Four Optimization Meta-heuristic Approaches in Evaluating Groundwater Quality (Case study: Shiraz Plain)
- Research Paper
- Published: 20 June 2024

Cite this article

- Hossein Moayedi 1 , 2 ,
- Marjan Salari 3 ,
- T. N. G. Nguyen 4 &
- Atefeh Ahmadi Dehrashid 5
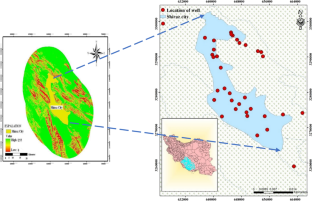
Estimating and predicting groundwater quality characteristics so that managers may make management decisions is one of the critical goals of water resource planners and managers. The complexity of groundwater networks makes it difficult to predict either the time or the location of groundwater. Many models have been created in this area, offering better management to preserve water quality. Most of these models call for input parameters that are either seldom accessible or expensively and laboriously measured. A better option among them is the Artificial Neural Network (ANN) Model, which draws inspiration from the human brain. This study uses Na + , Mg2 + , Ca2 + , Na%, K + , SO42 − , Cl − , pH, and HCO3 − quality parameters to estimate the Sodium Adsorption Ratio (SAR). The Shiraz Plain's groundwater quality was simulated using four optimization meta-heuristic methods, including biography-based optimization (BBO), black hole attack (BHA), sequential forward selection (SFS), and multi-verse optimization (MVO). These methods excel in adaptability, convergence speed, feature selection, diversity of solutions, and robustness to complex and noisy datasets, ultimately leading to more accurate and efficient predictive models than earlier methods. A statistical period of 16 years (2002–2018) was used to collect the groundwater quality data for the Shiraz plain to accomplish this purpose. The findings showed that the SFS-MLP approach was more accurate than the other methods with training and testing dataset values of R 2 = 0.9996 and 0.99923, RMSE = 0.04929 and 0.072, and MAE = 0.039357 and 0.048968, respectively. Additionally, the findings demonstrated that the SFS-MLP approach has a high capacity and accuracy for predicting and modeling groundwater quality. This study's findings also show that intelligence models and optimization algorithms may be used to mimic groundwater quality parameters effectively.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Data Availability
The data supporting this study's findings are available from the corresponding author upon reasonable request.
Adimalla N, Chen J, Qian H (2020) Spatial characteristics of heavy metal contamination and potential human health risk assessment of urban soils: a case study from an urban region of South India. Ecotoxicol Environ Saf 194:110406
Article Google Scholar
Ahmadi Dehrashid A, Dong H, Fatahizadeh M, Gholizadeh Touchaei H, Gör M, Moayedi H, Salari M, Thi QT (2024) A new procedure for optimizing neural network using stochastic algorithms in predicting and assessing landslide risk in East Azerbaijan. Stoch Environ Res Risk Assess. https://doi.org/10.1007/s00477-024-02690-7
Alfarrah N, Walraevens K (2018) Groundwater overexploitation and seawater intrusion in coastal areas of arid and semi-arid regions. Water 10(2):143
Al-Shurman M, Yoo SM, Park S (2004) Black hole attack in mobile ad hoc networks. Proceedings of the 42nd annual Southeast regional conference.
Badeenezhad A, Tabatabaee HR, Nikbakht H-A, Radfard M, Abbasnia A, Baghapour MA, Alhamd M (2020) Estimation of the groundwater quality index and investigation of the affecting factors their changes in Shiraz drinking groundwater. Iran Groundwater Sustain Develop 11:100435
Barbieri M, Ricolfi L, Vitale S, Muteto PV, Nigro A, Sappa G (2019) Assessment of groundwater quality in the buffer zone of limpopo national park, gaza province, southern Mozambique. Environ Sci Pollut Res 26:62–77
Cherkaoui B, Beni-hssane A, Erritali M (2020) Variable control chart for detecting black hole attack in vehicular ad-hoc networks. J Ambient Intell Humaniz Comput 11:5129–5138
Coulibaly P, Anctil F, Bobée B (1999) Prévision hydrologique par réseaux de neurones artificiels: état de l’art. Can J Civ Eng 26(3):293–304
Dai W (2021) Safety evaluation of traffic system with historical data based on Markov process and deep-reinforcement learning. J Comput Method Eng Appl 1(1):1–14
Google Scholar
Dai H, Ju J, Gui D, Zhu Y, Ye M, Cui J, Hu BX (2024a) A two-step Bayesian network-based process sensitivity analysis for complex nitrogen reactive transport modeling. J Hydrology. https://doi.org/10.1016/j.jhydrol.2024.130903
Dai H, Liu Y, Guadagnini A, Yuan S, Yang J, Ye M (2024b) Comparative assessment of two global sensitivity approaches considering model and parameter uncertainty. Water Resour Res 60(2):e2023WR0360976
Dai W (2022) Evaluation and improvement of carrying capacity of a traffic system. Innov Appl Eng Technol https://doi.org/10.58195/iaet.v1i1.001
Dai W (2023) Design of traffic improvement plan for line 1 Baijiahu station of Nanjing metro. Innov Appl Eng Technol https://doi.org/10.58195/iaet.v2i1.133
Deng H, Li W, Agrawal DP (2002) Routing security in wireless ad hoc networks. IEEE Commun Mag 40(10):70–75
El Bilali A, Taleb A (2020) Prediction of irrigation water quality parameters using machine learning models in a semi-arid environment. J Saudi Soc Agric Sci 19(7):439–451. https://doi.org/10.1016/j.jssas.2020.08.001
El Bilali A, Taleb A, Brouziyne Y (2021a) Groundwater quality forecasting using machine learning algorithms for irrigation purposes. Agric Water Manage 245:106625. https://doi.org/10.1016/j.agwat.2020.106625
El Bilali A, Taleb A, Nafii A, Alabjah B, Mazigh N (2021b) Prediction of sodium adsorption ratio and chloride concentration in a coastal aquifer under seawater intrusion using machine learning models. Environ Technol Innov 23:101641. https://doi.org/10.1016/j.eti.2021.101641
Fu Y, Zhou M, Guo X, Qi L (2019) Artificial-molecule-based chemical reaction optimization for flow shop scheduling problem with deteriorating and learning effects. Ieee Access 7:53429–53440
Haggerty R, Sun J, Yu H, Li Y (2023) Application of machine learning in groundwater quality modeling-A comprehensive review. Water Res 233:119745
Ibrahim H, Yaseen ZM, Scholz M, Ali M, Gad M, Elsayed S, Khadr M, Hussein H, Ibrahim HH, Eid MH (2023) Evaluation and prediction of groundwater quality for irrigation using an integrated water quality indices, machine learning models and GIS approaches: a representative case study. Water 15(4):694
Jha MK, Shekhar A, Jenifer MA (2020) Assessing groundwater quality for drinking water supply using hybrid fuzzy-GIS-based water quality index. Water Res 179:115867
Jia B, Zhou G (2023) (2023) Estimation of global karst carbon sink from 1950s to 2050s using response surface methodology. Geo-Spatial Inform Sci. https://doi.org/10.1080/10095020.2023.2165974
Joseph VR (2022) Optimal ratio for data splitting. Stat Anal Data Mining: ASA Data Sci J 15(4):531–538
Article MathSciNet Google Scholar
Kang Q, Feng S, Zhou M, Ammari AC, Sedraoui K (2017) Optimal load scheduling of plug-in hybrid electric vehicles via weight-aggregation multi-objective evolutionary algorithms. IEEE Trans Intell Transp Syst 18(9):2557–2568
Khan N, Malik A, Nehra K (2021) Groundwater hydro-geochemistry, quality, microbiology and human health risk assessment in semi-arid area of Rajasthan, India: a chemometric approach. Environ Monit Assess 193:1–36
Khashei-Siuki A, Kouchkzadeh M, Ghahraman B (2011) Predicting dryland wheat yield from meteorological data using expert system, Khorasan Province. Iran J Agric Sci Technol 13(4):627–640
Kong C, Li H, Zhang L, Zhu H, Liu T (2019) Link prediction on dynamic heterogeneous information networks. International Conference on Computational Data and Social Networks.
Kong C, Li H, Zhu H, Xiu Y, Liu J, Liu T (2019). Anonymized user linkage under differential privacy. Soft Computing in Data Science: 5th International Conference, SCDS 2019, Iizuka, Japan, August 28–29, 2019, Proceedings 5.
Kong C, Liu J, Li H, Liu Y, Zhu H, Liu T (2019) Drug abuse detection via broad learning. Web Information Systems and Applications: 16th International Conference, WISA 2019, Qingdao, China, September 20–22, 2019, Proceedings 16,
Kong C, Zhu H, Li H, Liu J, Wang Z, Qian Y (2019) Multi-agent negotiation in real-time bidding. 2019 IEEE International Conference on Consumer Electronics-Taiwan (ICCE-TW).
Kumar S, Bharti V, Singh K, Singh T (2010) Quality assessment of potable water in the town of Kolasib, Mizoram (India). Environ Earth Sci 61:115–121
Kumar R, Singh S, Kumar R, Sharma P (2022) Groundwater quality characterization for safe drinking water supply in sheikhpura district of Bihar, India: a geospatial approach. Front Water 4:848018
Li J, Pang Z, Liu Y, Hu S, Jiang W, Tian L, Yang G, Jiang Y, Jiao X, Tian J (2023) Changes in groundwater dynamics and geochemical evolution induced by drainage reorganization: evidence from 81Kr and 36Cl dating of geothermal water in the Weihe Basin of China. Earth Planet Sci Lett 623:118425
Ma H (2010) An analysis of the equilibrium of migration models for biogeography-based optimization. Inf Sci 180(18):3444–3464
MacArthur RH, Wilson EO (2001) The theory of island biogeography (Vol. 1). Princeton university press.
Masoudi R, Mousavi SR, Rahimabadi PD, Panahi M, Rahmani A (2023) Assessing data mining algorithms to predict the quality of groundwater resources for determining irrigation hazard. Environ Monit Assess 195(2):319
Meng X, Li J, Zhou M, Dai X, Dou J (2016) Population-based incremental learning algorithm for a serial colored traveling salesman problem. IEEE Trans Syst, Man, Cyber: Syst 48(2):277–288
Mirjalili S, Mirjalili SM, Hatamlou A (2016) Multi-verse optimizer: a nature-inspired algorithm for global optimization. Neural Comput Appl 27(2):495–513
Mishra A, Nadkarni K, Patcha A (2004) Intrusion detection in wireless ad hoc networks. IEEE Wirel Commun 11(1):48–60
Moayedi H, Dehrashid AA (2023) A new combined approach of neural-metaheuristic algorithms for predicting and appraisal of landslide susceptibility mapping. Environ Sci Pollut Res. https://doi.org/10.1007/s11356-023-28133-4
Moayedi H, Canatalay PJ, Ahmadi Dehrashid A, Cifci MA, Salari M, Le BN (2023a) Multilayer perceptron and their comparison with two nature-inspired hybrid techniques of biogeography-based optimization (BBO) and backtracking search algorithm (BSA) for assessment of landslide susceptibility. Land 12(1):242
Moayedi H, Salari M, Dehrashid AA, Le BN (2023b) Groundwater quality evaluation using hybrid model of the multi-layer perceptron combined with neural-evolutionary regression techniques: case study of Shiraz plain. Stoch Environ Res Risk Assess. https://doi.org/10.1007/s00477-023-02429-w
Mohammed MA, Kaya F, Mohamed A, Alarifi SS, Abdelrady A, Keshavarzi A, Szabó NP, Szűcs P (2023) Application of GIS-based machine learning algorithms for prediction of irrigational groundwater quality indices. Front Earth Sci 11:1274142
Naghibi SA, Khodaei B, Hashemi H (2022) An integrated InSAR-machine learning approach for ground deformation rate modeling in arid areas. J Hydrol 608:127627. https://doi.org/10.1016/j.jhydrol.2022.127627
Organization WH (2006) The Guidelines: a framework for safe drinking water. Guidelines for Drinking-water Quality. 3rd ed. Geneva; WHO, 22–36.
Qiu Y, Wang J (2024). A machine learning approach to credit card customer segmentation for economic stability. Proceedings of the 4th International Conference on Economic Management and Big Data Applications, ICEMBDA 2023, October 27–29, 2023, Tianjin, China.
Qiu Y (2019) Estimation of tail risk measures in finance: approaches to extreme value mixture modeling Johns Hopkins university.
Rácz A, Bajusz D, Héberger K (2021) Effect of dataset size and train/test split ratios in QSAR/QSPR multiclass classification. Molecules 26(4):1111
Raschka S, Mirjalili V (2017). Python machine learning: Machine learning and deep learning with python. Scikit-Learn, and TensorFlow. Second edition ed, 3.
Raschka S, Mirjalili V (2019). Python machine learning: Machine learning and deep learning with python, scikit-learn, and TensorFlow 2. Packt Publishing Ltd.
Salami E, Salari M, Ehteshami M, Bidokhti N, Ghadimi H (2016) Application of artificial neural networks and mathematical modeling for the prediction of water quality variables (case study: southwest of Iran). Desalin Water Treat 57(56):27073–27084
Salari M, Rakhshandehroo G, Ehetshami M (2017) Investigating the spatial variability of some important groundwater quality factors based on the geostatistical simulation (case study: Shiraz plain). Desalin Water Treat 65:163–174
Salari M, Shahid ES, Afzali SH, Ehteshami M, Conti GO, Derakhshan Z, Sheibani SN (2018) Quality assessment and artificial neural networks modeling for characterization of chemical and physical parameters of potable water. Food Chem Toxicol 118:212–219
Shafiee S, Lied LM, Burud I, Dieseth JA, Alsheikh M, Lillemo M (2021) Sequential forward selection and support vector regression in comparison to LASSO regression for spring wheat yield prediction based on UAV imagery. Comput Electron Agric 183:106036
Shahida ES, Salarib M, Rastegarc M, Nikbakht S, Sheibania ME (2021) Artificial neural network and mathematical approach for estimation of surface water quality parameters (case study: California, USA). Sat 100:2
Sharma, Y., Mukherjee, A., Srivastava, J., Mahato, M., & Singh, T. (2008). Prediction of various parameters of a river for assessment of water quality by an intelligent technique. Chemical Product and Process Modeling , 3 (1).
Simon D (2008) Biogeography-based optimization. IEEE Trans Evol Comput 12(6):702–713
Singh G, Rishi MS, Herojeet R, Kaur L, Sharma K (2020) Evaluation of groundwater quality and human health risks from fluoride and nitrate in semi-arid region of northern India. Environ Geochem Health 42:1833–1862
Singha S, Pasupuleti S, Singha SS, Singh R, Kumar S (2021) Prediction of groundwater quality using efficient machine learning technique. Chemosphere 276:130265
Song N, Qian L, Li X (2005) Wormhole attacks detection in wireless ad hoc networks: A statistical analysis approach. 19th IEEE international parallel and distributed processing symposium.
Sun B, Guan Y, Chen J, Pooch UW (2003) Detecting black-hole attack in mobile ad hoc networks.
Tian G, Hao N, Zhou M, Pedrycz W, Zhang C, Ma F, Li Z (2019) Fuzzy grey choquet integral for evaluation of multicriteria decision making problems with interactive and qualitative indices. IEEE Trans Syst, Man, Cyber: Syst 51(3):1855–1868
Tung TM, Yaseen ZM (2020) A survey on river water quality modelling using artificial intelligence models: 2000–2020. J Hydrol 585:124670
Verma A, Singh T (2013) Prediction of water quality from simple field parameters. Environ Earth Sci 69:821–829
Wang XP, Huang YS (2008) Predicting risks of capital flow using artificial neural network and levenberg marquardt algorithm. 2008 International Conference on Machine Learning and Cybernetics.
Wenjun D, Fatahizadeh M, Touchaei HG, Moayedi H, Foong LK (2023) Application of six neural network-based solutions on bearing capacity of shallow footing on double-layer soils. Steel Compos Struct 49(2):231–244
Xing K, Han L, Zhou M, Wang F (2011) Deadlock-free genetic scheduling algorithm for automated manufacturing systems based on deadlock control policy. IEEE Trans Syst, Man, Cyber, Part B Cyber 42(3):603–615
Zhang K, Li Y, Yu Z, Yang T, Xu J, Chao L, Ni J, Wang L, Gao Y, Hu Y (2022) Xin’anjiang nested experimental watershed (XAJ-NEW) for understanding multiscale water cycle: scientific objectives and experimental design. Engineering 18:207–217
Zhao J, Liu S, Zhou M, Guo X, Qi L (2018) Modified cuckoo search algorithm to solve economic power dispatch optimization problems. IEEE/CAA J Auto Sinica 5(4):794–806
Zhao Z, Liu S, Zhou M, Guo X, Qi L (2019) Decomposition method for new single-machine scheduling problems from steel production systems. IEEE Trans Autom Sci Eng 17(3):1376–1387
Zhao Y, Dai W, Wang Z, Ragab AE (2024) Application of computer simulation to model transient vibration responses of GPLs reinforced doubly curved concrete panel under instantaneous heating. Mater Today Commun 38:107949
Zheng Y-J, Ling H-F, Xue J-Y (2014) Disaster rescue task scheduling: An evolutionary multiobjective optimization approach. IEEE Trans Emerg Top Comput 6(2):288–300
Zhou G, Wang Z, Li Q (2022) Spatial negative co-location pattern directional mining algorithm with join-based prevalence. Remote Sens 14(9):2103
Zhou G, Su S, Xu J, Tian Z, Cao Q (2023) Bathymetry retrieval from spaceborne multispectral subsurface reflectance. IEEE J Select Topics Appl Earth Observ Remote Sens 16:2547–2558
Zhu H, Wang B (2021). Negative siamese network for classifying semantically similar sentences. 2021 International Conference on Asian Language Processing (IALP).
Download references
Acknowledgements
We would like to thank all the participants, without whom this study would be impossible.
This research received no external funding.
Author information
Authors and affiliations.
Institute of Research and Development, Duy Tan University, Da Nang, 550000, Vietnam
Hossein Moayedi
School of Engineering and Technology, Duy Tan University, Da Nang, Vietnam
Department of Civil Engineering, Sirjan University of Technology, Sirjan, Iran
Marjan Salari
School of Engineering & Technology, Duy Tan University, Da Nang, Vietnam
T. N. G. Nguyen
Department of Climatology Faculty of Natural Resources, , University of Kurdistan, Sanandaj, Iran
Atefeh Ahmadi Dehrashid
You can also search for this author in PubMed Google Scholar
Contributions
Hossein Moayedi; Conceptualization, methodology, writing-original draft preparation; Marjan Salari: Investigation, visualization, writing-original draft preparation, TNG Nguyen; Visualization, Formal analysis, Atefeh Ahmadi Dehrashid; Writing-review and editing. All authors have read and agreed to the published version of the manuscript.
Corresponding author
Correspondence to Marjan Salari .
Ethics declarations
Conflict of interest.
The authors declare no conflict of interest.
Informed Consent
Informed consent was obtained from all subjects involved in the study.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Moayedi, H., Salari, M., Nguyen, T.N.G. et al. Four Optimization Meta-heuristic Approaches in Evaluating Groundwater Quality (Case study: Shiraz Plain). Iran J Sci Technol Trans Civ Eng (2024). https://doi.org/10.1007/s40996-024-01501-x
Download citation
Received : 07 December 2023
Accepted : 31 May 2024
Published : 20 June 2024
DOI : https://doi.org/10.1007/s40996-024-01501-x
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Groundwater
- Artificial neural network
- Sodium adsorption ratio
- Swarm-based approach
- Find a journal
- Publish with us
- Track your research
This paper is in the following e-collection/theme issue:
Published on 19.6.2024 in Vol 12 (2024)
Effect of Implementing an Informatization Case Management Model on the Management of Chronic Respiratory Diseases in a General Hospital: Retrospective Controlled Study
Authors of this article:
- Yi-Zhen Xiao 1 , MBBS ;
- Xiao-Jia Chen 1 , MBBS ;
- Xiao-Ling Sun 1 , MBBS ;
- Huan Chen 1 , MM ;
- Yu-Xia Luo 1 , MBBS ;
- Yuan Chen 1 , MBBS ;
- Ye-Mei Liang 2 , MM
1 Department of Pulmonary and Critical Care Medicine, Yulin First People’s Hospital, , Yulin, , China
2 Department of Nursing, Yulin First People’s Hospital, , Yulin, , China
Corresponding Author:
Ye-Mei Liang, MM
Background: The use of chronic disease information systems in hospitals and communities plays a significant role in disease prevention, control, and monitoring. However, there are several limitations to these systems, including that the platforms are generally isolated, the patient health information and medical resources are not effectively integrated, and the “Internet Plus Healthcare” technology model is not implemented throughout the patient consultation process.
Objective: The aim of this study was to evaluate the efficiency of the application of a hospital case management information system in a general hospital in the context of chronic respiratory diseases as a model case.
Methods: A chronic disease management information system was developed for use in general hospitals based on internet technology, a chronic disease case management model, and an overall quality management model. Using this system, the case managers provided sophisticated inpatient, outpatient, and home medical services for patients with chronic respiratory diseases. Chronic respiratory disease case management quality indicators (number of managed cases, number of patients accepting routine follow-up services, follow-up visit rate, pulmonary function test rate, admission rate for acute exacerbations, chronic respiratory diseases knowledge awareness rate, and patient satisfaction) were evaluated before (2019‐2020) and after (2021‐2022) implementation of the chronic disease management information system.
Results: Before implementation of the chronic disease management information system, 1808 cases were managed in the general hospital, and an average of 603 (SD 137) people were provided with routine follow-up services. After use of the information system, 5868 cases were managed and 2056 (SD 211) patients were routinely followed-up, representing a significant increase of 3.2 and 3.4 times the respective values before use ( U =342.779; P <.001). With respect to the quality of case management, compared to the indicators measured before use, the achievement rate of follow-up examination increased by 50.2%, the achievement rate of the pulmonary function test increased by 26.2%, the awareness rate of chronic respiratory disease knowledge increased by 20.1%, the retention rate increased by 16.3%, and the patient satisfaction rate increased by 9.6% (all P <.001), while the admission rate of acute exacerbation decreased by 42.4% (P <.001) after use of the chronic disease management information system.
Conclusions: Use of a chronic disease management information system improves the quality of chronic respiratory disease case management and reduces the admission rate of patients owing to acute exacerbations of their diseases.
Introduction
Chronic obstructive pulmonary disease (COPD) and asthma are examples of common chronic respiratory diseases. The prevalence of COPD among people 40 years and older in China is estimated to be 13.7%, with the total number of patients reaching nearly 100 million. The lengthy disease cycle, recurrent acute exacerbations, and low control rate were found to have a significant impact on the prognosis and quality of life of middle-aged and older patients with COPD [ 1 , 2 ]. Therefore, to decrease the morbidity and disability rates and enhance the quality of life of all patients with chronic respiratory diseases, it is crucial to investigate effective prevention and treatment methods and establish a life cycle management model for chronic respiratory diseases.
Since the development of information technology, the internet and medical technology have been applied to the management of chronic diseases [ 3 ]. The chronic disease information systems adopted in hospitals and communities, along with mobile medical apps, can enhance the self-management capabilities of patients and play a significant role in disease prevention, control, and monitoring [ 4 - 9 ]. However, the existing platforms are generally isolated, the patient health information and medical resources are not effectively integrated, and the Internet Plus Healthcare technology model is not implemented throughout the patient consultation process [ 3 , 9 ].
Yulin First People’s Hospital developed a chronic disease management information system based on the hospital information system (HIS) to fully and effectively utilize the medical resources in hospitals and to better support and adapt the system to the needs of patients with chronic diseases. In this study, we evaluated the impact of the use of this system on the efficacy of case management for patients with chronic respiratory diseases.
Chronic Respiratory Diseases Case Management Model Prior to Implementation of the Chronic Disease Management Information System
Yulin First People’s Hospital is a public grade-3 general hospital with 2460 open beds, a specialty clinic in the Department of Pulmonary and Critical Care Medicine, and 180 beds in the Inpatient Department. Chronic respiratory diseases case management was initiated in 2019, which did not involve the use of an information system and was implemented by a chronic respiratory diseases case management team led by two nurses qualified as case managers, one chief physician, two supervisor nurses, and one technician. Under this system, patients with COPD, bronchial asthma, bronchiectasis, pulmonary thromboembolism, lung cancer, and lung nodules were managed using the traditional inpatient-outpatient-home chronic respiratory diseases case management model, including 1024 cases managed from 2019 to 2020. Except for medical prescriptions and electronic medical records, the patient case management information such as the basic information form, follow-up form, patient enrollment form, inpatient follow-up register, patient medication and inhalation device use records, smoking cessation and vaccination records, and pulmonary rehabilitation and health education records was managed using Microsoft Excel forms that were regularly printed for filing.
Establishment of a Management Information System for Chronic Diseases
The information carrier forming the basis of the management information system is constituted by the model of internet technology, chronic disease case management models, and overall quality management. The key technology is to establish a scientific, refined, and feasible follow-up pathway according to the methods and procedures of chronic disease case management based on the guidelines for the diagnosis and treatment of single chronic diseases. The closed-loop management of the clinical pathway was conducted in accordance with the Deming cycle (plan-do-check-act), and dynamic monitoring of single-disease health-sensitive and quality-sensitive indicators was carried out. The successfully developed system was installed on the hospital server to connect personal terminals (medical terminals and customer apps) to the existing HIS, which includes electronic medical records and medical advice.
Using the single-disease path assessment or plan scale as a framework, the system can automatically collect and integrate the majority of the medical information of patients with chronic respiratory diseases and provide these patients with inpatient, outpatient, and home intelligent medical services. Patients with chronic diseases who enroll in use of the system can use the app to schedule appointments for medical guidance, payment, and result queries; receive health guidance information; perform self-health assessments; write a treatment diary; and obtain medical communication materials.
The medical terminal consists of five functional modules: user entry, data statistics and query, quality control, knowledge base, and module management. As the core of the system, the user entry module can manage case information in seven steps: enrollment, assessment, planning, implementation, feedback, evaluation, and settlement [ 10 - 14 ]. Each step has a corresponding assessment record scale as well as the health-sensitive and quality-sensitive indicators. The structure of the HIS-based chronic disease management information system is shown in Figure 1 .

