levels of measurement and distributions . The Pearson product-moment correlation coefficient (Pearson’s r ) is commonly used to assess a linear relationship between two quantitative variables.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
Bhandari, P. (2022, December 05). Correlational Research | Guide, Design & Examples. Scribbr. Retrieved 3 June 2024, from https://www.scribbr.co.uk/research-methods/correlational-research-design/
Is this article helpful?

Pritha Bhandari
Other students also liked, a quick guide to experimental design | 5 steps & examples, quasi-experimental design | definition, types & examples, qualitative vs quantitative research | examples & methods.
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
Correlation Studies in Psychology Research
Determining the relationship between two or more variables.
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "a correlational research")
Emily is a board-certified science editor who has worked with top digital publishing brands like Voices for Biodiversity, Study.com, GoodTherapy, Vox, and Verywell.
:max_bytes(150000):strip_icc():format(webp)/Emily-Swaim-1000-0f3197de18f74329aeffb690a177160c.jpg "a correlational research")
Verywell / Brianna Gilmartin
- Characteristics
Potential Pitfalls
Frequently asked questions.
A correlational study is a type of research design that looks at the relationships between two or more variables. Correlational studies are non-experimental, which means that the experimenter does not manipulate or control any of the variables.
A correlation refers to a relationship between two variables. Correlations can be strong or weak and positive or negative. Sometimes, there is no correlation.
There are three possible outcomes of a correlation study: a positive correlation, a negative correlation, or no correlation. Researchers can present the results using a numerical value called the correlation coefficient, a measure of the correlation strength. It can range from –1.00 (negative) to +1.00 (positive). A correlation coefficient of 0 indicates no correlation.
- Positive correlations : Both variables increase or decrease at the same time. A correlation coefficient close to +1.00 indicates a strong positive correlation.
- Negative correlations : As the amount of one variable increases, the other decreases (and vice versa). A correlation coefficient close to -1.00 indicates a strong negative correlation.
- No correlation : There is no relationship between the two variables. A correlation coefficient of 0 indicates no correlation.
Characteristics of a Correlational Study
Correlational studies are often used in psychology, as well as other fields like medicine. Correlational research is a preliminary way to gather information about a topic. The method is also useful if researchers are unable to perform an experiment.
Researchers use correlations to see if a relationship between two or more variables exists, but the variables themselves are not under the control of the researchers.
While correlational research can demonstrate a relationship between variables, it cannot prove that changing one variable will change another. In other words, correlational studies cannot prove cause-and-effect relationships.
When you encounter research that refers to a "link" or an "association" between two things, they are most likely talking about a correlational study.
Types of Correlational Research
There are three types of correlational research: naturalistic observation, the survey method, and archival research. Each type has its own purpose, as well as its pros and cons.
Naturalistic Observation
The naturalistic observation method involves observing and recording variables of interest in a natural setting without interference or manipulation.
Can inspire ideas for further research
Option if lab experiment not available
Variables are viewed in natural setting
Can be time-consuming and expensive
Extraneous variables can't be controlled
No scientific control of variables
Subjects might behave differently if aware of being observed
This method is well-suited to studies where researchers want to see how variables behave in their natural setting or state. Inspiration can then be drawn from the observations to inform future avenues of research.
In some cases, it might be the only method available to researchers; for example, if lab experimentation would be precluded by access, resources, or ethics. It might be preferable to not being able to conduct research at all, but the method can be costly and usually takes a lot of time.
Naturalistic observation presents several challenges for researchers. For one, it does not allow them to control or influence the variables in any way nor can they change any possible external variables.
However, this does not mean that researchers will get reliable data from watching the variables, or that the information they gather will be free from bias.
For example, study subjects might act differently if they know that they are being watched. The researchers might not be aware that the behavior that they are observing is not necessarily the subject's natural state (i.e., how they would act if they did not know they were being watched).
Researchers also need to be aware of their biases, which can affect the observation and interpretation of a subject's behavior.
Surveys and questionnaires are some of the most common methods used for psychological research. The survey method involves having a random sample of participants complete a survey, test, or questionnaire related to the variables of interest. Random sampling is vital to the generalizability of a survey's results.
Cheap, easy, and fast
Can collect large amounts of data in a short amount of time
Results can be affected by poor survey questions
Results can be affected by unrepresentative sample
Outcomes can be affected by participants
If researchers need to gather a large amount of data in a short period of time, a survey is likely to be the fastest, easiest, and cheapest option.
It's also a flexible method because it lets researchers create data-gathering tools that will help ensure they get the information they need (survey responses) from all the sources they want to use (a random sample of participants taking the survey).
Survey data might be cost-efficient and easy to get, but it has its downsides. For one, the data is not always reliable—particularly if the survey questions are poorly written or the overall design or delivery is weak. Data is also affected by specific faults, such as unrepresented or underrepresented samples .
The use of surveys relies on participants to provide useful data. Researchers need to be aware of the specific factors related to the people taking the survey that will affect its outcome.
For example, some people might struggle to understand the questions. A person might answer a particular way to try to please the researchers or to try to control how the researchers perceive them (such as trying to make themselves "look better").
Sometimes, respondents might not even realize that their answers are incorrect or misleading because of mistaken memories .
Archival Research
Many areas of psychological research benefit from analyzing studies that were conducted long ago by other researchers, as well as reviewing historical records and case studies.
For example, in an experiment known as "The Irritable Heart ," researchers used digitalized records containing information on American Civil War veterans to learn more about post-traumatic stress disorder (PTSD).
Large amount of data
Can be less expensive
Researchers cannot change participant behavior
Can be unreliable
Information might be missing
No control over data collection methods
Using records, databases, and libraries that are publicly accessible or accessible through their institution can help researchers who might not have a lot of money to support their research efforts.
Free and low-cost resources are available to researchers at all levels through academic institutions, museums, and data repositories around the world.
Another potential benefit is that these sources often provide an enormous amount of data that was collected over a very long period of time, which can give researchers a way to view trends, relationships, and outcomes related to their research.
While the inability to change variables can be a disadvantage of some methods, it can be a benefit of archival research. That said, using historical records or information that was collected a long time ago also presents challenges. For one, important information might be missing or incomplete and some aspects of older studies might not be useful to researchers in a modern context.
A primary issue with archival research is reliability. When reviewing old research, little information might be available about who conducted the research, how a study was designed, who participated in the research, as well as how data was collected and interpreted.
Researchers can also be presented with ethical quandaries—for example, should modern researchers use data from studies that were conducted unethically or with questionable ethics?
You've probably heard the phrase, "correlation does not equal causation." This means that while correlational research can suggest that there is a relationship between two variables, it cannot prove that one variable will change another.
For example, researchers might perform a correlational study that suggests there is a relationship between academic success and a person's self-esteem. However, the study cannot show that academic success changes a person's self-esteem.
To determine why the relationship exists, researchers would need to consider and experiment with other variables, such as the subject's social relationships, cognitive abilities, personality, and socioeconomic status.
The difference between a correlational study and an experimental study involves the manipulation of variables. Researchers do not manipulate variables in a correlational study, but they do control and systematically vary the independent variables in an experimental study. Correlational studies allow researchers to detect the presence and strength of a relationship between variables, while experimental studies allow researchers to look for cause and effect relationships.
If the study involves the systematic manipulation of the levels of a variable, it is an experimental study. If researchers are measuring what is already present without actually changing the variables, then is a correlational study.
The variables in a correlational study are what the researcher measures. Once measured, researchers can then use statistical analysis to determine the existence, strength, and direction of the relationship. However, while correlational studies can say that variable X and variable Y have a relationship, it does not mean that X causes Y.
The goal of correlational research is often to look for relationships, describe these relationships, and then make predictions. Such research can also often serve as a jumping off point for future experimental research.
Heath W. Psychology Research Methods . Cambridge University Press; 2018:134-156.
Schneider FW. Applied Social Psychology . 2nd ed. SAGE; 2012:50-53.
Curtis EA, Comiskey C, Dempsey O. Importance and use of correlational research . Nurse Researcher . 2016;23(6):20-25. doi:10.7748/nr.2016.e1382
Carpenter S. Visualizing Psychology . 3rd ed. John Wiley & Sons; 2012:14-30.
Pizarro J, Silver RC, Prause J. Physical and mental health costs of traumatic war experiences among civil war veterans . Arch Gen Psychiatry . 2006;63(2):193. doi:10.1001/archpsyc.63.2.193
Post SG. The echo of Nuremberg: Nazi data and ethics . J Med Ethics . 1991;17(1):42-44. doi:10.1136/jme.17.1.42
Lau F. Chapter 12 Methods for Correlational Studies . In: Lau F, Kuziemsky C, eds. Handbook of eHealth Evaluation: An Evidence-based Approach . University of Victoria.
Akoglu H. User's guide to correlation coefficients . Turk J Emerg Med . 2018;18(3):91-93. doi:10.1016/j.tjem.2018.08.001
Price PC. Research Methods in Psychology . California State University.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Correlational Research: What it is with Examples

Our minds can do some brilliant things. For example, it can memorize the jingle of a pizza truck. The louder the jingle, the closer the pizza truck is to us. Who taught us that? Nobody! We relied on our understanding and came to a conclusion. We don’t stop there, do we? If there are multiple pizza trucks in the area and each one has a different jingle, we would memorize it all and relate the jingle to its pizza truck.
This is what correlational research precisely is, establishing a relationship between two variables, “jingle” and “distance of the truck” in this particular example. The correlational study looks for variables that seem to interact with each other. When you see one variable changing, you have a fair idea of how the other variable will change.
What is Correlational research?
Correlational research is a type of non-experimental research method in which a researcher measures two variables and understands and assesses the statistical relationship between them with no influence from any extraneous variable. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities.
Correlational Research Example
The correlation coefficient shows the correlation between two variables (A correlation coefficient is a statistical measure that calculates the strength of the relationship between two variables), a value measured between -1 and +1. When the correlation coefficient is close to +1, there is a positive correlation between the two variables. If the value is relative to -1, there is a negative correlation between the two variables. When the value is close to zero, then there is no relationship between the two variables.
Let us take an example to understand correlational research.
Consider hypothetically, a researcher is studying a correlation between cancer and marriage. In this study, there are two variables: disease and marriage. Let us say marriage has a negative association with cancer. This means that married people are less likely to develop cancer.
However, this doesn’t necessarily mean that marriage directly avoids cancer. In correlational research, it is not possible to establish the fact, what causes what. It is a misconception that a correlational study involves two quantitative variables. However, the reality is two variables are measured, but neither is changed. This is true independent of whether the variables are quantitative or categorical.
Types of correlational research
Mainly three types of correlational research have been identified:
1. Positive correlation: A positive relationship between two variables is when an increase in one variable leads to a rise in the other variable. A decrease in one variable will see a reduction in the other variable. For example, the amount of money a person has might positively correlate with the number of cars the person owns.
2. Negative correlation: A negative correlation is quite literally the opposite of a positive relationship. If there is an increase in one variable, the second variable will show a decrease, and vice versa.
For example, being educated might negatively correlate with the crime rate when an increase in one variable leads to a decrease in another and vice versa. If a country’s education level is improved, it can lower crime rates. Please note that this doesn’t mean that lack of education leads to crimes. It only means that a lack of education and crime is believed to have a common reason – poverty.
3. No correlation: There is no correlation between the two variables in this third type . A change in one variable may not necessarily see a difference in the other variable. For example, being a millionaire and happiness are not correlated. An increase in money doesn’t lead to happiness.
Characteristics of correlational research
Correlational research has three main characteristics. They are:
- Non-experimental : The correlational study is non-experimental. It means that researchers need not manipulate variables with a scientific methodology to either agree or disagree with a hypothesis. The researcher only measures and observes the relationship between the variables without altering them or subjecting them to external conditioning.
- Backward-looking : Correlational research only looks back at historical data and observes events in the past. Researchers use it to measure and spot historical patterns between two variables. A correlational study may show a positive relationship between two variables, but this can change in the future.
- Dynamic : The patterns between two variables from correlational research are never constant and are always changing. Two variables having negative correlation research in the past can have a positive correlation relationship in the future due to various factors.
Data collection
The distinctive feature of correlational research is that the researcher can’t manipulate either of the variables involved. It doesn’t matter how or where the variables are measured. A researcher could observe participants in a closed environment or a public setting.

Researchers use two data collection methods to collect information in correlational research.
01. Naturalistic observation
Naturalistic observation is a way of data collection in which people’s behavioral targeting is observed in their natural environment, in which they typically exist. This method is a type of field research. It could mean a researcher might be observing people in a grocery store, at the cinema, playground, or in similar places.
Researchers who are usually involved in this type of data collection make observations as unobtrusively as possible so that the participants involved in the study are not aware that they are being observed else they might deviate from being their natural self.
Ethically this method is acceptable if the participants remain anonymous, and if the study is conducted in a public setting, a place where people would not normally expect complete privacy. As mentioned previously, taking an example of the grocery store where people can be observed while collecting an item from the aisle and putting in the shopping bags. This is ethically acceptable, which is why most researchers choose public settings for recording their observations. This data collection method could be both qualitative and quantitative . If you need to know more about qualitative data, you can explore our newly published blog, “ Examples of Qualitative Data in Education .”
02. Archival data
Another approach to correlational data is the use of archival data. Archival information is the data that has been previously collected by doing similar kinds of research . Archival data is usually made available through primary research .
In contrast to naturalistic observation, the information collected through archived data can be pretty straightforward. For example, counting the number of people named Richard in the various states of America based on social security records is relatively short.
Use the correlational research method to conduct a correlational study and measure the statistical relationship between two variables. Uncover the insights that matter the most. Use QuestionPro’s research platform to uncover complex insights that can propel your business to the forefront of your industry.
Research to make better decisions. Start a free trial today. No credit card required.
LEARN MORE FREE TRIAL
MORE LIKE THIS

Why Multilingual 360 Feedback Surveys Provide Better Insights
Jun 3, 2024

Raked Weighting: A Key Tool for Accurate Survey Results
May 31, 2024

Top 8 Data Trends to Understand the Future of Data
May 30, 2024

Top 12 Interactive Presentation Software to Engage Your User
May 29, 2024
Other categories
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
- Privacy Policy
Home » Correlational Research – Methods, Types and Examples
Correlational Research – Methods, Types and Examples
Table of Contents

Correlational Research
Correlational Research is a type of research that examines the statistical relationship between two or more variables without manipulating them. It is a non-experimental research design that seeks to establish the degree of association or correlation between two or more variables.
Types of Correlational Research
There are three types of correlational research:
Positive Correlation
A positive correlation occurs when two variables increase or decrease together. This means that as one variable increases, the other variable also tends to increase. Similarly, as one variable decreases, the other variable also tends to decrease. For example, there is a positive correlation between the amount of time spent studying and academic performance. The more time a student spends studying, the higher their academic performance is likely to be. Similarly, there is a positive correlation between a person’s age and their income level. As a person gets older, they tend to earn more money.
Negative Correlation
A negative correlation occurs when one variable increases while the other decreases. This means that as one variable increases, the other variable tends to decrease. Similarly, as one variable decreases, the other variable tends to increase. For example, there is a negative correlation between the number of hours spent watching TV and physical activity level. The more time a person spends watching TV, the less physically active they are likely to be. Similarly, there is a negative correlation between the amount of stress a person experiences and their overall happiness. As stress levels increase, happiness levels tend to decrease.
Zero Correlation
A zero correlation occurs when there is no relationship between two variables. This means that the variables are unrelated and do not affect each other. For example, there is zero correlation between a person’s shoe size and their IQ score. The size of a person’s feet has no relationship to their level of intelligence. Similarly, there is zero correlation between a person’s height and their favorite color. The two variables are unrelated to each other.
Correlational Research Methods
Correlational research can be conducted using different methods, including:
Surveys are a common method used in correlational research. Researchers collect data by asking participants to complete questionnaires or surveys that measure different variables of interest. Surveys are useful for exploring the relationships between variables such as personality traits, attitudes, and behaviors.
Observational Studies
Observational studies involve observing and recording the behavior of participants in natural settings. Researchers can use observational studies to examine the relationships between variables such as social interactions, group dynamics, and communication patterns.
Archival Data
Archival data involves using existing data sources such as historical records, census data, or medical records to explore the relationships between variables. Archival data is useful for investigating the relationships between variables that cannot be manipulated or controlled.
Experimental Design
While correlational research does not involve manipulating variables, researchers can use experimental design to establish cause-and-effect relationships between variables. Experimental design involves manipulating one variable while holding other variables constant to determine the effect on the dependent variable.
Meta-Analysis
Meta-analysis involves combining and analyzing the results of multiple studies to explore the relationships between variables across different contexts and populations. Meta-analysis is useful for identifying patterns and inconsistencies in the literature and can provide insights into the strength and direction of relationships between variables.
Data Analysis Methods
Correlational research data analysis methods depend on the type of data collected and the research questions being investigated. Here are some common data analysis methods used in correlational research:
Correlation Coefficient
A correlation coefficient is a statistical measure that quantifies the strength and direction of the relationship between two variables. The correlation coefficient ranges from -1 to +1, with -1 indicating a perfect negative correlation, +1 indicating a perfect positive correlation, and 0 indicating no correlation. Researchers use correlation coefficients to determine the degree to which two variables are related.
Scatterplots
A scatterplot is a graphical representation of the relationship between two variables. Each data point on the plot represents a single observation. The x-axis represents one variable, and the y-axis represents the other variable. The pattern of data points on the plot can provide insights into the strength and direction of the relationship between the two variables.
Regression Analysis
Regression analysis is a statistical method used to model the relationship between two or more variables. Researchers use regression analysis to predict the value of one variable based on the value of another variable. Regression analysis can help identify the strength and direction of the relationship between variables, as well as the degree to which one variable can be used to predict the other.
Factor Analysis
Factor analysis is a statistical method used to identify patterns among variables. Researchers use factor analysis to group variables into factors that are related to each other. Factor analysis can help identify underlying factors that influence the relationship between two variables.
Path Analysis
Path analysis is a statistical method used to model the relationship between multiple variables. Researchers use path analysis to test causal models and identify direct and indirect effects between variables.
Applications of Correlational Research
Correlational research has many practical applications in various fields, including:
- Psychology : Correlational research is commonly used in psychology to explore the relationships between variables such as personality traits, behaviors, and mental health outcomes. For example, researchers may use correlational research to examine the relationship between anxiety and depression, or the relationship between self-esteem and academic achievement.
- Education : Correlational research is useful in educational research to explore the relationships between variables such as teaching methods, student motivation, and academic performance. For example, researchers may use correlational research to examine the relationship between student engagement and academic success, or the relationship between teacher feedback and student learning outcomes.
- Business : Correlational research can be used in business to explore the relationships between variables such as consumer behavior, marketing strategies, and sales outcomes. For example, marketers may use correlational research to examine the relationship between advertising spending and sales revenue, or the relationship between customer satisfaction and brand loyalty.
- Medicine : Correlational research is useful in medical research to explore the relationships between variables such as risk factors, disease outcomes, and treatment effectiveness. For example, researchers may use correlational research to examine the relationship between smoking and lung cancer, or the relationship between exercise and heart health.
- Social Science : Correlational research is commonly used in social science research to explore the relationships between variables such as socioeconomic status, cultural factors, and social behavior. For example, researchers may use correlational research to examine the relationship between income and voting behavior, or the relationship between cultural values and attitudes towards immigration.
Examples of Correlational Research
- Psychology : Researchers might be interested in exploring the relationship between two variables, such as parental attachment and anxiety levels in young adults. The study could involve measuring levels of attachment and anxiety using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying potential risk factors for anxiety in young adults, and in developing interventions that could help improve attachment and reduce anxiety.
- Education : In a correlational study in education, researchers might investigate the relationship between two variables, such as teacher engagement and student motivation in a classroom setting. The study could involve measuring levels of teacher engagement and student motivation using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying strategies that teachers could use to improve student motivation and engagement in the classroom.
- Business : Researchers might explore the relationship between two variables, such as employee satisfaction and productivity levels in a company. The study could involve measuring levels of employee satisfaction and productivity using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying factors that could help increase productivity and improve job satisfaction among employees.
- Medicine : Researchers might examine the relationship between two variables, such as smoking and the risk of developing lung cancer. The study could involve collecting data on smoking habits and lung cancer diagnoses, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in identifying risk factors for lung cancer and in developing interventions that could help reduce smoking rates.
- Sociology : Researchers might investigate the relationship between two variables, such as income levels and political attitudes. The study could involve measuring income levels and political attitudes using established scales or questionnaires, and then analyzing the data to determine if there is a correlation between the two variables. This information could be useful in understanding how socioeconomic factors can influence political beliefs and attitudes.
How to Conduct Correlational Research
Here are the general steps to conduct correlational research:
- Identify the Research Question : Start by identifying the research question that you want to explore. It should involve two or more variables that you want to investigate for a correlation.
- Choose the research method: Decide on the research method that will be most appropriate for your research question. The most common methods for correlational research are surveys, archival research, and naturalistic observation.
- Choose the Sample: Select the participants or data sources that you will use in your study. Your sample should be representative of the population you want to generalize the results to.
- Measure the variables: Choose the measures that will be used to assess the variables of interest. Ensure that the measures are reliable and valid.
- Collect the Data: Collect the data from your sample using the chosen research method. Be sure to maintain ethical standards and obtain informed consent from your participants.
- Analyze the data: Use statistical software to analyze the data and compute the correlation coefficient. This will help you determine the strength and direction of the correlation between the variables.
- Interpret the results: Interpret the results and draw conclusions based on the findings. Consider any limitations or alternative explanations for the results.
- Report the findings: Report the findings of your study in a research report or manuscript. Be sure to include the research question, methods, results, and conclusions.
Purpose of Correlational Research
The purpose of correlational research is to examine the relationship between two or more variables. Correlational research allows researchers to identify whether there is a relationship between variables, and if so, the strength and direction of that relationship. This information can be useful for predicting and explaining behavior, and for identifying potential risk factors or areas for intervention.
Correlational research can be used in a variety of fields, including psychology, education, medicine, business, and sociology. For example, in psychology, correlational research can be used to explore the relationship between personality traits and behavior, or between early life experiences and later mental health outcomes. In education, correlational research can be used to examine the relationship between teaching practices and student achievement. In medicine, correlational research can be used to investigate the relationship between lifestyle factors and disease outcomes.
Overall, the purpose of correlational research is to provide insight into the relationship between variables, which can be used to inform further research, interventions, or policy decisions.
When to use Correlational Research
Here are some situations when correlational research can be particularly useful:
- When experimental research is not possible or ethical: In some situations, it may not be possible or ethical to manipulate variables in an experimental design. In these cases, correlational research can be used to explore the relationship between variables without manipulating them.
- When exploring new areas of research: Correlational research can be useful when exploring new areas of research or when researchers are unsure of the direction of the relationship between variables. Correlational research can help identify potential areas for further investigation.
- When testing theories: Correlational research can be useful for testing theories about the relationship between variables. Researchers can use correlational research to examine the relationship between variables predicted by a theory, and to determine whether the theory is supported by the data.
- When making predictions: Correlational research can be used to make predictions about future behavior or outcomes. For example, if there is a strong positive correlation between education level and income, one could predict that individuals with higher levels of education will have higher incomes.
- When identifying risk factors: Correlational research can be useful for identifying potential risk factors for negative outcomes. For example, a study might find a positive correlation between drug use and depression, indicating that drug use could be a risk factor for depression.
Characteristics of Correlational Research
Here are some common characteristics of correlational research:
- Examines the relationship between two or more variables: Correlational research is designed to examine the relationship between two or more variables. It seeks to determine if there is a relationship between the variables, and if so, the strength and direction of that relationship.
- Non-experimental design: Correlational research is typically non-experimental in design, meaning that the researcher does not manipulate any variables. Instead, the researcher observes and measures the variables as they naturally occur.
- Cannot establish causation : Correlational research cannot establish causation, meaning that it cannot determine whether one variable causes changes in another variable. Instead, it only provides information about the relationship between the variables.
- Uses statistical analysis: Correlational research relies on statistical analysis to determine the strength and direction of the relationship between variables. This may include calculating correlation coefficients, regression analysis, or other statistical tests.
- Observes real-world phenomena : Correlational research is often used to observe real-world phenomena, such as the relationship between education and income or the relationship between stress and physical health.
- Can be conducted in a variety of fields : Correlational research can be conducted in a variety of fields, including psychology, sociology, education, and medicine.
- Can be conducted using different methods: Correlational research can be conducted using a variety of methods, including surveys, observational studies, and archival studies.
Advantages of Correlational Research
There are several advantages of using correlational research in a study:
- Allows for the exploration of relationships: Correlational research allows researchers to explore the relationships between variables in a natural setting without manipulating any variables. This can help identify possible relationships between variables that may not have been previously considered.
- Useful for predicting behavior: Correlational research can be useful for predicting future behavior. If a strong correlation is found between two variables, researchers can use this information to predict how changes in one variable may affect the other.
- Can be conducted in real-world settings: Correlational research can be conducted in real-world settings, which allows for the collection of data that is representative of real-world phenomena.
- Can be less expensive and time-consuming than experimental research: Correlational research is often less expensive and time-consuming than experimental research, as it does not involve manipulating variables or creating controlled conditions.
- Useful in identifying risk factors: Correlational research can be used to identify potential risk factors for negative outcomes. By identifying variables that are correlated with negative outcomes, researchers can develop interventions or policies to reduce the risk of negative outcomes.
- Useful in exploring new areas of research: Correlational research can be useful in exploring new areas of research, particularly when researchers are unsure of the direction of the relationship between variables. By conducting correlational research, researchers can identify potential areas for further investigation.
Limitation of Correlational Research
Correlational research also has several limitations that should be taken into account:
- Cannot establish causation: Correlational research cannot establish causation, meaning that it cannot determine whether one variable causes changes in another variable. This is because it is not possible to control all possible confounding variables that could affect the relationship between the variables being studied.
- Directionality problem: The directionality problem refers to the difficulty of determining which variable is influencing the other. For example, a correlation may exist between happiness and social support, but it is not clear whether social support causes happiness, or whether happy people are more likely to have social support.
- Third variable problem: The third variable problem refers to the possibility that a third variable, not included in the study, is responsible for the observed relationship between the two variables being studied.
- Limited generalizability: Correlational research is often limited in terms of its generalizability to other populations or settings. This is because the sample studied may not be representative of the larger population, or because the variables studied may behave differently in different contexts.
- Relies on self-reported data: Correlational research often relies on self-reported data, which can be subject to social desirability bias or other forms of response bias.
- Limited in explaining complex behaviors: Correlational research is limited in explaining complex behaviors that are influenced by multiple factors, such as personality traits, situational factors, and social context.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Mixed Methods Research – Types & Analysis