Implementation of the Chronic Disease Information Management System
Using the chronic disease management information system, two full-time case managers oversaw the case management of 2747 patients diagnosed with six diseases among chronic respiratory diseases between 2021 and 2022. The operation process was broken down into enrollment, assessment, planning, implementation, evaluation, feedback, and settlement stages.
Case managers entered the system through the medical app, selected a disease and an enrolled patient from the list of patients (the system automatically captures the patient’s name and ID number according to the International Classification of Diseases [ ICD ] code) in accordance with the chronic respiratory diseases diagnostic criteria to sign the enrollment contract and determine the relationship between the personal information and data [ 15 - 19 ].
The system can be seamlessly integrated with multiple workstations on the HIS to automatically capture the basic information, electronic medical records, medical advice, and inspection materials, and can generate questionnaires or assessment scales for patients with chronic respiratory diseases such as the COPD Assessment Test, Asthma Control Test, modified Medical Research Council scale, form for lung function test results, inhalation device technique evaluation form, 6-minute walk test record, rehabilitation assessment form, health promotion form, and nutritional assessment form. The above materials can be added or removed based on the requirements for individual patients.
The case managers drafted the follow-up plan based on the patient assessment criteria and included the patients on the 1-, 3-, 6-, and 12-month follow-up lists. If the patient satisfied the self-management and indicator control requirements after follow-up, they could be settled and included in the annual follow-up cohort. Case managers can set up follow-up warning and treatment, involving the return visit plan, health education, follow-up content, pathway, and time, and notify the patients and nurses on day 7 and at months 1, 3, 6, and 12 after discharge. The nurses should promptly deal with patients who miss their scheduled follow-up visit.
Implementation
During the inpatient or outpatient care, supervising physicians, nurses, and patients collaborated with each other to implement the treatment. Case managers monitored the patients, evaluated them, documented the results, interpreted various test indicators, and provided health guidance. The chronic disease management information system acquired the corresponding data for chronic disease–sensitive indicators from outpatient and inpatient orders and medical records automatically. The chronic respiratory diseases management team reviewed the patients’ conditions and the dynamics of chronic disease–sensitive indicators to make accurate decisions based on the current situation. The outpatient physicians obtained the single-disease package advice and personalized prescriptions to modify the diagnosis and treatment scheme.
Case managers highlighted evaluation and health education. First, they assessed and examined the content of the previous education and recorded and analyzed the patients’ conditions, medication, diet, nutrition, rehabilitation exercises, and self-management. Second, they prepared the personalized health education plan, return visit plan, and rehabilitation plan, and used standardized courseware, educational videos, and health prescriptions to provide the patients with one-on-one health guidance. Finally, they sent the management tasks and educational contents to the phones of the patients for consolidating the learning in the hospital, as an outpatient, and at home.
Patients can access their biochemical, physical, and chemical data as well as chronic disease–sensitive indicators in the hospital, as an outpatient, and at home for self-health management. Case managers can also perform online assessment, appraisal, and guidance via telephone, WeChat, and the chronic disease information system and record the data. Client mobile terminals can receive SMS text message alerts and the main interface of the chronic disease information system would display reminders of follow-up and return visits within ±7 days.
If a patient was out of contact for 3 months, died, or refused to accept the treatment, case managers could settle the case.
Evaluation of the Effect of Implementing the Chronic Disease Management Information System
Evaluation method.
In accordance with case quality management indicators [ 20 ], two full-time case managers collected and evaluated data in the process of the follow-up procedure. To reduce the potential for evaluation bias, the case managers consistently communicated and learned to standardize the evaluation method. The cases were divided based on different chronic respiratory diseases case management models (ie, before and after use of the chronic disease information system). The following case management quality indicators were evaluated under the noninformation system management model (2019‐2020) and under the chronic disease management information system model (2021‐2022): number of managed cases, number of patients accepting routine follow-up services, follow-up visit rate, pulmonary function test rate, admission rate for acute exacerbations, chronic respiratory diseases knowledge awareness rate, and patient satisfaction. Excel sheets were used to acquire data prior to incorporation of the chronic disease management information system into the new information system.
Evaluation Indicators
The annual number of cases was calculated as the sum of the number of newly enrolled patients and the number of initially enrolled patients. The number of cases was calculated as the sum of the number of cases in different years. The number of routine follow-up visits represents the number of patients who completed the treatment plan. The follow-up visit rate was calculated as the number of completed follow-up visits in the year divided by the number of planned follow-up visits in the same year. The pulmonary function test rate was calculated as the number of pulmonary function tests completed for patients scheduled for follow-up during the year divided by the number of pulmonary function tests for patients scheduled for follow-up during the year. The admission rate for acute exacerbations was calculated as the number of recorded patients admitted to the hospital due to acute exacerbations divided by the total number of patients recorded. The chronic respiratory diseases knowledge awareness rate was determined by the number of people having sufficient knowledge divided by the total number of people tested. This knowledge indicator was based on the self-prepared chronic respiratory diseases knowledge test scale, which consists of 10 items determined using the Delphi method (following expert consultation) through review of the literature, including common symptoms, disease hazards, treatment medication, diet, living habits, exercise, negative habits affecting the disease, regular review items, effective methods for cough and sputum removal, appointments, and follow-ups. The content of the questionnaire was refined by disease type, and the reviewers included 11 personnel with the title of Deputy Chief Nurse or above in the Internal Medicine Department of the hospital. The expert authority coefficients were 0.85 and 0.87 and the coordination coefficients were 0.50 and 0.67 for the two rounds of review, respectively; the χ 2 test showed a statistically significant value of P =.01. Patient satisfaction was assessed with a self-made questionnaire that showed good internal reliability (Cronbach α=0.78) and content validity (0.86). The questionnaire items included the reminder of return visits, practicability of health education content, and service attitude of medical staff; the full-time case managers surveyed the patients (or their caregivers) at the time of return visits after the third quarter of each year. Satisfaction items were rated using a 5-point Likert scale with a score of 1‐5, and a mean ≥4 points for an individual indicated satisfaction. Patient satisfaction was then calculated as the number of satisfied patients divided by the total number of managed patients.
Statistical Analysis
SPSS 16.0 software was used for data analysis. The Mann-Whitney U test was performed to compare continuous variables between groups and the χ 2 test was performed to compare categorical variables between groups. P <.05 indicated that the difference was statistically significant.
Ethical Considerations
The study was conducted in accordance with the principles of the Declaration of Helsinki. This study received approval from the Ethics Committee of Yulin First People’s Hospital (approval number: YLSY-IRB-RP-2024005). The study did not interfere with routine diagnosis and treatment, did not affect patients’ medical rights, and did not pose any additional risks to patients. Therefore, after discussion with the Ethics Committee of Yulin First People’s Hospital, it was decided to waive the requirement for informed consent from patients. Patients’ personal privacy and data confidentiality have been upheld throughout the study.
Characteristics of Patient Populations Before and After Implementation of the Information System
There was no significant difference in age and gender distributions in the patient populations that received care before and after implementation of the chronic disease management information system ( Table 1 ).
| Characteristic | Before use (n=1024) | After use (n=2747) | ² value | value | ||
| 1.046 | 1 | .31 | ||||
| Men | 677 (66.1) | 1767 (64.3) | ||||
| Women | 347 (33.9) | 980 (35.7) | ||||
| 0.997 | 3 | .80 | ||||
| <30 | 26 (2.6) | 73 (2.7) | ||||
| 30-59 | 370 (36.1) | 1013 (36.9) | ||||
| 60-79 | 510 (49.8) | 118 (11.5) | ||||
| >80 | 1322 (48.1) | 339 (12.3) | ||||
Comparison of Workload Before and After Implementation of the Information Management System
Before use of the system, 1808 cases were managed, with a mean of 603 (SD 137) cases having routine follow-up visits. After use of the system, 5868 cases were managed, with a mean of 2056 (SD 211) routine follow-up visits. Therefore, the number of managed cases and the number of follow-up visits significantly increased by 3.2 and 3.4 times, respectively, after use of the system (U =342.779; P< .001).
Comparison of Quality Indicators of Managed Cases Before and After Implementation of the Information System
The quality indicators in the two groups are summarized in Table 2 . Compared with the corresponding indicators before use of the system, the follow-up visit rate increased by 50.2%, the pulmonary function test rate increased by 26.2%, the chronic respiratory diseases knowledge awareness rate increased by 20.1%, the retention rate increased by 16.3%, and the patient satisfaction increased by 9.6%; moreover, the admission rate for acute exacerbations decreased by 42.4%.
| Quality indicators | Before use (n=1024), n (%) | After use (n=2747), n (%) | ² value ( =1) | value |
| Subsequent visit rate | 209 (20.4) | 1939 (70.6) | 7.660 | <.001 |
| Lung function test achievement rate | 190 (18.6) | 1231 (44.8) | 2.190 | <.001 |
| CRD knowledge awareness rate | 443 (43.3) | 1742 (63.4) | 1.243 | <.001 |
| Retention rate | 787 (76.9) | 2560 (93.2) | 1.995 | <.001 |
| Acute exacerbation admission rate | 663 (64.7) | 613 (22.3) | 5.999 | <.001 |
| Patient satisfaction | 862 (84.2) | 2577 (93.8) | 86.190 | .01 |
a CRD: chronic respiratory disease.
Principal Findings
The main purpose of this study was to build a chronic disease management information system and apply it to the case management of chronic respiratory diseases. Our evaluation showed that the chronic disease management information system not only improves the efficiency and quality of case management but also has a benefit for maintaining the stability of the condition for patients with respiratory diseases, reduces the number of acute disease exacerbations, increases the rate of outpatient return, and improves patients’ adherence with disease self-management. Thus, a chronic disease management information system is worth popularizing and applying widely.
Value of the HIS-Based Chronic Disease Management Information System
Chronic diseases constitute a significant public health issue in China. Public hospitals play important roles in the health service system, particularly large-scale public hospitals with the most advanced technologies, equipment, and enormous medical human resources, which can greatly aid in the diagnosis and treatment of diseases and also serve as important hubs for the graded treatment of chronic diseases. Moreover, a significant number of patients with chronic diseases visit large hospitals, making them important sources of big data on chronic diseases [ 21 ]. Adoption of an HIS-based chronic disease management information system can make full use of and exert the advantages of large-scale public hospitals in terms of labor, technology, and equipment in the diagnosis, treatment, and prevention of chronic diseases; enhance the cohesiveness of the case management team in chronic disease management; and achieve prehospital, in-hospital, and posthospital continuity of care for patients with chronic diseases. Overall, use of a chronic disease management information system can enhance the quality and efficiency of chronic disease management and lay a good foundation for teaching and research on chronic diseases.
Improved Efficiency of Case Management
China was relatively late in applying case management practices, and chronic disease management has traditionally been primarily conducted offline [ 14 , 20 ] or supplemented by management with apps and WeChat [ 7 , 8 ]. Traditional case management methods require case managers to manually search, record, store, query, count, and analyze information. This manual process necessitates substantial time and makes it challenging to realize a comprehensive, systematic, and dynamic understanding of patient information, resulting in a small number of managed cases and follow-up visits. With the application of information technology, use of an HIS-based chronic disease monitoring and case management system can automatically extract and integrate patient information, thereby increasing the efficiency of chronic disease management and reduce costs [ 4 , 22 ]. In this study, two case managers played leading roles both before and after implementation of the information system; however, compared with the situation before the use of the system, the numbers of both managed cases and of follow-up visits increased, reaching 3.2 and 3.4 times the preimplementation values, respectively. The information system can automatically obtain a patient’s name and ID number based on the ICD code, which can expand the range of enrollment screening and appoint the register of patients as planned. In addition, the information system can automatically obtain outpatient, inpatient, and home medical information for the postillness life cycle management of patients. Moreover, the intuitive, clear, and dynamic indicator charts on the system can save a significant amount of time for diagnosis and treatment by medical staff, while the paperless office and online data-sharing functions can essentially solve the problem of managing files by case managers to ultimately enhance efficiency.
Improved Quality of Case Management
According to evidence-based medicine, the seven steps of case management represent the optimal clinical pathway [ 10 - 14 , 22 ]. In this study, the concept of an Internet-Plus medical service was introduced; that is, the chronic disease management information system was established based on the HIS data and case management model [ 22 ] and the function of a mobile medical terminal app was incorporated in the system [ 6 , 7 ]. Compared with the noninformation system case management model, this system has several advantages. First, owing to the swift management mode, it can overcome the limitations of time and space [ 4 - 8 ]. Second, multichannel health education and communication can enhance patients’ knowledge and skills, as well as their compliance with self-management, based on diversified forms of image data such as graphics and audio [ 6 , 22 ]. Third, the use of intelligent management can remind doctors and patients to complete management work and follow-up visits as planned, and to perform intelligent pushes of patient outcome indicators to improve confidence in the treatment [ 22 ]. Fourth, this system enables information sharing and big data analysis, as well as multidisciplinary diagnosis and treatment based on the matching of doctor-patient responsibility management, which can be more conducive to the precise health management of patients.
Compared with the traditional case management model, information-based case management significantly increased the follow-up visit rate, lung function test rate, chronic respiratory diseases knowledge awareness rate of patients, patient satisfaction rate, and retention rate. Among these indicators, the follow-up visit rate and lung function test rate represent aspects related to the patients’ own management of their condition [ 1 ]. The results of this study are consistent with previous findings related to information-based management of chronic diseases in China, demonstrating that such a management system was more conducive to planned, systematic, and personalized education and follow-up by the case management team, thereby promoting the virtuous cycle of compliance with self-management and reducing the number of acute exacerbations among patients with chronic respiratory diseases, ultimately enhancing the precision of medical resource allocation and hospital management [ 22 , 23 ].
Helping Patients With COPD Maintain Stability of Their Condition
The admission rate for acute exacerbations serves as a common indicator of the quality of the treatment of chronic respiratory diseases [ 23 ]. The deployment of a clinical pathway–based hospital case management information system significantly reduced the admission rate for acute exacerbations and enhanced the quality of treatment for chronic respiratory diseases, indicating its high clinical significance. There are several reasons for these observed benefits. First, home care and self-management are essential in the management of chronic respiratory diseases. The information-based case management model improved the patients’ knowledge and skills along with their compliance with self-management. Consequently, the standardized self-management process helped to reduce the number of acute exacerbations of chronic respiratory diseases and thus lowered the admission rate. Second, the information-based case management model increased the regular return rate, which allowed the medical staff to identify the potential risk factors for acute exacerbations in a timely manner, deal with them when they occur, and prepare personalized treatment plans and precise health management schemes. This consequently enabled adjustment of treatment schemes in real time, reduced the number of admissions due to acute exacerbations, and lowered the readmission rate. For hospitals interested in implementing a similar model, we suggest first conducting a detailed review of the current situation prior to making adequate changes based on the relevant disease and patient populations.
Consequently, the HIS-based case information management model could improve efficiency, enhance the quality of case management, and aid in stabilizing the conditions of patients with chronic respiratory diseases. In contrast to the hospital case management information system reported by Yuan et al [ 22 ], the system described in this study includes a personal terminal app. Previous studies confirmed that a stand-alone mobile health app could improve patient compliance and disease control [ 6 - 8 ]; thus, whether this system can be used to manage specialized disease cohorts for patients with chronic diseases remains to be determined. In this study, the effect on the retention rate of patients was confirmed; however, the overall operational indicators for the diagnosis and treatment of chronic diseases should be further determined.
With the advancement of information technology, the internet and medical technology have been applied to the management of chronic diseases. As an information-based platform for the case management of patients with chronic respiratory diseases, a newly developed chronic disease management information system was introduced in this study. This system is capable of designing the follow-up time registration, follow-up content, approaches, methods, quality control, and feedback process for a single chronic respiratory disease via the single-disease clinical pathway following the case management process (enrollment, assessment, planning, implementation, feedback, and evaluation). Use of this system can encourage patients with chronic respiratory diseases to adhere to regular follow-up and form an outpatient-inpatient-home chronic disease management strategy. This can help in reducing the admission rate for acute exacerbations, increase the return visit rate, and improve the correctness and compliance of home self-management of patients with chronic respiratory diseases. Owing to these benefits, wide adoption of such information systems for the management of chronic diseases can offer substantial economic and social value.
Acknowledgments
We are particularly grateful to all the people who provided help with our article. This study was supported by a grant from Yulin City Science and Technology Planning Project (20202002).
Data Availability
The data sets used and/or analyzed during the current study are available from the corresponding author on reasonable request.
Authors' Contributions
YML, YZX, XLS, and YXL designed this study. XLS and XJC wrote the draft of the paper. YML, YZX, and YC contributed final revisions to the article. XJC, HC, and YC collected the data. XJC, YML, YXL, and HC performed the statistical analysis. YML received funding support. All authors read and approved the final draft of the article.
Conflicts of Interest
None declared.
- Anaev EK. Eosinophilic chronic obstructive pulmonary disease: a review. Ter Arkh. Oct 11, 2023;95(8):696-700. [ CrossRef ] [ Medline ]
- Shakeel I, Ashraf A, Afzal M, et al. The molecular blueprint for chronic obstructive pulmonary disease (COPD): a new paradigm for diagnosis and therapeutics. Oxid Med Cell Longev. Dec 2023;2023:2297559. [ CrossRef ] [ Medline ]
- Morimoto Y, Takahashi T, Sawa R, et al. Web portals for patients with chronic diseases: scoping review of the functional features and theoretical frameworks of telerehabilitation platforms. J Med Internet Res. Jan 27, 2022;24(1):e27759. [ CrossRef ] [ Medline ]
- Donner CF, ZuWallack R, Nici L. The role of telemedicine in extending and enhancing medical management of the patient with chronic obstructive pulmonary disease. Medicina. Jul 18, 2021;57(7):726. [ CrossRef ] [ Medline ]
- Wu F, Burt J, Chowdhury T, et al. Specialty COPD care during COVID-19: patient and clinician perspectives on remote delivery. BMJ Open Respir Res. Jan 2021;8(1):e000817. [ CrossRef ] [ Medline ]
- Hallensleben C, van Luenen S, Rolink E, Ossebaard HC, Chavannes NH. eHealth for people with COPD in the Netherlands: a scoping review. Int J Chron Obstruct Pulmon Dis. Jul 2019;14:1681-1690. [ CrossRef ] [ Medline ]
- Gokalp H, de Folter J, Verma V, Fursse J, Jones R, Clarke M. Integrated telehealth and telecare for monitoring frail elderly with chronic disease. Telemed J E Health. Dec 2018;24(12):940-957. [ CrossRef ] [ Medline ]
- McCabe C, McCann M, Brady AM. Computer and mobile technology interventions for self-management in chronic obstructive pulmonary disease. Cochrane Database Syst Rev. May 23, 2017;5(5):CD011425. [ CrossRef ] [ Medline ]
- Briggs AM, Persaud JG, Deverell ML, et al. Integrated prevention and management of non-communicable diseases, including musculoskeletal health: a systematic policy analysis among OECD countries. BMJ Glob Health. 2019;4(5):e001806. [ CrossRef ] [ Medline ]
- Franek J. Home telehealth for patients with chronic obstructive pulmonary disease (COPD): an evidence-based analysis. Ont Health Technol Assess Ser. 2012;12(11):1-58. [ Medline ]
- Shah A, Hussain-Shamsy N, Strudwick G, Sockalingam S, Nolan RP, Seto E. Digital health interventions for depression and anxiety among people with chronic conditions: scoping review. J Med Internet Res. Sep 26, 2022;24(9):e38030. [ CrossRef ] [ Medline ]
- Sugiharto F, Haroen H, Alya FP, et al. Health educational methods for improving self-efficacy among patients with coronary heart disease: a scoping review. J Multidiscip Healthc. Feb 2024;17:779-792. [ CrossRef ] [ Medline ]
- Metzendorf MI, Wieland LS, Richter B. Mobile health (m-health) smartphone interventions for adolescents and adults with overweight or obesity. Cochrane Database Syst Rev. Feb 20, 2024;2(2):CD013591. [ CrossRef ] [ Medline ]
- Reig-Garcia G, Suñer-Soler R, Mantas-Jiménez S, et al. Assessing nurses' satisfaction with continuity of care and the case management model as an indicator of quality of care in Spain. Int J Environ Res Public Health. Jun 19, 2021;18(12):6609. [ CrossRef ] [ Medline ]
- Aggelidis X, Kritikou M, Makris M, et al. Tele-monitoring applications in respiratory allergy. J Clin Med. Feb 4, 2024;13(3):898. [ CrossRef ] [ Medline ]
- Seid A, Fufa DD, Bitew ZW. The use of internet-based smartphone apps consistently improved consumers' healthy eating behaviors: a systematic review of randomized controlled trials. Front Digit Health. 2024;6:1282570. [ CrossRef ] [ Medline ]
- Verma L, Turk T, Dennett L, Dytoc M. Teledermatology in atopic dermatitis: a systematic review. J Cutan Med Surg. 2024;28(2):153-157. [ CrossRef ] [ Medline ]
- Tański W, Stapkiewicz A, Szalonka A, Głuszczyk-Ferenc B, Tomasiewicz B, Jankowska-Polańska B. The framework of the pilot project for testing a telemedicine model in the field of chronic diseases - health challenges and justification of the project implementation. Pol Merkur Lekarski. 2023;51(6):674-681. [ CrossRef ] [ Medline ]
- Popp Z, Low S, Igwe A, et al. Shifting from active to passive monitoring of Alzheimer disease: the state of the research. J Am Heart Assoc. Jan 16, 2024;13(2):e031247. [ CrossRef ] [ Medline ]
- Sagare N, Bankar NJ, Shahu S, Bandre GR. Transforming healthcare: the revolutionary benefits of cashless healthcare services. Cureus. Dec 2023;15(12):e50971. [ CrossRef ] [ Medline ]
- Noncommunicable Diseases, Rehabilitation and Disability (NCD), Surveillance, Monitoring and Reporting (SMR) WHO Team. Noncommunicable diseases progress monitor. World Health Organization; 2017. URL: https://www.who.int/publications/i/item/9789241513029 [Accessed 2024-05-09]
- Yuan W, Zhu T, Wang Y, et al. Research on development and application of case management information system in general hospital. Nurs Res. 2022;36(12):2251-2253.
- 2020 GOLD report. Global strategy for the diagnosis, management and prevention of chronic obstructive pulmonary disease. Global Initiative for Chronic Obstructive Lung Disease; 2020. URL: https://goldcopd.org/gold-reports/ [Accessed 2024-05-09]
Abbreviations
| chronic obstructive pulmonary disease |
| hospital information system |
| : |
Edited by Christian Lovis; submitted 15.06.23; peer-reviewed by Kuang-Ming Kuo; final revised version received 14.04.24; accepted 17.04.24; published 19.06.24.
© Yi-Zhen Xiao, Xiao-Jia Chen, Xiao-Ling Sun, Huan Chen, Yu-Xia Luo, Yuan Chen, Ye-Mei Liang. Originally published in JMIR Medical Informatics (https://medinform.jmir.org), 19.6.2024.
This is an open-access article distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/4.0/ ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work, first published in JMIR Medical Informatics, is properly cited. The complete bibliographic information, a link to the original publication on https://medinform.jmir.org/ , as well as this copyright and license information must be included.
Information
- Author Services
Initiatives
You are accessing a machine-readable page. In order to be human-readable, please install an RSS reader.
All articles published by MDPI are made immediately available worldwide under an open access license. No special permission is required to reuse all or part of the article published by MDPI, including figures and tables. For articles published under an open access Creative Common CC BY license, any part of the article may be reused without permission provided that the original article is clearly cited. For more information, please refer to https://www.mdpi.com/openaccess .
Feature papers represent the most advanced research with significant potential for high impact in the field. A Feature Paper should be a substantial original Article that involves several techniques or approaches, provides an outlook for future research directions and describes possible research applications.
Feature papers are submitted upon individual invitation or recommendation by the scientific editors and must receive positive feedback from the reviewers.
Editor’s Choice articles are based on recommendations by the scientific editors of MDPI journals from around the world. Editors select a small number of articles recently published in the journal that they believe will be particularly interesting to readers, or important in the respective research area. The aim is to provide a snapshot of some of the most exciting work published in the various research areas of the journal.
Original Submission Date Received: .
- Active Journals
- Find a Journal
- Proceedings Series
- For Authors
- For Reviewers
- For Editors
- For Librarians
- For Publishers
- For Societies
- For Conference Organizers
- Open Access Policy
- Institutional Open Access Program
- Special Issues Guidelines
- Editorial Process
- Research and Publication Ethics
- Article Processing Charges
- Testimonials
- Preprints.org
- SciProfiles
- Encyclopedia
Article Menu