One-to-One Interview – Methods and Guide

Phenomenology – Methods, Examples and Guide

Applied Research – Types, Methods and Examples

Quasi-Experimental Research Design – Types...

Qualitative Research – Methods, Analysis Types...
6.2 Correlational Research
Learning objectives.
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of non-experimental research.
- Interpret the strength and direction of different correlation coefficients.
- Explain why correlation does not imply causation.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one or are not interested in causal relationships. Recall two goals of science are to describe and to predict and the correlational research strategy allows researchers to achieve both of these goals. Specifically, this strategy can be used to describe the strength and direction of the relationship between two variables and if there is a relationship between the variables then the researchers can use scores on one variable to predict scores on the other (using a statistical technique called regression).
Another reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, while I might be interested in the relationship between the frequency people use cannabis and their memory abilities I cannot ethically manipulate the frequency that people use cannabis. As such, I must rely on the correlational research strategy; I must simply measure the frequency that people use cannabis and measure their memory abilities using a standardized test of memory and then determine whether the frequency people use cannabis use is statistically related to memory test performance.
Correlation is also used to establish the reliability and validity of measurements. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
Another strength of correlational research is that it is often higher in external validity than experimental research. Recall there is typically a trade-off between internal validity and external validity. As greater controls are added to experiments, internal validity is increased but often at the expense of external validity. In contrast, correlational studies typically have low internal validity because nothing is manipulated or control but they often have high external validity. Since nothing is manipulated or controlled by the experimenter the results are more likely to reflect relationships that exist in the real world.
Finally, extending upon this trade-off between internal and external validity, correlational research can help to provide converging evidence for a theory. If a theory is supported by a true experiment that is high in internal validity as well as by a correlational study that is high in external validity then the researchers can have more confidence in the validity of their theory. As a concrete example, correlational studies establishing that there is a relationship between watching violent television and aggressive behavior have been complemented by experimental studies confirming that the relationship is a causal one (Bushman & Huesmann, 2001) [1] . These converging results provide strong evidence that there is a real relationship (indeed a causal relationship) between watching violent television and aggressive behavior.
Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated.
Correlations Between Quantitative Variables
Correlations between quantitative variables are often presented using scatterplots . Figure 6.3 shows some hypothetical data on the relationship between the amount of stress people are under and the number of physical symptoms they have. Each point in the scatterplot represents one person’s score on both variables. For example, the circled point in Figure 6.3 represents a person whose stress score was 10 and who had three physical symptoms. Taking all the points into account, one can see that people under more stress tend to have more physical symptoms. This is a good example of a positive relationship , in which higher scores on one variable tend to be associated with higher scores on the other. A negative relationship is one in which higher scores on one variable tend to be associated with lower scores on the other. There is a negative relationship between stress and immune system functioning, for example, because higher stress is associated with lower immune system functioning.

Figure 6.3 Scatterplot Showing a Hypothetical Positive Relationship Between Stress and Number of Physical Symptoms. The circled point represents a person whose stress score was 10 and who had three physical symptoms. Pearson’s r for these data is +.51.
The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson’s r ) . As Figure 6.4 shows, Pearson’s r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship). A value of 0 means there is no relationship between the two variables. When Pearson’s r is 0, the points on a scatterplot form a shapeless “cloud.” As its value moves toward −1.00 or +1.00, the points come closer and closer to falling on a single straight line. Correlation coefficients near ±.10 are considered small, values near ± .30 are considered medium, and values near ±.50 are considered large. Notice that the sign of Pearson’s r is unrelated to its strength. Pearson’s r values of +.30 and −.30, for example, are equally strong; it is just that one represents a moderate positive relationship and the other a moderate negative relationship. With the exception of reliability coefficients, most correlations that we find in Psychology are small or moderate in size. The website http://rpsychologist.com/d3/correlation/ , created by Kristoffer Magnusson, provides an excellent interactive visualization of correlations that permits you to adjust the strength and direction of a correlation while witnessing the corresponding changes to the scatterplot.

Figure 6.4 Range of Pearson’s r, From −1.00 (Strongest Possible Negative Relationship), Through 0 (No Relationship), to +1.00 (Strongest Possible Positive Relationship)
There are two common situations in which the value of Pearson’s r can be misleading. Pearson’s r is a good measure only for linear relationships, in which the points are best approximated by a straight line. It is not a good measure for nonlinear relationships, in which the points are better approximated by a curved line. Figure 6.5, for example, shows a hypothetical relationship between the amount of sleep people get per night and their level of depression. In this example, the line that best approximates the points is a curve—a kind of upside-down “U”—because people who get about eight hours of sleep tend to be the least depressed. Those who get too little sleep and those who get too much sleep tend to be more depressed. Even though Figure 6.5 shows a fairly strong relationship between depression and sleep, Pearson’s r would be close to zero because the points in the scatterplot are not well fit by a single straight line. This means that it is important to make a scatterplot and confirm that a relationship is approximately linear before using Pearson’s r . Nonlinear relationships are fairly common in psychology, but measuring their strength is beyond the scope of this book.

Figure 6.5 Hypothetical Nonlinear Relationship Between Sleep and Depression
The other common situations in which the value of Pearson’s r can be misleading is when one or both of the variables have a limited range in the sample relative to the population. This problem is referred to as restriction of range . Assume, for example, that there is a strong negative correlation between people’s age and their enjoyment of hip hop music as shown by the scatterplot in Figure 6.6. Pearson’s r here is −.77. However, if we were to collect data only from 18- to 24-year-olds—represented by the shaded area of Figure 6.6—then the relationship would seem to be quite weak. In fact, Pearson’s r for this restricted range of ages is 0. It is a good idea, therefore, to design studies to avoid restriction of range. For example, if age is one of your primary variables, then you can plan to collect data from people of a wide range of ages. Because restriction of range is not always anticipated or easily avoidable, however, it is good practice to examine your data for possible restriction of range and to interpret Pearson’s r in light of it. (There are also statistical methods to correct Pearson’s r for restriction of range, but they are beyond the scope of this book).

Figure 6.6 Hypothetical Data Showing How a Strong Overall Correlation Can Appear to Be Weak When One Variable Has a Restricted Range.The overall correlation here is −.77, but the correlation for the 18- to 24-year-olds (in the blue box) is 0.
Correlation Does Not Imply Causation
You have probably heard repeatedly that “Correlation does not imply causation.” An amusing example of this comes from a 2012 study that showed a positive correlation (Pearson’s r = 0.79) between the per capita chocolate consumption of a nation and the number of Nobel prizes awarded to citizens of that nation [2] . It seems clear, however, that this does not mean that eating chocolate causes people to win Nobel prizes, and it would not make sense to try to increase the number of Nobel prizes won by recommending that parents feed their children more chocolate.
There are two reasons that correlation does not imply causation. The first is called the directionality problem . Two variables, X and Y , can be statistically related because X causes Y or because Y causes X . Consider, for example, a study showing that whether or not people exercise is statistically related to how happy they are—such that people who exercise are happier on average than people who do not. This statistical relationship is consistent with the idea that exercising causes happiness, but it is also consistent with the idea that happiness causes exercise. Perhaps being happy gives people more energy or leads them to seek opportunities to socialize with others by going to the gym. The second reason that correlation does not imply causation is called the third-variable problem . Two variables, X and Y , can be statistically related not because X causes Y , or because Y causes X , but because some third variable, Z , causes both X and Y . For example, the fact that nations that have won more Nobel prizes tend to have higher chocolate consumption probably reflects geography in that European countries tend to have higher rates of per capita chocolate consumption and invest more in education and technology (once again, per capita) than many other countries in the world. Similarly, the statistical relationship between exercise and happiness could mean that some third variable, such as physical health, causes both of the others. Being physically healthy could cause people to exercise and cause them to be happier. Correlations that are a result of a third-variable are often referred to as spurious correlations.
Some excellent and funny examples of spurious correlations can be found at http://www.tylervigen.com (Figure 6.7 provides one such example).

“Lots of Candy Could Lead to Violence”
Although researchers in psychology know that correlation does not imply causation, many journalists do not. One website about correlation and causation, http://jonathan.mueller.faculty.noctrl.edu/100/correlation_or_causation.htm , links to dozens of media reports about real biomedical and psychological research. Many of the headlines suggest that a causal relationship has been demonstrated when a careful reading of the articles shows that it has not because of the directionality and third-variable problems.
One such article is about a study showing that children who ate candy every day were more likely than other children to be arrested for a violent offense later in life. But could candy really “lead to” violence, as the headline suggests? What alternative explanations can you think of for this statistical relationship? How could the headline be rewritten so that it is not misleading?
As you have learned by reading this book, there are various ways that researchers address the directionality and third-variable problems. The most effective is to conduct an experiment. For example, instead of simply measuring how much people exercise, a researcher could bring people into a laboratory and randomly assign half of them to run on a treadmill for 15 minutes and the rest to sit on a couch for 15 minutes. Although this seems like a minor change to the research design, it is extremely important. Now if the exercisers end up in more positive moods than those who did not exercise, it cannot be because their moods affected how much they exercised (because it was the researcher who determined how much they exercised). Likewise, it cannot be because some third variable (e.g., physical health) affected both how much they exercised and what mood they were in (because, again, it was the researcher who determined how much they exercised). Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships.
Key Takeaways
- Correlational research involves measuring two variables and assessing the relationship between them, with no manipulation of an independent variable.
- Correlation does not imply causation. A statistical relationship between two variables, X and Y , does not necessarily mean that X causes Y . It is also possible that Y causes X , or that a third variable, Z , causes both X and Y .
- While correlational research cannot be used to establish causal relationships between variables, correlational research does allow researchers to achieve many other important objectives (establishing reliability and validity, providing converging evidence, describing relationships and making predictions)
- Correlation coefficients can range from -1 to +1. The sign indicates the direction of the relationship between the variables and the numerical value indicates the strength of the relationship.
- A cognitive psychologist compares the ability of people to recall words that they were instructed to “read” with their ability to recall words that they were instructed to “imagine.”
- A manager studies the correlation between new employees’ college grade point averages and their first-year performance reports.
- An automotive engineer installs different stick shifts in a new car prototype, each time asking several people to rate how comfortable the stick shift feels.
- A food scientist studies the relationship between the temperature inside people’s refrigerators and the amount of bacteria on their food.
- A social psychologist tells some research participants that they need to hurry over to the next building to complete a study. She tells others that they can take their time. Then she observes whether they stop to help a research assistant who is pretending to be hurt.
2. Practice: For each of the following statistical relationships, decide whether the directionality problem is present and think of at least one plausible third variable.
- People who eat more lobster tend to live longer.
- People who exercise more tend to weigh less.
- College students who drink more alcohol tend to have poorer grades.
- Bushman, B. J., & Huesmann, L. R. (2001). Effects of televised violence on aggression. In D. Singer & J. Singer (Eds.), Handbook of children and the media (pp. 223–254). Thousand Oaks, CA: Sage. ↵
- Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367 , 1562-1564. ↵

Share This Book
- Increase Font Size

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Non-Experimental Research
29 Correlational Research
Learning objectives.
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of non-experimental research.
- Interpret the strength and direction of different correlation coefficients.
- Explain why correlation does not imply causation.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one or are not interested in causal relationships. Recall two goals of science are to describe and to predict and the correlational research strategy allows researchers to achieve both of these goals. Specifically, this strategy can be used to describe the strength and direction of the relationship between two variables and if there is a relationship between the variables then the researchers can use scores on one variable to predict scores on the other (using a statistical technique called regression, which is discussed further in the section on Complex Correlation in this chapter).
Another reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, while a researcher might be interested in the relationship between the frequency people use cannabis and their memory abilities they cannot ethically manipulate the frequency that people use cannabis. As such, they must rely on the correlational research strategy; they must simply measure the frequency that people use cannabis and measure their memory abilities using a standardized test of memory and then determine whether the frequency people use cannabis is statistically related to memory test performance.
Correlation is also used to establish the reliability and validity of measurements. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
Another strength of correlational research is that it is often higher in external validity than experimental research. Recall there is typically a trade-off between internal validity and external validity. As greater controls are added to experiments, internal validity is increased but often at the expense of external validity as artificial conditions are introduced that do not exist in reality. In contrast, correlational studies typically have low internal validity because nothing is manipulated or controlled but they often have high external validity. Since nothing is manipulated or controlled by the experimenter the results are more likely to reflect relationships that exist in the real world.
Finally, extending upon this trade-off between internal and external validity, correlational research can help to provide converging evidence for a theory. If a theory is supported by a true experiment that is high in internal validity as well as by a correlational study that is high in external validity then the researchers can have more confidence in the validity of their theory. As a concrete example, correlational studies establishing that there is a relationship between watching violent television and aggressive behavior have been complemented by experimental studies confirming that the relationship is a causal one (Bushman & Huesmann, 2001) [1] .
Does Correlational Research Always Involve Quantitative Variables?
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of daily hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure 6.2 shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. What defines a study is how the study is conducted.
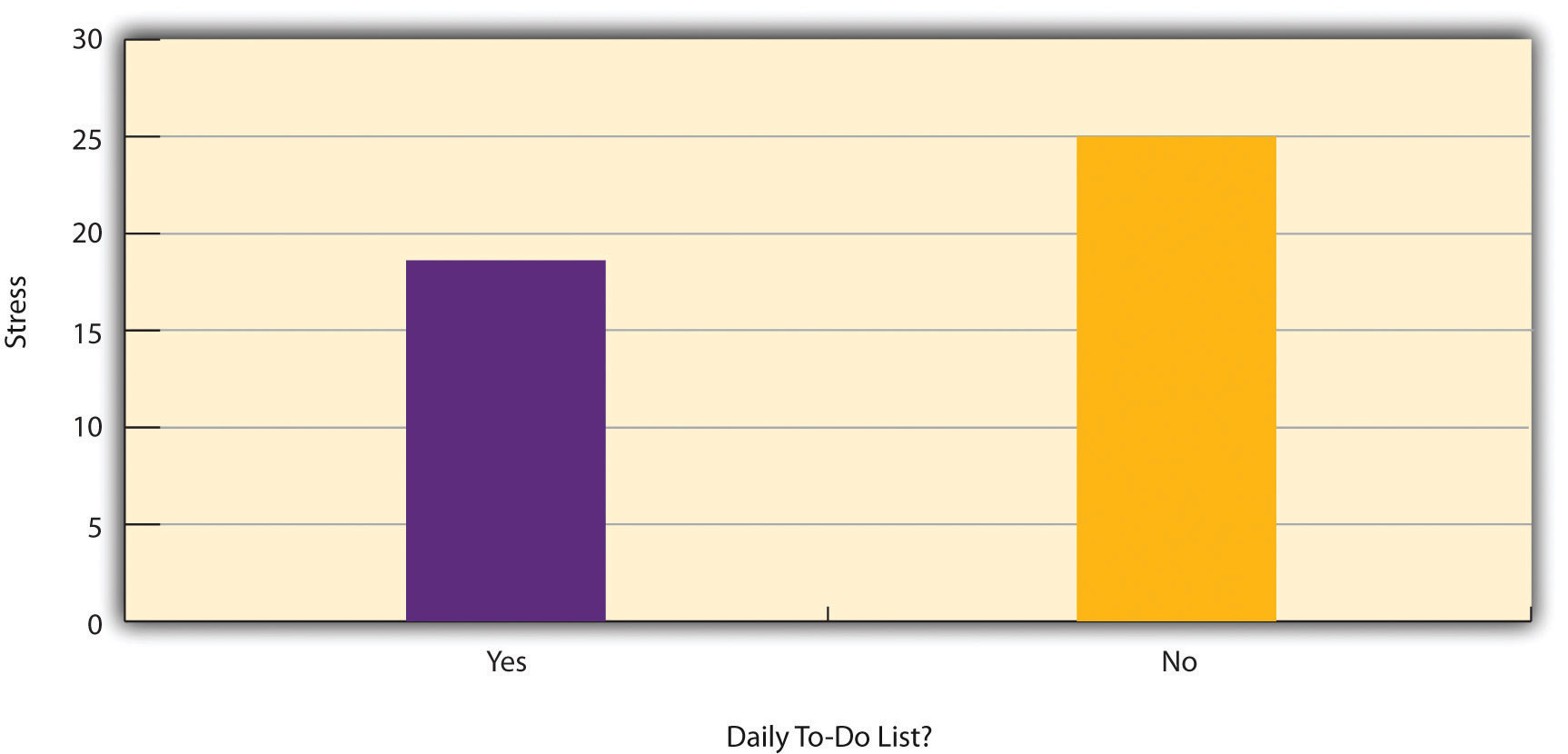
Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated.
Correlations Between Quantitative Variables
Correlations between quantitative variables are often presented using scatterplots . Figure 6.3 shows some hypothetical data on the relationship between the amount of stress people are under and the number of physical symptoms they have. Each point in the scatterplot represents one person’s score on both variables. For example, the circled point in Figure 6.3 represents a person whose stress score was 10 and who had three physical symptoms. Taking all the points into account, one can see that people under more stress tend to have more physical symptoms. This is a good example of a positive relationship , in which higher scores on one variable tend to be associated with higher scores on the other. In other words, they move in the same direction, either both up or both down. A negative relationship is one in which higher scores on one variable tend to be associated with lower scores on the other. In other words, they move in opposite directions. There is a negative relationship between stress and immune system functioning, for example, because higher stress is associated with lower immune system functioning.

The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson's r ) . As Figure 6.4 shows, Pearson’s r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship). A value of 0 means there is no relationship between the two variables. When Pearson’s r is 0, the points on a scatterplot form a shapeless “cloud.” As its value moves toward −1.00 or +1.00, the points come closer and closer to falling on a single straight line. Correlation coefficients near ±.10 are considered small, values near ± .30 are considered medium, and values near ±.50 are considered large. Notice that the sign of Pearson’s r is unrelated to its strength. Pearson’s r values of +.30 and −.30, for example, are equally strong; it is just that one represents a moderate positive relationship and the other a moderate negative relationship. With the exception of reliability coefficients, most correlations that we find in Psychology are small or moderate in size. The website http://rpsychologist.com/d3/correlation/ , created by Kristoffer Magnusson, provides an excellent interactive visualization of correlations that permits you to adjust the strength and direction of a correlation while witnessing the corresponding changes to the scatterplot.

There are two common situations in which the value of Pearson’s r can be misleading. Pearson’s r is a good measure only for linear relationships, in which the points are best approximated by a straight line. It is not a good measure for nonlinear relationships, in which the points are better approximated by a curved line. Figure 6.5, for example, shows a hypothetical relationship between the amount of sleep people get per night and their level of depression. In this example, the line that best approximates the points is a curve—a kind of upside-down “U”—because people who get about eight hours of sleep tend to be the least depressed. Those who get too little sleep and those who get too much sleep tend to be more depressed. Even though Figure 6.5 shows a fairly strong relationship between depression and sleep, Pearson’s r would be close to zero because the points in the scatterplot are not well fit by a single straight line. This means that it is important to make a scatterplot and confirm that a relationship is approximately linear before using Pearson’s r . Nonlinear relationships are fairly common in psychology, but measuring their strength is beyond the scope of this book.

The other common situations in which the value of Pearson’s r can be misleading is when one or both of the variables have a limited range in the sample relative to the population. This problem is referred to as restriction of range . Assume, for example, that there is a strong negative correlation between people’s age and their enjoyment of hip hop music as shown by the scatterplot in Figure 6.6. Pearson’s r here is −.77. However, if we were to collect data only from 18- to 24-year-olds—represented by the shaded area of Figure 6.6—then the relationship would seem to be quite weak. In fact, Pearson’s r for this restricted range of ages is 0. It is a good idea, therefore, to design studies to avoid restriction of range. For example, if age is one of your primary variables, then you can plan to collect data from people of a wide range of ages. Because restriction of range is not always anticipated or easily avoidable, however, it is good practice to examine your data for possible restriction of range and to interpret Pearson’s r in light of it. (There are also statistical methods to correct Pearson’s r for restriction of range, but they are beyond the scope of this book).

Correlation Does Not Imply Causation
You have probably heard repeatedly that “Correlation does not imply causation.” An amusing example of this comes from a 2012 study that showed a positive correlation (Pearson’s r = 0.79) between the per capita chocolate consumption of a nation and the number of Nobel prizes awarded to citizens of that nation [2] . It seems clear, however, that this does not mean that eating chocolate causes people to win Nobel prizes, and it would not make sense to try to increase the number of Nobel prizes won by recommending that parents feed their children more chocolate.
There are two reasons that correlation does not imply causation. The first is called the directionality problem . Two variables, X and Y , can be statistically related because X causes Y or because Y causes X . Consider, for example, a study showing that whether or not people exercise is statistically related to how happy they are—such that people who exercise are happier on average than people who do not. This statistical relationship is consistent with the idea that exercising causes happiness, but it is also consistent with the idea that happiness causes exercise. Perhaps being happy gives people more energy or leads them to seek opportunities to socialize with others by going to the gym. The second reason that correlation does not imply causation is called the third-variable problem . Two variables, X and Y , can be statistically related not because X causes Y , or because Y causes X , but because some third variable, Z , causes both X and Y . For example, the fact that nations that have won more Nobel prizes tend to have higher chocolate consumption probably reflects geography in that European countries tend to have higher rates of per capita chocolate consumption and invest more in education and technology (once again, per capita) than many other countries in the world. Similarly, the statistical relationship between exercise and happiness could mean that some third variable, such as physical health, causes both of the others. Being physically healthy could cause people to exercise and cause them to be happier. Correlations that are a result of a third-variable are often referred to as spurious correlations .
Some excellent and amusing examples of spurious correlations can be found at http://www.tylervigen.com (Figure 6.7 provides one such example).

“Lots of Candy Could Lead to Violence”
Although researchers in psychology know that correlation does not imply causation, many journalists do not. One website about correlation and causation, http://jonathan.mueller.faculty.noctrl.edu/100/correlation_or_causation.htm , links to dozens of media reports about real biomedical and psychological research. Many of the headlines suggest that a causal relationship has been demonstrated when a careful reading of the articles shows that it has not because of the directionality and third-variable problems.
One such article is about a study showing that children who ate candy every day were more likely than other children to be arrested for a violent offense later in life. But could candy really “lead to” violence, as the headline suggests? What alternative explanations can you think of for this statistical relationship? How could the headline be rewritten so that it is not misleading?
As you have learned by reading this book, there are various ways that researchers address the directionality and third-variable problems. The most effective is to conduct an experiment. For example, instead of simply measuring how much people exercise, a researcher could bring people into a laboratory and randomly assign half of them to run on a treadmill for 15 minutes and the rest to sit on a couch for 15 minutes. Although this seems like a minor change to the research design, it is extremely important. Now if the exercisers end up in more positive moods than those who did not exercise, it cannot be because their moods affected how much they exercised (because it was the researcher who used random assignment to determine how much they exercised). Likewise, it cannot be because some third variable (e.g., physical health) affected both how much they exercised and what mood they were in. Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships.
Media Attributions
- Nicholas Cage and Pool Drownings © Tyler Viegen is licensed under a CC BY (Attribution) license
- Bushman, B. J., & Huesmann, L. R. (2001). Effects of televised violence on aggression. In D. Singer & J. Singer (Eds.), Handbook of children and the media (pp. 223–254). Thousand Oaks, CA: Sage. ↵
- Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367 , 1562-1564. ↵
A graph that presents correlations between two quantitative variables, one on the x-axis and one on the y-axis. Scores are plotted at the intersection of the values on each axis.
A relationship in which higher scores on one variable tend to be associated with higher scores on the other.
A relationship in which higher scores on one variable tend to be associated with lower scores on the other.
A statistic that measures the strength of a correlation between quantitative variables.
When one or both variables have a limited range in the sample relative to the population, making the value of the correlation coefficient misleading.
The problem where two variables, X and Y , are statistically related either because X causes Y, or because Y causes X , and thus the causal direction of the effect cannot be known.
Two variables, X and Y, can be statistically related not because X causes Y, or because Y causes X, but because some third variable, Z, causes both X and Y.
Correlations that are a result not of the two variables being measured, but rather because of a third, unmeasured, variable that affects both of the measured variables.
Research Methods in Psychology Copyright © 2019 by Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Psychological Research
Correlational research, learning objectives.
- Explain what a correlation coefficient tells us about the relationship between variables
- Describe why correlation does not mean causation
Did you know that as sales in ice cream increase, so does the overall rate of crime? Is it possible that indulging in your favorite flavor of ice cream could send you on a crime spree? Or, after committing crime do you think you might decide to treat yourself to a cone? There is no question that a relationship exists between ice cream and crime (e.g., Harper, 2013), but it would be pretty foolish to decide that one thing actually caused the other to occur.
It is much more likely that both ice cream sales and crime rates are related to the temperature outside. When the temperature is warm, there are lots of people out of their houses, interacting with each other, getting annoyed with one another, and sometimes committing crimes. Also, when it is warm outside, we are more likely to seek a cool treat like ice cream. How do we determine if there is indeed a relationship between two things? And when there is a relationship, how can we discern whether it is attributable to coincidence or causation?
Correlation means that there is a relationship between two or more variables (such as ice cream consumption and crime), but this relationship does not necessarily imply cause and effect. When two variables are correlated, it simply means that as one variable changes, so does the other. We can measure correlation by calculating a statistic known as a correlation coefficient. A correlation coefficient is a number from -1 to +1 that indicates the strength and direction of the relationship between variables. The correlation coefficient is usually represented by the letter r .
The number portion of the correlation coefficient indicates the strength of the relationship. The closer the number is to 1 (be it negative or positive), the more strongly related the variables are, and the more predictable changes in one variable will be as the other variable changes. The closer the number is to zero, the weaker the relationship, and the less predictable the relationships between the variables becomes. For instance, a correlation coefficient of 0.9 indicates a far stronger relationship than a correlation coefficient of 0.3. If the variables are not related to one another at all, the correlation coefficient is 0. The example above about ice cream and crime is an example of two variables that we might expect to have no relationship to each other.
The sign—positive or negative—of the correlation coefficient indicates the direction of the relationship (Figure 1). A positive correlation means that the variables move in the same direction. Put another way, it means that as one variable increases so does the other, and conversely, when one variable decreases so does the other. A negative correlation means that the variables move in opposite directions. If two variables are negatively correlated, a decrease in one variable is associated with an increase in the other and vice versa.
The example of ice cream and crime rates is a positive correlation because both variables increase when temperatures are warmer. Other examples of positive correlations are the relationship between an individual’s height and weight or the relationship between a person’s age and number of wrinkles. One might expect a negative correlation to exist between someone’s tiredness during the day and the number of hours they slept the previous night: the amount of sleep decreases as the feelings of tiredness increase. In a real-world example of negative correlation, student researchers at the University of Minnesota found a weak negative correlation ( r = -0.29) between the average number of days per week that students got fewer than 5 hours of sleep and their GPA (Lowry, Dean, & Manders, 2010). Keep in mind that a negative correlation is not the same as no correlation. For example, we would probably find no correlation between hours of sleep and shoe size.
As mentioned earlier, correlations have predictive value. Imagine that you are on the admissions committee of a major university. You are faced with a huge number of applications, but you are able to accommodate only a small percentage of the applicant pool. How might you decide who should be admitted? You might try to correlate your current students’ college GPA with their scores on standardized tests like the SAT or ACT. By observing which correlations were strongest for your current students, you could use this information to predict relative success of those students who have applied for admission into the university.

Figure 1 . Scatterplots are a graphical view of the strength and direction of correlations. The stronger the correlation, the closer the data points are to a straight line. In these examples, we see that there is (a) a positive correlation between weight and height, (b) a negative correlation between tiredness and hours of sleep, and (c) no correlation between shoe size and hours of sleep.
Correlation Does Not Indicate Causation
Correlational research is useful because it allows us to discover the strength and direction of relationships that exist between two variables. However, correlation is limited because establishing the existence of a relationship tells us little about cause and effect . While variables are sometimes correlated because one does cause the other, it could also be that some other factor, a confounding variable , is actually causing the systematic movement in our variables of interest. In the ice cream/crime rate example mentioned earlier, temperature is a confounding variable that could account for the relationship between the two variables.
Even when we cannot point to clear confounding variables, we should not assume that a correlation between two variables implies that one variable causes changes in another. This can be frustrating when a cause-and-effect relationship seems clear and intuitive. Think back to our discussion of the research done by the American Cancer Society and how their research projects were some of the first demonstrations of the link between smoking and cancer. It seems reasonable to assume that smoking causes cancer, but if we were limited to correlational research , we would be overstepping our bounds by making this assumption.
Unfortunately, people mistakenly make claims of causation as a function of correlations all the time. Such claims are especially common in advertisements and news stories. For example, recent research found that people who eat cereal on a regular basis achieve healthier weights than those who rarely eat cereal (Frantzen, Treviño, Echon, Garcia-Dominic, & DiMarco, 2013; Barton et al., 2005). Guess how the cereal companies report this finding. Does eating cereal really cause an individual to maintain a healthy weight, or are there other possible explanations, such as, someone at a healthy weight is more likely to regularly eat a healthy breakfast than someone who is obese or someone who avoids meals in an attempt to diet (Figure 2)? While correlational research is invaluable in identifying relationships among variables, a major limitation is the inability to establish causality. Psychologists want to make statements about cause and effect, but the only way to do that is to conduct an experiment to answer a research question. The next section describes how scientific experiments incorporate methods that eliminate, or control for, alternative explanations, which allow researchers to explore how changes in one variable cause changes in another variable.
Watch this clip from Freakonomics for an example of how correlation does not indicate causation.
You can view the transcript for “Correlation vs. Causality: Freakonomics Movie” here (opens in new window) .

Figure 2 . Does eating cereal really cause someone to be a healthy weight? (credit: Tim Skillern)
Illusory Correlations
The temptation to make erroneous cause-and-effect statements based on correlational research is not the only way we tend to misinterpret data. We also tend to make the mistake of illusory correlations, especially with unsystematic observations. Illusory correlations , or false correlations, occur when people believe that relationships exist between two things when no such relationship exists. One well-known illusory correlation is the supposed effect that the moon’s phases have on human behavior. Many people passionately assert that human behavior is affected by the phase of the moon, and specifically, that people act strangely when the moon is full (Figure 3).

Figure 3 . Some people believe that a full moon makes people behave oddly. (credit: Cory Zanker)
There is no denying that the moon exerts a powerful influence on our planet. The ebb and flow of the ocean’s tides are tightly tied to the gravitational forces of the moon. Many people believe, therefore, that it is logical that we are affected by the moon as well. After all, our bodies are largely made up of water. A meta-analysis of nearly 40 studies consistently demonstrated, however, that the relationship between the moon and our behavior does not exist (Rotton & Kelly, 1985). While we may pay more attention to odd behavior during the full phase of the moon, the rates of odd behavior remain constant throughout the lunar cycle.
Why are we so apt to believe in illusory correlations like this? Often we read or hear about them and simply accept the information as valid. Or, we have a hunch about how something works and then look for evidence to support that hunch, ignoring evidence that would tell us our hunch is false; this is known as confirmation bias . Other times, we find illusory correlations based on the information that comes most easily to mind, even if that information is severely limited. And while we may feel confident that we can use these relationships to better understand and predict the world around us, illusory correlations can have significant drawbacks. For example, research suggests that illusory correlations—in which certain behaviors are inaccurately attributed to certain groups—are involved in the formation of prejudicial attitudes that can ultimately lead to discriminatory behavior (Fiedler, 2004).
Think It Over
- Analyzing Findings. Authored by : OpenStax College. Located at : https://openstax.org/books/psychology-2e/pages/2-3-analyzing-findings . License : CC BY: Attribution . License Terms : Download for free at https://openstax.org/books/psychology-2e/pages/1-introduction.
- Correlation vs. Causality: Freakonomics Movie. Located at : https://www.youtube.com/watch?v=lbODqslc4Tg . License : Other . License Terms : Standard YouTube License


An official website of the United States government
The .gov means it's official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you're on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- Browse Titles
NCBI Bookshelf. A service of the National Library of Medicine, National Institutes of Health.
Lau F, Kuziemsky C, editors. Handbook of eHealth Evaluation: An Evidence-based Approach [Internet]. Victoria (BC): University of Victoria; 2017 Feb 27.