- Subscribe SciFeed
- Recommended Articles
- Google Scholar
- on Google Scholar
- Table of Contents
Find support for a specific problem in the support section of our website.
Please let us know what you think of our products and services.
Visit our dedicated information section to learn more about MDPI.
JSmol Viewer
A proposed methodology for the dynamic standard evaluation of water quality in estuaries: a case study of the pearl river estuary, 1. introduction, 2. method construction, 2.1. classification of seawater quality in the seawater quality standards, 2.2. surface water function and standard classification in surface water environmental quality standards, 2.3. construction of dynamic standard methods for water quality in estuarine areas, 3. application example: evaluation of water quality in the pre (pb, ph, pi, do, cu, zn, cd, and hg), 3.1. description of the monitoring area, 3.2. sample collection and analysis, 3.3. analytical quality assurance, 3.4. results, 4. discussion, 5. conclusions, author contributions, institutional review board statement, informed consent statement, data availability statement, acknowledgments, conflicts of interest.
- Li, M.; Pang, B.; Lan, W.; Fu, J. Delineation of estuarine mixed zone and establishment of nutrient standard limits. China Environ. Monit. 2020 , 36 , 74–82. [ Google Scholar ] [ CrossRef ]
- Alber, M. A conceptual model of estuarine freshwater inflow management. Estuaries 2002 , 25 , 1246–1261. [ Google Scholar ] [ CrossRef ]
- Guo, H.; Wang, X.; Wang, Y.; Bao, M.; Li, X. Analysis of water quality evaluation standards for estuaries. Jiangsu Water Resour. 2022 , 4 , 62–65. [ Google Scholar ] [ CrossRef ]
- Wang, J.; Han, G.; Zhang, Z. The Latest Progress in International Marine Environmental Monitoring and Evaluation ; Ocean Press: Beijing, China, 2010. [ Google Scholar ]
- Meng, W. Research on China’s Ocean Engineering and Technology Development Strategy: Ocean Environment and Ecology Volume ; Ocean Press: Beijing, China, 2014. [ Google Scholar ]
- Chen, J. Estuarine Water Eco-Health Assessment Technical Method and Application ; Ocean University of China: Qingdao, China, 2013. [ Google Scholar ]
- Yang, F.; Lin, Z.; Zhang, Z.; Wang, L.; Yu, L.; Wang, J. Analysis on the problems of environmental quality standards for surface water and seawater in China. Mar. Dev. Manag. 2018 , 35 , 36–41. [ Google Scholar ]
- GB3097-1997 ; National Seawater Quality Standard of the People’s Republic of China. National Environmental Protection Administration: Beijing, China, 1997.
- GB3838-2002 ; General Administration of Quality Supervision of Inspection and Quarantine of China. National Standard of the People’s Republic of China Environmental Quality Standard for Surface Water. State Environmental Protection Administration: Beijing, China, 2002.
- Quan, Y.; Ji, X.; Wang, L.; Shi, B. Water quality analysis and evaluation of main estuaries in Qinhuangdao. Bull. Oceanol. Limnol. 2016 , 38 , 24–28. [ Google Scholar ] [ CrossRef ]
- Liu, J.; Liu, L.; Zheng, B. Problems and countermeasures of water environmental management in estuaries. Res. Environ. Sci. 2017 , 30 , 645–653. [ Google Scholar ] [ CrossRef ]
- Bricker, S.B.; Ferreira, J.G.; Simas, T. An integrated methodology for assessment of estuarine trophic status. Ecol. Model. 2003 , 169 , 39–60. [ Google Scholar ] [ CrossRef ]
- Ireland Environmental Protection Agency. Water Quality in Ireland 2001–2003 ; Environmental Protection Agency: Wexford, Ireland, 2005. [ Google Scholar ]
- OSPAR Commission. OSPAR Integrated Report 2003 on the Eutrophication Status of the OSPAR Maritime Area Based upon the First Application of the Comprehensive Procedure ; The Convention for the Protection of the Marine Environment of the North-East Atlantic: Paris, France, 2003. [ Google Scholar ]
- Office of Environment and Heritage. Assessing Estuary Ecosystem Health: Sampling, Data Analysis and Reporting Protocols ; State of NSW and Office of Environment and Heritage: Parramatta, NSW, Australia, 2013. [ Google Scholar ]
- Peng, T.; Wang, Z.; Zhao, Q. Ecosystem health assessment for Huangbai river based on PSR model. Water Resour. Prot. 2016 , 32 , 141–153. [ Google Scholar ]
- Ye, S.F.; Liu, X.; Ding, D.W. Ecosystem health assessment of the Changjiang river estuary: Indicator system and its primarily assessment. Acta Oceanol. Sin. 2007 , 29 , 128–136. [ Google Scholar ]
- Australian and New Zealand Environment and Conservation Council, Agriculture and Resource Management Council of Australia and New Zealand. Australia and New Zealand Guidelines for Fresh and Marine Water Quality ; Australian and New Zealand Environment and Conberra Council: Canberra, ACT, Australia, 2000. [ Google Scholar ]
- European Commission. Guidance on Typology, Reference Conditions and Classification Systems for Transitional and Coastal Water ; European Commission: Copenhagen, Denmark, 2002. [ Google Scholar ]
- US Environmental Protection Agency. Estuarine and Coastal Marine Waters: Bioassessment and Biocriteria Technical Guidance ; Office of Water: Washington, DC, USA, 2000. [ Google Scholar ]
- European Commission. Common Implementation Stategy for the Water Framework Directive (2000/30/EC-Technical Guidance for Deriving Environmental Quality Standards ; European Commission: Copenhagen, Denmark, 2000. [ Google Scholar ]
- US Environmental Protection Agency. National Estuary Program Coastal Condition Report. Chapter 5: Gulf of Mexico National Estuary Program Coastal Condition, Sarasota Bay Estuary Program ; US Environmental Protection Agency: Washington, DC, USA, 2007. [ Google Scholar ]
- Schuwirth, N. Towards an integrated surface water quality assessment: Aggregation over multiple pollutants and time. Water Res. 2020 , 186 , 761–774. [ Google Scholar ] [ CrossRef ]
- Reichert, J.; Schellenberg, J.; Schubert, P.; Wilke, T. Responses of reef building corals to microplastic exposure. Environ. Pollut. 2018 , 237 , 955–960. [ Google Scholar ] [ CrossRef ]
- Bawiec, A.; Paweska, K.; Jarzab, A. Changes in the Microbial Composition of Municipal Wastewater Treated in Biological Processes. J. Eco. Eng. 2016 , 17 , 41–46. [ Google Scholar ] [ CrossRef ]
- Lal, P.P.; Juste-Poinapen Ms, N.; Poinapen, J. Assessing the water quality of Suva foreshore for the establishment of estuary and marine recreational water guidelines in the Fiji Islands. Water Sci. Technol. 2021 , 84 , 3040–3054. [ Google Scholar ] [ CrossRef ] [ PubMed ]
- Li, S.; Chen, X.; Singh, V.P.; He, Y.; Bai, X. An improved index for water quality evaluation in an estuary region: A case study in the Eastern Pearl River Delta, China. Water Policy 2019 , 21 , 310–325. [ Google Scholar ] [ CrossRef ]
- Tri, D.Q.; Linh, N.T.M.; Thai, T.H.; Kandasamy, J. Application of 1D–2D coupled modeling in water quality assessment: A case study in Ca Mau Peninsula, Vietnam. Phys. Chem. Earth Parts A/B/C 2019 , 113 , 83–99. [ Google Scholar ]
- Tao, W.; Niu, L.; Dong, Y.; Fu, T.; Lou, Q. Nutrient pollution and its dynamic source-sink pattern in the Pearl River Estuary (South China). Front. Mar. Sci. 2021 , 8 , 713907. [ Google Scholar ] [ CrossRef ]
- Li, X.Q.; Lu, C.Q.; Zhang, Y.F.; Zhao, H.D.; Wang, J.Y.; Liu, H.B. Low dissolved oxygen in the Pearl River estuary in summer: Long-term spatio-temporal patterns, trends, and regulating factors. J. Mar. Sci. Eng. 2020 , 151 , 110814. [ Google Scholar ] [ CrossRef ]
- Tao, W.; Niu, L.X.; Liu, F.; Cai, H.Y.; Ou, S.Y.; Zeng, D.N.; Lou, Q.S.; Yang, Q.S. Influence of river-tide dynamics on phytoplankton variability and their ecological implications in two Chinese tropical estuaries. Ecol. Indic. 2020 , 115 , 106458. [ Google Scholar ] [ CrossRef ]
- Niu, L.X.; Cai, H.Y.; Jia, L.W.; Luo, X.X.; Tao, W.; Dong, Y.H.; Yang, Q.S. Metal pollution in the Pearl River Estuary and implications for estuary management: The influence of hydrological connectivity associated with estuarine mixing. EES 2021 , 225 , 112747. [ Google Scholar ]
- Tian, F.G.; Ni, Z.X.; Huang, B.B.; Lou, Q.S.; Zhong, Y.H.; Deng, W. Distribution characters of heavy metals in seawater and surface sediments in Daya Bay. J. Appl. Oceanogr. 2022 , 41 , 462–474. [ Google Scholar ]
- Tao, W.; Li, H.D.; Zhang, W.P.; Lou, Q.S.; Gong, J.; Ye, J.J. Characteristics of Heavy Metals in Seawater and Sediments from Daya Bay (South China): Environmental Fates, Source Apportionment and Ecological Risks. Sustainability 2021 , 13 , 10237. [ Google Scholar ] [ CrossRef ]
Click here to enlarge figure
| Similarities and Differences | Environmental Quality Standards for Surface Water (GB3838-2002) | Seawater Quality Standard (GB3097-1997) | ||
|---|---|---|---|---|
| Functional Categories Correspondence Relationship | Class I | Source water and nature reserves | N/A | |
| Class II | First-grade protection area of centralized surface drinking water sources, habitat of rare aquatic organisms, and feeding ground for young fish | Marine nature reserves, rare and endangered marine life reserves, and marine fishery waters | Class I | |
| Class III | Class II protection zone of centralized surface water sources for drinking water, fishery waters such as aquaculture, and swimming areas | Aquaculture areas, bathing beaches, and industrial water areas directly related to human consumption | Class II | |
| Class IV | General industrial water areas and entertainment water areas where the human body is not directly in contact | General industrial water area, coastal scenic tourist area | Class III | |
| Class V | Agricultural water use areas and general landscape requirements for water areas | Marine port waters and marine development operation areas | Class IV | |
| Element | A | A | A | A |
|---|---|---|---|---|
| Pb (mg/L) | ≤0.001 | ≤0.005 | ≤0.010 | ≤0.050 |
| pH | 7.8~8.5 | 6.8~8.8 | ||
| PI (mg/LO ) | ≤2 | ≤3 | ≤4 | ≤5 |
| DO (mg/L) | >6 | >5 | >4 | >3 |
| Cu (mg/L) | ≤0.005 | ≤0.010 | ≤0.050 | |
| Zn (mg/L) | ≤0.020 | ≤0.050 | ≤0.10 | ≤0.50 |
| Cd (mg/L) | ≤0.001 | ≤0.005 | ≤0.010 | |
| Hg (mg/L) | ≤0.00005 | ≤0.0002 | ≤0.0005 | |
| Element | B | B | B | B |
|---|---|---|---|---|
| Pb (mg/L) | ≤0.01 | ≤0.05 | ≤0.05 | ≤0.1 |
| pH | 6~9 | |||
| PI (mg/LO ) | ≤4 | ≤6 | ≤10 | ≤15 |
| DO (mg/L) | ≥6 | ≥5 | ≥3 | ≥2 |
| Cu (mg/L) | ≤1.0 | ≤1.0 | ≤1.0 | ≤1.0 |
| Zn (mg/L) | ≤1.0 | ≤1.0 | ≤2.0 | ≤2.0 |
| Cd (mg/L) | ≤0.005 | ≤0.005 | ≤0.005 | ≤0.01 |
| Hg (mg/L) | ≤0.00005 | ≤0.0001 | ≤0.001 | ≤0.001 |
| Sites | S01 | S02 | S03 | ||||
|---|---|---|---|---|---|---|---|
| Ebb tide | Water depth (m) | 0.5 | 8.0 | 0.5 | 8.0 | 0.5 | 7.0 |
| Salinity (S) | 16.453 | 17.641 | 17.565 | 17.643 | 15.405 | 16.439 | |
| Pb (mg/L) | 0.0006 | 0.0006 | 0.0010 | 0.0013 | 0.0007 | 0.0006 | |
| pH | 7.62 | 7.62 | 7.64 | 7.62 | 7.57 | 7.58 | |
| PI (mg/LO ) | 1.61 | 1.90 | 1.42 | 2.00 | 1.53 | 1.92 | |
| DO (mg/L) | 5.38 | 5.32 | 5.82 | 5.42 | 5.27 | 5.33 | |
| Cu (mg/L) | 0.0020 | 0.0016 | 0.0020 | 0.0022 | 0.0026 | 0.0022 | |
| Zn (mg/L) | 0.0069 | 0.0072 | 0.0109 | 0.0076 | 0.0071 | 0.0071 | |
| Cd (mg/L) | 0.00037 | 0.00038 | 0.00044 | 0.00042 | 0.0004 | 0.00043 | |
| Hg (mg/L) | 0.000028 | 0.000042 | 0.000030 | 0.000038 | 0.000028 | 0.000042 | |
| Rising tide | Water depth (m) | 0.5 | 7.0 | 0.5 | 7.0 | 0.5 | 8.0 |
| Salinity (S) | 15.660 | 15.663 | 15.435 | 15.743 | 13.551 | 14.529 | |
| Pb (mg/L) | 0.0008 | 0.0006 | 0.0005 | 0.0006 | 0.0005 | 0.0005 | |
| pH | 7.58 | 7.43 | 7.51 | 7.51 | 7.38 | 7.38 | |
| PI (mg/LO ) | 2.56 | 2.15 | 3.02 | 3.15 | 3.49 | 3.12 | |
| DO (mg/L) | 5.24 | 5.24 | 4.93 | 4.76 | 4.39 | 4.58 | |
| Cu (mg/L) | 0.0016 | 0.0018 | 0.0017 | 0.0015 | 0.0015 | 0.0015 | |
| Zn (mg/L) | 0.0079 | 0.0079 | 0.0078 | 0.0066 | 0.0073 | 0.0068 | |
| Cd (mg/L) | 0.00037 | 0.0004 | 0.00033 | 0.00033 | 0.0004 | 0.0004 | |
| Hg (mg/L) | 0.000024 | 0.000034 | 0.000031 | 0.000034 | 0.000028 | 0.000037 | |
| Sites | S01 | S02 | S03 | ||||
|---|---|---|---|---|---|---|---|
| Ebb tide | |||||||
| Pb | Class I | Class I | Class I | Class II | Class I | Class I | |
| pH | Class III | Class III | Class III | Class III | Class III | Class III | |
| PI | Class I | Class I | Class I | Class I | Class I | Class I | |
| DO | Class II | Class II | Class II | Class II | Class II | Class II | |
| Cu | Class I | Class I | Class I | Class I | Class I | Class I | |
| Zn | Class I | Class I | Class I | Class I | Class I | Class I | |
| Cd | Class I | Class I | Class I | Class I | Class I | Class I | |
| Hg | Class I | Class I | Class I | Class I | Class I | Class I | |
| Rising tide | |||||||
| Pb | Class I | Class I | Class I | Class I | Class I | Class I | |
| pH | Class III | Class III | Class III | Class III | Class III | Class III | |
| PI | Class II | Class II | Class III | Class III | Class III | Class III | |
| DO | Class II | Class II | Class III | Class III | Class III | Class III | |
| Cu | Class I | Class I | Class I | Class I | Class I | Class I | |
| Zn | Class I | Class I | Class I | Class I | Class I | Class I | |
| Cd | Class I | Class I | Class I | Class I | Class I | Class I | |
| Hg | Class I | Class I | Class I | Class I | Class I | Class I | |
| Sites | Depth (m) | Salinity (S) | C (mg/L) | C (mg/L) | C (mg/L) | C (mg/L) | |
|---|---|---|---|---|---|---|---|
| Ebb tide | S01 | 0.5 | 16.453 | 0.0052 | 0.0262 | 0.0288 | 0.0735 |
| 8.0 | 17.641 | 0.0055 | 0.0277 | 0.0302 | 0.0752 | ||
| S02 | 0.5 | 17.565 | 0.0055 | 0.0276 | 0.0301 | 0.0751 | |
| 8.0 | 17.643 | 0.0055 | 0.0277 | 0.0302 | 0.0752 | ||
| S03 | 0.5 | 15.405 | 0.0050 | 0.0248 | 0.0276 | 0.0720 | |
| 7.0 | 16.439 | 0.0052 | 0.0261 | 0.0288 | 0.0735 | ||
| Rising tide | S01 | 0.5 | 15.660 | 0.0050 | 0.0251 | 0.0279 | 0.0724 |
| 7.0 | 15.663 | 0.0050 | 0.0251 | 0.0279 | 0.0724 | ||
| S02 | 0.5 | 15.435 | 0.0050 | 0.0248 | 0.0276 | 0.0721 | |
| 7.0 | 15.743 | 0.0050 | 0.0252 | 0.0280 | 0.0725 | ||
| S03 | 0.5 | 13.551 | 0.0045 | 0.0224 | 0.0255 | 0.0694 | |
| 8.0 | 14.529 | 0.0047 | 0.0237 | 0.0266 | 0.0708 |
| Sites | Depth (m) | Salinity (S) | C | C | C | C | |
|---|---|---|---|---|---|---|---|
| Ebb tide | S01 | 0.5 | 16.453 | 6.85~8.74 | 6.85~8.74 | 6.38~8.89 | 6.38~8.89 |
| 8.0 | 17.641 | 6.91~8.75 | 6.91~8.75 | 6.40~8.90 | 6.40~8.90 | ||
| S02 | 0.5 | 17.565 | 6.90~8.75 | 6.90~8.75 | 6.40~8.90 | 6.40~8.90 | |
| 8.0 | 17.643 | 6.91~8.75 | 6.91~8.75 | 6.40~8.90 | 6.40~8.90 | ||
| S03 | 0.5 | 15.405 | 6.79~8.72 | 6.79~8.72 | 6.35~8.89 | 6.35~8.89 | |
| 7.0 | 16.439 | 6.85~8.73 | 6.85~8.73 | 6.38~8.89 | 6.38~8.89 | ||
| Rising tide | S01 | 0.5 | 15.660 | 6.81~8.72 | 6.81~8.72 | 6.36~8.89 | 6.36~8.89 |
| 7.0 | 15.663 | 6.81~8.72 | 6.81~8.72 | 6.36~8.89 | 6.36~8.89 | ||
| S02 | 0.5 | 15.435 | 6.79~8.72 | 6.79~8.72 | 6.35~8.89 | 6.35~8.89 | |
| 7.0 | 15.743 | 6.81~8.72 | 6.81~8.72 | 6.36~8.89 | 6.36~8.89 | ||
| S03 | 0.5 | 13.551 | 6.70~8.69 | 6.70~8.69 | 6.31~8.88 | 6.31~8.88 | |
| 8.0 | 14.529 | 6.75~8.71 | 6.75~8.71 | 6.33~8.88 | 6.33~8.88 |
| Sites | Depth (m) | Salinity (S) | C (mg/LO ) | C (mg/LO ) | C (mg/LO ) | C (mg/LO ) | |
|---|---|---|---|---|---|---|---|
| Ebb tide | S01 | 0.5 | 16.453 | 2.940 | 4.410 | 6.821 | 9.701 |
| 8.0 | 17.641 | 3.008 | 4.512 | 7.024 | 10.040 | ||
| S02 | 0.5 | 17.565 | 3.004 | 4.506 | 7.011 | 10.019 | |
| 8.0 | 17.643 | 3.008 | 4.512 | 7.025 | 10.041 | ||
| S03 | 0.5 | 15.405 | 2.880 | 4.320 | 6.641 | 9.401 | |
| 7.0 | 16.439 | 2.939 | 4.409 | 6.818 | 9.697 | ||
| Rising tide | S01 | 0.5 | 15.660 | 2.895 | 4.342 | 6.685 | 9.474 |
| 7.0 | 15.663 | 2.895 | 4.343 | 6.685 | 9.475 | ||
| S02 | 0.5 | 15.435 | 2.882 | 4.323 | 6.646 | 9.410 | |
| 7.0 | 15.743 | 2.900 | 4.349 | 6.699 | 9.498 | ||
| S03 | 0.5 | 13.551 | 2.774 | 4.162 | 6.323 | 8.872 | |
| 8.0 | 14.529 | 2.830 | 4.245 | 6.491 | 9.151 |
| Sites | Depth (m) | Salinity (S) | C (mg/L) | C (mg/L) | C (mg/L) | C (mg/L) | |
|---|---|---|---|---|---|---|---|
| Ebb tide | S01 | 0.5 | 16.453 | 6.000 | 5.000 | 3.470 | 2.470 |
| 8.0 | 17.641 | 6.000 | 5.000 | 3.504 | 2.504 | ||
| S02 | 0.5 | 17.565 | 6.000 | 5.000 | 3.502 | 2.502 | |
| 8.0 | 17.643 | 6.000 | 5.000 | 3.504 | 2.504 | ||
| S03 | 0.5 | 15.405 | 6.000 | 5.000 | 3.440 | 2.440 | |
| 7.0 | 16.439 | 6.000 | 5.000 | 3.470 | 2.470 | ||
| Rising tide | S01 | 0.5 | 15.660 | 6.000 | 5.000 | 3.447 | 2.447 |
| 7.0 | 15.663 | 6.000 | 5.000 | 3.448 | 2.448 | ||
| S02 | 0.5 | 15.435 | 6.000 | 5.000 | 3.441 | 2.441 | |
| 7.0 | 15.743 | 6.000 | 5.000 | 3.450 | 2.450 | ||
| S03 | 0.5 | 13.551 | 6.000 | 5.000 | 3.387 | 2.387 | |
| 8.0 | 14.529 | 6.000 | 5.000 | 3.415 | 2.415 |
| Sites | S01 | S02 | S03 | ||||
|---|---|---|---|---|---|---|---|
| Ebb tide | |||||||
| salinity | 16.453 | 17.641 | 17.565 | 17.643 | 15.405 | 16.439 | |
| Pb | Class I | Class I | Class I | Class I | Class I | Class I | |
| pH | Class I | Class I | Class I | Class I | Class I | Class I | |
| PI | Class I | Class I | Class I | Class I | Class I | Class I | |
| DO | Class II | Class II | Class II | Class II | Class II | Class II | |
| Rising tide | |||||||
| Salinity | 15.660 | 15.663 | 15.435 | 15.743 | 13.551 | 14.529 | |
| Pb | Class I | Class I | Class I | Class I | ClassI | Class I | |
| pH | Class I | Class I | Class I | Class I | Class I | Class I | |
| PI | Class I | Class I | Class II | Class II | Class II | Class II | |
| DO | Class II | Class II | Class III | Class III | Class III | Class III | |
| The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
Share and Cite
Wang, Z.; Zhang, H. A Proposed Methodology for the Dynamic Standard Evaluation of Water Quality in Estuaries: A Case Study of the Pearl River Estuary. J. Mar. Sci. Eng. 2024 , 12 , 1039. https://doi.org/10.3390/jmse12071039
Wang Z, Zhang H. A Proposed Methodology for the Dynamic Standard Evaluation of Water Quality in Estuaries: A Case Study of the Pearl River Estuary. Journal of Marine Science and Engineering . 2024; 12(7):1039. https://doi.org/10.3390/jmse12071039
Wang, Zhongyuan, and Hongkang Zhang. 2024. "A Proposed Methodology for the Dynamic Standard Evaluation of Water Quality in Estuaries: A Case Study of the Pearl River Estuary" Journal of Marine Science and Engineering 12, no. 7: 1039. https://doi.org/10.3390/jmse12071039
Article Metrics
Further information, mdpi initiatives, follow mdpi.
Subscribe to receive issue release notifications and newsletters from MDPI journals
- Open access
- Published: 15 June 2024
The quality of bone and paraspinal muscle in the fragility osteoporotic vertebral compression fracture: a comprehensive comparison between different indicators
- Sizheng Zhan 1 na1 ,
- Haoning Ma 1 na1 ,
- Xingguang Duan 2 &
- Ping Yi 1
BMC Musculoskeletal Disorders volume 25 , Article number: 471 ( 2024 ) Cite this article
103 Accesses
Metrics details
To evaluate the value of five indicators in predicting OVCF through a retrospective case–control study, and explore the internal correlation of different indicators.
We retrospectively enrolled patients over 50 years of age who had been subjected to surgery for fragility OVCF at China Japan Friendship Hospital from January 2021 to September 2023. Demographic characteristics, T-score based on dual-energy X-ray absorptiometry (DXA), CT-based Hounsfield unit (HU) value, vertebral bone quality (VBQ) score based on magnetic resonance imaging (MRI), relative cross-sectional area (rCSA) and the rate of fat infiltration (FI) of paraspinal muscle were collected. A 1:1 age- and sex-matched, fracture-free control group was established from patients admitted to our hospital for lumbar spinal stenosis or lumbar disk herniation.
A total of 78 patients with lumbar fragility OVCF were included. All the five indicators were significantly correlated with the occurrence of OVCFs. Logistic regression analysis showed that average HU value and VBQ score were significantly correlated with OVCF. The area under the curve (AUC) of VBQ score was the largest (0.89). There was a significantly positive correlation between average T-score, average HU value and average total rCSA. VBQ score was significantly positive correlated with FI.
VBQ score and HU value has good value in predicting of fragility OVCF. In addition to bone mineral density, we should pay more attention to bone quality, including the fatty signal intensity in bone and the FI in paraspinal muscle.
Peer Review reports
Introduction
Fragility fractures refer to fractures that occur after no trauma or minor trauma [ 1 ]. The most common fragility fracture is the osteoporotic vertebral compression fracture (OVCF) [ 2 ]. With the aging of the population, the incidence of fragile OVCF is increasing. According to the results of the osteoporosis epidemiological survey in China from 2017 to 2018 [ 3 ], the prevalence of OVCF in the population was 10.5% in men and 9.7% in women over 40 years old. The OVCF is one of the main causes of disability and death in elderly patients, and also causes a heavy burden to the family and society [ 4 ]. Therefore, it is of great significance to screen and identify high-risk factors for fragile OVCF in advance and provide timely preventive measures.
The most common cause of fragility OVCF is osteoporosis. Currently, dual-energy X-ray absorptiometry (DXA) is the gold standard for assessing bone mineral density (BMD), but its measurements are often overestimated due to lumbar degeneration, such as the formation of vertebral osteophytes [ 5 ]. Schuit [ 6 ] found that more than half of all fragility fractures occur in patients diagnosed without osteoporosis by DXA. Therefore, BMD measured by DXA may not be a sensitive indicator for fragility OVCF.
In order to enhance the assessment of vertebral bone quality in patients, numerous indicators have been proposed by scholars, including CT-based Hounsfield unit (HU) value [ 7 , 8 ] and vertebral bone quality score (VBQ) based on magnetic resonance imaging (MRI) [ 9 , 10 ]. Compared with DXA, HU value and VBQ score are easy to obtain in clinic, and do not need to add additional examination for patients. The research results of Zou et al. showed that low HU value was related to the occurrence of lumbar OVCF [ 7 ]. The research of Li et al. showed that VBQ can be used to predict the occurrence of OVCF [ 10 ]. Meanwhile, with the recognition of the importance of paraspinal muscle in maintaining lumbar spine stability and reducing lumbar spine load [ 11 , 12 ], researchers [ 13 , 14 ] found that the cross-sectional area (CSA) of paraspinal muscle in OVCF patients was smaller and the rate of fat infiltration (FI) was higher.
Therefore, we intend to evaluate the value of different indicators in predicting OVCF through a retrospective case–control study, and explore the internal correlation of different indicators.
Prior to the start of the study, the protocol was approved by the ethics review committee of China Japan Friendship Hospital. We reviewed patients admitted to our department of spinal surgery from January 2021 to September 2023. Inclusion criteria were (1) age \(\ge\) 50 years, regardless of the gender; (2) completed perioperative DXA scans, lumbar MRI and lumbar CT scans within 1 weeks; (3) fresh lumbar fragility OVCF; (4) the time between back pain onset and surgery is less than 2 weeks. Exclusion criteria were (1) previous history of fracture, surgery, trauma, or infection in L1 − L4; (2) Kummell’s disease; (3) long-term oral hormone-like drug therapy; (4) high-energy vertebral fractures, such as car accidents, falls, etc. In addition, for comparison with patients who did not have fractures, a 1:1 age- and sex-matched, fracture-free control group was established from patients admitted to our hospital for lumbar spinal stenosis or lumbar disk herniation with or without degenerative lumbar spondylolisthesis (the degree is less than 50%). The exclusion criteria were as described above.
We collected demographic characteristics of patients via our hospital’s electronic medical record system, including age, sex, body mass index (BMI), course of disease (the time between back pain onset and surgery), and comorbidities, etc.
BMD evaluation
For BMD, DXA scans (Discovery A densitometers, Hologic Inc., Bedford, MA, USA) of lumbar, femur and hip were performed during hospitalization. The T-score of L1-L4 were recorded from DXA. T-score of the fractured vertebrae were discarded.
Calculation of the VBQ score
According to the method proposed previousl [ 15 ], the VBQ score was calculated using signal intensity (SI) obtained from a non-contrast, T1-weighted lumbar spine MRI image (Fig. 1 ). Firstly, the mean SI of the trabecular bone of the vertebrae (L1 − L4) was measured using the midsagittal slices. For patients with abnormalities in the midsagittal slice (eg, hemangioma, venous plexus, scoliosis changes), measurements were performed using the parasagittal slices. The fractured vertebrae was excluded from the calculation and only the remaining vertebrae were used to calculate the VBQ score. The median SI of the L1-L4 was then divided by the SI of the cerebrospinal fluid (CSF) at L3 level to obtain the VBQ score. CSF ROI was placed at L2 or L4 level when L3 CSF space was completely blocked by descending nerve roots.

Non-contrast-enhanced T1-weighted MRI image shows the SI of L1, L3, L4 and SI of CSF using ROIs
The HU values of vertebrae in CT
The HU values of L1-L4 were measured for each patient according to the method of previous studies (Fig. 2 ) [ 8 ]. An oval region of interest inclusive of trabecular bone was placed in the middle-axial CT image of vertebral body. We avoided placing the ROI near areas that would distort the BMD measurement (posterior venous plexus; focal heterogeneity or lesion, including compression fracture; and imaging-related artifacts).

Example of the measurement of HU value at L3
Paraspinal muscle evaluation on MRI
The Picture Archiving and Communication Systems (PACS) processed imaging data of the paravertebral muscles and measured the cross-sectional area (CSA) of the paraspinal muscles. Relative cross-sectional area (rCSA, the ratio of cross-sectional area of muscle to that of disc at the same level) was introduced for reducing the effect of body shape on muscular parameters. The fat infiltration (FI) of the paraspinal muscles (psoas major [PM], multifidus [MF] and erector spinae [ES]) were measured by Image J software (Fig. 3 ). Middle images of each disc space at L1-2, L2 − 3, L3 − 4, and L4 − 5 was selected by locating lines in the sagittal slice. The pseudocoloring technique was used to measure the percentage of fat content. The bright pixels of fatty tissue are painted red and the percentage of red areas in the muscle compartment was calculated [ 16 ]. The paraspinal muscle-related parameters were the FI averaged on both sides and the three slices and the average total rCSA of PM, MF and ES across different cross Sects [ 17 ].

A Measurements of paraspinal muscular parameters on axial T2-weighted MRI. Regions of total cross-sectional area of multifidus (1), erector spinae (2), psoas muscle (3) level were outlined by green lines; B Thresholding technique to highlight intramuscular fat area (red area)
All quantitative measurements were analyzed using the average values of the measurements obtained by the two investigators.
Statistical analysis
Statistical analysis was performed using IBM SPSS Statistics for Windows, version 26.0 (IBMCorp., Armonk, N.Y., USA). The age- and sex-matching process was performed with the case–control matching function of SPSS. Inter-rater and intra-rater reliability was assessed with the intraclass correlation coefficient (ICC), respectively. Paired t test was used to compare the difference between the fracture group and the control group without fractures. The correlation analysis was calculated using Spearman correlation coefficients. Logistic regression analysis was used to examine the contribution of T-score, paravertebral muscle-related parameters, VBQ score and Hu values to the OVCF. Receiver-operator curve (ROC) was used to evaluate the performance of T-score, paravertebral muscle-related parameters, VBQ score and Hu values in distinguishing fracture patients from control patients. Statistical significance was set at P value < 0.05. STATA 15.0 were used to draw the ROC curves.
A total of 78 patients with lumbar fragility OVCF were included in this study, including 28 males and 50 females (Fig. 4 ). As for the 1:1 age and sex matched patients, all patients with OVCF were successfully matched to patients without fractures, and 78 control patients were also included in the study. There were no significant differences in gender and age between the two groups (Table 1 ). The ICCs of HU value, VBQ score and paraspinal muscle related parameters were all above 0.8.

Patient flow
The average T-score, VBQ score and average FI in the OVCF group were significantly higher than those in the control group, and HU value and average total rCSA were significantly lower than those in the control group. T-score, average HU value, VBQ score, average total rCSA and average FI were all significantly correlated with the occurrence of OVCFs. The correlations were ranked from high to low as VBQ score, average HU value, average FI, T-score, and average total rCSA (Rho = 0.84, -0.665, 0.568, -0.399, -0.297, respectively; Table 2 ). After adjusting for age, sex and BMI, logistic regression analysis showed that HU value and VBQ score were significantly correlated with OVCF (OR = 0.39, 95%CI: 0.29–0.77; and OR = 2.98, 95%CI: 1.78–8.25, respectively; Table 2 ). ROC curve was used to evaluate the different indicators for predicting OVCF. The area under the curve (AUC) of VBQ score was the largest (0.895, Fig. 5 ).