Handbook of eHealth Evaluation: An Evidence-based Approach [Internet].
Chapter 12 methods for correlational studies.
Francis Lau .
12.1. Introduction
Correlational studies aim to find out if there are differences in the characteristics of a population depending on whether or not its subjects have been exposed to an event of interest in the naturalistic setting. In eHealth, correlational studies are often used to determine whether the use of an eHealth system is associated with a particular set of user characteristics and/or quality of care patterns ( Friedman & Wyatt, 2006 ). An example is a computerized provider order entry ( cpoe ) study to differentiate the background, usage and performance between clinical users and non-users of the cpoe system after its implementation in a hospital.
Correlational studies are different from comparative studies in that the evaluator does not control the allocation of subjects into comparison groups or assignment of the intervention to specific groups. Instead, the evaluator defines a set of variables including an outcome of interest then tests for hypothesized relations among these variables. The outcome is known as the dependent variable and the variables being tested for association are the independent variables. Correlational studies are similar to comparative studies in that they take on an objectivist view where the variables can be defined, measured and analyzed for the presence of hypothesized relations. As such, correlational studies face the same challenges as comparative studies in terms of their internal and external validity. Of particular importance are the issues of design choices, selection bias, confounders, and reporting consistency.
In this chapter we describe the basic types of correlational studies seen in the eHealth literature and their methodological considerations. Also included are three case examples to show how these studies are done.
12.2. Types of Correlational Studies
Correlational studies, better known as observational studies in epidemiology, are used to examine event exposure, disease prevalence and risk factors in a population ( Elwood, 2007 ). In eHealth, the exposure typically refers to the use of an eHealth system by a population of subjects in a given setting. These subjects may be patients, providers or organizations identified through a set of variables that are thought to differ in their measured values depending on whether or not the subjects were “exposed” to the eHealth system.
There are three basic types of correlational studies that are used in eHealth evaluation: cohort, cross-sectional, and case-control studies ( Vandenbroucke et al., 2014 ). These are described below.
- Cohort studies – A sample of subjects is observed over time where those exposed and not exposed to the eHealth system are compared for differences in one or more predefined outcomes, such as adverse event rates. Cohort studies may be prospective in nature where subjects are followed for a time period into the future or retrospective for a period into the past. The comparisons are typically made at the beginning of the study as baseline measures, then repeated over time at predefined intervals for differences and trends. Some cohort studies involve only a single group of subjects. Their focus is to describe the characteristics of subjects based on a set of variables, such as the pattern of ehr use by providers and their quality of care in an organization over a given time period.
- Cross-sectional studies – These are considered a type of cohort study where only one comparison is made between exposed and unexposed subjects. They provide a snapshot of the outcome and the associated characteristics of the cohort at a specific point in time.
- Case-control studies – Subjects in a sample that are exposed to the eHealth system are matched with those not exposed but otherwise similar in composition, then compared for differences in some predefined outcomes. Case-control studies are retrospective in nature where subjects already exposed to the event are selected then matched with unexposed subjects, using historical cases to ensure they have similar characteristics.
A cross-sectional survey is a type of cross-sectional study where the data source is drawn from postal questionnaires and interviews. This topic will be covered in the chapter on methods for survey studies.
12.3. Methodological Considerations
While correlational studies are considered less rigorous than rct s, they are the preferred designs when it is neither feasible nor ethical to conduct experimental trials. Key methodological issues arise in terms of: (a) design options, (b) biases and confounders, (c) controlling for confounding effects, (d) adherence to good practices, and (e) reporting consistency. These issues are discussed below.
12.3.1. Design Options
There are growing populations with multiple chronic conditions and healthcare interventions. They have made it difficult to design rct s with sufficient sample size and long-term follow-up to account for all the variability this phenomenon entails. Also rct s are intended to test the efficacy of an intervention in a restricted sample of subjects under ideal settings. They have limited generalizability to the population at large in routine settings ( Fleurence, Naci, & Jansen, 2010 ). As such, correlational studies, especially those involving the use of routinely collected ehr data from the general population, have become viable alternatives to rct s. There are advantages and disadvantages to each of the three design options presented above. They are listed below.
- Cohort studies – These studies typically follow the cohorts over time, which allow one to examine causal relationships between exposure and one or more outcomes. They also allow one to measure change in exposure and outcomes over time. However, these studies can be costly and time-consuming to conduct if the outcomes are rare or occur in the future. With prospective cohorts they can be prone to dropout. With retrospective cohorts accurate historical records are required which may not be available or complete ( Levin, 2003a ).
- Case-control studies – These studies are suited to examine infrequent or rare outcomes since they are selected at the outset to ensure sufficient cases. Yet the selection of exposed and matching cases can be problematic, as not all relevant characteristics are known. Moreover, the cases may not be representative of the population of interest. The focus on exposed cases that occur infrequently may overestimate their risks ( Levin, 2003b ).
- Cross-sectional studies – These studies are easier and quicker to conduct than others as they involve a one-time effort over a short period using a sample from the population of interest. They can be used to generate hypotheses and examine multiple outcomes and characteristics at the same time with no loss to follow-up. On the other hand, these studies only give a snapshot of the situation at one time point, making it difficult for causal inference of the exposure and outcomes. The results might be different had another time period been chosen ( Levin, 2006 ).
12.3.2. Biases and Confounders
Shamliyan, Kane, and Dickinson (2010) conducted a systematic review on tools used to assess the quality of observational studies. Despite the large number of quality scales and checklists found in the literature, they concluded that the universal concerns are in the areas of selection bias, confounding, and misclassification. These concerns, also mentioned by Vandenbroucke and colleagues (2014) in their reporting guidelines for observational studies, are summarized below.
- Selection bias – When subjects are selected through their exposure to the event rather than by random or concealed allocation, there is a risk that the subjects are not comparable due to the presence of systematic differences in their baseline characteristics. For example, a correlational study that examines the association between ehr use and quality of care may have younger providers with more computer savvy in the exposed group because they use ehr more and with more facility than those in the unexposed group. It is also possible to have sicker patients in the exposed group since they require more frequent ehr use than unexposed patients who may be healthier and have less need for the ehr . This is sometimes referred to as response bias, where the characteristics of subjects agreed to be in the study are different from those who declined to take part.
- Confounding – Extraneous factors that influence the outcome but are also associated with the exposure are said to have a confounding effect. One such type is confounding by indication where sicker patients are both more likely to receive treatments and also more likely to have adverse outcomes. For example, a study of cds alerts and adverse drug events may find a positive but spurious association due to the inclusion of sicker patients with multiple conditions and medications, which increases their chance of adverse events regardless of cds alerts.
- Misclassification – When there are systematic differences in the completeness or accuracy of the data recorded on the subjects, there is a risk of misclassification in their exposures or outcomes. This is also known as information or detection bias. An example is where sicker patients may have more complete ehr data because they received more tests, treatments and outcome tracking than those who are healthier and require less attention. As such, the exposure and outcomes of sicker patients may be overestimated.
It is important to note that bias and confounding are not synonymous. Bias is caused by finding the wrong association from flawed information or subject selection. Confounding is factually correct with respect to the relationship found, but is incorrect in its interpretation due to an extraneous factor that is associated with both the exposure and outcome.
12.3.3. Controlling for Confounding Effects
There are three common methods to control for confounding effects. These are by matching, stratification, and modelling. They are described below ( Higgins & Green, 2011 ).
- Matching – The selection of subjects with similar characteristics so that they are comparable; the matching can be done at the individual subject level where each exposed subject is matched with one or more unexposed subjects as controls. It can also be done at the group level with equal numbers of exposed and unexposed subjects. Another way to match subjects is by propensity score, that is, a measure derived from a set of characteristics in the subjects. An example is the retrospective cohort study by Zhou, Leith, Li, and Tom (2015) to examine the association between caregiver phr use and healthcare utilization by pediatric patients. In that study, a propensity score-matching algorithm was used to match phr -registered children to non-registered children. The matching model used registration as the outcome variable and all child and caregiver characteristics as the independent variables.
- Stratification – Subjects are categorized into subgroups based on a set of characteristics such as age and sex then analyzed for the effect within each subgroup. An example is the retrospective cohort study by Staes et al. (2008) , examining the impact of computerized alerts on the quality of outpatient lab monitoring for transplant patients. In that study, the before/after comparison of the timeliness of reporting and clinician responses was stratified by the type of test (creatinine, cyclosporine A, and tacrolimus) and report source (hospital laboratory or other labs).
- Modelling – The use of statistical models to compute adjusted effects while accounting for relevant characteristics such as age and sex differences among subjects. An example is the retrospective cohort study by Beck and colleagues (2012) to compare documentation consistency and care plan improvement before and after the implementation of an electronic asthma-specific history and physical template. In that study, before/after group characteristics were compared for differences using t -tests for continuous variables and χ 2 statistics for categorical variables. Logistic regression was used to adjust for group differences in age, gender, insurance, albuterol use at admission, and previous hospitalization.
12.3.4. Adherence to Good Practices in Prospective Observational Studies
The ispor Good Research Practices Task Force published a set of recommendations in designing, conducting and reporting prospective observational studies for comparative effectiveness research ( Berger et al., 2012 ) that are relevant to eHealth evaluation. Their key recommendations are listed below.
- Key policy questions should be defined to allow inferences to be drawn.
- Hypothesis testing protocol design to include the hypothesis/questions, treatment groups and outcomes, measured and unmeasured confounders, primary analyses, and required sample size.
- Rationale for prospective observational study design over others (e.g., rct ) is based on question, feasibility, intervention characteristics and ability to answer the question versus cost and timeliness.
- Study design choice is able to address potential biases and confounders through the use of inception cohorts, multiple comparator groups, matching designs and unaffected outcomes.
- Explanation of study design and analytic choices is transparent.
- Study execution is carried out in ways that ensure relevance and reasonable follow-up is not different from the usual practice.
- Study registration takes place on publicly available sites prior to its initiation.
12.3.5. The Need for Reporting Consistency
Vandenbroucke et al. (2014) published an expanded version of the Strengthening the Reporting of Observational Studies in Epidemiology ( strobe ) statement to improve the reporting of observational studies that can be applied in eHealth evaluation. It is made up of 22 items, of which 18 are common to cohort, case-control and cross-sectional studies, with four being specific to each of the three designs. The 22 reporting items are listed below (for details refer to the cited reference).
- Title and abstract – one item that covers the type of design used, and a summary of what was done and found.
- Introduction – two items on study background/rationale, objectives and/or hypotheses.
- Methods – nine items on design, setting, participants, variables, data sources/measurement, bias, study size, quantitative variables and statistical methods used.
- Results – five items on participants, descriptive, outcome data, main results and other analyses.
- Discussion – four items on key results, limitations, interpretation and generalizability.
- Other information – one item on funding source.
The four items specific to study design relate to the reporting of participants, statistical methods, descriptive results and outcome data. They are briefly described below for the three types of designs.
- Cohort studies – Participant eligibility criteria and sources, methods of selection, follow-up and handling dropouts, description of follow-up time and duration, and number of outcome events or summary measures over time. For matched studies include matching criteria and number of exposed and unexposed subjects.
- Cross-sectional studies – Participant eligibility criteria, sources and methods of selection, analytical methods accounting for sampling strategy as needed, and number of outcome events or summary measures.
- Case-control studies – Participant eligibility criteria, sources and methods of case/control selection with rationale for choices, methods of matching cases/controls, and number of exposures by category or summary measures of exposures. For matched studies include matching criteria and number of controls per case.
12.4. Case Examples
12.4.1. cohort study of automated immunosuppressive care.
Park and colleagues (2010) conducted a retrospective cohort study to examine the association between the use of a cds (clinical decision support) system in post-liver transplant immunosuppressive care and the rates of rejection episode and drug toxicity. The study is summarized below.
- Setting – A liver transplant program in the United States that had implemented an automated cds system to manage immunosuppressive therapy for its post-liver transplant recipients after discharge. The system consolidated all clinical information to expedite immunosuppressive review, ordering, and follow-up with recipients. Prior to automation, a paper charting system was used that involved manually tracking lab tests, transcribing results into a paper spreadsheet, finding physicians to review results and orders, and contacting recipients to notify them of changes.
- Subjects – The study population included recipients of liver transplants between 2004 and 2008 who received outpatient immunosuppressive therapy that included tacrolimus medications.
- Design – A retrospective cohort study with a before/after design to compare recipients managed by the paper charting system against those managed by the cds system for up to one year after discharge.
- Measures – The outcome variables were the percentages of recipients with at least one rejection and/or tacrolimus toxicity episode during the one-year follow-up period. The independent variables included recipient, intraoperative, donor and postoperative characteristics, and use of paper charting or cds . Examples of recipient variables were age, gender, body mass index, presence of diabetes and hypertension, and pre-transplant lab results. Examples of intraoperative data were blood type match, type of transplant and volume of blood transfused. Examples of donor data included percentage of fat in the liver. Examples of post-transplantation data included the type of immunosuppressive induction therapy and the management method.
- Analysis – Mean, standard deviation and t -tests were computed for continuous variables after checking for normal distribution. Percentages and Fisher’s exact test were computed for categorical variables. Autoregressive integrated moving average analysis was done to determine change in outcomes over time. Logistic regression with variables thought to be clinically relevant was used to identify significant univariable and multivariable factors associated with the outcomes. P values of less than 0.05 were considered significant.
- Findings – Overall, the cds system was associated with significantly fewer episodes of rejection and tacrolimus toxicity. The integrated moving average analysis showed a significant decrease in outcome rates after the cds system was implemented compared with paper charting. Multivariable analysis showed the cds system had lower odds of a rejection episode than paper charting ( or 0.20; p < 0.01) and lower odds of tacrolimus toxicity ( or 0.5; p < 0.01). Other significant non-system related factors included the use of specific drugs, the percentage of fat in the donor liver and the volume of packed red cells transfused.
12.4.2. Cross-sectional Analysis of EHR Documentation and Care Quality
Linder, Schnipper, and Middleton (2012) conducted a cross-sectional study to examine the association between the type of ehr documentation used by physicians and the quality of care provided. The study is summarized below.
- Setting – An integrated primary care practice-based research network affiliated with an academic centre in the United States. The network uses an in-house ehr system with decision support for preventive services, chronic care management, and medication monitoring and alerts. The ehr data include problem and medication lists, coded allergies and lab tests.
- Subjects – Physicians and patients from 10 primary care practices that were part of an rct to examine the use of a decision support tool to manage patients with coronary artery disease and diabetes ( cad/DM ). Eligible patients were those with cad/DM in their ehr problem list prior to the rct start date.
- Design – A nine-month retrospective cross-sectional analysis of ehr data collected from the rct . Three physician documentation styles were defined based on 188,554 visit notes in the ehr : (a) dictation, (b) structured documentation, and (c) free text note. Physicians were divided into three groups based on their predominant style defined as more than 25% of their notes composed by a given method.
- Measures – The outcome variables were 15 ehr -based cad/DM quality measures assessed 30 days after primary care visits. They covered quality of documentation, medication use, lab testing, physiologic measures, and vaccinations. Measures collected prior to the day of visit were eligible and considered fulfilled with the presence of coded ehr data on vital signs, medications, allergies, problem lists, lab tests, and vaccinations. Independent variables on physicians and patients were included as covariates. For physicians, they included age, gender, training level, proportion of cad/DM patients in their panel, total patient visits, and self-reported experience with the ehr . For patients, they included socio-demographic factors, the number of clinic visits and hospitalizations, the number of problems and medications in the ehr , and whether their physician was in the intervention group.
- Analysis – Baseline characteristics of physicians and patients were compared using descriptive statistics. Continuous variables were compared using anova . For categorical variables, Fisher’s exact test was used for physician variables and χ 2 test for patient variables. Multivariate logistic regression models were used for each quality measure to adjust for patient and physician clustering and potential confounders. Bonferroni procedure was used to account for multiple comparisons for the 15 quality measures.
- Findings – During the study period, 234 physicians documented 18,569 visits from 7,000 cad/DM patients. Of these physicians, 146 (62%) typed free-text notes, 68 (25%) used structured documentation, and 20 (9%) dictated notes. After adjusting for cluster effect, physicians who dictated their notes had the worst quality of care in all 15 measures. In particular, physicians who dictated notes were significantly worse in three of 15 measures (antiplatelet medication, tobacco use, diabetic eye exam); physicians who used structured documentation were better in three measures (blood pressure, body mass, diabetic foot exam); and those who used free-text were better in one measure (influenza vaccination). In summary, physicians who dictated notes had worse quality of care than those with structured documentation.
12.4.3. Case-control Comparison of Internet Portal Use
Nielsen, Halamka, and Kinkel (2012) conducted a case-control study to evaluate whether there was an association between active Internet patient portal use by Multiple Sclerosis ( ms ) patients and medical resource utilization. Patient predictors and barriers to portal use were also identified. The study is summarized below.
- Setting – An academic ms centre in the United States with an in-house Internet patient portal site that was accessed by ms patients to schedule clinic appointments, request prescription refills and referrals, view test results, upload personal health information, and communicate with providers via secure e-mails.
- Subjects – 240 adult ms patients actively followed during 2008 and 2009 were randomly selected from the ehr ; 120 of these patients had submitted at least one message during that period and were defined as portal users. Another 120 patients who did not enrol in the portal or send any message were selected as non-users for comparison.
- Design – A retrospective case-control study facilitated through a chart review comparing portal users against non-users from the same period. Patient demographic and clinical information was extracted from the ehr , while portal usage, including feature access type and frequency and e-mail message content, were provided by it staff.
- Measures – Patient variables included age, gender, race, insurance type, employment status, number of medical problems, disease duration, psychiatric history, number of medications, and physical disability scores. Provider variables included prescription type and frequency. Portal usage variables included feature access type and frequency for test results, appointments, prescription requests and logins, and categorized messaging contents.
- Analysis – Comparison of patient demographic, clinical and medical resource utilization data from users and non-users were made using descriptive statistics, Wilcoxon rank sum test, Fisher’s exact test and χ 2 test. Multivariate logistic regression was used to identify patient predictors and barriers to portal use. Provider prescribing habits against patient’s psychiatric history and portal use were examined by two-way analysis of variance. All statistical tests used p value of 0.05 with no adjustment made for multiple comparisons. A logistic multivariate regression model was created to predict portal use based on patient demographics, clinical condition, socio-economic status, and physical disability metrics.
- Findings – Portal users were mostly young professionals with little physical disability. The most frequently used feature was secure patient-provider messaging, often for medication requests or refills, and self-reported side effects. Predictors and barriers of portal use were the number of medications prescribed ( or 1.69, p < 0.0001), Caucasian ethnicity ( or 5.04, p = 0.007), arm and hand disability ( or 0.23, p = 0.01), and impaired vision ( or 0.31, p = 0.01). For medical resource utilization, portal users had more frequent clinic visits, medication use and prescriptions from centre staff providers. Patients with a history of psychiatric disease were prescribed more ms medications than those without any history ( p < 0.0001). In summary, ms patients used the Internet more than the general population, but physical disability limited their access and need to be addressed.
12.4.4. Limitations
A general limitation of a correlational study is that it can determine association between exposure and outcomes but cannot predict causation. The more specific limitations of the three case examples cited by the authors are listed below.
- Automated immunosuppressive care – Baseline differences existed between groups with unknown effects; possible other unmeasured confounders; possible Hawthorne effects from focus on immunosuppressive care.
- ehr documentation and care quality – Small sample size; only three documentation styles were considered (e.g., scribe and voice recognition software were excluded) and unsure if they were stable during study period; quality measures specific to cad/DM conditions only; complex methods of adjusting for clustering and confounding that did not account for unmeasured confounders; the level of physician training (e.g., attending versus residents) not adjusted.
- Internet portal use – Small sample size not representative of the study population; referral centre site could over-represent complex patients requiring advanced care; all patients had health insurance.
12.5. Summary
In this chapter we described cohort, case-control and cross-sectional studies as three types of correlational studies used in eHealth evaluation. The methodological issues addressed include bias and confounding, controlling for confounders, adherence to good practices and consistency in reporting. Three case examples were included to show how eHealth correlational studies are done.
1 ISPOR – International Society for Pharmacoeconomics and Outcomes Research
- Beck A. F., Sauers H. S., Kahn R. S., Yau C., Weiser J., Simmons J.M. Improved documentation and care planning with an asthma-specific history and physical. Hospital Pediatrics. 2012; 2 (4):194–201. [ PubMed : 24313025 ]
- Berger M. L., Dreyer N., Anderson F., Towse A., Sedrakyan A., Normand S.L. Prospective observational studies to address comparative effectiveness: The ispor good research practices task force report. Value in Health. 2012; 15 (2):217–230. Retrieved from http://www .sciencedirect .com/science/article /pii/S1098301512000071 . [ PubMed : 22433752 ]
- Elwood M. Critical appraisal of epidemiological studies and clinical studies. 3rd ed. Oxford: Oxford University Press; 2007.
- Fleurence R. L., Naci H., Jansen J.P. The critical role of observational evidence in comparative effectiveness research. Health Affairs. 2010; 29 (10):1826–1833. [ PubMed : 20921482 ]
- Friedman C. P., Wyatt J.C. Evaluation methods in biomedical informatics. 2nd ed. New York: Springer Science + Business Media, Inc; 2006.
- Higgins J. P. T., Green S., editors. Cochrane handbook for systematic reviews of interventions. London: The Cochrane Collaboration; 2011. (Version 5.1.0, updated March 2011) Retrieved from http://handbook .cochrane.org/
- Levin K. A. Study design iv : Cohort studies. Evidence-based Dentistry. 2003a; 7 :51–52. [ PubMed : 16858385 ]
- Levin K. A. Study design v : Case-control studies. Evidence-based Dentistry. 2003b; 7 :83–84. [ PubMed : 17003803 ]
- Levin K. A. Study design iii : Cross-sectional studies. Evidence-based Dentistry. 2006; 7 :24–25. [ PubMed : 16557257 ]
- Linder J. A., Schnipper J. L., Middleton B. Method of electronic health record documentation and quality of primary care. Journal of the American Medical Informatics Association. 2012; 19 (6):1019–1024. [ PMC free article : PMC3534457 ] [ PubMed : 22610494 ]
- Nielsen A. S., Halamka J. D., Kinkel R.P. Internet portal use in an academic multiple sclerosis center. Journal of the American Medical Informatics Association. 2012; 19 (1):128–133. [ PMC free article : PMC3240754 ] [ PubMed : 21571744 ]
- Park E. S., Peccoud M. R., Wicks K. A., Halldorson J. B., Carithers R. L. Jr., Reyes J. D., Perkins J.D. Use of an automated clinical management system improves outpatient immunosuppressive care following liver transplantation. Journal of the American Medical Informatics Association. 2010; 17 (4):396–402. [ PMC free article : PMC2995663 ] [ PubMed : 20595306 ]
- Shamliyan T., Kane R. L., Dickinson S. A systematic review of tools used to assess the quality of observational studies that examine incidence or prevalence and risk factors for diseases. Journal of Clinical Epidemiology. 2010; 63 (10):1061–1070. [ PubMed : 20728045 ]
- Staes C. J., Evans R. S., Rocha B. H. S. C., Sorensen J. B., Huff S. M., Arata J., Narus S.P. Computerized alerts improve outpatient laboratory monitoring of transplant patients. Journal of the American Medical Informatics Association. 2008; 15 (3):324–332. [ PMC free article : PMC2410008 ] [ PubMed : 18308982 ]
- Vandenbroucke J. P., von Elm E., Altman D. G., Gotzsche P. C., Mulrow C. D., Pocock S. J., Egger M. for the strobe Initiative. Strengthening the reporting of observational studies in epidemiology ( strobe ): explanation and elaboration. International Journal of Surgery. 2014; 12 (12):1500–1524. Retrieved from http://www.sciencedirect.com/science/article/pii/ s174391911400212x . [ PubMed : 25046751 ]
- Zhou Y. Y., Leith W. M., Li H., Tom J.O. Personal health record use for children and health care utilization: propensity score-matched cohort analysis. Journal of the American Medical Informatics Association. 2015; 22 (4):748–754. [ PubMed : 25656517 ]
This publication is licensed under a Creative Commons License, Attribution-Noncommercial 4.0 International License (CC BY-NC 4.0): see https://creativecommons.org/licenses/by-nc/4.0/
- Cite this Page Lau F. Chapter 12 Methods for Correlational Studies. In: Lau F, Kuziemsky C, editors. Handbook of eHealth Evaluation: An Evidence-based Approach [Internet]. Victoria (BC): University of Victoria; 2017 Feb 27.
- PDF version of this title (4.5M)
- Disable Glossary Links
In this Page
- Introduction
- Types of Correlational Studies
- Methodological Considerations
- Case Examples
Related information
- PMC PubMed Central citations
- PubMed Links to PubMed
Recent Activity
- Chapter 12 Methods for Correlational Studies - Handbook of eHealth Evaluation: A... Chapter 12 Methods for Correlational Studies - Handbook of eHealth Evaluation: An Evidence-based Approach
Your browsing activity is empty.
Activity recording is turned off.
Turn recording back on
Connect with NLM
National Library of Medicine 8600 Rockville Pike Bethesda, MD 20894
Web Policies FOIA HHS Vulnerability Disclosure
Help Accessibility Careers
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 7: Nonexperimental Research
Correlational Research
Learning Objectives
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of nonexperimental research.
What Is Correlational Research?
Correlational research is a type of nonexperimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
The other reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, Allen Kanner and his colleagues thought that the number of “daily hassles” (e.g., rude salespeople, heavy traffic) that people experience affects the number of physical and psychological symptoms they have (Kanner, Coyne, Schaefer, & Lazarus, 1981). [1] But because they could not manipulate the number of daily hassles their participants experienced, they had to settle for measuring the number of daily hassles—along with the number of symptoms—using self-report questionnaires. Although the strong positive relationship they found between these two variables is consistent with their idea that hassles cause symptoms, it is also consistent with the idea that symptoms cause hassles or that some third variable (e.g., neuroticism) causes both.
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extroversion tests or the number of hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American university students and 50 Japanese university students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing professors and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure 7.2 shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this design is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. It is how the study is conducted.

Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated. However, because some approaches to data collection are strongly associated with correlational research, it makes sense to discuss them here. The two we will focus on are naturalistic observation and archival data. A third, survey research, is discussed in its own chapter, Chapter 9.
Naturalistic Observation
Naturalistic observation is an approach to data collection that involves observing people’s behaviour in the environment in which it typically occurs. Thus naturalistic observation is a type of field research (as opposed to a type of laboratory research). It could involve observing shoppers in a grocery store, children on a school playground, or psychiatric inpatients in their wards. Researchers engaged in naturalistic observation usually make their observations as unobtrusively as possible so that participants are often not aware that they are being studied. Ethically, this method is considered to be acceptable if the participants remain anonymous and the behaviour occurs in a public setting where people would not normally have an expectation of privacy. Grocery shoppers putting items into their shopping carts, for example, are engaged in public behaviour that is easily observable by store employees and other shoppers. For this reason, most researchers would consider it ethically acceptable to observe them for a study. On the other hand, one of the arguments against the ethicality of the naturalistic observation of “bathroom behaviour” discussed earlier in the book is that people have a reasonable expectation of privacy even in a public restroom and that this expectation was violated.
Researchers Robert Levine and Ara Norenzayan used naturalistic observation to study differences in the “pace of life” across countries (Levine & Norenzayan, 1999). [2] One of their measures involved observing pedestrians in a large city to see how long it took them to walk 60 feet. They found that people in some countries walked reliably faster than people in other countries. For example, people in Canada and Sweden covered 60 feet in just under 13 seconds on average, while people in Brazil and Romania took close to 17 seconds.
Because naturalistic observation takes place in the complex and even chaotic “real world,” there are two closely related issues that researchers must deal with before collecting data. The first is sampling. When, where, and under what conditions will the observations be made, and who exactly will be observed? Levine and Norenzayan described their sampling process as follows:
“Male and female walking speed over a distance of 60 feet was measured in at least two locations in main downtown areas in each city. Measurements were taken during main business hours on clear summer days. All locations were flat, unobstructed, had broad sidewalks, and were sufficiently uncrowded to allow pedestrians to move at potentially maximum speeds. To control for the effects of socializing, only pedestrians walking alone were used. Children, individuals with obvious physical handicaps, and window-shoppers were not timed. Thirty-five men and 35 women were timed in most cities.” (p. 186)
Precise specification of the sampling process in this way makes data collection manageable for the observers, and it also provides some control over important extraneous variables. For example, by making their observations on clear summer days in all countries, Levine and Norenzayan controlled for effects of the weather on people’s walking speeds.
The second issue is measurement. What specific behaviours will be observed? In Levine and Norenzayan’s study, measurement was relatively straightforward. They simply measured out a 60-foot distance along a city sidewalk and then used a stopwatch to time participants as they walked over that distance. Often, however, the behaviours of interest are not so obvious or objective. For example, researchers Robert Kraut and Robert Johnston wanted to study bowlers’ reactions to their shots, both when they were facing the pins and then when they turned toward their companions (Kraut & Johnston, 1979). [3] But what “reactions” should they observe? Based on previous research and their own pilot testing, Kraut and Johnston created a list of reactions that included “closed smile,” “open smile,” “laugh,” “neutral face,” “look down,” “look away,” and “face cover” (covering one’s face with one’s hands). The observers committed this list to memory and then practised by coding the reactions of bowlers who had been videotaped. During the actual study, the observers spoke into an audio recorder, describing the reactions they observed. Among the most interesting results of this study was that bowlers rarely smiled while they still faced the pins. They were much more likely to smile after they turned toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.
When the observations require a judgment on the part of the observers—as in Kraut and Johnston’s study—this process is often described as coding . Coding generally requires clearly defining a set of target behaviours. The observers then categorize participants individually in terms of which behaviour they have engaged in and the number of times they engaged in each behaviour. The observers might even record the duration of each behaviour. The target behaviours must be defined in such a way that different observers code them in the same way. This difficulty with coding is the issue of interrater reliability, as mentioned in Chapter 5. Researchers are expected to demonstrate the interrater reliability of their coding procedure by having multiple raters code the same behaviours independently and then showing that the different observers are in close agreement. Kraut and Johnston, for example, video recorded a subset of their participants’ reactions and had two observers independently code them. The two observers showed that they agreed on the reactions that were exhibited 97% of the time, indicating good interrater reliability.
Archival Data
Another approach to correlational research is the use of archival data , which are data that have already been collected for some other purpose. An example is a study by Brett Pelham and his colleagues on “implicit egotism”—the tendency for people to prefer people, places, and things that are similar to themselves (Pelham, Carvallo, & Jones, 2005). [4] In one study, they examined Social Security records to show that women with the names Virginia, Georgia, Louise, and Florence were especially likely to have moved to the states of Virginia, Georgia, Louisiana, and Florida, respectively.
As with naturalistic observation, measurement can be more or less straightforward when working with archival data. For example, counting the number of people named Virginia who live in various states based on Social Security records is relatively straightforward. But consider a study by Christopher Peterson and his colleagues on the relationship between optimism and health using data that had been collected many years before for a study on adult development (Peterson, Seligman, & Vaillant, 1988). [5] In the 1940s, healthy male college students had completed an open-ended questionnaire about difficult wartime experiences. In the late 1980s, Peterson and his colleagues reviewed the men’s questionnaire responses to obtain a measure of explanatory style—their habitual ways of explaining bad events that happen to them. More pessimistic people tend to blame themselves and expect long-term negative consequences that affect many aspects of their lives, while more optimistic people tend to blame outside forces and expect limited negative consequences. To obtain a measure of explanatory style for each participant, the researchers used a procedure in which all negative events mentioned in the questionnaire responses, and any causal explanations for them, were identified and written on index cards. These were given to a separate group of raters who rated each explanation in terms of three separate dimensions of optimism-pessimism. These ratings were then averaged to produce an explanatory style score for each participant. The researchers then assessed the statistical relationship between the men’s explanatory style as undergraduate students and archival measures of their health at approximately 60 years of age. The primary result was that the more optimistic the men were as undergraduate students, the healthier they were as older men. Pearson’s r was +.25.
This method is an example of content analysis —a family of systematic approaches to measurement using complex archival data. Just as naturalistic observation requires specifying the behaviours of interest and then noting them as they occur, content analysis requires specifying keywords, phrases, or ideas and then finding all occurrences of them in the data. These occurrences can then be counted, timed (e.g., the amount of time devoted to entertainment topics on the nightly news show), or analyzed in a variety of other ways.
Key Takeaways
- Correlational research involves measuring two variables and assessing the relationship between them, with no manipulation of an independent variable.
- Correlational research is not defined by where or how the data are collected. However, some approaches to data collection are strongly associated with correlational research. These include naturalistic observation (in which researchers observe people’s behaviour in the context in which it normally occurs) and the use of archival data that were already collected for some other purpose.
Discussion: For each of the following, decide whether it is most likely that the study described is experimental or correlational and explain why.
- An educational researcher compares the academic performance of students from the “rich” side of town with that of students from the “poor” side of town.
- A cognitive psychologist compares the ability of people to recall words that they were instructed to “read” with their ability to recall words that they were instructed to “imagine.”
- A manager studies the correlation between new employees’ college grade point averages and their first-year performance reports.
- An automotive engineer installs different stick shifts in a new car prototype, each time asking several people to rate how comfortable the stick shift feels.
- A food scientist studies the relationship between the temperature inside people’s refrigerators and the amount of bacteria on their food.
- A social psychologist tells some research participants that they need to hurry over to the next building to complete a study. She tells others that they can take their time. Then she observes whether they stop to help a research assistant who is pretending to be hurt.
- Kanner, A. D., Coyne, J. C., Schaefer, C., & Lazarus, R. S. (1981). Comparison of two modes of stress measurement: Daily hassles and uplifts versus major life events. Journal of Behavioural Medicine, 4 , 1–39. ↵
- Levine, R. V., & Norenzayan, A. (1999). The pace of life in 31 countries. Journal of Cross-Cultural Psychology, 30 , 178–205. ↵
- Kraut, R. E., & Johnston, R. E. (1979). Social and emotional messages of smiling: An ethological approach. Journal of Personality and Social Psychology, 37 , 1539–1553. ↵
- Pelham, B. W., Carvallo, M., & Jones, J. T. (2005). Implicit egotism. Current Directions in Psychological Science, 14 , 106–110. ↵
- Peterson, C., Seligman, M. E. P., & Vaillant, G. E. (1988). Pessimistic explanatory style is a risk factor for physical illness: A thirty-five year longitudinal study. Journal of Personality and Social Psychology, 55 , 23–27. ↵
An approach to data collection that involves observing people’s behaviour in the environment in which it typically occurs.
A judgment on part of the observers by clearly defining a set of target behaviours.
Data that have already been collected for some other purpose.
A family of systematic approaches to measurement using complex archival data.
Research Methods in Psychology - 2nd Canadian Edition Copyright © 2015 by Paul C. Price, Rajiv Jhangiani, & I-Chant A. Chiang is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- How it works

Correlational Research – Steps & Examples
Published by Carmen Troy at August 14th, 2021 , Revised On August 29, 2023
In correlational research design , a researcher measures the association between two or more variables or sets of scores. A researcher doesn’t have control over the variables .
Example: Relationship between income and age.
Types of Correlations
Based on the number of variables
Based on the direction of change of variables
When to Use Correlation Design?
Correlation research design is used when experimental studies are difficult to design.
Example: You want to know the impact of tobacco on people’s health and the extent of their addiction. You can’t distribute tobacco among your participants to understand its effect and addiction level. Instead of it, you can collect information from the people who are already addicted to tobacco and affected by it.
It is used to identify the association between two or more variables.
Example: You want to find out whether there is a correlation between the increasing population and poverty among the people. You don’t think that an increasing population leads to unemployment, but identifying a relationship can help you find a better answer to your study.
Example: You want to find out whether high income causes obesity. However, you don’t see any relationship. However, you can still find out the association between the lifestyle, age, and eating patterns of the people to make predictions of your research question.
Does your Research Methodology Have the Following?
- Great Research/Sources
- Perfect Language
- Accurate Sources
If not, we can help. Our panel of experts makes sure to keep the 3 pillars of Research Methodology strong.

How to Conduct Correlation Research?
Step 1: select the problem.
You can select the issues according to the requirement of your research. There are three common types of problems as follows;
- Is there any relationship between the two variables?
- How well does a variable predict another variable?
- What could be the association between a large number of variables and what predictions you can make?
Step 2: Select the Sample
You need to select the sample carefully and randomly if necessary. Your sample size should not be more than 30.
Step 3: Collect the Data
There are various types of data collection methods used in correlational research. The most common methods used for data collection are as follows:
Surveys are the most frequently used method for collecting data. It helps find the association between variables based on the participants’ responses selected for the study. You can carry out the surveys online, face-to-face, and on the phone.
Example: You want to find out the association between poverty and unemployment. You need to distribute a questionnaire about the sources of income and expenses among the participants. You can analyse the information obtained to identify whether unemployment leads to poverty.
Naturalistic Observation
In the naturalistic observation method, you need to collect the participants’ data by observing them in their natural surroundings. You can consider it as a type of field research. You can observe people and gather information from them in various public places such as stores, malls, parks, playgrounds, etc. The participants are not informed about the research. However, you need to ensure the anonymity of the participants. It includes both qualitative and quantitative data.
Example: You want to find out the correlation between the price hike of vegetables and whether changes. You need to visit the market and talk to vegetable vendors to collect the required information. You can categorise the information according to the price, whether change effects and challenges the vendors/farmers face during such periods.
Archival Data
Archival data is a type of data or information that already exists. Instead of collecting new data, you can use the existing data in your research if it fulfills your research requirements. Generally, previous studies or theories, records, documents, and transcripts are used as the primary source of information. This type of research is also called retrospective research.
Example: Suppose you want to find out the relation between exercise and weight loss. You can use various scholarly journals, health records, and scientific studies and discoveries based on people’s age and gender. You can identify whether exercise leads to significant weight loss among people of various ages and gender.
What is Causation?
The association between cause and effect is called causation . You can identify the correlation between the two variables, but they may not influence each other. It can be considered as the limitation of correlation research.
Example: You’ve found that people who exercise regularly lost maximum weight. However, it doesn’t prove that people who don’t use will gain weight. There could be many other possible variables, such as a healthy diet, age, stress, gender, and health condition, impacting people’s weight. You can’t find out the causation of your research problem. Still, you can collect and analyse data to support the theory. You can only predict the possibilities of the method, phenomena, or problem you are studying.
Frequently Asked Questions
How to describe correlational research.
Correlational research examines the relationship between two or more variables. It doesn’t imply causation but measures the strength and direction of association. Statistical analysis determines if changes in one variable correspond to changes in another, helping understand patterns and predict outcomes.
You May Also Like
You can transcribe an interview by converting a conversation into a written format including question-answer recording sessions between two or more people.
Ethnography is a type of research where a researcher observes the people in their natural environment. Here is all you need to know about ethnography.
Quantitative research is associated with measurable numerical data. Qualitative research is where a researcher collects evidence to seek answers to a question.
USEFUL LINKS
LEARNING RESOURCES

COMPANY DETAILS

- How It Works
Correlational Research in Psychology: Definition and How It Works
Categories Research Methods
Correlational research is a type of scientific investigation in which a researcher looks at the relationships between variables but does not vary, manipulate, or control them. It can be a useful research method for evaluating the direction and strength of the relationship between two or more different variables.
When examining how variables are related to one another, researchers may find that the relationship is positive or negative. Or they may also find that there is no relationship at all.
Table of Contents
How Does Correlational Research Work?
In correlational research, the researcher measures the values of the variables of interest and calculates a correlation coefficient, which quantifies the strength and direction of the relationship between the variables.
The correlation coefficient ranges from -1.0 to +1.0, where -1.0 represents a perfect negative correlation, 0 represents no correlation, and +1.0 represents a perfect positive correlation.
A negative correlation indicates that as the value of one variable increases, the value of the other variable decreases, while a positive correlation indicates that as the value of one variable increases, the value of the other variable also increases. A zero correlation indicates that there is no relationship between the variables.
Correlational Research vs. Experimental Research
Correlational research differs from experimental research in that it does not involve manipulating variables. Instead, it focuses on analyzing the relationship between two or more variables.
In other words, correlational research seeks to determine whether there is a relationship between two variables and, if so, the nature of that relationship.
Experimental research, on the other hand, involves manipulating one or more variables to determine the effect on another variable. Because of this manipulation and control of variables, experimental research allows for causal conclusions to be drawn, while correlational research does not.
Both types of research are important in understanding the world around us, but they serve different purposes and are used in different situations.
Types of Correlational Research
There are three main types of correlational studies:
Cohort Correlational Study
This type of study involves following a cohort of participants over a period of time. This type of research can be useful for understanding how certain events might influence outcomes.
For example, researchers might study how exposure to a traumatic natural disaster influences the mental health of a group of people over time.
By examining the data collected from these individuals, researchers can determine whether there is a correlation between the two variables under investigation. This information can be used to develop strategies for preventing or treating certain conditions or illnesses.
Cross-Sectional Correlational Study
A cross-sectional design is a research method that examines a group of individuals at a single time. This type of study collects information from a diverse group of people, usually from different backgrounds and age groups, to gain insight into a particular phenomenon or issue.
The data collected from this type of study is used to analyze relationships between variables and identify patterns and trends within the group.
Cross-sectional studies can help identify potential risk factors for certain conditions or illnesses, and can also be used to evaluate the prevalence of certain behaviors, attitudes, or beliefs within a population.
Case-Control Correlational Study
A case-control correlational study is a type of research design that investigates the relationship between exposure and health outcomes. In this study, researchers identify a group of individuals with the health outcome of interest (cases) and another group of individuals without the health outcome (controls).
The researchers then compare the exposure history of the cases and controls to determine whether the exposure and health outcome correlate.
This type of study design is often used in epidemiology and can provide valuable information about potential risk factors for a particular disease or condition.
When to Use Correlational Research
There are a number of situations where researchers might opt to use a correlational study instead of some other research design.
Correlational research can be used to investigate a wide range of psychological phenomena, including the relationship between personality traits and academic performance, the association between sleep duration and mental health, and the correlation between parental involvement and child outcomes.
To Generate Hypotheses
Correlational research can also be used to generate hypotheses for further research by identifying variables that are associated with each other.
To Investigate Variables Without Manipulating Them
Researchers should use correlational research when they want to investigate the relationship between two variables without manipulating them. This type of research is useful when the researcher cannot or should not manipulate one of the variables or when it is impossible to conduct an experiment due to ethical or practical concerns.
To Identify Patterns
Correlational research allows researchers to identify patterns and relationships between variables, which can inform future research and help to develop theories. However, it is important to note that correlational research does not prove that one variable causes changes in the other.
While correlational research has its limitations, it is still a valuable tool for researchers in many fields, including psychology, sociology, and education.
How to Collect Data in Correlational Research
Researchers can collect data for correlational research in a few different ways. To conduct correlational research, data can be collected using the following:
- Surveys : One method is through surveys, where participants are asked to self-report their behaviors or attitudes. This approach allows researchers to gather large amounts of data quickly and affordably.
- Naturalistic observation : Another method is through observation, where researchers observe and record behaviors in a natural or controlled setting. This method allows researchers to learn more about the behavior in question and better generalize the results to real-world settings.
- Archival, retrospective data : Additionally, researchers can collect data from archival sources, such as medical, school records, official records, or past polls.
The key is to collect data from a large and representative sample to measure the relationship between two variables accurately.
Pros and Cons of Correlational Research
There are some advantages of using correlational research, but there are also some downsides to consider.
- One of the strengths of correlational research is its ability to identify patterns and relationships between variables that may be difficult or unethical to manipulate in an experimental study.
- Correlational research can also be used to examine variables that are not under the control of the researcher , such as age, gender, or socioeconomic status.
- Correlational research can be used to make predictions about future behavior or outcomes, which can be valuable in a variety of fields.
- Correlational research can be conducted quickly and inexpensively , making it a practical option for researchers with limited resources.
- Correlational research is limited by its inability to establish causality between variables. Correlation does not imply causation, and it is possible that a third variable may be influencing both variables of interest, creating a spurious correlation. Therefore, it is important for researchers to use multiple methods of data collection and to be cautious when interpreting correlational findings.
- Correlational research relies heavily on self-reported data , which can be biased or inaccurate.
- Correlational research is limited in its ability to generalize findings to larger populations, as it only measures the relationship between two variables in a specific sample.
Frequently Asked Questions About Correlational Research
What are the main problems with correlational research.
Some of the main problems that can occur in correlational research include selection bias, confounding variables. and misclassification.
- Selecting participants based on their exposure to an event means that the sample might be biased since the selection was not randomized.
- Correlational studies may also be impacted by extraneous factors that researchers cannot control.
- Finally, there may be problems with how accurately data is recorded and classified, which can be particularly problematic in retrospective studies.
What are the variables in a correlational study?
In a correlational study, variables refer to any measurable factors being examined for their potential relationship or association with each other. These variables can be continuous (meaning they can take on a range of values) or categorical (meaning they fall into distinct categories or groups).
For example, in a study examining the correlation between exercise and mental health, the independent variable would be exercise frequency (measured in times per week), while the dependent variable would be mental health (measured using a standardized questionnaire).
What is the goal of correlational research?
The goal of correlational research is to examine the relationship between two or more variables. It involves analyzing data to determine if there is a statistically significant connection between the variables being studied.
Correlational research is useful for identifying patterns and making predictions but cannot establish causation. Instead, it helps researchers to better understand the nature of the relationship between variables and to generate hypotheses for further investigation.
How do you identify correlational research?
To identify correlational research, look for studies that measure two or more variables and analyze their relationship using statistical techniques. The results of correlational studies are typically presented in the form of correlation coefficients or scatterplots, which visually represent the degree of association between the variables being studied.
Correlational research can be useful for identifying potential causal relationships between variables but cannot establish causation on its own.
Curtis EA, Comiskey C, Dempsey O. Importance and use of correlational research . Nurse Researcher . 2016;23(6):20-25. doi10.7748/nr.2016.e1382
Lau F. Chapter 12 Methods for Correlational Studies . University of Victoria; 2017.
Mitchell TR. An evaluation of the validity of correlational research conducted in organizations . The Academy of Management Review . 1985;10(2):192. doi:10.5465/amr.1985.4277939
Seeram E. An overview of correlational research . Radiol Technol . 2019;91(2):176-179.
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Correlational Research
Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton
Learning Objectives
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of non-experimental research.
- Interpret the strength and direction of different correlation coefficients.
- Explain why correlation does not imply causation.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one or are not interested in causal relationships. Recall two goals of science are to describe and to predict and the correlational research strategy allows researchers to achieve both of these goals. Specifically, this strategy can be used to describe the strength and direction of the relationship between two variables and if there is a relationship between the variables then the researchers can use scores on one variable to predict scores on the other (using a statistical technique called regression, which is discussed further in the section on Complex Correlation in this chapter).
Another reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, while a researcher might be interested in the relationship between the frequency people use cannabis and their memory abilities they cannot ethically manipulate the frequency that people use cannabis. As such, they must rely on the correlational research strategy; they must simply measure the frequency that people use cannabis and measure their memory abilities using a standardized test of memory and then determine whether the frequency people use cannabis is statistically related to memory test performance.
Correlation is also used to establish the reliability and validity of measurements. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
Another strength of correlational research is that it is often higher in external validity than experimental research. Recall there is typically a trade-off between internal validity and external validity. As greater controls are added to experiments, internal validity is increased but often at the expense of external validity as artificial conditions are introduced that do not exist in reality. In contrast, correlational studies typically have low internal validity because nothing is manipulated or controlled but they often have high external validity. Since nothing is manipulated or controlled by the experimenter the results are more likely to reflect relationships that exist in the real world.
Finally, extending upon this trade-off between internal and external validity, correlational research can help to provide converging evidence for a theory. If a theory is supported by a true experiment that is high in internal validity as well as by a correlational study that is high in external validity then the researchers can have more confidence in the validity of their theory. As a concrete example, correlational studies establishing that there is a relationship between watching violent television and aggressive behavior have been complemented by experimental studies confirming that the relationship is a causal one (Bushman & Huesmann, 2001) [1] .
Does Correlational Research Always Involve Quantitative Variables?
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of daily hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure 6.2 shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. What defines a study is how the study is conducted.
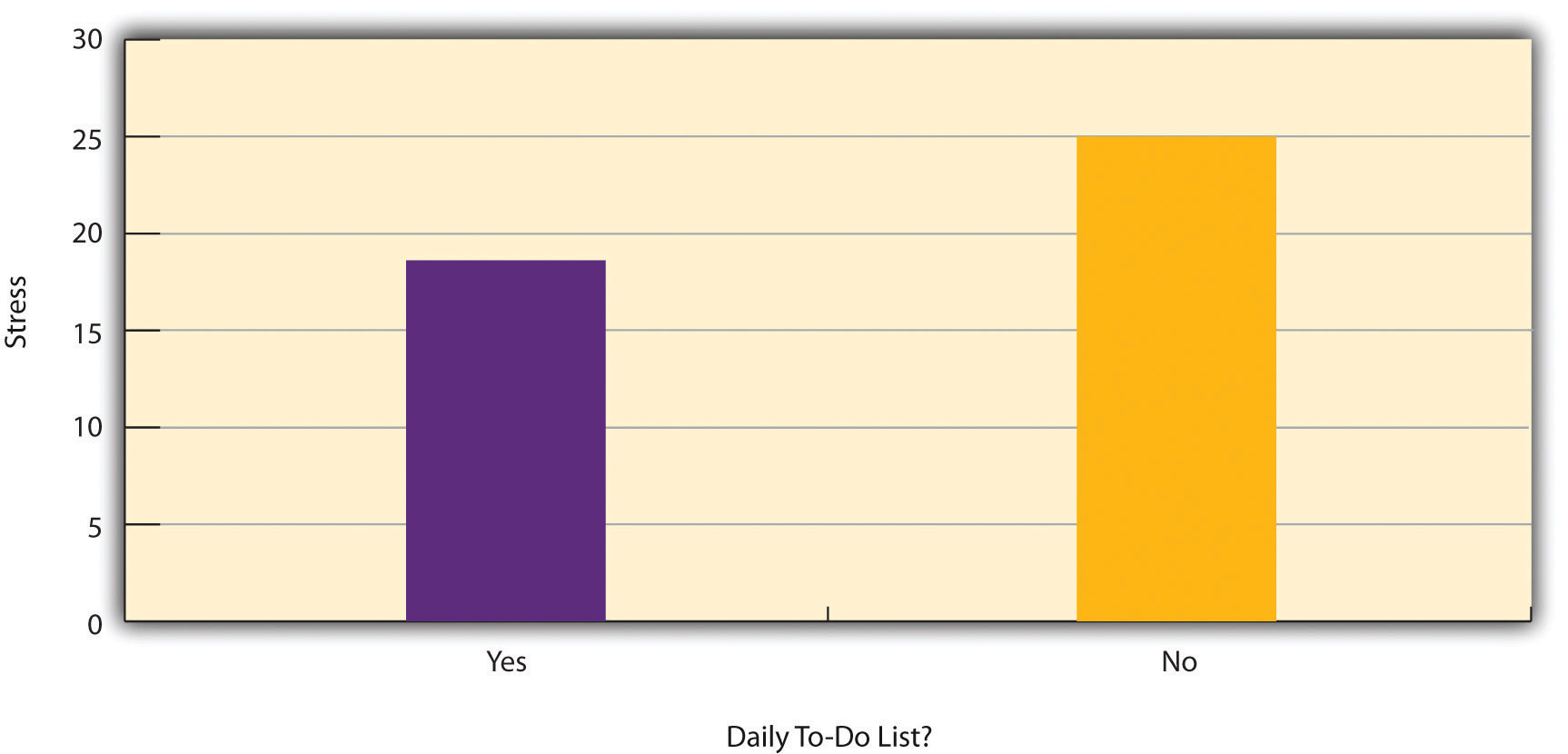
Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated.
Correlations Between Quantitative Variables
Correlations between quantitative variables are often presented using scatterplots . Figure 6.3 shows some hypothetical data on the relationship between the amount of stress people are under and the number of physical symptoms they have. Each point in the scatterplot represents one person’s score on both variables. For example, the circled point in Figure 6.3 represents a person whose stress score was 10 and who had three physical symptoms. Taking all the points into account, one can see that people under more stress tend to have more physical symptoms. This is a good example of a positive relationship , in which higher scores on one variable tend to be associated with higher scores on the other. In other words, they move in the same direction, either both up or both down. A negative relationship is one in which higher scores on one variable tend to be associated with lower scores on the other. In other words, they move in opposite directions. There is a negative relationship between stress and immune system functioning, for example, because higher stress is associated with lower immune system functioning.