The ROC curves of the five indicators for OVCF
The correlation analysis among the different indicators found that there were significant correlations among the five indicators (Table 3 ). There was a positive correlation between average T-score, HU value and average total rCSA. VBQ score was significantly positive correlated with FI. The strongest correlations were HU value and average T-score (Rho = 0.926), VBQ score and average FI (Rho = 0.919), respectively.
In the face of an increasing number of risk indicators for OVCF, we compared five indicators that have been widely studied firstly. Through the retrospective case–control study, we found that all five indicators were associated with OVCF, and the two most strongly correlated indicators were VBQ score and HU value. At the same time, the internal correlation analysis showed that T-score, HU value and rCSA were significantly positive correlated, and FI and VBQ score were significantly positive correlated.
It is of great significance to screen and identify high-risk factors for fragile OVCF in advance and provide timely preventive measures. The most common cause of fragility OVCF is osteoporosis. Currently, dual-energy X-ray absorptiometry (DXA) is the gold standard for assessing bone mineral density (BMD), but its measurements are often overestimated due to lumbar degeneration, such as the formation of vertebral osteophytes [ 5 ]. With increasing awareness of identifying high risk factors for OVCF, it has been identified based on some routine tests. In 2013, it was found that CT-based HU value could be used to determine BMD [ 8 ]. A number of studies [ 7 , 18 , 19 ] by Li have shown that HU value has good application value in identing the high-risk factors of OVCF and postoperative nonunion. A wide range of studies have confirmed that HU value can be used as a simple and important method to evaluate BMD in patients [ 19 ].
VBQ score based on MRI is a new technique to evaluate bone quality first introduced by Ehresman in 2019 [ 20 ], and its principle is to measure the fat content of the vertebra and indirectly reflect the bone quality [ 20 ]. A good correlation between the VBQ score and BMD has been widely demonstrated [ 21 ]. It has also been found to predict complications after spinal surgery [ 22 ]. A retrospective single-center cohort study also found that the VBQ score could predict fragile vertebral fractures independently of BMD [ 23 ].
With the deepening of clinical research, clinicians gradually discovered the important role of paraspinal muscle. A large number of studies have shown that the reduction of paraspinal muscle CSA and the increase of FI are closely related to the occurrence of various lumbar diseases [ 14 , 17 , 24 ]. Paraspinal muscle-related parameters were significantly correlated with BMD [ 11 ]. Paraspinal muscle degeneration can be used to predict OVCF [ 14 ], postoperative outcome of lumbar stenosis [ 24 ], postoperative complications of scoliosis [ 17 ], etc. The clinical outcome of patients can be improved by strengthening the paraspinal muscle [ 25 ].
Each indicator has been validated in clinical studies for its important role in assessing risk factors for OVCF. But which indicator is better, the internal correlation between each indicator is still questionable. In our study cohort, VBQ score and HU value ranked first and second in evaluating OVCF risk, superior to T-score. Therefore, in clinical work, we recommend the priority selection of VBQ score as an evaluation indicator for OVCF risk. If the patient cannot complete MRI examination, we suggest that HU value should be selected as an evaluation indicator to identify the risk of OVCF. Compared with DXA, CT or MRI can also provide clinical information in addition to bone quality. At the same time, Ehresman’s study [ 23 ] showed that the fatty signal intensity in bone has an important influence on bone quality. In our study, we also found that in addition to BMD, the fatty signal intensity in bone may be more important.
In the evaluation of paraspinal muscle, we found that FI was more important than CSA. Other studies [ 14 ] have come to similar conclusions that OVCF is more related to FI than CSA. We have chosen rCSA to reduce the interference caused by factors such as height, but the conclusion is still consistent. The possible reason is that greater CSA does not mean stronger paraspinal muscle strength, and the correlation between paraspinal muscle strength and FI is stronger. At the same time, we found that the correlation between OVCF and FI or CSA was not as good as that of VBQ score, HU value or T-score. This suggests that OVCF may be more related to bone quality rather than paraspinal muscles. Finite element analysis found that strengthening the paravertebral muscle could only reduce the vertebral load by 3.1% at most 12 . Therefore, as for the prevention of OVCF, the most noteworthy is the bone quality. The paraspinal muscle is also a very critical intervention variable.
As for the internal correlation of different indicators, we found that T-score was significantly correlated with HU value, and VBQ score was significantly correlated with FI. The results from other studies [ 7 , 11 ] also show that T-score and HU are significantly consistent. The measurement of the two depends on bone trabecular density, etc. So in the clinic, HU value may replace T-score to assess the BMD. Li’s study 16 showed that the CSA and FI of the paraspinal muscle may be more likely to influence the value of the VBQ score than BMD, which showed the important influence of the fatty signal intensity in bone quality.
The limitations of this study should also be considered. First, as a retrospective study, the data were obtained from the medical record system. Some data, such as patients’ special comorbidities, smoking or drinking history, were not fully recorded. Some studies have proved that these comorbidities might affect the occurrence of OVCF. Second, patients in the control group were hospitalized for surgical treatment due to lumbar spinal stenosis or lumbar disc herniation. Lumbar MRI scans are less common in patients treated conservatively. Therefore, VBQ scores and the other indicators in patients who did not receive any surgical treatment were not analyzed in this study. In addition, the acquisition of HU value, VBQ score and paraspinal muscle-related parameters differ greatly. Although there is good internal consistency in our study, this is based on sufficient sample size training and internal communication among data collectors.
VBQ score and HU value has good value in predicting of fragility OVCF. The higher the VBQ score, the lower the HU value, the greater the likelihood of a fragility OVCF. In addition to BMD, we should pay more attention to bone quality, including the fatty signal intensity in bone and the FI in paraspinal muscle.
Availability of data and materials
Almost all data generated or analysed during this study are included in this published article. The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Abbreviations
- Osteoporotic vertebral compression fracture
Dual-energy X-ray absorptiometry
Hounsfield unit
Vertebral bone quality
Magnetic resonance imaging
Relative cross-sectional area
Fat infiltration
Area under the curve
Body mass index
Signal intensity
Cerebrospinal fluid
Bone mineral density
Cheng X, Zhao K, Zha X, et al. Opportunistic screening using low-dose CT and the prevalence of osteoporosis in China: a nationwide, multicenter study. J Bone Miner Res. 2021;36(3):427–35.
Article CAS PubMed Google Scholar
LeBoff MS, Greenspan SL, Insogna KL, et al. The clinician’s guide to prevention and treatment of osteoporosis. Osteoporosis Int. 2022;33(10):2049–102.
Article CAS Google Scholar
Society TOFTGoOCoCG. Treatment guidelines for osteoporotic vertebral compression fractures. Chin J Osteoporos. 2015;6(21):643–8.
Google Scholar
Papaioannou A, Santesso N, Morin SN, et al. Recommendations for preventing fracture in long-term care. CMAJ. 2015;187(15):1135–44.
Article PubMed PubMed Central Google Scholar
Muraki S, Yamamoto S, Ishibashi H, et al. Impact of degenerative spinal diseases on bone mineral density of the lumbar spine in elderly women. Osteoporos Int. 2004;15(9):724–8.
Article PubMed Google Scholar
Schuit SC, van der Klift M, Weel AE, et al. Fracture incidence and association with bone mineral density in elderly men and women: the Rotterdam study. Bone. 2004;34(1):195–202.
Zou D, Ye K, Tian Y, et al. Characteristics of vertebral CT Hounsfield units in elderly patients with acute vertebral fragility fractures. Eur Spine J. 2020;29(5):1092–7.
Pickhardt PJ, Pooler BD, Lauder T, del Rio AM, Bruce RJ, Binkley N. Opportunistic screening for osteoporosis using abdominal computed tomography scans obtained for other indications. Ann Intern Med. 2013;158(8):588–95.
Li W, Zhu H, Liu J, Tian H, Li J, Wang L. Characteristics of MRI-based vertebral bone quality scores in elderly patients with vertebral fragility fractures. Eur Spine J. 2023;32(7):2588–93.
Li R, Yin Y, Ji W, et al. MRI-based vertebral bone quality score effectively reflects bone quality in patients with osteoporotic vertebral compressive fractures. Eur Spine J. 2022;31(5):1131–7.
Han G, Zou D, Liu Z, et al. Paraspinal muscle characteristics on MRI in degenerative lumbar spine with normal bone density, osteopenia and osteoporosis: a case-control study. BMC Musculoskelet Disord. 2022;23(1):73.
Article CAS PubMed PubMed Central Google Scholar
Kang S, Chang MC, Kim H, et al. The effects of paraspinal muscle volume on physiological load on the lumbar vertebral column: a finite-element study. Spine. 2021;46(19):E1015-e1021.
Huang CWC, Tseng IJ, Yang SW, Lin YK, Chan WP. Lumbar muscle volume in postmenopausal women with osteoporotic compression fractures: quantitative measurement using MRI. Eur Radiol. 2019;29(9):4999–5006.
Chen Z, Shi T, Li W, Sun J, Yao Z, Liu W. Role of paraspinal muscle degeneration in the occurrence and recurrence of osteoporotic vertebral fracture: a meta-analysis. Front Endocrinol (Lausanne). 2022;13:1073013.
Ehresman J, Pennington Z, Schilling A, et al. MRI-based score for assessment of bone density in operative spine patients. Spine J. 2020;20(4):556–62.
Li W, Wang F, Chen J, Zhu H, Tian H, Wang L. MRI-based vertebral bone quality score is a comprehensive index reflecting the quality of bone and paravertebral muscle. Spine J. 2024;24(3):472–8.
Leng J, Han G, Zeng Y, Chen Z, Li W. The effect of paraspinal muscle degeneration on distal pedicle screw loosening following corrective surgery for degenerative lumbar scoliosis. Spine. 2020;45(9):590–8.
Wang H, Zou D, Sun Z, Wang L, Ding W, Li W. Hounsfield unit for assessing vertebral bone quality and asymmetrical vertebral degeneration in degenerative lumbar scoliosis. Spine. 2020;45(22):1559–66.
Zou D, Sun Z, Zhou S, Zhong W, Li W. Hounsfield units value is a better predictor of pedicle screw loosening than the T-score of DXA in patients with lumbar degenerative diseases. Eur Spine J. 2020;29(5):1105–11.
Ehresman J, Schilling A, Pennington Z, et al. A novel MRI-based score assessing trabecular bone quality to predict vertebral compression fractures in patients with spinal metastasis. J Neurosurgery Spine. 2019;32(4):499–506.
Article Google Scholar
Salzmann SN, Okano I, Jones C, et al. Preoperative MRI-based vertebral bone quality (VBQ) score assessment in patients undergoing lumbar spinal fusion. Spine J. 2022;22(8):1301–8.
Li W, Zhu H, Hua Z, et al. Vertebral bone quality score as a predictor of pedicle screw loosening following surgery for degenerative lumbar disease. Spine. 2023;48(23):1635–41.
Ehresman J, Schilling A, Yang X, et al. Vertebral bone quality score predicts fragility fractures independently of bone mineral density. Spine J. 2021;21(1):20–7.
Han G, Zou D, Li X, et al. Can fat infiltration in the multifidus muscle be a predictor of postoperative symptoms and complications in patients undergoing lumbar fusion for degenerative lumbar spinal stenosis? A case-control study. J Orthop Surg Res. 2022;17(1):289.
Zhao H, He Y, Yang JS, et al. Can paraspinal muscle degeneration be a reason for refractures after percutaneous kyphoplasty? A magnetic resonance imaging observation. J Orthop Surg Res. 2021;16(1):476.
Download references
Acknowledgements
This study was funded by Beijing Natural Science Foundation number L212005.
Author information
Sizheng Zhan and Haoning Ma co-first author.
Authors and Affiliations
Department of Spine Surgery, China, Japan Friendship Hospital, No.2 Yinghuayuan East Street, Chaoyang District, Beijing, 100029, China
Sizheng Zhan, Haoning Ma & Ping Yi
School of Mechatronical Engineering, Beijing Institute of Technology, Beijing, 100081, China
Xingguang Duan
You can also search for this author in PubMed Google Scholar
Contributions
Sizheng Zhan, Haoning Ma and Ping Yi were responsible for research design. Haoning Ma, Xingguang Duan and Sizheng, Zhan collected and analyzed the patient clinical and hematological data. Sizheng, Zhan and Haoning Ma were major contributors to writing the manuscript and should be listed as to co-first authors. All authors read and approved the final manuscript.
Corresponding author
Correspondence to Ping Yi .
Ethics declarations
Ethics approval and consent to participate.
The study was approved by the ethics committee of China Japan Friendship Hospital. Signing the informed consent was waived by the ethics committee of China Japan Friendship Hospital.
Consent for publication
Not applicable.
Competing interests
The authors declare no competing interests.
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ . The Creative Commons Public Domain Dedication waiver ( http://creativecommons.org/publicdomain/zero/1.0/ ) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
Reprints and permissions
About this article
Cite this article.
Zhan, S., Ma, H., Duan, X. et al. The quality of bone and paraspinal muscle in the fragility osteoporotic vertebral compression fracture: a comprehensive comparison between different indicators. BMC Musculoskelet Disord 25 , 471 (2024). https://doi.org/10.1186/s12891-024-07587-8
Download citation
Received : 18 February 2024
Accepted : 11 June 2024
Published : 15 June 2024
DOI : https://doi.org/10.1186/s12891-024-07587-8
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Vertebral bone quality score
- Paraspinal muscle
- CT-based Hounsfield unit value
BMC Musculoskeletal Disorders
ISSN: 1471-2474
- Submission enquiries: [email protected]
- General enquiries: [email protected]
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
Quality management
- Business management
- Process management
- Project management

Crafting the Luxury Experience
- Robert Chavez
- December 04, 2011
Creating a Culture of Quality
- Ashwin Srinivasan
- Bryan Kurey
- From the April 2014 Issue
Relentless Idealism for Tough Times
- Alice Waters
- From the June 2009 Issue

U.S. Health Care Reform Can't Wait for Quality Measures to Be Perfect
- Brian J Marcotte
- Annette Guarisco Fildes
- Michael Thompson
- Leah Binder
- October 04, 2017
Coming Commoditization of Processes
- Thomas H. Davenport
- From the June 2005 Issue
Benchmarking Your Staff
- Michael Goold
- David J. Collis
- From the September 2005 Issue
The Contradictions That Drive Toyota's Success
- Hirotaka Takeuchi
- Norihiko Shimizu
- From the June 2008 Issue
Inside the Mind of the Chinese Consumer
- William McEwen
- Xiaoguang Fang
- Chuanping Zhang
- Richard Burkholder
- From the March 2006 Issue

Will Disruptive Innovations Cure Health Care? (HBR OnPoint Enhanced Edition)
- Clayton M. Christensen
- Richard Bohmer
- John Kenagy
- June 01, 2004
Will Disruptive Innovations Cure Health Care?
- September 01, 2000
Manage Your Human Sigma
- John H. Fleming
- Curt Coffman
- James K. Harter
- From the July–August 2005 Issue

The Employer-Led Health Care Revolution
- Patricia A. McDonald
- Robert S. Mecklenburg
- Lindsay A. Martin
- From the July–August 2015 Issue
Reign of Zero Tolerance (HBR Case Study and Commentary)
- Janet Parker
- Eugene Volokh
- Jean Halloran
- Michael G. Cherkasky
- From the November 2006 Issue
Reign of Zero Tolerance (HBR Case Study)
- November 01, 2006
Quality Circles After the Fad
- Edward E. Lawler III
- Susan A. Mohrman
- From the January 1985 Issue
Growth as a Process: The HBR Interview
- Jeffrey R. Immelt
- Thomas A. Stewart
- From the June 2006 Issue

The Case for Capitation
- Brent C. James
- Gregory P. Poulsen
- From the July–August 2016 Issue

Lean Knowledge Work
- Bradley Staats
- David M. Upton
- From the October 2011 Issue

Teaching Smart People How to Learn
- Chris Argyris
- From the May–June 1991 Issue

Learning to Lead at Toyota
- Steven J. Spear
- From the May 2004 Issue

Cost System Analysis
- Robert S. Kaplan
- December 01, 1994
Micom Caribe (A)
- Joshua D. Margolis
- November 15, 1991
General Electric--Thermocouple Manufacturing (B)
- David A. Garvin
- Suzanne Detreville
- February 12, 1985
A3 Thinking
- Elliott N. Weiss
- Austin English
- June 03, 2020
Lean Manufacturing at FCI (A):The Global Challenge
- Cynthia Laumuno
- Enver Yucesan
- June 25, 2012
Six Sigma: F(X) Cascade
- Andrew Gonce
- March 08, 2001
Micom Caribe (B)
The challenge facing the u.s. healthcare delivery system.
- Carin-Isabel Knoop
- June 06, 2006
Hub and Spoke, Health Care Global, and Additional Focused Factory Models for Cancer Care
- Regina E. Herzlinger
- Amit Ghorawat
- Meera Krishnan
- Naiyya Saggi
- August 26, 2012
Cristo Rey St. Martin College Preparatory School: Promoting a Culture of Continuous Improvement
- Gail Berger Darlow
- Liz Livingston Howard
- March 08, 2019
LongXi Machinery Works: Quality Improvement (A)
- Robert Klassen
- May 04, 1998
Danaher Corporation, 2007-2017
- John R. Wells
- Gabriel Ellsworth
- January 18, 2017
Apollo Hospitals: Differentiation through Hospitality
- Suhruta Kulkarni
- Kripa Makhija
- Unnikrishnan Dinesh Kumar
- June 01, 2013
Gati: Achieving Quality Excellence in Shipment Delivery
- Soumyajyoti Datta
- Rohit Kapoor
- August 22, 2019
Andrew Ryan at VC Brakes
- Frank V. Cespedes
- February 11, 2013
Megacard Corporation
- Edward W. Davis
- John L. Colley
- February 18, 1993

Redefining Health Care: Creating Value-Based Competition on Results
- Michael E. Porter
- Elizabeth Olmsted Teisberg
- May 25, 2006
- Elaine Landry
- January 01, 2000
GE: We Bring Good Things to Life (A)
- James L. Heskett
- January 22, 1999
Eurasia International: Total Quality Management in the Shipping Industry
- Ali Farhoomand
- Amir Hoosain
- July 23, 2004
Fine Tuning Market Oriented Practices
- Brendan Gray
- July 15, 2010
Popular Topics
Partner center.