The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson's r ) . As Figure 6.4 shows, Pearson’s r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship). A value of 0 means there is no relationship between the two variables. When Pearson’s r is 0, the points on a scatterplot form a shapeless “cloud.” As its value moves toward −1.00 or +1.00, the points come closer and closer to falling on a single straight line. Correlation coefficients near ±.10 are considered small, values near ± .30 are considered medium, and values near ±.50 are considered large. Notice that the sign of Pearson’s r is unrelated to its strength. Pearson’s r values of +.30 and −.30, for example, are equally strong; it is just that one represents a moderate positive relationship and the other a moderate negative relationship. With the exception of reliability coefficients, most correlations that we find in Psychology are small or moderate in size. The website http://rpsychologist.com/d3/correlation/ , created by Kristoffer Magnusson, provides an excellent interactive visualization of correlations that permits you to adjust the strength and direction of a correlation while witnessing the corresponding changes to the scatterplot.

There are two common situations in which the value of Pearson’s r can be misleading. Pearson’s r is a good measure only for linear relationships, in which the points are best approximated by a straight line. It is not a good measure for nonlinear relationships, in which the points are better approximated by a curved line. Figure 6.5, for example, shows a hypothetical relationship between the amount of sleep people get per night and their level of depression. In this example, the line that best approximates the points is a curve—a kind of upside-down “U”—because people who get about eight hours of sleep tend to be the least depressed. Those who get too little sleep and those who get too much sleep tend to be more depressed. Even though Figure 6.5 shows a fairly strong relationship between depression and sleep, Pearson’s r would be close to zero because the points in the scatterplot are not well fit by a single straight line. This means that it is important to make a scatterplot and confirm that a relationship is approximately linear before using Pearson’s r . Nonlinear relationships are fairly common in psychology, but measuring their strength is beyond the scope of this book.

The other common situations in which the value of Pearson’s r can be misleading is when one or both of the variables have a limited range in the sample relative to the population. This problem is referred to as restriction of range . Assume, for example, that there is a strong negative correlation between people’s age and their enjoyment of hip hop music as shown by the scatterplot in Figure 6.6. Pearson’s r here is −.77. However, if we were to collect data only from 18- to 24-year-olds—represented by the shaded area of Figure 6.6—then the relationship would seem to be quite weak. In fact, Pearson’s r for this restricted range of ages is 0. It is a good idea, therefore, to design studies to avoid restriction of range. For example, if age is one of your primary variables, then you can plan to collect data from people of a wide range of ages. Because restriction of range is not always anticipated or easily avoidable, however, it is good practice to examine your data for possible restriction of range and to interpret Pearson’s r in light of it. (There are also statistical methods to correct Pearson’s r for restriction of range, but they are beyond the scope of this book).

Correlation Does Not Imply Causation
You have probably heard repeatedly that “Correlation does not imply causation.” An amusing example of this comes from a 2012 study that showed a positive correlation (Pearson’s r = 0.79) between the per capita chocolate consumption of a nation and the number of Nobel prizes awarded to citizens of that nation [2] . It seems clear, however, that this does not mean that eating chocolate causes people to win Nobel prizes, and it would not make sense to try to increase the number of Nobel prizes won by recommending that parents feed their children more chocolate.
There are two reasons that correlation does not imply causation. The first is called the directionality problem . Two variables, X and Y , can be statistically related because X causes Y or because Y causes X . Consider, for example, a study showing that whether or not people exercise is statistically related to how happy they are—such that people who exercise are happier on average than people who do not. This statistical relationship is consistent with the idea that exercising causes happiness, but it is also consistent with the idea that happiness causes exercise. Perhaps being happy gives people more energy or leads them to seek opportunities to socialize with others by going to the gym. The second reason that correlation does not imply causation is called the third-variable problem . Two variables, X and Y , can be statistically related not because X causes Y , or because Y causes X , but because some third variable, Z , causes both X and Y . For example, the fact that nations that have won more Nobel prizes tend to have higher chocolate consumption probably reflects geography in that European countries tend to have higher rates of per capita chocolate consumption and invest more in education and technology (once again, per capita) than many other countries in the world. Similarly, the statistical relationship between exercise and happiness could mean that some third variable, such as physical health, causes both of the others. Being physically healthy could cause people to exercise and cause them to be happier. Correlations that are a result of a third-variable are often referred to as spurious correlations .
Some excellent and amusing examples of spurious correlations can be found at http://www.tylervigen.com (Figure 6.7 provides one such example).
“Lots of Candy Could Lead to Violence”
Although researchers in psychology know that correlation does not imply causation, many journalists do not. One website about correlation and causation, http://jonathan.mueller.faculty.noctrl.edu/100/correlation_or_causation.htm , links to dozens of media reports about real biomedical and psychological research. Many of the headlines suggest that a causal relationship has been demonstrated when a careful reading of the articles shows that it has not because of the directionality and third-variable problems.
One such article is about a study showing that children who ate candy every day were more likely than other children to be arrested for a violent offense later in life. But could candy really “lead to” violence, as the headline suggests? What alternative explanations can you think of for this statistical relationship? How could the headline be rewritten so that it is not misleading?
As you have learned by reading this book, there are various ways that researchers address the directionality and third-variable problems. The most effective is to conduct an experiment. For example, instead of simply measuring how much people exercise, a researcher could bring people into a laboratory and randomly assign half of them to run on a treadmill for 15 minutes and the rest to sit on a couch for 15 minutes. Although this seems like a minor change to the research design, it is extremely important. Now if the exercisers end up in more positive moods than those who did not exercise, it cannot be because their moods affected how much they exercised (because it was the researcher who used random assignment to determine how much they exercised). Likewise, it cannot be because some third variable (e.g., physical health) affected both how much they exercised and what mood they were in. Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships.
Media Attributions
- Nicholas Cage and Pool Drownings © Tyler Viegen is licensed under a CC BY (Attribution) license
- Bushman, B. J., & Huesmann, L. R. (2001). Effects of televised violence on aggression. In D. Singer & J. Singer (Eds.), Handbook of children and the media (pp. 223–254). Thousand Oaks, CA: Sage. ↵
- Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367 , 1562-1564. ↵
A graph that presents correlations between two quantitative variables, one on the x-axis and one on the y-axis. Scores are plotted at the intersection of the values on each axis.
A relationship in which higher scores on one variable tend to be associated with higher scores on the other.
A relationship in which higher scores on one variable tend to be associated with lower scores on the other.
A statistic that measures the strength of a correlation between quantitative variables.
When one or both variables have a limited range in the sample relative to the population, making the value of the correlation coefficient misleading.
The problem where two variables, X and Y , are statistically related either because X causes Y, or because Y causes X , and thus the causal direction of the effect cannot be known.
Two variables, X and Y, can be statistically related not because X causes Y, or because Y causes X, but because some third variable, Z, causes both X and Y.
Correlations that are a result not of the two variables being measured, but rather because of a third, unmeasured, variable that affects both of the measured variables.
Correlational Research Copyright © by Rajiv S. Jhangiani; I-Chant A. Chiang; Carrie Cuttler; and Dana C. Leighton is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Open access
- Published: 30 May 2024
Correlation between thyroid hormone sensitivity and the risk of polycystic ovary syndrome
- Qian Wang 1 , 2 ,
- Ru Zhao 2 , 3 ,
- Chen Han 2 , 4 ,
- Zeyu Huang 1 , 2 ,
- Yan Bi 1 , 2 ,
- Xiaowen Zhang ORCID: orcid.org/0000-0002-0072-2439 1 , 2 &
- Shanmei Shen ORCID: orcid.org/0000-0003-4949-0162 1 , 2
BMC Endocrine Disorders volume 24 , Article number: 76 ( 2024 ) Cite this article
117 Accesses
Metrics details
There has been some confusion in earlier research on the connection between thyroid function and polycystic ovary syndrome (PCOS). This research is aimed to probe into the correlation between thyroid condition and the risk of PCOS from a new standpoint of thyroid hormone sensitivity.
This research comprised 415 females with PCOS from Drum Tower Hospital Affiliated with the Medical School of Nanjing University, and 137 non-PCOS individuals were selected as the normal control. Based on free thyroxine (FT4), free triiodothyronine (FT3), and thyroid-stimulating hormone (TSH), we calculated the thyroid hormone sensitivity indices, which consist of Thyroid Feedback Quantile-based Index (TFQI), Thyroid-stimulating Hormone Index (TSHI), Thyrotroph Thyroxine Resistance Index (TT4RI) and Free Triiodothyronine /Free thyroxine (FT3/FT4). The binary logistic regression model was adopted to investigate the correlation between thyroid hormone sensitivity indices with the risk of PCOS. Pearson or Spearman correlation analysis was employed to explore the association among thyroid-related measures with metabolic parameters in PCOS.
Results of this research showed that females with PCOS had rising TFQI, TSHI, TT4RI, and FT3/FT4 levels compared with the control group. After adjustment for the impact of various covariates, there was no significant correlation between FT3/FT4 and the risk of PCOS; However, the odds ratio of the third and fourth vs. the first quartile of TFQI were 3.57(95% confidence interval [CI]:1.08,11.87) and 4.90(95% CI:1.38,17.38) respectively; The odds ratio of the fourth vs. the first quartile of TSHI was 5.35(95% CI:1.48,19.37); The odds ratio of the second vs. the first quartile of TT4RI was 0.27(95%CI 0.09,0.82). In addition, no significant correlation was observed between thyroid-related measures and metabolic measures in females with PCOS.
Conclusions
A reduction in the sensitivity of central thyroid hormone is closely correlated with a higher risk of PCOS. Further research is necessary to corroborate our findings and the supporting mechanisms.
Peer Review reports
Introduction
As one of the most prevalent endocrine illnesses, polycystic ovary syndrome (PCOS) influences almost 5–10% of females of child-bearing age [ 1 , 2 , 3 ]. Menstrual disorders, anovulation infertility, androgen excess, and polycystic changes in ovaries are all symptoms of PCOS. In addition, it is also in connection with an added accident of obesity, insulin resistance (IR), Type 2 diabetes (T2D), metabolic syndrome (MS), cardiovascular disease, and cancer of the endometrium [ 1 , 4 , 5 , 6 ].
Thyroid hormones are closely related to PCOS [ 7 ]. Multiple studies demonstrated that the prevalence of thyroid diseases was substantially greater in females with PCOS in comparison to age-matched controls [ 8 , 9 , 10 ]. For the past few years, a rising quantity of scholars has taken notice of the correlation between metabolic disorders and thyroid hormone sensitivity indexes which have been proven to be credible predictors of IR, T2D, hyperuricemia, cardiometabolic risk, and disturbances of lipid metabolism [ 11 , 12 , 13 , 14 ]. As a metabolic disease, however, PCOS has not been investigated concerning sensitivity to thyroid hormones. Therefore, we adopt four thyroid hormone sensitivity indices, including FT3/FT4, thyrotropin T4 resistance index (TT4RI), TSH index (TSHI), and thyroid feedback Quantile index (TFQI) [ 13 , 14 , 15 , 16 ], to look into the connection between thyroid conditions and PCOS.
Patients and methods
Study population.
The study group consists of 415 females with PCOS who visited the PCOS Special Clinic of our hospital from May 2016 to February 2019 (Fig. 1 ). Inclusion criteria: (1) Definite diagnosis of PCOS, all patients were diagnosed by an experienced endocrinologist or gynecologist with expertise in the field and underwent our re-evaluation before enrollment; (2) Age 18–40 years old; (3) Has not been treated for PCOS. Exclusion criteria: (1) Use of hormones or added medications in the last three months that could exert an impact on endocrine metabolism; (2) The existence of significant thyroid dysfunction; (3) Pregnancy or lactation; (4) Severe cardiopulmonary dysfunction and liver and kidney insufficiency. Another 137 cases of concurrent health check-up females were chosen as the control group. Inclusion criteria: (1) Females aged 18–40 years; (2) Clinical information and examination indicators are complete. Exclusion criteria: Individuals with PCOS, obesity, hypertension, hyperlipidemia, and other metabolic diseases are excluded.

Flowchart of the inclusion and exclusion of participants
Diagnostic criteria
The 2003 Rotterdam criteria revisions were used to diagnose PCOS [ 17 ]: (1). Oligo-ovulation and/or anovulation; (2). Hyperandrogenemia and/or clinical hyperandrogenic manifestations; (3). Polycystic changes in the ovaries; and exclusion of other diseases that may cause androgen excess such as Cushing’s syndrome.
Data collection
General clinical information such as age, height, weight, and blood pressure levels was recorded. And calculate body mass index (BMI). Approximately 5 ml of venous blood was drawn from each subject in the morning, on days 2–5 of the menstrual cycle, following a 12-hour overnight fast. Calculate thyroid hormone sensitivity indices: FT3/FT4 ratio = FT3/FT4, which indicates that peripheral thyroid hormone sensitivity is elevated when FT3/FT4 is higher. TT4RI = FT4 ∗ TSH, TSHI = lnTSH + 0.1345 ∗ FT4, the central thyroid hormone sensitivity is inversely linked to the TT4RI and TSHI values. TFQI = cdfFT4-(1-cdfTSH), the coefficient of TFQI is achieved by applying the medical examination population. TFQI is superior because it does not generate extremes even under the circumstance of thyroid dysfunction when compared to TT4RI and TSHI. TFQI takes the amount from − 1 to 1. A positive TFQI implies regular insensitivity, while a negative TFQI shows that the HPT axis is more responsive to variation in FT4, and 0 indicates normal sensitivity.
Laboratory tests
All laboratory parameters were measured at our hospital’s clinical laboratory, adhering to the ISO15189 international quality standard. The enzymatic auto-analyzer (Kyowa Medex Co., Ltd., Tokyo, Japan) was used to measure concentrations of Fasting Plasma Glucose (FPG), Triglyceride (TG), Total Cholesterol (TC), High-Density Lipoprotein Cholesterol (HDL-C), and Low-Density Lipoprotein Cholesterol (LDL-C), following the manufacturer’s instructions. Electrochemiluminescence (Roche Diagnostics, Basel, Switzerland) was used to measure serum levels of TSH, FT3, and FT4, according to standardized methods and rigorous quality control protocols. The reference ranges for each parameter are as follows. FPG, 3.9-6.1mmol/L; TG, ≤ 1.7mmol/L; TC, 2.9-5.72mmol/L; HDL-C, 0.94-2mmol/L; LDL-C, 1.89–3.1 mmol/L; TSH, 0.27–4.2 mIU/L; FT3, 3.1–6.8 pmol/L; FT4, 12–22 pmol/L.
Statistical analyze
The data were examined by adopting the program SPSS 27.0. Normally distributed variables were expressed as means ± SD, otherwise, they are expressed as quartiles. T-test and Mann-Whitney test were adopted to compare the differences between groups, separately. The binary logistic regression analysis was used to examine the overall PCOS risk at the thyroid hormone sensitivity index quartile. For finding the correlation, Pearson’s correlation was applied to continuous variables with normal distribution, while Spearman’s correlation was applied to skewed distributed ones. Statistics were deemed significant when P < 0.05.
This research contained 552 participants, and their average age was 28 (SD 3.51 years); 415 were patients with PCOS, and 137 were from the healthy check-up population, with clinical characteristics shown in Table 1 . Compared to the healthy check-up population, patients with PCOS had higher weight, BMI, blood pressure, FPG, TG, TC, LDL levels, lower HDL, and higher TSH, FT3, FT4, FT3/FT4, TT4RI, TSHI, TFQI levels ( P <0.05).
After age adjustment, in comparison to the first quartile of the TFQI (Q1), women in the third and fourth quartiles (Q3 and Q4) had a remarkably increased risk of PCOS by 130% (OR, 2.30;95% CI:1.32,4.00) and 240% (OR, 3.40;95% CI:1.87,6.18) separately (Table 2 ). Similarly, compared with the TSHI Q1 group, women in the Q3 and Q4 groups had a markedly increased risk of PCOS by 75% (OR, 1.75;95% CI:1.04,2.96) and 352% (OR, 4.52;95% CI:2.04,2.96) separately. Meanwhile, compared with the TT4RI Q1 group, the risk of PCOS was increased by 322% (OR, 4.22;95% CI:2.15,8.31) in the Q4 group. The FT3/FT4 quartiles have progressively increased PCOS risk (OR, 2.48 to 6.01).
After further adjustment for BMI, compared to the Q1 of TFQI, women in Q3 and Q4 still had a significantly increased risk of PCOS (OR 4.47,5.49, respectively); Compared with the Q1 group of TSHI, the risk of PCOS increased in Q4 (OR = 6.24); Compared with the Q1 group in TT4RI, the risk of PCOS decreased in Q2 (OR = 0.24); No difference was observed in the risk of PCOS between FT3/FT4 groups.
After further adjustment for hypertension, FPG ≥ 7.0, and dyslipidemia, compared with Q1 of TFQI, women in Q3 and Q4 remained considerably more likely to have PCOS. (OR 3.57,4.90, respectively); Q4 in TSHI showed a higher incidence of PCOS compared to Q1 (OR = 5.35); Q2 in TT4RI showed a decreased risk of PCOS compared to Q1 (OR = 0.27); No difference was observed among FT3/FT4 groups.
While finding the correlation of thyroid-related parameters with clinical, metabolic, and hormonal measures, our results revealed no significant relationship ( r = 0.100 ∼ 0.166) (Table 3 ).
In this research, we probed into the correlation among thyroid hormone sensitivity with PCOS. We found that elevated peripheral thyroid hormone sensitivity (elevated FT3/FT4) was linked to an increased PCOS risk, but there was no noticeable correlation after accounting for numerous covariates. However, diminished central thyroid hormone sensitivity (elevated TFQI, TSHI) was in connection to an elevated risk of PCOS and remained significantly associated after controlling for a few confounding factors.
Our study elucidates important associations between thyroid hormone resistance and the occurrence of PCOS. This finding provides clinicians with a deeper understanding of the underlying mechanisms involved in PCOS. Furthermore, our study sheds light on thyroid hormone sensitivity served as a potential risk indicator that can aid in early identification and early intervention of PCOS patients, thereby improving patient outcomes. More importantly, addressing thyroid hormone resistance in PCOS patients may hold therapeutic potential for improving their symptoms and overall prognosis. By improving thyroid hormone sensitivity or optimizing thyroid hormone levels, clinicians may be able to mitigate the metabolic and reproductive disturbances associated with PCOS. This could potentially lead to better outcomes, such as improved menstrual regularity, ovulation, and fertility, as well as a reduction in insulin resistance, and other metabolic abnormalities.
PCOS and thyroid diseases are both common endocrine diseases, and even though they are completely different diseases, they share quantities of clinical features, including irregular menstruation, infertility, obesity, and abnormal glucose and lipid metabolism [ 3 , 18 , 19 , 20 ]. Although the correlation between PCOS and thyroid diseases has not been clear, several studies have confirmed that dyslipidemia and IR are more severe among sufferers with combined thyroid diseases like subclinical hypothyroidism and thyroid nodules than those with PCOS alone [ 21 , 22 , 23 , 24 ], implying that thyroid diseases may exacerbate metabolic disorders in PCOS patients. Nevertheless, there is still insufficient proof to say if thyroid conditions impact the onset and progression of PCOS. A population-based investigation reported that Danish PCOS females showed a considerably greater prevalence of thyroid diseases than the control group (2.5% vs. 0.7%) before the diagnosis of PCOS [ 25 ]. Two studies showed that PCOS was substantially more common in females with autoimmune thyroid illness by 39% (OR, 1.39; 95% CI:1.07,1.71) and 137% (OR, 2.37; 95% CI:1.22,4.62), separately [ 26 , 27 ]. However, another study indicated that there was no difference in PCOS prevalence between euthyroid women and subclinical hypothyroidism (SCH) women, and SCH was not a standalone PCOS risk factor (OR = 0.743,95% CI 0.423–1.305) [ 28 ]. The inconsistent findings of the research may be associated with the diverse criteria used to determine thyroid status and different participating members.
Furthermore, the hypothalamus influences the pituitary gland by releasing the thyrotropin-releasing hormone (TRH), and the pituitary directs the thyroid by the release of TSH. Once there are enough thyroid hormones in the blood, they will be coupled back to the pituitary and hypothalamus through negative feedback, reducing the production and secretion of TSH and TRH. In consideration of the HPT axis’ intricate interplay, it may be insufficient for individual parameters to reflect the thyroid status. We started to inquire into the unresolved debate on the correlation between thyroid and PCOS from the aspect of thyroid hormone sensitivity adopting composed indices.
Initially, some studies proposed TSHI and TT4RI to evaluate thyroid hormone sensitivity [ 15 , 16 ]. Afterwards, Laclaustra et al. [ 14 ] put forward a novel index, TFQI, which has greater stability in comparison to TSHI and TT4RI. They found that TFQI is in connection to obesity, diabetes, and MS in euthyroid people and suggested we can use this new index to detect decreased sensitivity to thyroid hormones. Several cross-sectional investigations have discovered that impaired thyroid hormone sensitivity is linked to coronary artery disease, non-alcoholic fatty liver disease, renal insufficiency, along with osteoarthritis [ 12 , 29 , 30 , 31 ]. Similarly, our findings imply that a higher TFQI is in connection to an elevated risk of PCOS, and this correlation remains statistically meaningful when other confounding factors are taken into account. Accordingly, we hypothesize that the occurrence of PCOS may be in connection with the central sensitivity to thyroid hormones.
Previous studies have examined the potential mechanisms by which thyroid hormones affect PCOS, mainly through the following: (1) Although currently an accepted genotypic milieu has not been set up, gene polymorphisms such as FBN3 gene variants cause the pathogenesis of PCOS and HT by affecting TGFb’s activity [ 32 , 33 ]. (2) Thyroid function antibodies (stimulatory or inhibitory) may interact with functional ovarian antibodies (stimulatory or inhibitory) [ 34 ]. (3) Through their impacts on FSH, LH, and GnRH levels, thyroid hormones have the power to regulate the growth of germ cells and even to disrupt the HPT axis’s ability to operate [ 35 ]. (4) In experiments involving animals, all thyroid axis receptors, such as TRH, TSH, and thyroid hormones, existed in the monkey uterus [ 36 ], and even TSH receptors, TRα1 receptors, and TRβ1 receptors were expressed in the human endometrium [ 37 ]. Of course, it cannot be excluded that the comparative deficiency of thyroid hormones due to reduced sensitivity may also influence PCOS by means of the above-mentioned mechanisms.
For all we know, this research marks the first to investigate the connection among thyroid hormone sensitivity with PCOS. Although this study is relatively novel and achieved significant results, there exist a few limitations as well. The first and foremost is data missing: gonadal hormones and insulin concentrations are not routinely measured in healthy check-up populations, so the possibility of residual confounding factors cannot be eliminated. Secondly, epidemiological surveys are subject to challenges such as genetic, environmental, as well as other variables which could affect clinical outcomes, and consequently, we should view the results with a cautious eye. Furthermore, as an inventory survey, this investigation has not been capable of identifying the fundamental causes of the phenomenon. Further prospective studies are needed to confirm the potential benefits of improving thyroid hormone resistance in PCOS patients, including symptom, reproductive function, and prognostic assessment, to provide strong evidence of its effectiveness. In addition, mechanistic studies can reveal the molecular pathways between improvement of thyroid hormone resistance and improvement of PCOS symptoms, which can enhance the understanding of PCOS pathophysiology and investigate therapeutic targets.
Our research elucidates the linkage among PCOS risk in euthyroid people with diminished central sensitivity to thyroid hormones. Compared to individual parameters such as TSH and FT4, composed indices such as TFQI exhibit a stronger association with PCOS. Therefore, TFQI is expected to be a novel potential risk indicator to help clinicians early identify patients with high risk of PCOS.
Continuous variables are presented as mean ± standard deviation (SD) or median (interquartile range).
Abbreviations: BMI, body mass index; SBP, systolic blood pressure; DBP, diastolic blood pressure; FPG, fasting plasma glucose level; TG, triglycerides; TC, total cholesterol; HDL-C, high-density lipoprotein cholesterol; LDL-C, low-density lipoprotein cholesterol; TSH, thyroid stimulating hormone; FT3, free triiodothyronine; FT4, free thyroxine; TT4RI, Thyrotropin T4 resistance index; TSHI, TSH index; TFQI, thyroid feedback quantile-based index.
Data availability
Data and materials are available from the corresponding author on reasonable request.
Nandi A, Chen Z, Patel R, Poretsky L. Polycystic ovary syndrome. Endocrinol Metab Clin North Am. 2014;43(1):123–47. https://doi.org/10.1016/j.ecl.2013.10.003
Article PubMed Google Scholar
Escobar-Morreale HF. Polycystic ovary syndrome: treatment strategies and management. Expert Opin Pharmacother. 2008;9(17):2995–3008. https://doi.org/10.1517/14656560802559932
Fauser BC, Tarlatzis BC, Rebar RW, et al. Consensus on women’s health aspects of polycystic ovary syndrome (PCOS): the Amsterdam ESHRE/ASRM-Sponsored 3rd PCOS consensus workshop group. Fertil Steril. 2012;97(1):28–e3825. https://doi.org/10.1016/j.fertnstert.2011.09.024
Moran LJ, Misso ML, Wild RA, Norman RJ. Impaired glucose tolerance, type 2 diabetes and metabolic syndrome in polycystic ovary syndrome: a systematic review and meta-analysis. Hum Reprod Update. 2010;16(4):347–63. https://doi.org/10.1093/humupd/dmq001
Article CAS PubMed Google Scholar
Chen L, Xu WM, Zhang D. Association of abdominal obesity, insulin resistance, and oxidative stress in adipose tissue in women with polycystic ovary syndrome [published correction appears in Fertil Steril. 2014;102(5):1499]. Fertil Steril. 2014;102(4):1167–1174.e4. https://doi.org/10.1016/j.fertnstert.2014.06.027
Setji TL, Brown AJ. Polycystic ovary syndrome: update on diagnosis and treatment. Am J Med. 2014;127(10):912–9. https://doi.org/10.1016/j.amjmed.2014.04.017
Gaberšček S, Zaletel K, Schwetz V, Pieber T, Obermayer-Pietsch B, Lerchbaum E. Mechanisms in endocrinology: thyroid and polycystic ovary syndrome. Eur J Endocrinol. 2015;172(1):R9–21. https://doi.org/10.1530/EJE-14-0295
Kachuei M, Jafari F, Kachuei A, Keshteli AH. Prevalence of autoimmune thyroiditis in patients with polycystic ovary syndrome. Arch Gynecol Obstet. 2012;285(3):853–6. https://doi.org/10.1007/s00404-011-2040-5
Romitti M, Fabris VC, Ziegelmann PK, Maia AL, Spritzer PM. Association between PCOS and autoimmune thyroid disease: a systematic review and meta-analysis. Endocr Connect. 2018;7(11):1158–67. https://doi.org/10.1530/EC-18-0309 . Published 2018 Oct 26.
Article CAS PubMed PubMed Central Google Scholar
Glintborg D, Rubin KH, Nybo M, Abrahamsen B, Andersen M. Increased risk of thyroid disease in Danish women with polycystic ovary syndrome: a cohort study. Endocr Connect. 2019;8(10):1405–15. https://doi.org/10.1530/EC-19-0377
Sun Y, Teng D, Zhao L, et al. Impaired sensitivity to thyroid hormones is associated with hyperuricemia, obesity, and cardiovascular disease risk in subjects with subclinical hypothyroidism. Thyroid. 2022;32(4):376–84. https://doi.org/10.1089/thy.2021.0500
Lai S, Li J, Wang Z, Wang W, Guan H. Sensitivity to thyroid hormone indices are closely associated with NAFLD. Front Endocrinol (Lausanne). 2021;12:766419. https://doi.org/10.3389/fendo.2021.766419 . Published 2021 Nov 5.
Štěpánek L, Horáková D, Štěpánek L, et al. Free triiodothyronine/free thyroxine (FT3/FT4) ratio is strongly associated with insulin resistance in euthyroid and hypothyroid adults: a cross-sectional study. Endokrynol Pol. 2021;72(1):8–13. https://doi.org/10.5603/EP.a2020.0066
Laclaustra M, Moreno-Franco B, Lou-Bonafonte JM, et al. Impaired sensitivity to thyroid hormones is associated with diabetes and metabolic syndrome. Diabetes Care. 2019;42(2):303–10. https://doi.org/10.2337/dc18-1410
Yagi H, Pohlenz J, Hayashi Y, Sakurai A, Refetoff S. Resistance to thyroid hormone caused by two mutant thyroid hormone receptors beta, R243Q and R243W, with marked impairment of function that cannot be explained by altered in vitro 3,5,3’-triiodothyroinine binding affinity. J Clin Endocrinol Metab. 1997;82(5):1608–14. https://doi.org/10.1210/jcem.82.5.3945
Jostel A, Ryder WD, Shalet SM. The use of thyroid function tests in the diagnosis of hypopituitarism: definition and evaluation of the TSH Index. Clin Endocrinol (Oxf). 2009;71(4):529–34. https://doi.org/10.1111/j.1365-2265.2009.03534.x
Rotterdam ESHRE, ASRM-Sponsored PCOS consensus workshop group. Revised 2003 consensus on diagnostic criteria and long-term health risks related to polycystic ovary syndrome (PCOS). Hum Reprod. 2004;19(1):41–7. https://doi.org/10.1093/humrep/deh098
Article Google Scholar
Singla R, Gupta Y, Khemani M, Aggarwal S. Thyroid disorders and polycystic ovary syndrome: an emerging relationship. Indian J Endocrinol Metab. 2015;19(1):25–9. https://doi.org/10.4103/2230-8210.146860
Article PubMed PubMed Central Google Scholar
Peddemul A, Tejovath S, Hassan D, et al. Influence of subclinical hypothyroidism on women with polycystic ovary syndrome: a Literature Review. Cureus. 2022;14(8):e28468. https://doi.org/10.7759/cureus.28468 . Published 2022 Aug 27.
Han C, He X, Xia X, et al. Subclinical hypothyroidism and type 2 diabetes: a systematic review and meta-analysis. PLoS ONE. 2015;10(8):e0135233. https://doi.org/10.1371/journal.pone.0135233 . Published 2015 Aug 13.
Mueller A, Schöfl C, Dittrich R, et al. Thyroid-stimulating hormone is associated with insulin resistance independently of body mass index and age in women with polycystic ovary syndrome. Hum Reprod. 2009;24(11):2924–30. https://doi.org/10.1093/humrep/dep285
Yu Q, Wang JB. Subclinical hypothyroidism in PCOS: impact on presentation, insulin resistance, and cardiovascular risk. Biomed Res Int. 2016;2016:2067087. https://doi.org/10.1155/2016/2067087
Benetti-Pinto CL, Berini Piccolo VR, Garmes HM, Teatin Juliato CR. Subclinical hypothyroidism in young women with polycystic ovary syndrome: an analysis of clinical, hormonal, and metabolic parameters. Fertil Steril. 2013;99(2):588–92. https://doi.org/10.1016/j.fertnstert.2012.10.006
Karaköse M, Hepsen S, Çakal E, et al. Frequency of nodular goiter and autoimmune thyroid disease and association of these disorders with insulin resistance in polycystic ovary syndrome. J Turk Ger Gynecol Assoc. 2017;18(2):85–9. https://doi.org/10.4274/jtgga.2016.0217
Glintborg D, Hass Rubin K, Nybo M, Abrahamsen B, Andersen M. Morbidity and medicine prescriptions in a nationwide Danish population of patients diagnosed with polycystic ovary syndrome. Eur J Endocrinol. 2015;172(5):627–38. https://doi.org/10.1530/EJE-14-1108
Ho CW, Chen HH, Hsieh MC, et al. Increased risk of polycystic ovary syndrome and it’s comorbidities in women with autoimmune thyroid disease. Int J Environ Res Public Health. 2020;17(7):2422. https://doi.org/10.3390/ijerph17072422 . Published 2020 Apr 2.
Ho CW, Chen HH, Hsieh MC, et al. Hashimoto’s thyroiditis might increase polycystic ovary syndrome and associated comorbidities risks in Asia. Ann Transl Med. 2020;8(11):684. https://doi.org/10.21037/atm-19-4763
Zhang B, Wang J, Shen S, et al. Subclinical hypothyroidism is not a risk factor for polycystic ovary syndrome in obese women of reproductive age. Gynecol Endocrinol. 2018;34(10):875–9. https://doi.org/10.1080/09513590.2018.1462319
Yu N, Wang L, Zeng Y, et al. The association of thyroid hormones with coronary atherosclerotic severity in euthyroid patients. Horm Metab Res. 2022;54(1):12–9. https://doi.org/10.1055/a-1718-6283
Yang S, Lai S, Wang Z, Liu A, Wang W, Guan H. Thyroid feedback quantile-based index correlates strongly to renal function in euthyroid individuals. Ann Med. 2021;53(1):1945–55. https://doi.org/10.1080/07853890.2021.1993324
Chen S, Sun X, Zhou G, Jin J, Li Z. Association between sensitivity to thyroid hormone indices and the risk of osteoarthritis: an NHANES study. Eur J Med Res. 2022;27(1):114. https://doi.org/10.1186/s40001-022-00749-1 . Published 2022 Jul 11.
Akinci B, Comlekci A, Yener S, et al. Hashimoto’s thyroiditis, but not treatment of hypothyroidism, is associated with altered TGF-beta1 levels. Arch Med Res. 2008;39(4):397–401. https://doi.org/10.1016/j.arcmed.2007.12.001
Raja-Khan N, Urbanek M, Rodgers RJ, Legro RS. The role of TGF-β in polycystic ovary syndrome. Reprod Sci. 2014;21(1):20–31. https://doi.org/10.1177/1933719113485294
Gleicher N, Barad D, Weghofer A. Functional autoantibodies, a new paradigm in autoimmunity? Autoimmun Rev. 2007;7(1):42–5. https://doi.org/10.1016/j.autrev.2007.06.001
Ren B, Zhu Y. A new perspective on thyroid hormones: crosstalk with reproductive hormones in females. Int J Mol Sci. 2022;23(5):2708. https://doi.org/10.3390/ijms23052708 . Published 2022 Feb 28.
Hulchiy M, Zhang H, Cline JM, Hirschberg AL, Sahlin L. Receptors for thyrotropin-releasing hormone, thyroid-stimulating hormone, and thyroid hormones in the macaque uterus: effects of long-term sex hormone treatment. Menopause. 2012;19(11):1253–9. https://doi.org/10.1097/gme.0b013e318252e450
Catalano RD, Critchley HO, Heikinheimo O, et al. Mifepristone induced progesterone withdrawal reveals novel regulatory pathways in human endometrium. Mol Hum Reprod. 2007;13(9):641–54. https://doi.org/10.1093/molehr/gam021
Download references
Acknowledgements
Not applicable.
This project was supported by the National Nature Science Funds of China (Grant No.81800752), the grant from Jiangsu Research Hospital Association for Precision Medication (JY202041), and Fundings for Clinical Trials from the Affiliated Drum Tower Hospital, Medical School of Nanjing University (Grant No.2022-YXZX-NFM-02).
Author information
Authors and affiliations.
Department of Endocrinology, Endocrine and Metabolic Disease Medical Center, Nanjing Drum Tower Hospital, Affiliated Hospital of Medical School, Nanjing University, Nanjing, China
Qian Wang, Zeyu Huang, Yan Bi, Xiaowen Zhang & Shanmei Shen
Branch of National Clinical Research Centre for Metabolic Diseases, Nanjing, China
Qian Wang, Ru Zhao, Chen Han, Zeyu Huang, Yan Bi, Xiaowen Zhang & Shanmei Shen
Department of Endocrinology, Endocrine and Metabolic Disease Medical Center, Nanjing Drum Tower Hospital Clinical College of Nanjing Medical University, Nanjing, China
Department of Endocrinology and Metabolism, Drum Tower Clinical Medical College, Southeast University, Nanjing, China
You can also search for this author in PubMed Google Scholar
Contributions
Qian Wang analyzed the data and wrote the article. Ru Zhao assisted in statistical analysis. Chen Han and Zeyu Huang collected the data together. All authors read and approved the final manuscript.
Corresponding authors
Correspondence to Yan Bi , Xiaowen Zhang or Shanmei Shen .
Ethics declarations
Ethics approval and consent to participate.
All experiments and methods were performed in accordance with the Declaration of Helsinki. This research approved by the Ethics Committee of Drum Tower Hospital Affiliated to School of Medicine of Nanjing University. Informed consent was obtained from all participants.
Consent for publication
Competing interests.
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Wang, Q., Zhao, R., Han, C. et al. Correlation between thyroid hormone sensitivity and the risk of polycystic ovary syndrome. BMC Endocr Disord 24 , 76 (2024). https://doi.org/10.1186/s12902-024-01607-3
Download citation
Received : 19 May 2023
Accepted : 23 May 2024
Published : 30 May 2024
DOI : https://doi.org/10.1186/s12902-024-01607-3
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Sensitivity to thyroid hormones
- Polycystic ovary syndrome
BMC Endocrine Disorders
ISSN: 1472-6823
- General enquiries: [email protected]
What executives are saying about the future of hybrid work
In the postpandemic future of work, nine out of ten organizations will be combining remote and on-site working, according to a new McKinsey survey of 100 executives across industries and geographies. 1 From December 2020 through January 2021, McKinsey surveyed and analyzed responses from 100 respondents at the C-suite, vice-president, and director level, evenly split among organizations based in Asia, Europe, Latin America, and the United States, and among a variety of industries. Company revenues ranged, on average, from $5.1 billion to $11.0 billion per year. The survey confirms that productivity and customer satisfaction have increased during the pandemic.
About the authors