An official website of the United States government
Here’s how you know
Official websites use .gov A .gov website belongs to an official government organization in the United States.
Secure .gov websites use HTTPS A lock ( A locked padlock ) or https:// means you’ve safely connected to the .gov website. Share sensitive information only on official, secure websites.
- Heart-Healthy Living
- High Blood Pressure
- Sickle Cell Disease
- Sleep Apnea
- Information & Resources on COVID-19
- The Heart Truth®
- Learn More Breathe Better®
- Blood Diseases and Disorders Education Program
- Publications and Resources
- Blood Disorders and Blood Safety
- Sleep Science and Sleep Disorders
- Lung Diseases
- Health Disparities and Inequities
- Heart and Vascular Diseases
- Precision Medicine Activities
- Obesity, Nutrition, and Physical Activity
- Population and Epidemiology Studies
- Women’s Health
- Research Topics
- Clinical Trials
- All Science A-Z
- Grants and Training Home
- Policies and Guidelines
- Funding Opportunities and Contacts
- Training and Career Development
- Email Alerts
- NHLBI in the Press
- Research Features
- Past Events
- Upcoming Events
- Mission and Strategic Vision
- Divisions, Offices and Centers
- Advisory Committees
- Budget and Legislative Information
- Jobs and Working at the NHLBI
- Contact and FAQs
- NIH Sleep Research Plan
- < Back To Health Topics
Study Quality Assessment Tools
In 2013, NHLBI developed a set of tailored quality assessment tools to assist reviewers in focusing on concepts that are key to a study’s internal validity. The tools were specific to certain study designs and tested for potential flaws in study methods or implementation. Experts used the tools during the systematic evidence review process to update existing clinical guidelines, such as those on cholesterol, blood pressure, and obesity. Their findings are outlined in the following reports:
- Assessing Cardiovascular Risk: Systematic Evidence Review from the Risk Assessment Work Group
- Management of Blood Cholesterol in Adults: Systematic Evidence Review from the Cholesterol Expert Panel
- Management of Blood Pressure in Adults: Systematic Evidence Review from the Blood Pressure Expert Panel
- Managing Overweight and Obesity in Adults: Systematic Evidence Review from the Obesity Expert Panel
While these tools have not been independently published and would not be considered standardized, they may be useful to the research community. These reports describe how experts used the tools for the project. Researchers may want to use the tools for their own projects; however, they would need to determine their own parameters for making judgements. Details about the design and application of the tools are included in Appendix A of the reports.
Quality Assessment of Controlled Intervention Studies - Study Quality Assessment Tools
| Criteria | Yes | No | Other (CD, NR, NA)* |
|---|---|---|---|
| 1. Was the study described as randomized, a randomized trial, a randomized clinical trial, or an RCT? | |||
| 2. Was the method of randomization adequate (i.e., use of randomly generated assignment)? | |||
| 3. Was the treatment allocation concealed (so that assignments could not be predicted)? | |||
| 4. Were study participants and providers blinded to treatment group assignment? | |||
| 5. Were the people assessing the outcomes blinded to the participants' group assignments? | |||
| 6. Were the groups similar at baseline on important characteristics that could affect outcomes (e.g., demographics, risk factors, co-morbid conditions)? | |||
| 7. Was the overall drop-out rate from the study at endpoint 20% or lower of the number allocated to treatment? | |||
| 8. Was the differential drop-out rate (between treatment groups) at endpoint 15 percentage points or lower? | |||
| 9. Was there high adherence to the intervention protocols for each treatment group? | |||
| 10. Were other interventions avoided or similar in the groups (e.g., similar background treatments)? | |||
| 11. Were outcomes assessed using valid and reliable measures, implemented consistently across all study participants? | |||
| 12. Did the authors report that the sample size was sufficiently large to be able to detect a difference in the main outcome between groups with at least 80% power? | |||
| 13. Were outcomes reported or subgroups analyzed prespecified (i.e., identified before analyses were conducted)? | |||
| 14. Were all randomized participants analyzed in the group to which they were originally assigned, i.e., did they use an intention-to-treat analysis? |
| Quality Rating (Good, Fair, or Poor) |
|---|
| Rater #1 initials: |
| Rater #2 initials: |
| Additional Comments (If POOR, please state why): |
*CD, cannot determine; NA, not applicable; NR, not reported
Guidance for Assessing the Quality of Controlled Intervention Studies
The guidance document below is organized by question number from the tool for quality assessment of controlled intervention studies.
Question 1. Described as randomized
Was the study described as randomized? A study does not satisfy quality criteria as randomized simply because the authors call it randomized; however, it is a first step in determining if a study is randomized
Questions 2 and 3. Treatment allocation–two interrelated pieces
Adequate randomization: Randomization is adequate if it occurred according to the play of chance (e.g., computer generated sequence in more recent studies, or random number table in older studies). Inadequate randomization: Randomization is inadequate if there is a preset plan (e.g., alternation where every other subject is assigned to treatment arm or another method of allocation is used, such as time or day of hospital admission or clinic visit, ZIP Code, phone number, etc.). In fact, this is not randomization at all–it is another method of assignment to groups. If assignment is not by the play of chance, then the answer to this question is no. There may be some tricky scenarios that will need to be read carefully and considered for the role of chance in assignment. For example, randomization may occur at the site level, where all individuals at a particular site are assigned to receive treatment or no treatment. This scenario is used for group-randomized trials, which can be truly randomized, but often are "quasi-experimental" studies with comparison groups rather than true control groups. (Few, if any, group-randomized trials are anticipated for this evidence review.)
Allocation concealment: This means that one does not know in advance, or cannot guess accurately, to what group the next person eligible for randomization will be assigned. Methods include sequentially numbered opaque sealed envelopes, numbered or coded containers, central randomization by a coordinating center, computer-generated randomization that is not revealed ahead of time, etc. Questions 4 and 5. Blinding
Blinding means that one does not know to which group–intervention or control–the participant is assigned. It is also sometimes called "masking." The reviewer assessed whether each of the following was blinded to knowledge of treatment assignment: (1) the person assessing the primary outcome(s) for the study (e.g., taking the measurements such as blood pressure, examining health records for events such as myocardial infarction, reviewing and interpreting test results such as x ray or cardiac catheterization findings); (2) the person receiving the intervention (e.g., the patient or other study participant); and (3) the person providing the intervention (e.g., the physician, nurse, pharmacist, dietitian, or behavioral interventionist).
Generally placebo-controlled medication studies are blinded to patient, provider, and outcome assessors; behavioral, lifestyle, and surgical studies are examples of studies that are frequently blinded only to the outcome assessors because blinding of the persons providing and receiving the interventions is difficult in these situations. Sometimes the individual providing the intervention is the same person performing the outcome assessment. This was noted when it occurred.
Question 6. Similarity of groups at baseline
This question relates to whether the intervention and control groups have similar baseline characteristics on average especially those characteristics that may affect the intervention or outcomes. The point of randomized trials is to create groups that are as similar as possible except for the intervention(s) being studied in order to compare the effects of the interventions between groups. When reviewers abstracted baseline characteristics, they noted when there was a significant difference between groups. Baseline characteristics for intervention groups are usually presented in a table in the article (often Table 1).
Groups can differ at baseline without raising red flags if: (1) the differences would not be expected to have any bearing on the interventions and outcomes; or (2) the differences are not statistically significant. When concerned about baseline difference in groups, reviewers recorded them in the comments section and considered them in their overall determination of the study quality.
Questions 7 and 8. Dropout
"Dropouts" in a clinical trial are individuals for whom there are no end point measurements, often because they dropped out of the study and were lost to followup.
Generally, an acceptable overall dropout rate is considered 20 percent or less of participants who were randomized or allocated into each group. An acceptable differential dropout rate is an absolute difference between groups of 15 percentage points at most (calculated by subtracting the dropout rate of one group minus the dropout rate of the other group). However, these are general rates. Lower overall dropout rates are expected in shorter studies, whereas higher overall dropout rates may be acceptable for studies of longer duration. For example, a 6-month study of weight loss interventions should be expected to have nearly 100 percent followup (almost no dropouts–nearly everybody gets their weight measured regardless of whether or not they actually received the intervention), whereas a 10-year study testing the effects of intensive blood pressure lowering on heart attacks may be acceptable if there is a 20-25 percent dropout rate, especially if the dropout rate between groups was similar. The panels for the NHLBI systematic reviews may set different levels of dropout caps.
Conversely, differential dropout rates are not flexible; there should be a 15 percent cap. If there is a differential dropout rate of 15 percent or higher between arms, then there is a serious potential for bias. This constitutes a fatal flaw, resulting in a poor quality rating for the study.
Question 9. Adherence
Did participants in each treatment group adhere to the protocols for assigned interventions? For example, if Group 1 was assigned to 10 mg/day of Drug A, did most of them take 10 mg/day of Drug A? Another example is a study evaluating the difference between a 30-pound weight loss and a 10-pound weight loss on specific clinical outcomes (e.g., heart attacks), but the 30-pound weight loss group did not achieve its intended weight loss target (e.g., the group only lost 14 pounds on average). A third example is whether a large percentage of participants assigned to one group "crossed over" and got the intervention provided to the other group. A final example is when one group that was assigned to receive a particular drug at a particular dose had a large percentage of participants who did not end up taking the drug or the dose as designed in the protocol.
Question 10. Avoid other interventions
Changes that occur in the study outcomes being assessed should be attributable to the interventions being compared in the study. If study participants receive interventions that are not part of the study protocol and could affect the outcomes being assessed, and they receive these interventions differentially, then there is cause for concern because these interventions could bias results. The following scenario is another example of how bias can occur. In a study comparing two different dietary interventions on serum cholesterol, one group had a significantly higher percentage of participants taking statin drugs than the other group. In this situation, it would be impossible to know if a difference in outcome was due to the dietary intervention or the drugs.
Question 11. Outcome measures assessment
What tools or methods were used to measure the outcomes in the study? Were the tools and methods accurate and reliable–for example, have they been validated, or are they objective? This is important as it indicates the confidence you can have in the reported outcomes. Perhaps even more important is ascertaining that outcomes were assessed in the same manner within and between groups. One example of differing methods is self-report of dietary salt intake versus urine testing for sodium content (a more reliable and valid assessment method). Another example is using BP measurements taken by practitioners who use their usual methods versus using BP measurements done by individuals trained in a standard approach. Such an approach may include using the same instrument each time and taking an individual's BP multiple times. In each of these cases, the answer to this assessment question would be "no" for the former scenario and "yes" for the latter. In addition, a study in which an intervention group was seen more frequently than the control group, enabling more opportunities to report clinical events, would not be considered reliable and valid.
Question 12. Power calculation
Generally, a study's methods section will address the sample size needed to detect differences in primary outcomes. The current standard is at least 80 percent power to detect a clinically relevant difference in an outcome using a two-sided alpha of 0.05. Often, however, older studies will not report on power.
Question 13. Prespecified outcomes
Investigators should prespecify outcomes reported in a study for hypothesis testing–which is the reason for conducting an RCT. Without prespecified outcomes, the study may be reporting ad hoc analyses, simply looking for differences supporting desired findings. Investigators also should prespecify subgroups being examined. Most RCTs conduct numerous post hoc analyses as a way of exploring findings and generating additional hypotheses. The intent of this question is to give more weight to reports that are not simply exploratory in nature.
Question 14. Intention-to-treat analysis
Intention-to-treat (ITT) means everybody who was randomized is analyzed according to the original group to which they are assigned. This is an extremely important concept because conducting an ITT analysis preserves the whole reason for doing a randomized trial; that is, to compare groups that differ only in the intervention being tested. When the ITT philosophy is not followed, groups being compared may no longer be the same. In this situation, the study would likely be rated poor. However, if an investigator used another type of analysis that could be viewed as valid, this would be explained in the "other" box on the quality assessment form. Some researchers use a completers analysis (an analysis of only the participants who completed the intervention and the study), which introduces significant potential for bias. Characteristics of participants who do not complete the study are unlikely to be the same as those who do. The likely impact of participants withdrawing from a study treatment must be considered carefully. ITT analysis provides a more conservative (potentially less biased) estimate of effectiveness.
General Guidance for Determining the Overall Quality Rating of Controlled Intervention Studies
The questions on the assessment tool were designed to help reviewers focus on the key concepts for evaluating a study's internal validity. They are not intended to create a list that is simply tallied up to arrive at a summary judgment of quality.
Internal validity is the extent to which the results (effects) reported in a study can truly be attributed to the intervention being evaluated and not to flaws in the design or conduct of the study–in other words, the ability for the study to make causal conclusions about the effects of the intervention being tested. Such flaws can increase the risk of bias. Critical appraisal involves considering the risk of potential for allocation bias, measurement bias, or confounding (the mixture of exposures that one cannot tease out from each other). Examples of confounding include co-interventions, differences at baseline in patient characteristics, and other issues addressed in the questions above. High risk of bias translates to a rating of poor quality. Low risk of bias translates to a rating of good quality.
Fatal flaws: If a study has a "fatal flaw," then risk of bias is significant, and the study is of poor quality. Examples of fatal flaws in RCTs include high dropout rates, high differential dropout rates, no ITT analysis or other unsuitable statistical analysis (e.g., completers-only analysis).
Generally, when evaluating a study, one will not see a "fatal flaw;" however, one will find some risk of bias. During training, reviewers were instructed to look for the potential for bias in studies by focusing on the concepts underlying the questions in the tool. For any box checked "no," reviewers were told to ask: "What is the potential risk of bias that may be introduced by this flaw?" That is, does this factor cause one to doubt the results that were reported in the study?
NHLBI staff provided reviewers with background reading on critical appraisal, while emphasizing that the best approach to use is to think about the questions in the tool in determining the potential for bias in a study. The staff also emphasized that each study has specific nuances; therefore, reviewers should familiarize themselves with the key concepts.
Quality Assessment of Systematic Reviews and Meta-Analyses - Study Quality Assessment Tools
| Criteria | Yes | No | Other (CD, NR, NA)* |
|---|---|---|---|
| 1. Is the review based on a focused question that is adequately formulated and described? | |||
| 2. Were eligibility criteria for included and excluded studies predefined and specified? | |||
| 3. Did the literature search strategy use a comprehensive, systematic approach? | |||
| 4. Were titles, abstracts, and full-text articles dually and independently reviewed for inclusion and exclusion to minimize bias? | |||
| 5. Was the quality of each included study rated independently by two or more reviewers using a standard method to appraise its internal validity? | |||
| 6. Were the included studies listed along with important characteristics and results of each study? | |||
| 7. Was publication bias assessed? | |||
| 8. Was heterogeneity assessed? (This question applies only to meta-analyses.) |
Guidance for Quality Assessment Tool for Systematic Reviews and Meta-Analyses
A systematic review is a study that attempts to answer a question by synthesizing the results of primary studies while using strategies to limit bias and random error.424 These strategies include a comprehensive search of all potentially relevant articles and the use of explicit, reproducible criteria in the selection of articles included in the review. Research designs and study characteristics are appraised, data are synthesized, and results are interpreted using a predefined systematic approach that adheres to evidence-based methodological principles.
Systematic reviews can be qualitative or quantitative. A qualitative systematic review summarizes the results of the primary studies but does not combine the results statistically. A quantitative systematic review, or meta-analysis, is a type of systematic review that employs statistical techniques to combine the results of the different studies into a single pooled estimate of effect, often given as an odds ratio. The guidance document below is organized by question number from the tool for quality assessment of systematic reviews and meta-analyses.
Question 1. Focused question
The review should be based on a question that is clearly stated and well-formulated. An example would be a question that uses the PICO (population, intervention, comparator, outcome) format, with all components clearly described.
Question 2. Eligibility criteria
The eligibility criteria used to determine whether studies were included or excluded should be clearly specified and predefined. It should be clear to the reader why studies were included or excluded.
Question 3. Literature search
The search strategy should employ a comprehensive, systematic approach in order to capture all of the evidence possible that pertains to the question of interest. At a minimum, a comprehensive review has the following attributes:
- Electronic searches were conducted using multiple scientific literature databases, such as MEDLINE, EMBASE, Cochrane Central Register of Controlled Trials, PsychLit, and others as appropriate for the subject matter.
- Manual searches of references found in articles and textbooks should supplement the electronic searches.
Additional search strategies that may be used to improve the yield include the following:
- Studies published in other countries
- Studies published in languages other than English
- Identification by experts in the field of studies and articles that may have been missed
- Search of grey literature, including technical reports and other papers from government agencies or scientific groups or committees; presentations and posters from scientific meetings, conference proceedings, unpublished manuscripts; and others. Searching the grey literature is important (whenever feasible) because sometimes only positive studies with significant findings are published in the peer-reviewed literature, which can bias the results of a review.
In their reviews, researchers described the literature search strategy clearly, and ascertained it could be reproducible by others with similar results.
Question 4. Dual review for determining which studies to include and exclude
Titles, abstracts, and full-text articles (when indicated) should be reviewed by two independent reviewers to determine which studies to include and exclude in the review. Reviewers resolved disagreements through discussion and consensus or with third parties. They clearly stated the review process, including methods for settling disagreements.
Question 5. Quality appraisal for internal validity
Each included study should be appraised for internal validity (study quality assessment) using a standardized approach for rating the quality of the individual studies. Ideally, this should be done by at least two independent reviewers appraised each study for internal validity. However, there is not one commonly accepted, standardized tool for rating the quality of studies. So, in the research papers, reviewers looked for an assessment of the quality of each study and a clear description of the process used.
Question 6. List and describe included studies
All included studies were listed in the review, along with descriptions of their key characteristics. This was presented either in narrative or table format.
Question 7. Publication bias
Publication bias is a term used when studies with positive results have a higher likelihood of being published, being published rapidly, being published in higher impact journals, being published in English, being published more than once, or being cited by others.425,426 Publication bias can be linked to favorable or unfavorable treatment of research findings due to investigators, editors, industry, commercial interests, or peer reviewers. To minimize the potential for publication bias, researchers can conduct a comprehensive literature search that includes the strategies discussed in Question 3.
A funnel plot–a scatter plot of component studies in a meta-analysis–is a commonly used graphical method for detecting publication bias. If there is no significant publication bias, the graph looks like a symmetrical inverted funnel.
Reviewers assessed and clearly described the likelihood of publication bias.
Question 8. Heterogeneity
Heterogeneity is used to describe important differences in studies included in a meta-analysis that may make it inappropriate to combine the studies.427 Heterogeneity can be clinical (e.g., important differences between study participants, baseline disease severity, and interventions); methodological (e.g., important differences in the design and conduct of the study); or statistical (e.g., important differences in the quantitative results or reported effects).
Researchers usually assess clinical or methodological heterogeneity qualitatively by determining whether it makes sense to combine studies. For example:
- Should a study evaluating the effects of an intervention on CVD risk that involves elderly male smokers with hypertension be combined with a study that involves healthy adults ages 18 to 40? (Clinical Heterogeneity)
- Should a study that uses a randomized controlled trial (RCT) design be combined with a study that uses a case-control study design? (Methodological Heterogeneity)
Statistical heterogeneity describes the degree of variation in the effect estimates from a set of studies; it is assessed quantitatively. The two most common methods used to assess statistical heterogeneity are the Q test (also known as the X2 or chi-square test) or I2 test.
Reviewers examined studies to determine if an assessment for heterogeneity was conducted and clearly described. If the studies are found to be heterogeneous, the investigators should explore and explain the causes of the heterogeneity, and determine what influence, if any, the study differences had on overall study results.
Quality Assessment Tool for Observational Cohort and Cross-Sectional Studies - Study Quality Assessment Tools
| Criteria | Yes | No | Other (CD, NR, NA)* |
|---|---|---|---|
| 1. Was the research question or objective in this paper clearly stated? | |||
| 2. Was the study population clearly specified and defined? | |||
| 3. Was the participation rate of eligible persons at least 50%? | |||
| 4. Were all the subjects selected or recruited from the same or similar populations (including the same time period)? Were inclusion and exclusion criteria for being in the study prespecified and applied uniformly to all participants? | |||
| 5. Was a sample size justification, power description, or variance and effect estimates provided? | |||
| 6. For the analyses in this paper, were the exposure(s) of interest measured prior to the outcome(s) being measured? | |||
| 7. Was the timeframe sufficient so that one could reasonably expect to see an association between exposure and outcome if it existed? | |||
| 8. For exposures that can vary in amount or level, did the study examine different levels of the exposure as related to the outcome (e.g., categories of exposure, or exposure measured as continuous variable)? | |||
| 9. Were the exposure measures (independent variables) clearly defined, valid, reliable, and implemented consistently across all study participants? | |||
| 10. Was the exposure(s) assessed more than once over time? | |||
| 11. Were the outcome measures (dependent variables) clearly defined, valid, reliable, and implemented consistently across all study participants? | |||
| 12. Were the outcome assessors blinded to the exposure status of participants? | |||
| 13. Was loss to follow-up after baseline 20% or less? | |||
| 14. Were key potential confounding variables measured and adjusted statistically for their impact on the relationship between exposure(s) and outcome(s)? |
Guidance for Assessing the Quality of Observational Cohort and Cross-Sectional Studies
The guidance document below is organized by question number from the tool for quality assessment of observational cohort and cross-sectional studies.
Question 1. Research question
Did the authors describe their goal in conducting this research? Is it easy to understand what they were looking to find? This issue is important for any scientific paper of any type. Higher quality scientific research explicitly defines a research question.
Questions 2 and 3. Study population
Did the authors describe the group of people from which the study participants were selected or recruited, using demographics, location, and time period? If you were to conduct this study again, would you know who to recruit, from where, and from what time period? Is the cohort population free of the outcomes of interest at the time they were recruited?
An example would be men over 40 years old with type 2 diabetes who began seeking medical care at Phoenix Good Samaritan Hospital between January 1, 1990 and December 31, 1994. In this example, the population is clearly described as: (1) who (men over 40 years old with type 2 diabetes); (2) where (Phoenix Good Samaritan Hospital); and (3) when (between January 1, 1990 and December 31, 1994). Another example is women ages 34 to 59 years of age in 1980 who were in the nursing profession and had no known coronary disease, stroke, cancer, hypercholesterolemia, or diabetes, and were recruited from the 11 most populous States, with contact information obtained from State nursing boards.
In cohort studies, it is crucial that the population at baseline is free of the outcome of interest. For example, the nurses' population above would be an appropriate group in which to study incident coronary disease. This information is usually found either in descriptions of population recruitment, definitions of variables, or inclusion/exclusion criteria.
You may need to look at prior papers on methods in order to make the assessment for this question. Those papers are usually in the reference list.
If fewer than 50% of eligible persons participated in the study, then there is concern that the study population does not adequately represent the target population. This increases the risk of bias.
Question 4. Groups recruited from the same population and uniform eligibility criteria
Were the inclusion and exclusion criteria developed prior to recruitment or selection of the study population? Were the same underlying criteria used for all of the subjects involved? This issue is related to the description of the study population, above, and you may find the information for both of these questions in the same section of the paper.
Most cohort studies begin with the selection of the cohort; participants in this cohort are then measured or evaluated to determine their exposure status. However, some cohort studies may recruit or select exposed participants in a different time or place than unexposed participants, especially retrospective cohort studies–which is when data are obtained from the past (retrospectively), but the analysis examines exposures prior to outcomes. For example, one research question could be whether diabetic men with clinical depression are at higher risk for cardiovascular disease than those without clinical depression. So, diabetic men with depression might be selected from a mental health clinic, while diabetic men without depression might be selected from an internal medicine or endocrinology clinic. This study recruits groups from different clinic populations, so this example would get a "no."
However, the women nurses described in the question above were selected based on the same inclusion/exclusion criteria, so that example would get a "yes."
Question 5. Sample size justification
Did the authors present their reasons for selecting or recruiting the number of people included or analyzed? Do they note or discuss the statistical power of the study? This question is about whether or not the study had enough participants to detect an association if one truly existed.
A paragraph in the methods section of the article may explain the sample size needed to detect a hypothesized difference in outcomes. You may also find a discussion of power in the discussion section (such as the study had 85 percent power to detect a 20 percent increase in the rate of an outcome of interest, with a 2-sided alpha of 0.05). Sometimes estimates of variance and/or estimates of effect size are given, instead of sample size calculations. In any of these cases, the answer would be "yes."
However, observational cohort studies often do not report anything about power or sample sizes because the analyses are exploratory in nature. In this case, the answer would be "no." This is not a "fatal flaw." It just may indicate that attention was not paid to whether the study was sufficiently sized to answer a prespecified question–i.e., it may have been an exploratory, hypothesis-generating study.
Question 6. Exposure assessed prior to outcome measurement
This question is important because, in order to determine whether an exposure causes an outcome, the exposure must come before the outcome.
For some prospective cohort studies, the investigator enrolls the cohort and then determines the exposure status of various members of the cohort (large epidemiological studies like Framingham used this approach). However, for other cohort studies, the cohort is selected based on its exposure status, as in the example above of depressed diabetic men (the exposure being depression). Other examples include a cohort identified by its exposure to fluoridated drinking water and then compared to a cohort living in an area without fluoridated water, or a cohort of military personnel exposed to combat in the Gulf War compared to a cohort of military personnel not deployed in a combat zone.
With either of these types of cohort studies, the cohort is followed forward in time (i.e., prospectively) to assess the outcomes that occurred in the exposed members compared to nonexposed members of the cohort. Therefore, you begin the study in the present by looking at groups that were exposed (or not) to some biological or behavioral factor, intervention, etc., and then you follow them forward in time to examine outcomes. If a cohort study is conducted properly, the answer to this question should be "yes," since the exposure status of members of the cohort was determined at the beginning of the study before the outcomes occurred.
For retrospective cohort studies, the same principal applies. The difference is that, rather than identifying a cohort in the present and following them forward in time, the investigators go back in time (i.e., retrospectively) and select a cohort based on their exposure status in the past and then follow them forward to assess the outcomes that occurred in the exposed and nonexposed cohort members. Because in retrospective cohort studies the exposure and outcomes may have already occurred (it depends on how long they follow the cohort), it is important to make sure that the exposure preceded the outcome.
Sometimes cross-sectional studies are conducted (or cross-sectional analyses of cohort-study data), where the exposures and outcomes are measured during the same timeframe. As a result, cross-sectional analyses provide weaker evidence than regular cohort studies regarding a potential causal relationship between exposures and outcomes. For cross-sectional analyses, the answer to Question 6 should be "no."
Question 7. Sufficient timeframe to see an effect
Did the study allow enough time for a sufficient number of outcomes to occur or be observed, or enough time for an exposure to have a biological effect on an outcome? In the examples given above, if clinical depression has a biological effect on increasing risk for CVD, such an effect may take years. In the other example, if higher dietary sodium increases BP, a short timeframe may be sufficient to assess its association with BP, but a longer timeframe would be needed to examine its association with heart attacks.
The issue of timeframe is important to enable meaningful analysis of the relationships between exposures and outcomes to be conducted. This often requires at least several years, especially when looking at health outcomes, but it depends on the research question and outcomes being examined.
Cross-sectional analyses allow no time to see an effect, since the exposures and outcomes are assessed at the same time, so those would get a "no" response.
Question 8. Different levels of the exposure of interest
If the exposure can be defined as a range (examples: drug dosage, amount of physical activity, amount of sodium consumed), were multiple categories of that exposure assessed? (for example, for drugs: not on the medication, on a low dose, medium dose, high dose; for dietary sodium, higher than average U.S. consumption, lower than recommended consumption, between the two). Sometimes discrete categories of exposure are not used, but instead exposures are measured as continuous variables (for example, mg/day of dietary sodium or BP values).
In any case, studying different levels of exposure (where possible) enables investigators to assess trends or dose-response relationships between exposures and outcomes–e.g., the higher the exposure, the greater the rate of the health outcome. The presence of trends or dose-response relationships lends credibility to the hypothesis of causality between exposure and outcome.
For some exposures, however, this question may not be applicable (e.g., the exposure may be a dichotomous variable like living in a rural setting versus an urban setting, or vaccinated/not vaccinated with a one-time vaccine). If there are only two possible exposures (yes/no), then this question should be given an "NA," and it should not count negatively towards the quality rating.
Question 9. Exposure measures and assessment
Were the exposure measures defined in detail? Were the tools or methods used to measure exposure accurate and reliable–for example, have they been validated or are they objective? This issue is important as it influences confidence in the reported exposures. When exposures are measured with less accuracy or validity, it is harder to see an association between exposure and outcome even if one exists. Also as important is whether the exposures were assessed in the same manner within groups and between groups; if not, bias may result.
For example, retrospective self-report of dietary salt intake is not as valid and reliable as prospectively using a standardized dietary log plus testing participants' urine for sodium content. Another example is measurement of BP, where there may be quite a difference between usual care, where clinicians measure BP however it is done in their practice setting (which can vary considerably), and use of trained BP assessors using standardized equipment (e.g., the same BP device which has been tested and calibrated) and a standardized protocol (e.g., patient is seated for 5 minutes with feet flat on the floor, BP is taken twice in each arm, and all four measurements are averaged). In each of these cases, the former would get a "no" and the latter a "yes."
Here is a final example that illustrates the point about why it is important to assess exposures consistently across all groups: If people with higher BP (exposed cohort) are seen by their providers more frequently than those without elevated BP (nonexposed group), it also increases the chances of detecting and documenting changes in health outcomes, including CVD-related events. Therefore, it may lead to the conclusion that higher BP leads to more CVD events. This may be true, but it could also be due to the fact that the subjects with higher BP were seen more often; thus, more CVD-related events were detected and documented simply because they had more encounters with the health care system. Thus, it could bias the results and lead to an erroneous conclusion.
Question 10. Repeated exposure assessment
Was the exposure for each person measured more than once during the course of the study period? Multiple measurements with the same result increase our confidence that the exposure status was correctly classified. Also, multiple measurements enable investigators to look at changes in exposure over time, for example, people who ate high dietary sodium throughout the followup period, compared to those who started out high then reduced their intake, compared to those who ate low sodium throughout. Once again, this may not be applicable in all cases. In many older studies, exposure was measured only at baseline. However, multiple exposure measurements do result in a stronger study design.
Question 11. Outcome measures
Were the outcomes defined in detail? Were the tools or methods for measuring outcomes accurate and reliable–for example, have they been validated or are they objective? This issue is important because it influences confidence in the validity of study results. Also important is whether the outcomes were assessed in the same manner within groups and between groups.
An example of an outcome measure that is objective, accurate, and reliable is death–the outcome measured with more accuracy than any other. But even with a measure as objective as death, there can be differences in the accuracy and reliability of how death was assessed by the investigators. Did they base it on an autopsy report, death certificate, death registry, or report from a family member? Another example is a study of whether dietary fat intake is related to blood cholesterol level (cholesterol level being the outcome), and the cholesterol level is measured from fasting blood samples that are all sent to the same laboratory. These examples would get a "yes." An example of a "no" would be self-report by subjects that they had a heart attack, or self-report of how much they weigh (if body weight is the outcome of interest).
Similar to the example in Question 9, results may be biased if one group (e.g., people with high BP) is seen more frequently than another group (people with normal BP) because more frequent encounters with the health care system increases the chances of outcomes being detected and documented.
Question 12. Blinding of outcome assessors
Blinding means that outcome assessors did not know whether the participant was exposed or unexposed. It is also sometimes called "masking." The objective is to look for evidence in the article that the person(s) assessing the outcome(s) for the study (for example, examining medical records to determine the outcomes that occurred in the exposed and comparison groups) is masked to the exposure status of the participant. Sometimes the person measuring the exposure is the same person conducting the outcome assessment. In this case, the outcome assessor would most likely not be blinded to exposure status because they also took measurements of exposures. If so, make a note of that in the comments section.
As you assess this criterion, think about whether it is likely that the person(s) doing the outcome assessment would know (or be able to figure out) the exposure status of the study participants. If the answer is no, then blinding is adequate. An example of adequate blinding of the outcome assessors is to create a separate committee, whose members were not involved in the care of the patient and had no information about the study participants' exposure status. The committee would then be provided with copies of participants' medical records, which had been stripped of any potential exposure information or personally identifiable information. The committee would then review the records for prespecified outcomes according to the study protocol. If blinding was not possible, which is sometimes the case, mark "NA" and explain the potential for bias.
Question 13. Followup rate
Higher overall followup rates are always better than lower followup rates, even though higher rates are expected in shorter studies, whereas lower overall followup rates are often seen in studies of longer duration. Usually, an acceptable overall followup rate is considered 80 percent or more of participants whose exposures were measured at baseline. However, this is just a general guideline. For example, a 6-month cohort study examining the relationship between dietary sodium intake and BP level may have over 90 percent followup, but a 20-year cohort study examining effects of sodium intake on stroke may have only a 65 percent followup rate.
Question 14. Statistical analyses
Were key potential confounding variables measured and adjusted for, such as by statistical adjustment for baseline differences? Logistic regression or other regression methods are often used to account for the influence of variables not of interest.
This is a key issue in cohort studies, because statistical analyses need to control for potential confounders, in contrast to an RCT, where the randomization process controls for potential confounders. All key factors that may be associated both with the exposure of interest and the outcome–that are not of interest to the research question–should be controlled for in the analyses.
For example, in a study of the relationship between cardiorespiratory fitness and CVD events (heart attacks and strokes), the study should control for age, BP, blood cholesterol, and body weight, because all of these factors are associated both with low fitness and with CVD events. Well-done cohort studies control for multiple potential confounders.
Some general guidance for determining the overall quality rating of observational cohort and cross-sectional studies
The questions on the form are designed to help you focus on the key concepts for evaluating the internal validity of a study. They are not intended to create a list that you simply tally up to arrive at a summary judgment of quality.
Internal validity for cohort studies is the extent to which the results reported in the study can truly be attributed to the exposure being evaluated and not to flaws in the design or conduct of the study–in other words, the ability of the study to draw associative conclusions about the effects of the exposures being studied on outcomes. Any such flaws can increase the risk of bias.
Critical appraisal involves considering the risk of potential for selection bias, information bias, measurement bias, or confounding (the mixture of exposures that one cannot tease out from each other). Examples of confounding include co-interventions, differences at baseline in patient characteristics, and other issues throughout the questions above. High risk of bias translates to a rating of poor quality. Low risk of bias translates to a rating of good quality. (Thus, the greater the risk of bias, the lower the quality rating of the study.)
In addition, the more attention in the study design to issues that can help determine whether there is a causal relationship between the exposure and outcome, the higher quality the study. These include exposures occurring prior to outcomes, evaluation of a dose-response gradient, accuracy of measurement of both exposure and outcome, sufficient timeframe to see an effect, and appropriate control for confounding–all concepts reflected in the tool.
Generally, when you evaluate a study, you will not see a "fatal flaw," but you will find some risk of bias. By focusing on the concepts underlying the questions in the quality assessment tool, you should ask yourself about the potential for bias in the study you are critically appraising. For any box where you check "no" you should ask, "What is the potential risk of bias resulting from this flaw in study design or execution?" That is, does this factor cause you to doubt the results that are reported in the study or doubt the ability of the study to accurately assess an association between exposure and outcome?
The best approach is to think about the questions in the tool and how each one tells you something about the potential for bias in a study. The more you familiarize yourself with the key concepts, the more comfortable you will be with critical appraisal. Examples of studies rated good, fair, and poor are useful, but each study must be assessed on its own based on the details that are reported and consideration of the concepts for minimizing bias.
Quality Assessment of Case-Control Studies - Study Quality Assessment Tools
| Criteria | Yes | No | Other (CD, NR, NA)* |
|---|---|---|---|
| 1. Was the research question or objective in this paper clearly stated and appropriate? | |||
| 2. Was the study population clearly specified and defined? | |||
| 3. Did the authors include a sample size justification? | |||
| 4. Were controls selected or recruited from the same or similar population that gave rise to the cases (including the same timeframe)? | |||
| 5. Were the definitions, inclusion and exclusion criteria, algorithms or processes used to identify or select cases and controls valid, reliable, and implemented consistently across all study participants? | |||
| 6. Were the cases clearly defined and differentiated from controls? | |||
| 7. If less than 100 percent of eligible cases and/or controls were selected for the study, were the cases and/or controls randomly selected from those eligible? | |||
| 8. Was there use of concurrent controls? | |||
| 9. Were the investigators able to confirm that the exposure/risk occurred prior to the development of the condition or event that defined a participant as a case? | |||
| 10. Were the measures of exposure/risk clearly defined, valid, reliable, and implemented consistently (including the same time period) across all study participants? | |||
| 11. Were the assessors of exposure/risk blinded to the case or control status of participants? | |||
| 12. Were key potential confounding variables measured and adjusted statistically in the analyses? If matching was used, did the investigators account for matching during study analysis? |
| Quality Rating ( |
|---|
| Rater #1 Initials: |
| Rater #2 Initials: |
| Additional Comments (If POOR, please state why): |
Guidance for Assessing the Quality of Case-Control Studies
The guidance document below is organized by question number from the tool for quality assessment of case-control studies.
Did the authors describe their goal in conducting this research? Is it easy to understand what they were looking to find? This issue is important for any scientific paper of any type. High quality scientific research explicitly defines a research question.
Question 2. Study population
Did the authors describe the group of individuals from which the cases and controls were selected or recruited, while using demographics, location, and time period? If the investigators conducted this study again, would they know exactly who to recruit, from where, and from what time period?
Investigators identify case-control study populations by location, time period, and inclusion criteria for cases (individuals with the disease, condition, or problem) and controls (individuals without the disease, condition, or problem). For example, the population for a study of lung cancer and chemical exposure would be all incident cases of lung cancer diagnosed in patients ages 35 to 79, from January 1, 2003 to December 31, 2008, living in Texas during that entire time period, as well as controls without lung cancer recruited from the same population during the same time period. The population is clearly described as: (1) who (men and women ages 35 to 79 with (cases) and without (controls) incident lung cancer); (2) where (living in Texas); and (3) when (between January 1, 2003 and December 31, 2008).
Other studies may use disease registries or data from cohort studies to identify cases. In these cases, the populations are individuals who live in the area covered by the disease registry or included in a cohort study (i.e., nested case-control or case-cohort). For example, a study of the relationship between vitamin D intake and myocardial infarction might use patients identified via the GRACE registry, a database of heart attack patients.
NHLBI staff encouraged reviewers to examine prior papers on methods (listed in the reference list) to make this assessment, if necessary.
Question 3. Target population and case representation
In order for a study to truly address the research question, the target population–the population from which the study population is drawn and to which study results are believed to apply–should be carefully defined. Some authors may compare characteristics of the study cases to characteristics of cases in the target population, either in text or in a table. When study cases are shown to be representative of cases in the appropriate target population, it increases the likelihood that the study was well-designed per the research question.
However, because these statistics are frequently difficult or impossible to measure, publications should not be penalized if case representation is not shown. For most papers, the response to question 3 will be "NR." Those subquestions are combined because the answer to the second subquestion–case representation–determines the response to this item. However, it cannot be determined without considering the response to the first subquestion. For example, if the answer to the first subquestion is "yes," and the second, "CD," then the response for item 3 is "CD."
Question 4. Sample size justification
Did the authors discuss their reasons for selecting or recruiting the number of individuals included? Did they discuss the statistical power of the study and provide a sample size calculation to ensure that the study is adequately powered to detect an association (if one exists)? This question does not refer to a description of the manner in which different groups were included or excluded using the inclusion/exclusion criteria (e.g., "Final study size was 1,378 participants after exclusion of 461 patients with missing data" is not considered a sample size justification for the purposes of this question).
An article's methods section usually contains information on sample size and the size needed to detect differences in exposures and on statistical power.
Question 5. Groups recruited from the same population
To determine whether cases and controls were recruited from the same population, one can ask hypothetically, "If a control was to develop the outcome of interest (the condition that was used to select cases), would that person have been eligible to become a case?" Case-control studies begin with the selection of the cases (those with the outcome of interest, e.g., lung cancer) and controls (those in whom the outcome is absent). Cases and controls are then evaluated and categorized by their exposure status. For the lung cancer example, cases and controls were recruited from hospitals in a given region. One may reasonably assume that controls in the catchment area for the hospitals, or those already in the hospitals for a different reason, would attend those hospitals if they became a case; therefore, the controls are drawn from the same population as the cases. If the controls were recruited or selected from a different region (e.g., a State other than Texas) or time period (e.g., 1991-2000), then the cases and controls were recruited from different populations, and the answer to this question would be "no."
The following example further explores selection of controls. In a study, eligible cases were men and women, ages 18 to 39, who were diagnosed with atherosclerosis at hospitals in Perth, Australia, between July 1, 2000 and December 31, 2007. Appropriate controls for these cases might be sampled using voter registration information for men and women ages 18 to 39, living in Perth (population-based controls); they also could be sampled from patients without atherosclerosis at the same hospitals (hospital-based controls). As long as the controls are individuals who would have been eligible to be included in the study as cases (if they had been diagnosed with atherosclerosis), then the controls were selected appropriately from the same source population as cases.
In a prospective case-control study, investigators may enroll individuals as cases at the time they are found to have the outcome of interest; the number of cases usually increases as time progresses. At this same time, they may recruit or select controls from the population without the outcome of interest. One way to identify or recruit cases is through a surveillance system. In turn, investigators can select controls from the population covered by that system. This is an example of population-based controls. Investigators also may identify and select cases from a cohort study population and identify controls from outcome-free individuals in the same cohort study. This is known as a nested case-control study.
Question 6. Inclusion and exclusion criteria prespecified and applied uniformly
Were the inclusion and exclusion criteria developed prior to recruitment or selection of the study population? Were the same underlying criteria used for all of the groups involved? To answer this question, reviewers determined if the investigators developed I/E criteria prior to recruitment or selection of the study population and if they used the same underlying criteria for all groups. The investigators should have used the same selection criteria, except for study participants who had the disease or condition, which would be different for cases and controls by definition. Therefore, the investigators use the same age (or age range), gender, race, and other characteristics to select cases and controls. Information on this topic is usually found in a paper's section on the description of the study population.
Question 7. Case and control definitions
For this question, reviewers looked for descriptions of the validity of case and control definitions and processes or tools used to identify study participants as such. Was a specific description of "case" and "control" provided? Is there a discussion of the validity of the case and control definitions and the processes or tools used to identify study participants as such? They determined if the tools or methods were accurate, reliable, and objective. For example, cases might be identified as "adult patients admitted to a VA hospital from January 1, 2000 to December 31, 2009, with an ICD-9 discharge diagnosis code of acute myocardial infarction and at least one of the two confirmatory findings in their medical records: at least 2mm of ST elevation changes in two or more ECG leads and an elevated troponin level. Investigators might also use ICD-9 or CPT codes to identify patients. All cases should be identified using the same methods. Unless the distinction between cases and controls is accurate and reliable, investigators cannot use study results to draw valid conclusions.
Question 8. Random selection of study participants
If a case-control study did not use 100 percent of eligible cases and/or controls (e.g., not all disease-free participants were included as controls), did the authors indicate that random sampling was used to select controls? When it is possible to identify the source population fairly explicitly (e.g., in a nested case-control study, or in a registry-based study), then random sampling of controls is preferred. When investigators used consecutive sampling, which is frequently done for cases in prospective studies, then study participants are not considered randomly selected. In this case, the reviewers would answer "no" to Question 8. However, this would not be considered a fatal flaw.
If investigators included all eligible cases and controls as study participants, then reviewers marked "NA" in the tool. If 100 percent of cases were included (e.g., NA for cases) but only 50 percent of eligible controls, then the response would be "yes" if the controls were randomly selected, and "no" if they were not. If this cannot be determined, the appropriate response is "CD."
Question 9. Concurrent controls
A concurrent control is a control selected at the time another person became a case, usually on the same day. This means that one or more controls are recruited or selected from the population without the outcome of interest at the time a case is diagnosed. Investigators can use this method in both prospective case-control studies and retrospective case-control studies. For example, in a retrospective study of adenocarcinoma of the colon using data from hospital records, if hospital records indicate that Person A was diagnosed with adenocarcinoma of the colon on June 22, 2002, then investigators would select one or more controls from the population of patients without adenocarcinoma of the colon on that same day. This assumes they conducted the study retrospectively, using data from hospital records. The investigators could have also conducted this study using patient records from a cohort study, in which case it would be a nested case-control study.
Investigators can use concurrent controls in the presence or absence of matching and vice versa. A study that uses matching does not necessarily mean that concurrent controls were used.
Question 10. Exposure assessed prior to outcome measurement
Investigators first determine case or control status (based on presence or absence of outcome of interest), and then assess exposure history of the case or control; therefore, reviewers ascertained that the exposure preceded the outcome. For example, if the investigators used tissue samples to determine exposure, did they collect them from patients prior to their diagnosis? If hospital records were used, did investigators verify that the date a patient was exposed (e.g., received medication for atherosclerosis) occurred prior to the date they became a case (e.g., was diagnosed with type 2 diabetes)? For an association between an exposure and an outcome to be considered causal, the exposure must have occurred prior to the outcome.
Question 11. Exposure measures and assessment
Were the exposure measures defined in detail? Were the tools or methods used to measure exposure accurate and reliable–for example, have they been validated or are they objective? This is important, as it influences confidence in the reported exposures. Equally important is whether the exposures were assessed in the same manner within groups and between groups. This question pertains to bias resulting from exposure misclassification (i.e., exposure ascertainment).
For example, a retrospective self-report of dietary salt intake is not as valid and reliable as prospectively using a standardized dietary log plus testing participants' urine for sodium content because participants' retrospective recall of dietary salt intake may be inaccurate and result in misclassification of exposure status. Similarly, BP results from practices that use an established protocol for measuring BP would be considered more valid and reliable than results from practices that did not use standard protocols. A protocol may include using trained BP assessors, standardized equipment (e.g., the same BP device which has been tested and calibrated), and a standardized procedure (e.g., patient is seated for 5 minutes with feet flat on the floor, BP is taken twice in each arm, and all four measurements are averaged).
Question 12. Blinding of exposure assessors
Blinding or masking means that outcome assessors did not know whether participants were exposed or unexposed. To answer this question, reviewers examined articles for evidence that the outcome assessor(s) was masked to the exposure status of the research participants. An outcome assessor, for example, may examine medical records to determine the outcomes that occurred in the exposed and comparison groups. Sometimes the person measuring the exposure is the same person conducting the outcome assessment. In this case, the outcome assessor would most likely not be blinded to exposure status. A reviewer would note such a finding in the comments section of the assessment tool.
One way to ensure good blinding of exposure assessment is to have a separate committee, whose members have no information about the study participants' status as cases or controls, review research participants' records. To help answer the question above, reviewers determined if it was likely that the outcome assessor knew whether the study participant was a case or control. If it was unlikely, then the reviewers marked "no" to Question 12. Outcome assessors who used medical records to assess exposure should not have been directly involved in the study participants' care, since they probably would have known about their patients' conditions. If the medical records contained information on the patient's condition that identified him/her as a case (which is likely), that information would have had to be removed before the exposure assessors reviewed the records.
If blinding was not possible, which sometimes happens, the reviewers marked "NA" in the assessment tool and explained the potential for bias.
Question 13. Statistical analysis
Were key potential confounding variables measured and adjusted for, such as by statistical adjustment for baseline differences? Investigators often use logistic regression or other regression methods to account for the influence of variables not of interest.
This is a key issue in case-controlled studies; statistical analyses need to control for potential confounders, in contrast to RCTs in which the randomization process controls for potential confounders. In the analysis, investigators need to control for all key factors that may be associated with both the exposure of interest and the outcome and are not of interest to the research question.
A study of the relationship between smoking and CVD events illustrates this point. Such a study needs to control for age, gender, and body weight; all are associated with smoking and CVD events. Well-done case-control studies control for multiple potential confounders.
Matching is a technique used to improve study efficiency and control for known confounders. For example, in the study of smoking and CVD events, an investigator might identify cases that have had a heart attack or stroke and then select controls of similar age, gender, and body weight to the cases. For case-control studies, it is important that if matching was performed during the selection or recruitment process, the variables used as matching criteria (e.g., age, gender, race) should be controlled for in the analysis.
General Guidance for Determining the Overall Quality Rating of Case-Controlled Studies
NHLBI designed the questions in the assessment tool to help reviewers focus on the key concepts for evaluating a study's internal validity, not to use as a list from which to add up items to judge a study's quality.
Internal validity for case-control studies is the extent to which the associations between disease and exposure reported in the study can truly be attributed to the exposure being evaluated rather than to flaws in the design or conduct of the study. In other words, what is ability of the study to draw associative conclusions about the effects of the exposures on outcomes? Any such flaws can increase the risk of bias.
In critical appraising a study, the following factors need to be considered: risk of potential for selection bias, information bias, measurement bias, or confounding (the mixture of exposures that one cannot tease out from each other). Examples of confounding include co-interventions, differences at baseline in patient characteristics, and other issues addressed in the questions above. High risk of bias translates to a poor quality rating; low risk of bias translates to a good quality rating. Again, the greater the risk of bias, the lower the quality rating of the study.
In addition, the more attention in the study design to issues that can help determine whether there is a causal relationship between the outcome and the exposure, the higher the quality of the study. These include exposures occurring prior to outcomes, evaluation of a dose-response gradient, accuracy of measurement of both exposure and outcome, sufficient timeframe to see an effect, and appropriate control for confounding–all concepts reflected in the tool.
If a study has a "fatal flaw," then risk of bias is significant; therefore, the study is deemed to be of poor quality. An example of a fatal flaw in case-control studies is a lack of a consistent standard process used to identify cases and controls.
Generally, when reviewers evaluated a study, they did not see a "fatal flaw," but instead found some risk of bias. By focusing on the concepts underlying the questions in the quality assessment tool, reviewers examined the potential for bias in the study. For any box checked "no," reviewers asked, "What is the potential risk of bias resulting from this flaw in study design or execution?" That is, did this factor lead to doubt about the results reported in the study or the ability of the study to accurately assess an association between exposure and outcome?
By examining questions in the assessment tool, reviewers were best able to assess the potential for bias in a study. Specific rules were not useful, as each study had specific nuances. In addition, being familiar with the key concepts helped reviewers assess the studies. Examples of studies rated good, fair, and poor were useful, yet each study had to be assessed on its own.
Quality Assessment Tool for Before-After (Pre-Post) Studies With No Control Group - Study Quality Assessment Tools
| Criteria | Yes | No | Other |
|---|---|---|---|
| 1. Was the study question or objective clearly stated? | |||
| 2. Were eligibility/selection criteria for the study population prespecified and clearly described? | |||
| 3. Were the participants in the study representative of those who would be eligible for the test/service/intervention in the general or clinical population of interest? | |||
| 4. Were all eligible participants that met the prespecified entry criteria enrolled? | |||
| 5. Was the sample size sufficiently large to provide confidence in the findings? | |||
| 6. Was the test/service/intervention clearly described and delivered consistently across the study population? | |||
| 7. Were the outcome measures prespecified, clearly defined, valid, reliable, and assessed consistently across all study participants? | |||
| 8. Were the people assessing the outcomes blinded to the participants' exposures/interventions? | |||
| 9. Was the loss to follow-up after baseline 20% or less? Were those lost to follow-up accounted for in the analysis? | |||
| 10. Did the statistical methods examine changes in outcome measures from before to after the intervention? Were statistical tests done that provided p values for the pre-to-post changes? | |||
| 11. Were outcome measures of interest taken multiple times before the intervention and multiple times after the intervention (i.e., did they use an interrupted time-series design)? | |||
| 12. If the intervention was conducted at a group level (e.g., a whole hospital, a community, etc.) did the statistical analysis take into account the use of individual-level data to determine effects at the group level? |
Guidance for Assessing the Quality of Before-After (Pre-Post) Studies With No Control Group
Question 1. Study question
Question 2. Eligibility criteria and study population
Did the authors describe the eligibility criteria applied to the individuals from whom the study participants were selected or recruited? In other words, if the investigators were to conduct this study again, would they know whom to recruit, from where, and from what time period?
Here is a sample description of a study population: men over age 40 with type 2 diabetes, who began seeking medical care at Phoenix Good Samaritan Hospital, between January 1, 2005 and December 31, 2007. The population is clearly described as: (1) who (men over age 40 with type 2 diabetes); (2) where (Phoenix Good Samaritan Hospital); and (3) when (between January 1, 2005 and December 31, 2007). Another sample description is women who were in the nursing profession, who were ages 34 to 59 in 1995, had no known CHD, stroke, cancer, hypercholesterolemia, or diabetes, and were recruited from the 11 most populous States, with contact information obtained from State nursing boards.
To assess this question, reviewers examined prior papers on study methods (listed in reference list) when necessary.
Question 3. Study participants representative of clinical populations of interest
The participants in the study should be generally representative of the population in which the intervention will be broadly applied. Studies on small demographic subgroups may raise concerns about how the intervention will affect broader populations of interest. For example, interventions that focus on very young or very old individuals may affect middle-aged adults differently. Similarly, researchers may not be able to extrapolate study results from patients with severe chronic diseases to healthy populations.
Question 4. All eligible participants enrolled
To further explore this question, reviewers may need to ask: Did the investigators develop the I/E criteria prior to recruiting or selecting study participants? Were the same underlying I/E criteria used for all research participants? Were all subjects who met the I/E criteria enrolled in the study?
Question 5. Sample size
Did the authors present their reasons for selecting or recruiting the number of individuals included or analyzed? Did they note or discuss the statistical power of the study? This question addresses whether there was a sufficient sample size to detect an association, if one did exist.
An article's methods section may provide information on the sample size needed to detect a hypothesized difference in outcomes and a discussion on statistical power (such as, the study had 85 percent power to detect a 20 percent increase in the rate of an outcome of interest, with a 2-sided alpha of 0.05). Sometimes estimates of variance and/or estimates of effect size are given, instead of sample size calculations. In any case, if the reviewers determined that the power was sufficient to detect the effects of interest, then they would answer "yes" to Question 5.
Question 6. Intervention clearly described
Another pertinent question regarding interventions is: Was the intervention clearly defined in detail in the study? Did the authors indicate that the intervention was consistently applied to the subjects? Did the research participants have a high level of adherence to the requirements of the intervention? For example, if the investigators assigned a group to 10 mg/day of Drug A, did most participants in this group take the specific dosage of Drug A? Or did a large percentage of participants end up not taking the specific dose of Drug A indicated in the study protocol?
Reviewers ascertained that changes in study outcomes could be attributed to study interventions. If participants received interventions that were not part of the study protocol and could affect the outcomes being assessed, the results could be biased.
Question 7. Outcome measures clearly described, valid, and reliable
Were the outcomes defined in detail? Were the tools or methods for measuring outcomes accurate and reliable–for example, have they been validated or are they objective? This question is important because the answer influences confidence in the validity of study results.
An example of an outcome measure that is objective, accurate, and reliable is death–the outcome measured with more accuracy than any other. But even with a measure as objective as death, differences can exist in the accuracy and reliability of how investigators assessed death. For example, did they base it on an autopsy report, death certificate, death registry, or report from a family member? Another example of a valid study is one whose objective is to determine if dietary fat intake affects blood cholesterol level (cholesterol level being the outcome) and in which the cholesterol level is measured from fasting blood samples that are all sent to the same laboratory. These examples would get a "yes."
An example of a "no" would be self-report by subjects that they had a heart attack, or self-report of how much they weight (if body weight is the outcome of interest).
Question 8. Blinding of outcome assessors
Blinding or masking means that the outcome assessors did not know whether the participants received the intervention or were exposed to the factor under study. To answer the question above, the reviewers examined articles for evidence that the person(s) assessing the outcome(s) was masked to the participants' intervention or exposure status. An outcome assessor, for example, may examine medical records to determine the outcomes that occurred in the exposed and comparison groups. Sometimes the person applying the intervention or measuring the exposure is the same person conducting the outcome assessment. In this case, the outcome assessor would not likely be blinded to the intervention or exposure status. A reviewer would note such a finding in the comments section of the assessment tool.
In assessing this criterion, the reviewers determined whether it was likely that the person(s) conducting the outcome assessment knew the exposure status of the study participants. If not, then blinding was adequate. An example of adequate blinding of the outcome assessors is to create a separate committee whose members were not involved in the care of the patient and had no information about the study participants' exposure status. Using a study protocol, committee members would review copies of participants' medical records, which would be stripped of any potential exposure information or personally identifiable information, for prespecified outcomes.
Question 9. Followup rate
Higher overall followup rates are always desirable to lower followup rates, although higher rates are expected in shorter studies, and lower overall followup rates are often seen in longer studies. Usually an acceptable overall followup rate is considered 80 percent or more of participants whose interventions or exposures were measured at baseline. However, this is a general guideline.
In accounting for those lost to followup, in the analysis, investigators may have imputed values of the outcome for those lost to followup or used other methods. For example, they may carry forward the baseline value or the last observed value of the outcome measure and use these as imputed values for the final outcome measure for research participants lost to followup.
Question 10. Statistical analysis
Were formal statistical tests used to assess the significance of the changes in the outcome measures between the before and after time periods? The reported study results should present values for statistical tests, such as p values, to document the statistical significance (or lack thereof) for the changes in the outcome measures found in the study.
Question 11. Multiple outcome measures
Were the outcome measures for each person measured more than once during the course of the before and after study periods? Multiple measurements with the same result increase confidence that the outcomes were accurately measured.
Question 12. Group-level interventions and individual-level outcome efforts
Group-level interventions are usually not relevant for clinical interventions such as bariatric surgery, in which the interventions are applied at the individual patient level. In those cases, the questions were coded as "NA" in the assessment tool.
General Guidance for Determining the Overall Quality Rating of Before-After Studies
The questions in the quality assessment tool were designed to help reviewers focus on the key concepts for evaluating the internal validity of a study. They are not intended to create a list from which to add up items to judge a study's quality.
Internal validity is the extent to which the outcome results reported in the study can truly be attributed to the intervention or exposure being evaluated, and not to biases, measurement errors, or other confounding factors that may result from flaws in the design or conduct of the study. In other words, what is the ability of the study to draw associative conclusions about the effects of the interventions or exposures on outcomes?
Critical appraisal of a study involves considering the risk of potential for selection bias, information bias, measurement bias, or confounding (the mixture of exposures that one cannot tease out from each other). Examples of confounding include co-interventions, differences at baseline in patient characteristics, and other issues throughout the questions above. High risk of bias translates to a rating of poor quality; low risk of bias translates to a rating of good quality. Again, the greater the risk of bias, the lower the quality rating of the study.
In addition, the more attention in the study design to issues that can help determine if there is a causal relationship between the exposure and outcome, the higher quality the study. These issues include exposures occurring prior to outcomes, evaluation of a dose-response gradient, accuracy of measurement of both exposure and outcome, and sufficient timeframe to see an effect.
Generally, when reviewers evaluate a study, they will not see a "fatal flaw," but instead will find some risk of bias. By focusing on the concepts underlying the questions in the quality assessment tool, reviewers should ask themselves about the potential for bias in the study they are critically appraising. For any box checked "no" reviewers should ask, "What is the potential risk of bias resulting from this flaw in study design or execution?" That is, does this factor lead to doubt about the results reported in the study or doubt about the ability of the study to accurately assess an association between the intervention or exposure and the outcome?
The best approach is to think about the questions in the assessment tool and how each one reveals something about the potential for bias in a study. Specific rules are not useful, as each study has specific nuances. In addition, being familiar with the key concepts will help reviewers be more comfortable with critical appraisal. Examples of studies rated good, fair, and poor are useful, but each study must be assessed on its own.
Quality Assessment Tool for Case Series Studies - Study Quality Assessment Tools
| Criteria | Yes | No | Other |
|---|---|---|---|
| 1. Was the study question or objective clearly stated? | |||
| 2. Was the study population clearly and fully described, including a case definition? | |||
| 3. Were the cases consecutive? | |||
| 4. Were the subjects comparable? | |||
| 5. Was the intervention clearly described? | |||
| 6. Were the outcome measures clearly defined, valid, reliable, and implemented consistently across all study participants? | |||
| 7. Was the length of follow-up adequate? | |||
| 8. Were the statistical methods well-described? | |||
| 9. Were the results well-described? |
Background: Development and Use - Study Quality Assessment Tools
Learn more about the development and use of Study Quality Assessment Tools.
Last updated: July, 2021
Sign up for the newsletter
Digital editions.