A McKinsey Live event on ‘Getting hybrid work right: What employees are saying’
The following charts, drawn from our survey, offer insights for executives who are sorting out the particulars of the hybrid approach. A notable finding is that organizations with the biggest productivity increases during the pandemic have supported and encouraged “small moments of engagement” among their employees, moments in which coaching, mentorship, idea sharing, and coworking take place. These organizations are preparing for hybrid working by training managers for remote leadership, by reimagining processes, and by rethinking how to help employees thrive in their roles.
The future will be more hybrid. Prior to the COVID-19 crisis, the majority of organizations required employees to spend most of their time on-site. But as the pandemic eases, executives say that the hybrid model—in which employees work both remotely and in the office—will become far more common. The majority of executives expect that (for all roles that aren’t essential to perform on-site) employees will be on-site between 21 and 80 percent of the time, or one to four days per week.
Future vision. Although nine out of ten executives envision a hybrid model going forward, most have at best a high-level plan for how to carry it out—and nearly a third of them say that their organizations lack alignment on a high-level vision among the top team. Although another third of organizations have a more detailed vision in place, only one in ten organizations have begun communicating and piloting that vision.
Productive nonetheless. The survey also confirms that during the pandemic most organizations have seen rises in individual and team productivity and employee engagement, and, perhaps as a result of this increased focus and energy, a rise in the satisfaction of their customers as well.
But not every organization has experienced the same improvement. Take individual productivity. Some 58 percent of executives report improvements in individual productivity, but an additional third say that productivity has not changed. Lagging companies, which make up 10 percent of respondents, relate that individual productivity has declined during the pandemic. It’s important to note the high correlation between individual and team productivity: C-suite executives who say that individual productivity has improved are five times more likely to report that team productivity has risen too.
Making the small connections count. Why have some companies enjoyed higher productivity during the pandemic? According to our survey, they’re the ones supporting small connections between colleagues—opportunities to discuss projects, share ideas, network, mentor, and coach, for example. Two-thirds of productivity leaders report that these kinds of “microtransactions” have increased, compared with just 9 percent of productivity laggards. As executives look to sustain pandemic-style productivity gains with a hybrid model, they will need to design and develop the right spaces for these small interactions to take place.
Managing differently. Supporting small moments of connection requires subtle shifts in how managers work. Nearly all executives surveyed recognize that managing remotely differs from when all employees are on-site, but other subtleties may not be as apparent. Nuances can be seen in the more than half of productivity leaders that have trained their managers on how to lead teams more effectively. Only a third of productivity laggards have done the same. The emphasis on small connections suggests that organizations could better support managers by, among other things, educating them about the positive and negative impact they have on the people who report to them, and by training managers on soft skills , such as providing and receiving feedback. Organizations can also explore novel ways to address the loss of empathy that often accompanies gains in authority.
Experiment and iterate. Across organizations, executives already recognize the need to redesign processes to better support a remote workforce—with the majority having at least identified the processes that will require rethinking. But productivity leaders are more likely to continually iterate and tweak their processes as the context shifts. As organizations look to codify the hybrid model, there is evidence that the test-and-learn approach to process redesign will be an important enabler.
Reimagine hiring. Hiring is among the most crucial processes to reconsider in the hybrid world. Should organizations continue to hire within specific geographies, or should they open up their talent aperture beyond traditional recruiting locations, for instance? Should they conduct more remote interviews? During the pandemic, nearly two-thirds of organizations have moved in-person recruiting events and activities to remote settings, but only one in three have reimagined hiring from the ground up. Forty percent of productivity leaders, by contrast, have holistically redesigned their entire hiring process.
Rethink talent allocation. During the pandemic, nearly two-thirds of organizations have reassessed the number of people in each role and in each function in the company. But productivity leaders are more likely than middle performers and laggards to fall into this category. A select few leading companies have taken it even further and have gone beyond reassessing to actually implementing changes. As organizations redesign their hybrid future, matching the workforce with the right priorities could help spur productivity improvements.
Andrea Alexander is an associate partner in McKinsey’s Houston office, where Mihir Mysore is a partner; Rich Cracknell is a solution leader in the Silicon Valley office; Aaron De Smet is a senior partner in the New Jersey office; and Meredith Langstaff is an associate partner in the Washington, DC, office, where Dan Ravid is a research and knowledge fellow.
This article was edited by Lang Davison, an executive editor in the Seattle office.
Explore a career with us
Related articles.

What employees are saying about the future of remote work

Reimagining the postpandemic workforce

Reimagining the postpandemic organization

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
5.3: Correlational Research
- Last updated
- Save as PDF
- Page ID 20165

- Rajiv S. Jhangiani, I-Chant A. Chiang, Carrie Cuttler, & Dana C. Leighton
- Kwantlen Polytechnic U., Washington State U., & Texas A&M U.—Texarkana
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
- Define correlational research and give several examples.
- Explain why a researcher might choose to conduct correlational research rather than experimental research or another type of non-experimental research.
- Interpret the strength and direction of different correlation coefficients.
- Explain why correlation does not imply causation.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one or are not interested in causal relationships. Recall two goals of science are to describe and to predict and the correlational research strategy allows researchers to achieve both of these goals. Specifically, this strategy can be used to describe the strength and direction of the relationship between two variables and if there is a relationship between the variables then the researchers can use scores on one variable to predict scores on the other (using a statistical technique called regression, which is discussed further in the section on Complex Correlation in this chapter).
Another reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, while a researcher might be interested in the relationship between the frequency people use cannabis and their memory abilities they cannot ethically manipulate the frequency that people use cannabis. As such, they must rely on the correlational research strategy; they must simply measure the frequency that people use cannabis and measure their memory abilities using a standardized test of memory and then determine whether the frequency people use cannabis is statistically related to memory test performance.
Correlation is also used to establish the reliability and validity of measurements. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variabl e do not apply to this kind of research.
Another strength of correlational research is that it is often higher in external validity than experimental research. Recall there is typically a trade-off between internal validity and external validity. As greater controls are added to experiments, internal validity is increased but often at the expense of external validity as artificial conditions are introduced that do not exist in reality. In contrast, correlational studies typically have low internal validity because nothing is manipulated or controlled but they often have high external validity. Since nothing is manipulated or controlled by the experimenter the results are more likely to reflect relationships that exist in the real world.
Finally, extending upon this trade-off between internal and external validity, correlational research can help to provide converging evidence for a theory. If a theory is supported by a true experiment that is high in internal validity as well as by a correlational study that is high in external validity then the researchers can have more confidence in the validity of their theory. As a concrete example, correlational studies establishing that there is a relationship between watching violent television and aggressive behavior have been complemented by experimental studies confirming that the relationship is a causal one (Bushman & Huesmann, 2001) [1] .
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of daily hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Figure \(\PageIndex{1}\) shows data from a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. What defines a study is how the study is conducted.

Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated.
scatterplots. Figure \(\PageIndex{2}\) shows some hypothetical data on the relationship between the amount of stress people are under and the number of physical symptoms they have. Each point in the scatterplot represents one person’s score on both variables. For example, the circled point in Figure \(\PageIndex{2}\) represents a person whose stress score was 10 and who had three physical symptoms. Taking all the points into account, one can see that people under more stress tend to have more physical symptoms. This is a good example of a positive relationship , in which higher scores on one variable tend to be associated with higher scores on the other. In other words, they move in the same direction, either both up or both down. A negative relationship is one in which higher scores on one variable tend to be associated with lower scores on the other. In other words, they move in opposite directions. There is a negative relationship between stress and immune system functioning, for example, because higher stress is associated with lower immune system functioning.

The strength of a correlation between quantitative variables is typically measured using a statistic called Pearson’s Correlation Coefficient (or Pearson's r ) . As Figure \(\PageIndex{3}\) shows, Pearson’s r ranges from −1.00 (the strongest possible negative relationship) to +1.00 (the strongest possible positive relationship). A value of 0 means there is no relationship between the two variables. When Pearson’s r is 0, the points on a scatterplot form a shapeless “cloud.” As its value moves toward −1.00 or +1.00, the points come closer and closer to falling on a single straight line. Correlation coefficients near ±.10 are considered small, values near ± .30 are considered medium, and values near ±.50 are considered large. Notice that the sign of Pearson’s r is unrelated to its strength. Pearson’s r values of +.30 and −.30, for example, are equally strong; it is just that one represents a moderate positive relationship and the other a moderate negative relationship. With the exception of reliability coefficients, most correlations that we find in Psychology are small or moderate in size. The website http://rpsychologist.com/d3/correlation/ , created by Kristoffer Magnusson, provides an excellent interactive visualization of correlations that permits you to adjust the strength and direction of a correlation while witnessing the corresponding changes to the scatterplot.

There are two common situations in which the value of Pearson’s r can be misleading. Pearson’s r is a good measure only for linear relationships, in which the points are best approximated by a straight line. It is not a good measure for nonlinear relationships, in which the points are better approximated by a curved line. Figure \(\PageIndex{4}\), for example, shows a hypothetical relationship between the amount of sleep people get per night and their level of depression. In this example, the line that best approximates the points is a curve—a kind of upside-down “U”—because people who get about eight hours of sleep tend to be the least depressed. Those who get too little sleep and those who get too much sleep tend to be more depressed. Even though Figure \(\PageIndex{4}\) shows a fairly strong relationship between depression and sleep, Pearson’s r would be close to zero because the points in the scatterplot are not well fit by a single straight line. This means that it is important to make a scatterplot and confirm that a relationship is approximately linear before using Pearson’s r . Nonlinear relationships are fairly common in psychology, but measuring their strength is beyond the scope of this book.

The other common situations in which the value of Pearson’s r can be misleading is when one or both of the variables have a limited range in the sample relative to the population. This problem is referred to as restriction of range . Assume, for example, that there is a strong negative correlation between people’s age and their enjoyment of hip hop music as shown by the scatterplot in Figure \(\PageIndex{5}\). Pearson’s r here is −.77. However, if we were to collect data only from 18- to 24-year-olds—represented by the shaded area of Figure \(\PageIndex{5}\)—then the relationship would seem to be quite weak. In fact, Pearson’s r for this restricted range of ages is 0. It is a good idea, therefore, to design studies to avoid restriction of range. For example, if age is one of your primary variables, then you can plan to collect data from people of a wide range of ages. Because restriction of range is not always anticipated or easily avoidable, however, it is good practice to examine your data for possible restriction of range and to interpret Pearson’s r in light of it. (There are also statistical methods to correct Pearson’s r for restriction of range, but they are beyond the scope of this book).

Correlation Does Not Imply Causation
You have probably heard repeatedly that “Correlation does not imply causation.” An amusing example of this comes from a 2012 study that showed a positive correlation (Pearson’s r = 0.79) between the per capita chocolate consumption of a nation and the number of Nobel prizes awarded to citizens of that nation [2] . It seems clear, however, that this does not mean that eating chocolate causes people to win Nobel prizes, and it would not make sense to try to increase the number of Nobel prizes won by recommending that parents feed their children more chocolate.
There are two reasons that correlation does not imply causation. The first is called the directionality problem . Two variables, X and Y , can be statistically related because X causes Y or because Y causes X . Consider, for example, a study showing that whether or not people exercise is statistically related to how happy they are—such that people who exercise are happier on average than people who do not. This statistical relationship is consistent with the idea that exercising causes happiness, but it is also consistent with the idea that happiness causes exercise. Perhaps being happy gives people more energy or leads them to seek opportunities to socialize with others by going to the gym. The second reason that correlation does not imply causation is called the third-variable problem . Two variables, X and Y , can be statistically related not because X causes Y , or because Y causes X , but because some third variable, Z , causes both X and Y . For example, the fact that nations that have won more Nobel prizes tend to have higher chocolate consumption probably reflects geography in that European countries tend to have higher rates of per capita chocolate consumption and invest more in education and technology (once again, per capita) than many other countries in the world. Similarly, the statistical relationship between exercise and happiness could mean that some third variable, such as physical health, causes both of the others. Being physically healthy could cause people to exercise and cause them to be happier. Correlations that are a result of a third-variable are often referred to as spurious correlations.
Some excellent and amusing examples of spurious correlations can be found at http://www.tylervigen.com (Figure \(\PageIndex{6}\) provides one such example).

Although researchers in psychology know that correlation does not imply causation, many journalists do not. One website about correlation and causation, http://jonathan.mueller.faculty.noctrl.edu/100/correlation_or_causation.htm , links to dozens of media reports about real biomedical and psychological research. Many of the headlines suggest that a causal relationship has been demonstrated when a careful reading of the articles shows that it has not because of the directionality and third-variable problems.
One such article is about a study showing that children who ate candy every day were more likely than other children to be arrested for a violent offense later in life. But could candy really “lead to” violence, as the headline suggests? What alternative explanations can you think of for this statistical relationship? How could the headline be rewritten so that it is not misleading?
As you have learned by reading this book, there are various ways that researchers address the directionality and third-variable problems. The most effective is to conduct an experiment. For example, instead of simply measuring how much people exercise, a researcher could bring people into a laboratory and randomly assign half of them to run on a treadmill for 15 minutes and the rest to sit on a couch for 15 minutes. Although this seems like a minor change to the research design, it is extremely important. Now if the exercisers end up in more positive moods than those who did not exercise, it cannot be because their moods affected how much they exercised (because it was the researcher who used random assignment to determine how much they exercised). Likewise, it cannot be because some third variable (e.g., physical health) affected both how much they exercised and what mood they were in. Thus experiments eliminate the directionality and third-variable problems and allow researchers to draw firm conclusions about causal relationships.
- Bushman, B. J., & Huesmann, L. R. (2001). Effects of televised violence on aggression. In D. Singer & J. Singer (Eds.), Handbook of children and the media (pp. 223–254). Thousand Oaks, CA: Sage. ↵
- Messerli, F. H. (2012). Chocolate consumption, cognitive function, and Nobel laureates. New England Journal of Medicine, 367 , 1562-1564. ↵
IMAGES
VIDEO
COMMENTS
Correlational research is a type of study that explores how variables are related to each other. It can help you identify patterns, trends, and predictions in your data. In this guide, you will learn when and how to use correlational research, and what its advantages and limitations are. You will also find examples of correlational research questions and designs. If you want to know the ...
What Is Correlational Research? Correlational research is a type of nonexperimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in ...
A correlational research design investigates relationships between variables without the researcher controlling or manipulating any of them. A correlation reflects the strength and/or direction of the relationship between two (or more) variables. The direction of a correlation can be either positive or negative. Positive correlation.
A correlational study is an experimental design that evaluates only the correlation between variables. The researchers record measurements but do not control or manipulate the variables. Correlational research is a form of observational study. A correlation indicates that as the value of one variable increases, the other tends to change in a ...
A correlational study is a type of research design that looks at the relationships between two or more variables. Correlational studies are non-experimental, which means that the experimenter does not manipulate or control any of the variables. A correlation refers to a relationship between two variables. Correlations can be strong or weak and ...
Correlational research is a type of non-experimental research method in which a researcher measures two variables and understands and assesses the statistical relationship between them with no influence from any extraneous variable. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical ...
This page titled 6.2: Correlational Research is shared under a CC BY-NC-SA 3.0 license and was authored, remixed, and/or curated by Anonymous via source content that was edited to the style and standards of the LibreTexts platform; a detailed edit history is available upon request. Correlational research is a type of non-experimental research ...
Correlational research allows researchers to identify whether there is a relationship between variables, and if so, the strength and direction of that relationship. This information can be useful for predicting and explaining behavior, and for identifying potential risk factors or areas for intervention.
Correlational research is a psychological research method that examines the relationship between two or more variables using statistical techniques based on the research objectives. It typically involves collecting data on research variables using methods such as tests, surveys, interviews, and natural observations, without intervening or ...
Correlational research is a type of non-experimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical relationships between variables ...
Correlational Research. Correlation means that there is a relationship between two or more variables (such as ice cream consumption and crime), but this relationship does not necessarily imply cause and effect. When two variables are correlated, it simply means that as one variable changes, so does the other. We can measure correlation by calculating a statistic known as a correlation coefficient.
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical ...
Proper Interpretation of Correlation. Correlational analyses have been reported as one of the most common analytic techniques in research at the beginning of the 21 st century, particularly in health and epidemiological research. 15 Thus effective and proper interpretation is critical to understanding the literature.
Correlational Research. Correlation means that there is a relationship between two or more variables (such as ice cream consumption and crime), but this relationship does not necessarily imply cause and effect. When two variables are correlated, it simply means that as one variable changes, so does the other.
Correlational studies aim to find out if there are differences in the characteristics of a population depending on whether or not its subjects have been exposed to an event of interest in the naturalistic setting. In eHealth, correlational studies are often used to determine whether the use of an eHealth system is associated with a particular set of user characteristics and/or quality of care ...
Correlational research is a type of nonexperimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in statistical relationships between ...
Correlational Research - Steps & Examples. Published by Carmen Troy at August 14th, 2021 , Revised On August 29, 2023. In correlational research design, a researcher measures the association between two or more variables or sets of scores. A researcher doesn't have control over the variables. Example: Relationship between income and age.
Correlational research is a type of scientific investigation in which a researcher looks at the relationships between variables but does not vary, manipulate, or control them. It can be a useful research method for evaluating the direction and strength of the relationship between two or more different variables.
Positive correlational research is a research method involving 2 variables that are statistically corresponding where an increase or decrease in 1 variable creates a like change in the other. An example is when an increase in workers' remuneration results in an increase in the prices of goods and services and vice versa.
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical ...
Correlational research designs are often used in psychology, epidemiology, medicine and nursing. They show the strength of correlation that exists between the variables within a population. For this reason, these studies are also known as ecological studies. Correlational research design methods are characterized by such traits:
Correlation coefficients are useful for researchers seeking to understand relationships between variables. By comprehending the nuances of positive and negative correlations, employing appropriate measures such as Pearson's r or Spearman's rho, and exercising caution in interpretation, researchers can harness the power of correlation analysis effectively in their studies.
Background Adhesion G protein-coupled receptors (aGPCRs), a distinctive subset of the G protein-coupled receptor (GPCR) superfamily, play crucial roles in various physiological and pathological processes, with implications in tumor development. Despite the global prevalence of breast cancer (BRCA), specific aGPCRs as potential drug targets or biomarkers remain underexplored. Methods UALCAN ...
There has been some confusion in earlier research on the connection between thyroid function and polycystic ovary syndrome (PCOS). This research is aimed to probe into the correlation between thyroid condition and the risk of PCOS from a new standpoint of thyroid hormone sensitivity. This research comprised 415 females with PCOS from Drum Tower Hospital Affiliated with the Medical School of ...
In the postpandemic future of work, nine out of ten organizations will be combining remote and on-site working, according to a new McKinsey survey of 100 executives across industries and geographies. 1 From December 2020 through January 2021, McKinsey surveyed and analyzed responses from 100 respondents at the C-suite, vice-president, and director level, evenly split among organizations based ...
Correlational research is a type of non-experimental research in which the researcher measures two variables (binary or continuous) and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are many reasons that researchers interested in statistical ...
Using Digital Image Correlation for Quantifying Load Induced in Elastomers at Cryogenic Temperatures Elastomers have glass transition temperatures (TG) that are well below room temperature. Below this temperature, elastomers can suddenly exhibit significantly different mechanical properties than those exhibited at warmer temperatures.
Research Article. Encapsulation of Alpinia leaf essential oil in nanophytosome-embedded gel as novel strategy to treat periodontal infections: evaluation of antimicrobial effectiveness, pharmacokinetic, in vitro-ex vivo correlation and in silico studies ... pharmacokinetic, in vitro-ex vivo correlation and in silico studies. Bhabani Sankar ...
Finally, a case study was conducted on a district having 29,461 buildings in Shanghai, China to illustrate the influence of interstructural damage correlation on the regional seismic risk. Results show that disregarding the interstructural seismic damage correlation can lead to underestimation of overall loss uncertainty.