Total quality management: three case studies from around the world
With organisations to run and big orders to fill, it’s easy to see how some ceos inadvertently sacrifice quality for quantity. by integrating a system of total quality management it’s possible to have both.

Top 5 ways to manage the board during turbulent times Top 5 ways to create a family-friendly work culture Top 5 tips for a successful joint venture Top 5 ways managers can support ethnic minority workers Top 5 ways to encourage gender diversity in the workplace Top 5 ways CEOs can create an ethical company culture Top 5 tips for going into business with your spouse Top 5 ways to promote a healthy workforce Top 5 ways to survive a recession Top 5 tips for avoiding the ‘conference vortex’ Top 5 ways to maximise new parents’ work-life balance with technology Top 5 ways to build psychological safety in the workplace Top 5 ways to prepare your workforce for the AI revolution Top 5 ways to tackle innovation stress in the workplace Top 5 tips for recruiting Millennials
There are few boardrooms in the world whose inhabitants don’t salivate at the thought of engaging in a little aggressive expansion. After all, there’s little room in a contemporary, fast-paced business environment for any firm whose leaders don’t subscribe to ambitions of bigger factories, healthier accounts and stronger turnarounds. Yet too often such tales of excess go hand-in-hand with complaints of a severe drop in quality.
Food and entertainment markets are riddled with cautionary tales, but service sectors such as health and education aren’t immune to the disappointing by-products of unsustainable growth either. As always, the first steps in avoiding a catastrophic forsaking of quality begins with good management.
There are plenty of methods and models geared at managing the quality of a particular company’s goods or services. Yet very few of those models take into consideration the widely held belief that any company is only as strong as its weakest link. With that in mind, management consultant William Deming developed an entirely new set of methods with which to address quality.
Deming, whose managerial work revolutionised the titanic Japanese manufacturing industry, perceived quality management to be more of a philosophy than anything else. Top-to-bottom improvement, he reckoned, required uninterrupted participation of all key employees and stakeholders. Thus, the total quality management (TQM) approach was born.
All in Similar to the Six Sigma improvement process, TQM ensures long-term success by enforcing all-encompassing internal guidelines and process standards to reduce errors. By way of serious, in-depth auditing – as well as some well-orchestrated soul-searching – TQM ensures firms meet stakeholder needs and expectations efficiently and effectively, without forsaking ethical values.
By opting to reframe the way employees think about the company’s goals and processes, TQM allows CEOs to make sure certain things are done right from day one. According to Teresa Whitacre, of international consulting firm ASQ , proper quality management also boosts a company’s profitability.
“Total quality management allows the company to look at their management system as a whole entity — not just an output of the quality department,” she says. “Total quality means the organisation looks at all inputs, human resources, engineering, production, service, distribution, sales, finance, all functions, and their impact on the quality of all products or services of the organisation. TQM can improve a company’s processes and bottom line.”
Embracing the entire process sees companies strive to improve in several core areas, including: customer focus, total employee involvement, process-centred thinking, systematic approaches, good communication and leadership and integrated systems. Yet Whitacre is quick to point out that companies stand to gain very little from TQM unless they’re willing to go all-in.
“Companies need to consider the inputs of each department and determine which inputs relate to its governance system. Then, the company needs to look at the same inputs and determine if those inputs are yielding the desired results,” she says. “For example, ISO 9001 requires management reviews occur at least annually. Aside from minimum standard requirements, the company is free to review what they feel is best for them. While implementing TQM, they can add to their management review the most critical metrics for their business, such as customer complaints, returns, cost of products, and more.”
The customer knows best: AtlantiCare TQM isn’t an easy management strategy to introduce into a business; in fact, many attempts tend to fall flat. More often than not, it’s because firms maintain natural barriers to full involvement. Middle managers, for example, tend to complain their authority is being challenged when boots on the ground are encouraged to speak up in the early stages of TQM. Yet in a culture of constant quality enhancement, the views of any given workforce are invaluable.
AtlantiCare in numbers
5,000 Employees
$280m Profits before quality improvement strategy was implemented
$650m Profits after quality improvement strategy
One firm that’s proven the merit of TQM is New Jersey-based healthcare provider AtlantiCare . Managing 5,000 employees at 25 locations, AtlantiCare is a serious business that’s boasted a respectable turnaround for nearly two decades. Yet in order to increase that margin further still, managers wanted to implement improvements across the board. Because patient satisfaction is the single-most important aspect of the healthcare industry, engaging in a renewed campaign of TQM proved a natural fit. The firm chose to adopt a ‘plan-do-check-act’ cycle, revealing gaps in staff communication – which subsequently meant longer patient waiting times and more complaints. To tackle this, managers explored a sideways method of internal communications. Instead of information trickling down from top-to-bottom, all of the company’s employees were given freedom to provide vital feedback at each and every level.
AtlantiCare decided to ensure all new employees understood this quality culture from the onset. At orientation, staff now receive a crash course in the company’s performance excellence framework – a management system that organises the firm’s processes into five key areas: quality, customer service, people and workplace, growth and financial performance. As employees rise through the ranks, this emphasis on improvement follows, so managers can operate within the company’s tight-loose-tight process management style.
After creating benchmark goals for employees to achieve at all levels – including better engagement at the point of delivery, increasing clinical communication and identifying and prioritising service opportunities – AtlantiCare was able to thrive. The number of repeat customers at the firm tripled, and its market share hit a six-year high. Profits unsurprisingly followed. The firm’s revenues shot up from $280m to $650m after implementing the quality improvement strategies, and the number of patients being serviced dwarfed state numbers.
Hitting the right notes: Santa Cruz Guitar Co For companies further removed from the long-term satisfaction of customers, it’s easier to let quality control slide. Yet there are plenty of ways in which growing manufacturers can pursue both quality and sales volumes simultaneously. Artisan instrument makers the Santa Cruz Guitar Co (SCGC) prove a salient example. Although the California-based company is still a small-scale manufacturing operation, SCGC has grown in recent years from a basement operation to a serious business.
SCGC in numbers
14 Craftsmen employed by SCGC
800 Custom guitars produced each year
Owner Dan Roberts now employs 14 expert craftsmen, who create over 800 custom guitars each year. In order to ensure the continued quality of his instruments, Roberts has created an environment that improves with each sale. To keep things efficient (as TQM must), the shop floor is divided into six workstations in which guitars are partially assembled and then moved to the next station. Each bench is manned by a senior craftsman, and no guitar leaves that builder’s station until he is 100 percent happy with its quality. This product quality is akin to a traditional assembly line; however, unlike a traditional, top-to-bottom factory, Roberts is intimately involved in all phases of instrument construction.
Utilising this doting method of quality management, it’s difficult to see how customers wouldn’t be satisfied with the artists’ work. Yet even if there were issues, Roberts and other senior management also spend much of their days personally answering web queries about the instruments. According to the managers, customers tend to be pleasantly surprised to find the company’s senior leaders are the ones answering their technical questions and concerns. While Roberts has no intentions of taking his manufacturing company to industrial heights, the quality of his instruments and high levels of customer satisfaction speak for themselves; the company currently boasts one lengthy backlog of orders.
A quality education: Ramaiah Institute of Management Studies Although it may appear easier to find success with TQM at a boutique-sized endeavour, the philosophy’s principles hold true in virtually every sector. Educational institutions, for example, have utilised quality management in much the same way – albeit to tackle decidedly different problems.
The global financial crisis hit higher education harder than many might have expected, and nowhere have the odds stacked higher than in India. The nation plays home to one of the world’s fastest-growing markets for business education. Yet over recent years, the relevance of business education in India has come into question. A report by one recruiter recently asserted just one in four Indian MBAs were adequately prepared for the business world.
RIMS in numbers
9% Increase in test scores post total quality management strategy
22% Increase in number of recruiters hiring from the school
20,000 Increase in the salary offered to graduates
50,000 Rise in placement revenue
At the Ramaiah Institute of Management Studies (RIMS) in Bangalore, recruiters and accreditation bodies specifically called into question the quality of students’ educations. Although the relatively small school has always struggled to compete with India’s renowned Xavier Labour Research Institute, the faculty finally began to notice clear hindrances in the success of graduates. The RIMS board decided it was time for a serious reassessment of quality management.
The school nominated Chief Academic Advisor Dr Krishnamurthy to head a volunteer team that would audit, analyse and implement process changes that would improve quality throughout (all in a particularly academic fashion). The team was tasked with looking at three key dimensions: assurance of learning, research and productivity, and quality of placements. Each member underwent extensive training to learn about action plans, quality auditing skills and continuous improvement tools – such as the ‘plan-do-study-act’ cycle.
Once faculty members were trained, the team’s first task was to identify the school’s key stakeholders, processes and their importance at the institute. Unsurprisingly, the most vital processes were identified as student intake, research, knowledge dissemination, outcomes evaluation and recruiter acceptance. From there, Krishnamurthy’s team used a fishbone diagram to help identify potential root causes of the issues plaguing these vital processes. To illustrate just how bad things were at the school, the team selected control groups and administered domain-based knowledge tests.
The deficits were disappointing. A RIMS students’ knowledge base was rated at just 36 percent, while students at Harvard rated 95 percent. Likewise, students’ critical thinking abilities rated nine percent, versus 93 percent at MIT. Worse yet, the mean salaries of graduating students averaged $36,000, versus $150,000 for students from Kellogg. Krishnamurthy’s team had their work cut out.
To tackle these issues, Krishnamurthy created an employability team, developed strategic architecture and designed pilot studies to improve the school’s curriculum and make it more competitive. In order to do so, he needed absolutely every employee and student on board – and there was some resistance at the onset. Yet the educator asserted it didn’t actually take long to convince the school’s stakeholders the changes were extremely beneficial.
“Once students started seeing the results, buy-in became complete and unconditional,” he says. Acceptance was also achieved by maintaining clearer levels of communication with stakeholders. The school actually started to provide shareholders with detailed plans and projections. Then, it proceeded with a variety of new methods, such as incorporating case studies into the curriculum, which increased general test scores by almost 10 percent. Administrators also introduced a mandate saying students must be certified in English by the British Council – increasing scores from 42 percent to 51 percent.
By improving those test scores, the perceived quality of RIMS skyrocketed. The number of top 100 businesses recruiting from the school shot up by 22 percent, while the average salary offers graduates were receiving increased by $20,000. Placement revenue rose by an impressive $50,000, and RIMS has since skyrocketed up domestic and international education tables.
No matter the business, total quality management can and will work. Yet this philosophical take on quality control will only impact firms that are in it for the long haul. Every employee must be in tune with the company’s ideologies and desires to improve, and customer satisfaction must reign supreme.
Contributors
- Industry Outlook
MBA Knowledge Base
Business • Management • Technology
Home » Management Case Studies » Case Study: Quality Management System at Coca Cola Company
Case Study: Quality Management System at Coca Cola Company
Coca Cola’s history can be traced back to a man called Asa Candler, who bought a specific formula from a pharmacist named Smith Pemberton. Two years later, Asa founded his business and started production of soft drinks based on the formula he had bought. From then, the company grew to become the biggest producers of soft drinks with more than five hundred brands sold and consumed in more than two hundred nations worldwide.
Although the company is said to be the biggest bottler of soft drinks, they do not bottle much. Instead, Coca Cola Company manufactures a syrup concentrate, which is bought by bottlers all over the world. This distribution system ensures the soft drink is bottled by these smaller firms according to the company’s standards and guidelines. Although this franchised method of distribution is the primary method of distribution, the mother company has a key bottler in America, Coca Cola Refreshments.
In addition to soft drinks, which are Coca Cola’s main products, the company also produces diet soft drinks. These are variations of the original soft drinks with improvements in nutritional value, and reductions in sugar content. Saccharin replaced industrial sugar in 1963 so that the drinks could appeal to health-conscious consumers. A major cause for concern was the inter product competition which saw some sales dwindle in some products in favor of others.
Coca Cola started diversifying its products during the First World War when ‘Fanta’ was introduced. During World War 1, the heads of Coca Cola in Nazi Germany decided to establish a new soft drink into the market. During the ongoing war, America’s promotion in Germany was not acceptable. Therefore, he decided to use a new name and ‘Fanta’ was born. The creation was successful and production continued even after the war. ‘Sprite’ followed soon after.
In the 1990’s, health concerns among consumers of soft drinks forced their manufactures to consider altering the energy content of these products. ‘Minute Maid’ Juices, ‘PowerAde’ sports drinks, and a few flavored teas variants were Coca Cola’s initial reactions to this new interest. Although most of these new products were well received, some did not perform as well. An example of such was Coca Cola classic, dubbed C2.
Coca Cola Company has been a successful company for more than a century. This can be attributed partly to the nature of its products since soft drinks will always appeal to people. In addition to this, Coca Cola has one of the best commercial and public relations programs in the world. The company’s products can be found on adverts in virtually every corner of the globe. This success has led to its support for a wide range of sporting activities. Soccer, baseball, ice hockey, athletics and basketball are some of these sports, where Coca Cola is involved

The Quality Management System at Coca Cola
It is very important that each product that Coca Cola produces is of a high quality standard to ensure that each product is exactly the same. This is important as the company wants to meet with customer requirements and expectations. With the brand having such a global presence, it is vital that these checks are continually consistent. The standardized bottle of Coca Cola has elements that need to be checked whilst on the production line to make sure that a high quality is being met. The most common checks include ingredients, packaging and distribution. Much of the testing being taken place is during the production process, as machines and a small team of employees monitor progress. It is the responsibility of all of Coca Colas staff to check quality from hygiene operators to product and packaging quality. This shows that these constant checks require staff to be on the lookout for problems and take responsibility for this, to ensure maintained quality.
Coca-cola uses inspection throughout its production process, especially in the testing of the Coca-Cola formula to ensure that each product meets specific requirements. Inspection is normally referred to as the sampling of a product after production in order to take corrective action to maintain the quality of products. Coca-Cola has incorporated this method into their organisational structure as it has the ability of eliminating mistakes and maintaining high quality standards, thus reducing the chance of product recall. It is also easy to implement and is cost effective.
Coca-cola uses both Quality Control (QC) and Quality Assurance (QA) throughout its production process. QC mainly focuses on the production line itself, whereas QA focuses on its entire operations process and related functions, addressing potential problems very quickly. In QC and QA, state of the art computers check all aspects of the production process, maintaining consistency and quality by checking the consistency of the formula, the creation of the bottle (blowing), fill levels of each bottle, labeling of each bottle, overall increasing the speed of production and quality checks, which ensures that product demands are met. QC and QA helps reduce the risk of defective products reaching a customer; problems are found and resolved in the production process, for example, bottles that are considered to be defective are placed in a waiting area for inspection. QA also focuses on the quality of supplied goods to Coca-cola, for example sugar, which is supplied by Tate and Lyle. Coca-cola informs that they have never had a problem with their suppliers. QA can also involve the training of staff ensuring that employees understand how to operate machinery. Coca-Cola ensures that all members of staff receive training prior to their employment, so that employees can operate machinery efficiently. Machinery is also under constant maintenance, which requires highly skilled engineers to fix problems, and help Coca-cola maintain high outputs.
Every bottle is also checked that it is at the correct fill level and has the correct label. This is done by a computer which every bottle passes through during the production process. Any faulty products are taken off the main production line. Should the quality control measures find any errors, the production line is frozen up to the last good check that was made. The Coca Cola bottling plant also checks the utilization level of each production line using a scorecard system. This shows the percentage of the line that is being utilized and allows managers to increase the production levels of a line if necessary.
Coca-Cola also uses Total Quality Management (TQM) , which involves the management of quality at every level of the organisation , including; suppliers, production, customers etc. This allows Coca-cola to retain/regain competitiveness to achieve increased customer satisfaction . Coca-cola uses this method to continuously improve the quality of their products. Teamwork is very important and Coca-cola ensures that every member of staff is involved in the production process, meaning that each employee understands their job/roles, thus improving morale and motivation , overall increasing productivity. TQM practices can also increase customer involvement as many organisations, including Coca-Cola relish the opportunity to receive feedback and information from their consumers. Overall, reducing waste and costs, provides Coca-cola with a competitive advantage .
The Production Process
Before production starts on the line cleaning quality tasks are performed to rinse internal pipelines, machines and equipment. This is often performed during a switch over of lines for example, changing Coke to Diet Coke to ensure that the taste is the same. This quality check is performed for both hygiene purposes and product quality. When these checks are performed the production process can begin.
Coca Cola uses a database system called Questar which enables them to perform checks on the line. For example, all materials are coded and each line is issued with a bill of materials before the process starts. This ensures that the correct materials are put on the line. This is a check that is designed to eliminate problems on the production line and is audited regularly. Without this system, product quality wouldn’t be assessed at this high level. Other quality checks on the line include packaging and carbonation which is monitored by an operator who notes down the values to ensure they are meeting standards.
To test product quality further lab technicians carry out over 2000 spot checks a day to ensure quality and consistency. This process can be prior to production or during production which can involve taking a sample of bottles off the production line. Quality tests include, the CO2 and sugar values, micro testing, packaging quality and cap tightness. These tests are designed so that total quality management ideas can be put forward. For example, one way in which Coca Cola has improved their production process is during the wrapping stage at the end of the line. The machine performed revolutions around the products wrapping it in plastic until the contents were secure. One initiative they adopted meant that one less revolution was needed. This idea however, did not impact on the quality of the packaging or the actual product therefore saving large amounts of money on packaging costs. This change has been beneficial to the organisation. Continuous improvement can also be used to adhere to environmental and social principles which the company has the responsibility to abide by. Continuous Improvement methods are sometimes easy to identify but could lead to a big changes within the organisation. The idea of continuous improvement is to reveal opportunities which could change the way something is performed. Any sources of waste, scrap or rework are potential projects which can be improved.
The successfulness of this system can be measured by assessing the consistency of the product quality. Coca Cola say that ‘Our Company’s Global Product Quality Index rating has consistently reached averages near 94 since 2007, with a 94.3 in 2010, while our Company Global Package Quality Index has steadily increased since 2007 to a 92.6 rating in 2010, our highest value to date’. This is an obvious indication this quality system is working well throughout the organisation. This increase of the index shows that the consistency of the products is being recognized by consumers.
Related posts:
- Case Study: The Coca-Cola Company Struggles with Ethical Crisis
- Case Study: Analysis of the Ethical Behavior of Coca Cola
- Case Study of Burger King: Achieving Competitive Advantage through Quality Management
- SWOT Analysis of Coca Cola
- Case Study: Marketing Strategy of Walt Disney Company
- Case Study of Papa John’s: Quality as a Core Business Strategy
- Case Study: Johnson & Johnson Company Analysis
- Case Study: Inventory Management Practices at Walmart
- Case Study: Analysis of Performance Management at British Petroleum
- Total Quality Management And Continuous Quality Improvement
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *

The Ultimate Guide to Qualitative Research - Part 1: The Basics

- Introduction and overview
- What is qualitative research?
- What is qualitative data?
- Examples of qualitative data
- Qualitative vs. quantitative research
- Mixed methods
- Qualitative research preparation
- Theoretical perspective
- Theoretical framework
- Literature reviews
Research question
- Conceptual framework
- Conceptual vs. theoretical framework
Data collection
- Qualitative research methods
- Focus groups
- Observational research
What is a case study?
Applications for case study research, what is a good case study, process of case study design, benefits and limitations of case studies.
- Ethnographical research
- Ethical considerations
- Confidentiality and privacy
- Power dynamics
- Reflexivity
Case studies
Case studies are essential to qualitative research , offering a lens through which researchers can investigate complex phenomena within their real-life contexts. This chapter explores the concept, purpose, applications, examples, and types of case studies and provides guidance on how to conduct case study research effectively.

Whereas quantitative methods look at phenomena at scale, case study research looks at a concept or phenomenon in considerable detail. While analyzing a single case can help understand one perspective regarding the object of research inquiry, analyzing multiple cases can help obtain a more holistic sense of the topic or issue. Let's provide a basic definition of a case study, then explore its characteristics and role in the qualitative research process.
Definition of a case study
A case study in qualitative research is a strategy of inquiry that involves an in-depth investigation of a phenomenon within its real-world context. It provides researchers with the opportunity to acquire an in-depth understanding of intricate details that might not be as apparent or accessible through other methods of research. The specific case or cases being studied can be a single person, group, or organization – demarcating what constitutes a relevant case worth studying depends on the researcher and their research question .
Among qualitative research methods , a case study relies on multiple sources of evidence, such as documents, artifacts, interviews , or observations , to present a complete and nuanced understanding of the phenomenon under investigation. The objective is to illuminate the readers' understanding of the phenomenon beyond its abstract statistical or theoretical explanations.
Characteristics of case studies
Case studies typically possess a number of distinct characteristics that set them apart from other research methods. These characteristics include a focus on holistic description and explanation, flexibility in the design and data collection methods, reliance on multiple sources of evidence, and emphasis on the context in which the phenomenon occurs.
Furthermore, case studies can often involve a longitudinal examination of the case, meaning they study the case over a period of time. These characteristics allow case studies to yield comprehensive, in-depth, and richly contextualized insights about the phenomenon of interest.
The role of case studies in research
Case studies hold a unique position in the broader landscape of research methods aimed at theory development. They are instrumental when the primary research interest is to gain an intensive, detailed understanding of a phenomenon in its real-life context.
In addition, case studies can serve different purposes within research - they can be used for exploratory, descriptive, or explanatory purposes, depending on the research question and objectives. This flexibility and depth make case studies a valuable tool in the toolkit of qualitative researchers.
Remember, a well-conducted case study can offer a rich, insightful contribution to both academic and practical knowledge through theory development or theory verification, thus enhancing our understanding of complex phenomena in their real-world contexts.
What is the purpose of a case study?
Case study research aims for a more comprehensive understanding of phenomena, requiring various research methods to gather information for qualitative analysis . Ultimately, a case study can allow the researcher to gain insight into a particular object of inquiry and develop a theoretical framework relevant to the research inquiry.
Why use case studies in qualitative research?
Using case studies as a research strategy depends mainly on the nature of the research question and the researcher's access to the data.
Conducting case study research provides a level of detail and contextual richness that other research methods might not offer. They are beneficial when there's a need to understand complex social phenomena within their natural contexts.
The explanatory, exploratory, and descriptive roles of case studies
Case studies can take on various roles depending on the research objectives. They can be exploratory when the research aims to discover new phenomena or define new research questions; they are descriptive when the objective is to depict a phenomenon within its context in a detailed manner; and they can be explanatory if the goal is to understand specific relationships within the studied context. Thus, the versatility of case studies allows researchers to approach their topic from different angles, offering multiple ways to uncover and interpret the data .
The impact of case studies on knowledge development
Case studies play a significant role in knowledge development across various disciplines. Analysis of cases provides an avenue for researchers to explore phenomena within their context based on the collected data.

This can result in the production of rich, practical insights that can be instrumental in both theory-building and practice. Case studies allow researchers to delve into the intricacies and complexities of real-life situations, uncovering insights that might otherwise remain hidden.
Types of case studies
In qualitative research , a case study is not a one-size-fits-all approach. Depending on the nature of the research question and the specific objectives of the study, researchers might choose to use different types of case studies. These types differ in their focus, methodology, and the level of detail they provide about the phenomenon under investigation.
Understanding these types is crucial for selecting the most appropriate approach for your research project and effectively achieving your research goals. Let's briefly look at the main types of case studies.
Exploratory case studies
Exploratory case studies are typically conducted to develop a theory or framework around an understudied phenomenon. They can also serve as a precursor to a larger-scale research project. Exploratory case studies are useful when a researcher wants to identify the key issues or questions which can spur more extensive study or be used to develop propositions for further research. These case studies are characterized by flexibility, allowing researchers to explore various aspects of a phenomenon as they emerge, which can also form the foundation for subsequent studies.
Descriptive case studies
Descriptive case studies aim to provide a complete and accurate representation of a phenomenon or event within its context. These case studies are often based on an established theoretical framework, which guides how data is collected and analyzed. The researcher is concerned with describing the phenomenon in detail, as it occurs naturally, without trying to influence or manipulate it.
Explanatory case studies
Explanatory case studies are focused on explanation - they seek to clarify how or why certain phenomena occur. Often used in complex, real-life situations, they can be particularly valuable in clarifying causal relationships among concepts and understanding the interplay between different factors within a specific context.

Intrinsic, instrumental, and collective case studies
These three categories of case studies focus on the nature and purpose of the study. An intrinsic case study is conducted when a researcher has an inherent interest in the case itself. Instrumental case studies are employed when the case is used to provide insight into a particular issue or phenomenon. A collective case study, on the other hand, involves studying multiple cases simultaneously to investigate some general phenomena.
Each type of case study serves a different purpose and has its own strengths and challenges. The selection of the type should be guided by the research question and objectives, as well as the context and constraints of the research.
The flexibility, depth, and contextual richness offered by case studies make this approach an excellent research method for various fields of study. They enable researchers to investigate real-world phenomena within their specific contexts, capturing nuances that other research methods might miss. Across numerous fields, case studies provide valuable insights into complex issues.
Critical information systems research
Case studies provide a detailed understanding of the role and impact of information systems in different contexts. They offer a platform to explore how information systems are designed, implemented, and used and how they interact with various social, economic, and political factors. Case studies in this field often focus on examining the intricate relationship between technology, organizational processes, and user behavior, helping to uncover insights that can inform better system design and implementation.
Health research
Health research is another field where case studies are highly valuable. They offer a way to explore patient experiences, healthcare delivery processes, and the impact of various interventions in a real-world context.

Case studies can provide a deep understanding of a patient's journey, giving insights into the intricacies of disease progression, treatment effects, and the psychosocial aspects of health and illness.
Asthma research studies
Specifically within medical research, studies on asthma often employ case studies to explore the individual and environmental factors that influence asthma development, management, and outcomes. A case study can provide rich, detailed data about individual patients' experiences, from the triggers and symptoms they experience to the effectiveness of various management strategies. This can be crucial for developing patient-centered asthma care approaches.
Other fields
Apart from the fields mentioned, case studies are also extensively used in business and management research, education research, and political sciences, among many others. They provide an opportunity to delve into the intricacies of real-world situations, allowing for a comprehensive understanding of various phenomena.
Case studies, with their depth and contextual focus, offer unique insights across these varied fields. They allow researchers to illuminate the complexities of real-life situations, contributing to both theory and practice.
Whatever field you're in, ATLAS.ti puts your data to work for you
Download a free trial of ATLAS.ti to turn your data into insights.
Understanding the key elements of case study design is crucial for conducting rigorous and impactful case study research. A well-structured design guides the researcher through the process, ensuring that the study is methodologically sound and its findings are reliable and valid. The main elements of case study design include the research question , propositions, units of analysis, and the logic linking the data to the propositions.
The research question is the foundation of any research study. A good research question guides the direction of the study and informs the selection of the case, the methods of collecting data, and the analysis techniques. A well-formulated research question in case study research is typically clear, focused, and complex enough to merit further detailed examination of the relevant case(s).
Propositions
Propositions, though not necessary in every case study, provide a direction by stating what we might expect to find in the data collected. They guide how data is collected and analyzed by helping researchers focus on specific aspects of the case. They are particularly important in explanatory case studies, which seek to understand the relationships among concepts within the studied phenomenon.
Units of analysis
The unit of analysis refers to the case, or the main entity or entities that are being analyzed in the study. In case study research, the unit of analysis can be an individual, a group, an organization, a decision, an event, or even a time period. It's crucial to clearly define the unit of analysis, as it shapes the qualitative data analysis process by allowing the researcher to analyze a particular case and synthesize analysis across multiple case studies to draw conclusions.
Argumentation
This refers to the inferential model that allows researchers to draw conclusions from the data. The researcher needs to ensure that there is a clear link between the data, the propositions (if any), and the conclusions drawn. This argumentation is what enables the researcher to make valid and credible inferences about the phenomenon under study.
Understanding and carefully considering these elements in the design phase of a case study can significantly enhance the quality of the research. It can help ensure that the study is methodologically sound and its findings contribute meaningful insights about the case.
Ready to jumpstart your research with ATLAS.ti?
Conceptualize your research project with our intuitive data analysis interface. Download a free trial today.
Conducting a case study involves several steps, from defining the research question and selecting the case to collecting and analyzing data . This section outlines these key stages, providing a practical guide on how to conduct case study research.
Defining the research question
The first step in case study research is defining a clear, focused research question. This question should guide the entire research process, from case selection to analysis. It's crucial to ensure that the research question is suitable for a case study approach. Typically, such questions are exploratory or descriptive in nature and focus on understanding a phenomenon within its real-life context.
Selecting and defining the case
The selection of the case should be based on the research question and the objectives of the study. It involves choosing a unique example or a set of examples that provide rich, in-depth data about the phenomenon under investigation. After selecting the case, it's crucial to define it clearly, setting the boundaries of the case, including the time period and the specific context.
Previous research can help guide the case study design. When considering a case study, an example of a case could be taken from previous case study research and used to define cases in a new research inquiry. Considering recently published examples can help understand how to select and define cases effectively.
Developing a detailed case study protocol
A case study protocol outlines the procedures and general rules to be followed during the case study. This includes the data collection methods to be used, the sources of data, and the procedures for analysis. Having a detailed case study protocol ensures consistency and reliability in the study.
The protocol should also consider how to work with the people involved in the research context to grant the research team access to collecting data. As mentioned in previous sections of this guide, establishing rapport is an essential component of qualitative research as it shapes the overall potential for collecting and analyzing data.
Collecting data
Gathering data in case study research often involves multiple sources of evidence, including documents, archival records, interviews, observations, and physical artifacts. This allows for a comprehensive understanding of the case. The process for gathering data should be systematic and carefully documented to ensure the reliability and validity of the study.
Analyzing and interpreting data
The next step is analyzing the data. This involves organizing the data , categorizing it into themes or patterns , and interpreting these patterns to answer the research question. The analysis might also involve comparing the findings with prior research or theoretical propositions.
Writing the case study report
The final step is writing the case study report . This should provide a detailed description of the case, the data, the analysis process, and the findings. The report should be clear, organized, and carefully written to ensure that the reader can understand the case and the conclusions drawn from it.
Each of these steps is crucial in ensuring that the case study research is rigorous, reliable, and provides valuable insights about the case.
The type, depth, and quality of data in your study can significantly influence the validity and utility of the study. In case study research, data is usually collected from multiple sources to provide a comprehensive and nuanced understanding of the case. This section will outline the various methods of collecting data used in case study research and discuss considerations for ensuring the quality of the data.
Interviews are a common method of gathering data in case study research. They can provide rich, in-depth data about the perspectives, experiences, and interpretations of the individuals involved in the case. Interviews can be structured , semi-structured , or unstructured , depending on the research question and the degree of flexibility needed.
Observations
Observations involve the researcher observing the case in its natural setting, providing first-hand information about the case and its context. Observations can provide data that might not be revealed in interviews or documents, such as non-verbal cues or contextual information.
Documents and artifacts
Documents and archival records provide a valuable source of data in case study research. They can include reports, letters, memos, meeting minutes, email correspondence, and various public and private documents related to the case.

These records can provide historical context, corroborate evidence from other sources, and offer insights into the case that might not be apparent from interviews or observations.
Physical artifacts refer to any physical evidence related to the case, such as tools, products, or physical environments. These artifacts can provide tangible insights into the case, complementing the data gathered from other sources.
Ensuring the quality of data collection
Determining the quality of data in case study research requires careful planning and execution. It's crucial to ensure that the data is reliable, accurate, and relevant to the research question. This involves selecting appropriate methods of collecting data, properly training interviewers or observers, and systematically recording and storing the data. It also includes considering ethical issues related to collecting and handling data, such as obtaining informed consent and ensuring the privacy and confidentiality of the participants.
Data analysis
Analyzing case study research involves making sense of the rich, detailed data to answer the research question. This process can be challenging due to the volume and complexity of case study data. However, a systematic and rigorous approach to analysis can ensure that the findings are credible and meaningful. This section outlines the main steps and considerations in analyzing data in case study research.
Organizing the data
The first step in the analysis is organizing the data. This involves sorting the data into manageable sections, often according to the data source or the theme. This step can also involve transcribing interviews, digitizing physical artifacts, or organizing observational data.
Categorizing and coding the data
Once the data is organized, the next step is to categorize or code the data. This involves identifying common themes, patterns, or concepts in the data and assigning codes to relevant data segments. Coding can be done manually or with the help of software tools, and in either case, qualitative analysis software can greatly facilitate the entire coding process. Coding helps to reduce the data to a set of themes or categories that can be more easily analyzed.
Identifying patterns and themes
After coding the data, the researcher looks for patterns or themes in the coded data. This involves comparing and contrasting the codes and looking for relationships or patterns among them. The identified patterns and themes should help answer the research question.
Interpreting the data
Once patterns and themes have been identified, the next step is to interpret these findings. This involves explaining what the patterns or themes mean in the context of the research question and the case. This interpretation should be grounded in the data, but it can also involve drawing on theoretical concepts or prior research.
Verification of the data
The last step in the analysis is verification. This involves checking the accuracy and consistency of the analysis process and confirming that the findings are supported by the data. This can involve re-checking the original data, checking the consistency of codes, or seeking feedback from research participants or peers.
Like any research method , case study research has its strengths and limitations. Researchers must be aware of these, as they can influence the design, conduct, and interpretation of the study.
Understanding the strengths and limitations of case study research can also guide researchers in deciding whether this approach is suitable for their research question . This section outlines some of the key strengths and limitations of case study research.
Benefits include the following:
- Rich, detailed data: One of the main strengths of case study research is that it can generate rich, detailed data about the case. This can provide a deep understanding of the case and its context, which can be valuable in exploring complex phenomena.
- Flexibility: Case study research is flexible in terms of design , data collection , and analysis . A sufficient degree of flexibility allows the researcher to adapt the study according to the case and the emerging findings.
- Real-world context: Case study research involves studying the case in its real-world context, which can provide valuable insights into the interplay between the case and its context.
- Multiple sources of evidence: Case study research often involves collecting data from multiple sources , which can enhance the robustness and validity of the findings.
On the other hand, researchers should consider the following limitations:
- Generalizability: A common criticism of case study research is that its findings might not be generalizable to other cases due to the specificity and uniqueness of each case.
- Time and resource intensive: Case study research can be time and resource intensive due to the depth of the investigation and the amount of collected data.
- Complexity of analysis: The rich, detailed data generated in case study research can make analyzing the data challenging.
- Subjectivity: Given the nature of case study research, there may be a higher degree of subjectivity in interpreting the data , so researchers need to reflect on this and transparently convey to audiences how the research was conducted.
Being aware of these strengths and limitations can help researchers design and conduct case study research effectively and interpret and report the findings appropriately.

Ready to analyze your data with ATLAS.ti?
See how our intuitive software can draw key insights from your data with a free trial today.
- Browse All Articles
- Newsletter Sign-Up

- 11 Apr 2023
- Cold Call Podcast
A Rose by Any Other Name: Supply Chains and Carbon Emissions in the Flower Industry
Headquartered in Kitengela, Kenya, Sian Flowers exports roses to Europe. Because cut flowers have a limited shelf life and consumers want them to retain their appearance for as long as possible, Sian and its distributors used international air cargo to transport them to Amsterdam, where they were sold at auction and trucked to markets across Europe. But when the Covid-19 pandemic caused huge increases in shipping costs, Sian launched experiments to ship roses by ocean using refrigerated containers. The company reduced its costs and cut its carbon emissions, but is a flower that travels halfway around the world truly a “low-carbon rose”? Harvard Business School professors Willy Shih and Mike Toffel debate these questions and more in their case, “Sian Flowers: Fresher by Sea?”

- 17 Sep 2019
How a New Leader Broke Through a Culture of Accuse, Blame, and Criticize
Children’s Hospital & Clinics COO Julie Morath sets out to change the culture by instituting a policy of blameless reporting, which encourages employees to report anything that goes wrong or seems substandard, without fear of reprisal. Professor Amy Edmondson discusses getting an organization into the “High Performance Zone.” Open for comment; 0 Comments.

- 27 Feb 2019
- Research & Ideas
The Hidden Cost of a Product Recall
Product failures create managerial challenges for companies but market opportunities for competitors, says Ariel Dora Stern. The stakes have only grown higher. Open for comment; 0 Comments.

- 31 Mar 2018
- Working Paper Summaries
Expected Stock Returns Worldwide: A Log-Linear Present-Value Approach
Over the last 20 years, shortcomings of classical asset-pricing models have motivated research in developing alternative methods for measuring ex ante expected stock returns. This study evaluates the main paradigms for deriving firm-level expected return proxies (ERPs) and proposes a new framework for estimating them.
- 26 Apr 2017
Assessing the Quality of Quality Assessment: The Role of Scheduling
Accurate inspections enable companies to assess the quality, safety, and environmental practices of their business partners, and enable regulators to protect consumers, workers, and the environment. This study finds that inspectors are less stringent later in their workday and after visiting workplaces with fewer problems. Managers and regulators can improve inspection accuracy by mitigating these biases and their consequences.
- 23 Sep 2013
Status: When and Why It Matters
Status plays a key role in everything from the things we buy to the partnerships we make. Professor Daniel Malter explores when status matters most. Closed for comment; 0 Comments.
- 16 May 2011
What Loyalty? High-End Customers are First to Flee
Companies offering top-drawer customer service might have a nasty surprise awaiting them when a new competitor comes to town. Their best customers might be the first to defect. Research by Harvard Business School's Ryan W. Buell, Dennis Campbell, and Frances X. Frei. Key concepts include: Companies that offer high levels of customer service can't expect too much loyalty if a new competitor offers even better service. High-end businesses must avoid complacency and continue to proactively increase relative service levels when they're faced with even the potential threat of increased service competition. Even though high-end customers can be fickle, a company that sustains a superior service position in its local market can attract and retain customers who are more valuable over time. Firms rated lower in service quality are more or less immune from the high-end challenger. Closed for comment; 0 Comments.
- 08 Dec 2008
Thinking Twice About Supply-Chain Layoffs
Cutting the wrong employees can be counterproductive for retailers, according to research from Zeynep Ton. One suggestion: Pay special attention to staff who handle mundane tasks such as stocking and labeling. Your customers do. Closed for comment; 0 Comments.
- 01 Dec 2006
- What Do You Think?
How Important Is Quality of Labor? And How Is It Achieved?
A new book by Gregory Clark identifies "labor quality" as the major enticement for capital flows that lead to economic prosperity. By defining labor quality in terms of discipline and attitudes toward work, this argument minimizes the long-term threat of outsourcing to developed economies. By understanding labor quality, can we better confront anxieties about outsourcing and immigration? Closed for comment; 0 Comments.
- 20 Sep 2004
How Consumers Value Global Brands
What do consumers expect of global brands? Does it hurt to be an American brand? This Harvard Business Review excerpt co-written by HBS professor John A. Quelch identifies the three characteristics consumers look for to make purchase decisions. Closed for comment; 0 Comments.
- ACS Foundation
- Diversity, Equity, and Inclusion
- ACS Archives
- Careers at ACS
- Federal Legislation
- State Legislation
- Regulatory Issues
- Get Involved
- SurgeonsPAC
- About ACS Quality Programs
- Accreditation & Verification Programs
- Data & Registries
- Standards & Staging
- Membership & Community
- Practice Management
- Professional Growth
- News & Publications
- Information for Patients and Family
- Preparing for Your Surgery
- Recovering from Your Surgery
- Jobs for Surgeons
- Become a Member
- Media Center
Our top priority is providing value to members. Your Member Services team is here to ensure you maximize your ACS member benefits, participate in College activities, and engage with your ACS colleagues. It's all here.
- Membership Benefits
- Find a Surgeon
- Find a Hospital or Facility
- Quality Programs
- Education Programs
- Member Benefits
- QI Resources
- Case Studies
Quality Improvement Case Study Repository
The ACS Quality Improvement Case Study Repository is a collection of QI projects from hospitals participating in ACS Quality Programs.
The ACS Quality Improvement Case Study Repository is a centralized platform of quality improvement projects implemented by participants of the ACS Quality Programs. Each of the curated projects in the repository has been formatted to follow the new ACS Quality Framework , allowing readers to easily understand the details of each project from planning through execution, data analysis, and lessons learned.
All projects were developed by surgical clinical reviewers, cancer registrars, surgeon champions, program directors, or other quality improvement professionals. They focus on a local problem, utilize local data, and were implemented within their own facilities. They describe the team’s experience, explain project challenges, and how these challenges were addressed.
The ACS is providing these case studies to educate and inspire surgical teams, their hospitals, and other healthcare entities to engage in quality improvement activities. Quality improvement is not an exact science, and it is important that your quality improvement project is based on a local problem at your institution.
The case studies offered represent the experiences of the authors and may not be generalizable to other institutions. These examples may serve as a starting point to assist you in developing your own quality improvement initiative. Adapting projects outlined as example here does not guarantee compliance with an ACS accreditation or verification standard.
If you have a quality improvement project you would like to add to the case study repository or would like to provide feedback on this new resource, contact us at [email protected] .
Last updated 20/06/24: Online ordering is currently unavailable due to technical issues. We apologise for any delays responding to customers while we resolve this. For further updates please visit our website: https://www.cambridge.org/news-and-insights/technical-incident
We use cookies to distinguish you from other users and to provide you with a better experience on our websites. Close this message to accept cookies or find out how to manage your cookie settings .
Login Alert
- > The Case for Case Studies
- > Using Case Studies to Enhance the Quality of Explanation and Implementation

Book contents
- The Case for Case Studies
- Strategies for Social Inquiry
- Copyright page
- Contributors
- Preface and Acknowledgments
- 1 Using Case Studies to Enhance the Quality of Explanation and Implementation
- Part I Internal and External Validity Issues in Case Study Research
- Part II Ensuring High-Quality Case Studies
- Part III Putting Case Studies to Work: Applications to Development Practice
1 - Using Case Studies to Enhance the Quality of Explanation and Implementation
Integrating Scholarship and Development Practice
Published online by Cambridge University Press: 05 May 2022
The opening chapter provides a brief outline of the conventional division of labor between qualitative and quantitative methods in the social sciences. It sketches the main standards that govern case study research. It then offers an overview of subsequent chapters, which challenge some of these distinctions or deepen our understanding of what makes qualitative case studies useful for both causal inference and policy practice.
1.1 Introduction
In recent years the development policy community has turned to case studies as an analytical and diagnostic tool. Practitioners are using case studies to discern the mechanisms underpinning variations in the quality of service delivery and institutional reform, to identify how specific challenges are addressed during implementation, and to explore the conditions under which given instances of programmatic success might be replicated or scaled up. Footnote 1 These issues are of prime concern to organizations such as Princeton University’s Innovations for Successful Societies (ISS) Footnote 2 program and the Global Delivery Initiative (GDI), Footnote 3 housed in the World Bank Group (from 2015–2021), both of which explicitly prepare case studies exploring the dynamics underpinning effective implementation in fields ranging from water, energy, sanitation, and health to cabinet office performance and national development strategies.
In this sense, the use of case studies by development researchers and practitioners mirrors their deployment in other professional fields. Case studies have long enjoyed high status as a pedagogical tool and research method in business, law, medicine, and public policy, and indeed across the full span of human knowledge. According to Google Scholar data reported by Reference Van Noorden, Maher and Nuzzo Van Noorden, Maher, and Nuzzo (2014) , Robert Yin’s Case Study Research ( Reference Yin 1984 ) is, remarkably, the sixth most cited article or book in any field , of all time . Footnote 4 Even so, skepticism lingers in certain quarters regarding the veracity of the case study method – for example, how confident can one be about claims drawn from single cases selected on a nonrandom or nonrepresentative basis? – and many legitimate questions remain ( Reference Morgan Morgan 2012 ). In order for insights from case studies to be valid and reliable, development professionals need to think carefully about how to ensure that data used in preparing the case study is accurate, that causal inferences drawn from it are made on a defensible basis ( Reference Mahoney Mahoney 2000 ; Reference Rohlfing Rohlfing 2012 ), and that broader generalizations are carefully delimited ( Reference Ruzzene Ruzzene 2012 ; Reference Woolcock Woolcock 2013 ). Footnote 5
How best to ensure this happens? Given the recent rise in prominence and influence of the case study method within the development community and elsewhere, scholars have a vital quality control and knowledge dissemination role to play in ensuring that the use of case studies both accurately reflects and contributes to leading research. To provide a forum for this purpose, the World Bank’s Development Research Group and its leading operational unit deploying case studies (the GDI) partnered with the leading academic institution that develops policy-focused case studies of development (Princeton’s ISS) and asked scholars and practitioners to engage with several key questions regarding the foundations, strategies, and applications of case studies as they pertain to development processes and outcomes: Footnote 6
What are the distinctive virtues and limits of case studies, in their own right and vis-à-vis other research methods? How can their respective strengths be harnessed and their weaknesses overcome (or complemented by other approaches) in policy deliberations?
Are there criteria for case study selection, research design, and analysis that can help ensure accuracy and comparability in data collection, reliability in causal inference within a single case, integrity in statements about uncertainty or scope, and something akin to the replicability standard in quantitative methods?
Under what conditions can we generalize from a small number of cases? When can comparable cases be generalized or not (across time, contexts, units of analysis, scales of operation, implementing agents)?
How can case studies most effectively complement the insights drawn from household surveys and other quantitative assessment tools in development research, policy, and practice?
How can lessons from case studies be used for pedagogical, diagnostic, and policy-advising purposes as improvements in the quality of implementation of a given intervention are sought?
How can the proliferation of case studies currently being prepared on development processes and outcomes be used to inform the scholarship on the theory and practice of case studies?
The remainder of this chapter provides an overview of the distinctive features (and limits) of case study research, drawing on “classic” and recent contributions in the scholarly literature. It provides a broad outline of the key claims and issues in the field, as well as a summary of the book’s chapters.
1.2 The Case for Case Studies: A Brief Overview
We can all point to great social science books and articles that derive from qualitative case study research. Herbert Reference Kaufman Kaufman’s (1960) classic, The Forest Ranger , profiles the principal–agent problems that arise in management of the US Forest Service as well as the design and implementation of several solutions. Robert Reference Ellickson Ellickson’s (1991) Order Without Law portrays how ranchers settle disputes among themselves without recourse to police or courts. Judith Reference Tendler Tendler’s (1997) Good Government in the Tropics uses four case studies of Ceara, Brazil’s poorest state, to identify instances of positive deviance in public sector reform. Daniel Reference Carpenter Carpenter’s (2001) The Forging of Bureaucratic Autonomy , based on three historical cases, seeks to explain why reformers in some US federal agencies were able to carve out space free from partisan legislative interference while others were unable to do so. In “The Market for Public Office,” Robert Reference Wade Wade (1985) elicits the strategic structure of a particular kind of spoiler problem from a case study conducted in India. In economics, a longitudinal study of poverty dynamics in a single village in India (Palanpur) Footnote 7 has usefully informed understandings of these processes across the subcontinent (and beyond).
What makes these contributions stand out compared to the vast numbers of case studies that few find insightful? What standards should govern the choice and design of case studies, generally? And what specific insights do case studies yield that other research methods might be less well placed to provide?
The broad ambition of the social sciences is to forge general insights that help us quickly understand the world around us and make informed policy decisions. While each social science discipline has its own distinctive approach, there is broad agreement upon a methodological division of labor in the work we do. This conventional wisdom holds that quantitative analysis of large numbers of discrete cases is usually more effective for testing the veracity of causal propositions, for estimating the strength of the association between readily measurable causes and outcomes, and for evaluating the sensitivity of correlations to changes in the underlying model specifying the relationship between causal variables (and their measurement). By contrast, qualitative methods generally, and case studies in particular, fulfill other distinct epistemological functions and are the predominant method for:
1. Developing a theory and/or identifying causal mechanisms (e.g., working inductively from evidence to propositions and exploring the contents of the “black box” processes connecting causes and effects)
2. Eliciting strategic structure (e.g., documenting how interaction effects of one kind or another influence options, processes, and outcomes)
3. Showing how antecedent conditions elicit a prevailing structure which thereby shapes/constrains the decisions of actors within that structure
4. Testing a theory in novel circumstances
5. Understanding outliers or deviant cases
The conventional wisdom also holds that in an ideal world we would have the ability to use both quantitative and qualitative analysis and employ “nested” research designs ( Reference Bamberger, Rao, Woolcock, Tashakkori and Teddlie Bamberger, Rao, and Woolcock 2010 ; Reference Goertz and Mahoney Goertz and Mahoney 2012 ; Reference Lieberman, Mahoney and Thelen Lieberman 2015 ). However, the appropriate choice of method depends on the character of the subject matter, the kinds of data available, and the array of constraints (resources, politics, time) under which the study is being conducted. The central task is to deploy those combinations of research methods that yield the most fruitful insights in response to a specific problem, given the prevailing constraints ( Reference Rueschemeyer Rueschemeyer 2009 ). We now consider each of these five domains in greater detail.
1.3 Developing a Theory and/or Identifying Causal Mechanisms
Identifying a causal mechanism and inferring an explanation or theory are important parts of the research process, especially in the early stages of knowledge development. The causal mechanism links an independent variable to an outcome, and over time may become more precise: to cite an oft-used example, an initial awareness that citrus fruits reduced scurvy became more refined when the underlying causal mechanism was discovered to be vitamin C. For policy purposes, mechanisms provide the basis for a compelling storyline, which can greatly influence the tone and terms of debate – or the space of what is “thinkable,” “say-able,” and “do-able” – which in turn can affect the design, implementation, and support for interventions. This can be particularly relevant for development practitioners if the storyline – and the mechanisms it highlights – provides important insights into how and where implementation processes unravel, and what factors enabled a particular intervention to succeed or fail during the delivery process.
In this way, qualitative research can provide clarity on the factors that influence critical processes and help us identify the mechanisms that affect particular outcomes. For example, there is a fairly robust association, globally, between higher incomes and smaller family sizes. But what is it about income that would lead families to have fewer children – or does income mask other changes that influence child-bearing decisions? To figure out the mechanism, one could conduct interviews and focus groups with a few families to understand decision-making about family planning. Hypotheses based on these family case studies could then inform the design of survey-based quantitative research to test alternative mechanisms and the extent to which one or another predominates in different settings. Population researchers have done just that (see Reference Knodel Knodel 1997 ).
Case studies carried out for the purpose of inductive generalization or identifying causal mechanisms are rarely pure “soak and poke” exercises uninformed by any preconceptions. Indeed, approaching a case with a provisional set of hypotheses is vitally important. The fact that we want to use a case to infer a general statement about cause and effect does not obviate the need for this vital intellectual tool; it just means we need to listen hard for alternative explanations we did not initially perceive and be highly attentive to actions, events, attitudes, etc., that are at odds with the reasoned intuition brought to the project.
An example where having an initial set of hypotheses was important comes from a GDI case on scaling-up rural sanitation. In this case, the authors wanted to further understand how the government of Indonesia had been able to substantially diminish open defecation, which is the main cause of several diseases in thousands of villages across the country. Footnote 8 The key policy change was a dramatic move from years of subsidizing latrines that ended up not being used to trying to change people’s behavior toward open defecation, a socially accepted norm. The authors had a set of hypotheses with respect to what triggered this important policy shift: a change in cabinet members, the presence of international organizations, adjustments in budgets, etc. However, the precise mechanism that triggered the change only became clear after interviewing several actors involved in the process. It turns out that a study tour taken by several Indonesian officials to Bangladesh was decisive since, for the first time, they could see the results of a different policy “with their own eyes” instead of just reading about it. Footnote 9
There are some situations, however, in which we may know so little that hypothesis development must essentially begin from scratch. For example, consider an ISS case study series on cabinet office performance. A key question was why so many heads of government allow administrative decisions to swamp cabinet meetings, causing the meetings to last a long time and reducing the chance that the government will reach actual policy decisions or priorities. One might have a variety of hypotheses to explain this predicament, but without direct access to the meetings themselves it is hard to know which of these hypotheses is most likely to be true ( Reference March, Sproull and Tamuz March, Sproul, and Tamuz 1991 ). In the initial phases, ISS researchers deliberately left a lot of space for the people interviewed to offer their own explanations. They anticipated that not all heads of state might want their cabinets to work as forums for decision-making and coordination, because ministers who had a lot of political and military clout might capture the stage or threaten vital interests of weaker members – or because the head of state benefited from the dysfunction. But as the first couple of cases unfolded, the research team realized that part of the problem arose from severe under-staffing, simple lack of know-how, inadequate capacity at the ministry level, or rapid turnover in personnel. In such situations, as Reference March, Sproull and Tamuz March, Sproul, and Tamuz (1991 : 8) aptly put it,
[t]he pursuit of rich experience … requires a method for absorbing detail without molding it. Great organizational histories, like great novels, are written, not by first constructing interpretations of events and then filling in the details, but by first identifying the details and allowing the interpretations to emerge from them. As a result, openness to a variety of (possibly irrelevant) dimensions of experience and preference is often more valuable than a clear prior model and unambiguous objectives.
In another ISS case study on the factors shaping the implementation and sustainability of “rapid results” management practices (e.g., setting 100-day goals, coupled with coaching on project management), a subquestion was when and why setting a 100-day goal improved service delivery. In interviews, qualitative insight into causal mechanisms surfaced: some managers said they thought employees understood expectations more clearly and therefore performed better as a result of setting a 100-day goal, while in other instances a competitive spirit or “game sense” increased motivation or cooperation with other employees, making work more enjoyable. Still others expected that an audit might follow, so a sense of heightened scrutiny also made a difference. The project in question did not try to arbitrate among these causal mechanisms or theories, but using the insight from the qualitative research, a researcher might well have proceeded to decipher which of these explanations carried most weight.
In many instances it is possible and preferable to approach the task of inductive generalization with more intellectual structure up front, however. As researchers we always have a few “priors” – hunches or hypotheses – that guide investigation. The extent to which we want these to structure initial inquiry may depend on the purpose of our research, but also on the likely causal complexity of the outcome we want to study, the rapidity of change in contexts, and the stock of information already available.
1.4 Eliciting Strategic Structure
A second important feature of the case study method, one that is intimately related to developing a theory or identifying causal mechanisms, is its ability to elicit the strategic structure of an event – that is, to capture the interactions that produce an important outcome. Some kinds of outcomes are “conditioned”: they vary with underlying contextual features like income levels or geography. Others are “crafted” or choice-based: the outcome is the product of bargaining, negotiating, deal-cutting, brinkmanship, and other types of interaction among a set of specified actors. Policy choice and implementation fall into this second category. Context may shape the feasible set of outcomes or the types of bargaining challenges, but the only way to explain outcomes is to trace the process or steps and choices as they unfold in the interaction (see Reference Bennett and Checkel Bennett and Checkel 2015 ).
In process tracing we want to identify the key actors, their preferences, and the alternatives or options they faced; evaluate the information available to these people and the expectations they formed; assess the resources available to each to persuade others or to alter the incentives others face and the expectations they form (especially with regard to the strategies they deploy); and indicate the formal and informal rules that govern the negotiation, as well as the personal aptitudes that influence effectiveness and constrain choice. The researcher often approaches the case with a specific type of strategic structure in mind – a bargaining story that plausibly accounts for the outcome – along with a sense of other frames that might explain the same set of facts.
In the 1980s and 1990s, the extensive literature on the politics of structural adjustment yielded many case studies designed to give us a better understanding of the kinds of difficulties ministers of finance faced in winning agreement to devalue a currency, sell assets, or liberalize trade or commodity markets, as well as the challenges they encountered in making these changes happen (e.g., Reference Haggard Haggard 1992 ). Although the case studies yielded insights that could be used to create models testable with large-N data, in any individual case the specific parameters – context or circumstance – remained important for explaining particular outcomes. Sensitivity to the kinds of strategic challenges that emerged in other settings helped decision-makers assess the ways their situations might be similar or different, identify workarounds or coalitions essential for winning support, and increase the probability that their own efforts would succeed. It is important to know what empirical relationships seem to hold across a wide (ideally full) array of cases, but the most useful policy advice is that which is given in response to specific people in a specific place responding to a specific problem under specific constraints; as such, deep knowledge of contextual contingencies characterizing each case is vital. Footnote 10
For example, consider the challenge of improving rural livelihoods during an economic crisis in Indonesia. In “Services for the People, By the People,” ISS researchers profiled how Indonesian policy-makers tried to address the problem of “capture” in a rural development program. Officials and local leaders often diverted resources designed to benefit the poor. The question was how to make compliance incentive compatible. That is, what did program leaders do to alter the cost–benefit calculus of the potential spoiler? How did they make their commitment to bargains, deals, pacts, or other devices credible? In most cases, the interaction is “dynamic” and equilibria (basis for compliance) are not stable. Learning inevitably takes place, and reform leaders often have to take new steps as circumstances change. Over time, what steps did a reformer take to preserve the fragile equilibrium first created or to forge a new equilibrium? Which tactics proved most effective, given the context?
In this instance, leaders used a combination of tactics to address the potential spoiler problem. They vested responsibility for defining priorities in communities, not in the capital or the district. They required that at least two of three proposals the communities could submit came from women’s groups. They set up subdistrict competitions to choose the best proposals, with elected members of each community involved in selection. They transferred money to community bank accounts that could only be tapped when the people villagers elected to monitor the projects all countersigned. They created teams of facilitators to provide support and monitor results. When funds disappeared, communities lost the ability to compete. Careful case analysis helped reveal not only the incentive design, but also the interaction between design and context – and the ways in which the system occasionally failed, although the program was quite successful overall.
A related series of ISS cases focused on how leaders overcame the opposition of people or groups who benefited from dysfunction and whose institutional positions enabled them to block changes that would improve service delivery. The ambition in these cases was to tease out the strategies reform leaders could use to reach an agreement on a new set of rules or practices; if they were able to do so, case studies focused on institutions where spoiler traps often appear: anticorruption initiatives, port reform (ports, like banks, being “where the money is”), and infrastructure. The strategies or tactics at the focus in these studies included use of external agencies of restraint (e.g., the Governance and Economic Management Assistance Program [GEMAP] in Liberia); “coalitions with the public” to make interference more costly in social or political terms; persuading opponents to surrender rents in one activity for rewards in another; pitting strong spoilers against each other; and altering the cost calculus by exposing the spoiler to new risks. The cases allowed researchers both to identify the strategies used and to weigh the sensitivity of these to variations in context or shifts in the rules of the game or the actors involved. The hope was that the analysis the cases embodied would help practitioners avoid the adoption of strategies that are doomed to fail in the specific contexts they face. It also enabled policy-makers to see how they might alter rules or practices in ways that make a reformer’s job ( at least to a degree) easier.
A couple of GDI cases provide further illustration of how to elicit strategic structure. In a case on how to shape an enabling environment for water service delivery in Nigeria, Footnote 11 the authors were able to identify the political incentives that undermine long-term commitments and overhaul short-run returns, and which generate a low-level equilibrium trap. This has led to improvements in investments in rehabilitation and even an expansion of water services, yet it has not allowed the institutional reforms needed to ensure sustainability to move forward. In the case of Mexico, where the government had been struggling to improve service delivery to Indigenous communities, a World Bank loan provided a window of opportunity to change things. A number of reformers within the government believed that catering services to these populations in their own languages would help decrease the number of dropouts from its flagship social program, Oportunidades. Footnote 12 However, previous efforts had not moved forward. A World Bank loan to the Mexican government triggered a safeguards policy on Indigenous populations and it became fundamental for officials to be able to develop a program to certify bilingual personnel that could service these communities. Interviews with key officials and stakeholders showed how the safeguards policy kick-started a set of meetings and decisions within the government that eventually led to this program, changing the strategic structures within government.
1.5 Showing How an Antecedent Condition Limits Decision-Makers’ Options
Some types of phenomena require case study analysis to disentangle complex causal relationships. We generally assume the cause of an outcome is exogenous, but sometimes there are feedback effects and an outcome intensifies one of its causes or limits the range of values the outcome can later assume. In such situations, case studies can be helpful in parsing the structure of these causal relationships and identifying which conditions are prior. Some of the case studies that inform Why States Fail ( Reference Acemoglu and Robinson Acemoglu and Robinson 2012 ), for example, perform this function. More detailed case studies of this type appear in political science and sociological writing in the “historical institutionalism” tradition (see Reference Thelen and Mahoney Thelen and Mahoney 2009 ; Reference Mahoney and Thelen Mahoney and Thelen 2015 ).
Case studies are also useful in other instances when both the design of a policy intervention and the way in which it is implemented affect the outcome. They help identify ways to distinguish the effects of policy from the effects of process, two things that most quantitative studies conflate. To illustrate, take another ISS case study series on rapid turnarounds observed in some types of public sector agencies: the quick development of pockets of effectiveness. The agencies at the focus of this project provided business licenses or identity documents – actions that required relatively little exercise of judgment on the part of the person dispensing the service and where the number of distribution points is fairly limited. Businesses and citizens felt the effects of delay and corruption in these services keenly, but not all governments put reformers at the helm and not all reformers improved performance. The ISS team was partly interested in the interventions that produced turnarounds in this type of activity: was there a secret recipe – a practice that produced altered incentives or outlooks and generated positive results? The literature on principal–agent problems offered hypotheses about ways to better align the interests of leaders and the people on the front-line who deliver a service, but many of these were inapplicable in low-resource environments or where removing personnel and modifying terms of service was hard to do. But ISS was also interested in how the mode of implementation affected outcomes, because solving the principal–agent problem often created clear losers who could block the new policies. How did the successful reformers win support?
The team refined and expanded its initial set of hypotheses through a detailed case study of South Africa’s Ministry of Home Affairs, and traced both the influence of the incentive design and the process used to put the new practices into effect. Without the second part, the case study team might have reasoned that the results stemmed purely from changed practices and tried to copy the same approach somewhere else, but in this instance, as in many cases, the mode of implementation was critical to success. The project leader could not easily draw from the standard toolkit for solving principal–agent problems because he could not easily remove poorly performing employees. He had to find ways to win union acceptance of the new policies and get people excited about the effort. This case study was an example of using qualitative methods to identify a causal mechanism and to develop explanations we can evaluate more broadly by conducting other case studies.
An example from the GDI is a case on addressing maternal and child mortality in Argentina in the early 2000s. Footnote 13 As a result of the 2001 economic crisis, thousands of people lost their jobs and hence were unable to pay for private healthcare; consequently, the public health system suddenly received a vast and unexpected influx of patients. Given that the Argentine public health system had been decentralized over the preceding decades and therefore the central government’s role in the provinces was minor, policy-makers had to work around a set of conditions and do it fast, given the context. The case disentangled how the central government was able to design one of the first results-based finance programs in the health sector and how this design was critical in explaining the maternal and child mortality outcomes. Policy-makers had to react immediately to the pressure on the health system and were able to make use of a provincial coordination mechanism that had become mostly irrelevant. By reviving this mechanism and having access to international funds, the central government was able to reinstate its role in provincial health care and engage key local decision-makers. Through the case study, the authors were able to assess the relevance of the policy-making process and how it defined the stakeholders’ choices, as well as the effect of the process in the Argentine healthcare system.
1.6 Testing a Theory in Novel Circumstances
Case study analysis is a relatively weak method for testing explanations derived from large sample sizes but it is often the only method available if the event is relatively uncommon or if sample sizes are small. Testing a theory against a small number of instrumentally chosen cases carries some peril. If we have only a few cases to study, the number of causal variables that potentially influence the outcome could overwhelm the number of observations, making it impossible to infer anything about the relationship between two variables, except through intensive tracing of processes.
Usually theory testing with case studies begins with a “truth table” or matrix, with the key independent variable(s) arrayed on one axis and the outcome variable arrayed on the other. The researcher collects data on the same variables in each case. The names of the cases in the cells of the table are then arranged and comparisons made of expected patterns with the actual pattern. The proportion of cases in each cell will track expectations if there is support for the theory.
An example of this kind of use of case studies appears in Alejandro Portes’s collaborative project on institutional development in Latin America ( Reference Portes and Smith Portes and Smith 2008 ). In each country, the project studied the same five agencies. The research team listed several organizational characteristics that prior theories suggested might be important. In the truth table, the characteristic on which the successful agencies clustered was having a merit system for making personnel decisions. Having a merit system distinguished the successful agencies from the unsuccessful agencies in each of the five country settings in which the research took place. (A slightly different design would have allowed the researchers to determine whether an antecedent condition shaped the adoption of merit systems in the successful cases and also exercised an independent effect on the outcome.)
In the ISS project about single-agency turnarounds, the aim was to make some tentative general statements about the robustness of a set of practices to differences in context. Specifically, the claim was that delays would diminish and productivity would rise by introducing a fairly standard set of management practices designed to streamline a process, increase transparency, and invite friendly group competition. In this kind of observational study, the authors had a before-and-after or longitudinal design in each individual case, which was married with a cross-sectional design. Footnote 14 The elements of the intervention were arrayed in a truth table and examined to see which of them were present or absent in parallel interventions in a number of other cases. The team added cases with nearly identical interventions but different underlying country contexts. ISS then explored each case in greater detail to see whether implementation strategy or something else having to do with context explained which reforms were successful and which were not.
Small-scale observational studies (the only type of study possible in many subject areas) suffer from a variety of threats, including inability to control for large numbers of differences in setting. However, the interview data and close process tracing helped increase confidence in two respects. First, they helped reveal the connection between the outcomes observed and the practices under study. For example, it was relevant that people in work groups could describe their reactions when a poster showing how many identity documents they had issued had increased or decreased compared to the month before. Second, the information the interviews delivered about obstacles encountered and workarounds developed fueled hypotheses about robustness to changes in setting. In short, the deep dive that the case study permitted helped alleviate some of the inferential challenges that inevitably arise when there are only small numbers of observations and a randomized controlled trial is not feasible.
Rare events pose special problems for theory testing. Organizations must often learn from single cases – for example, from the outcome of a rare event (such as a natural disaster, or a major restructuring). In this circumstance it may be possible to evaluate impact across several units within the organization or influences across policy areas. However, where this approach is impossible few organizations decline to learn from experience; instead, they look closely at the history of the event to assess the sequence of steps by which prevailing outcomes obtained and how these might have been different had alternative courses of action been pursued.
1.7 Understanding Outliers or Deviant Cases
A common and important use of case studies is to explore the case that does not conform to expectations. An analysis comparing a large number of cases on a few variables may find that most units (countries, agencies, etc.) cluster closely around a regression line whose slope shows the relationship between the causal variables and the outcome. However, one or two cases may lie far from the line. We usually want to know what’s different about those cases, and especially how and why they differ. For example, there is generally a quite robust relationship between a country’s level of spending on education and the quality of outcomes that country’s education system generates. Why is Vietnam in the bottom third globally in terms of its spending on education, yet in the upper third globally in terms of outcomes (as measured by student performance on standardized examinations)? Conversely, why is Malaysia in the upper third on spending and bottom third on outcomes?
In the study of development, outliers such as these hold particular fascination. For example, several scholars whose contributions are ordinarily associated with use of quantitative methods have employed schematic case studies to ponder why Botswana seems to have stronger institutions than most other African countries ( Reference Acemoglu, Johnson, Robinson and Rodrik Acemoglu, Johnson, and Robinson 2003 ). Costa Rica and Singapore attract attention for the same reason. Footnote 15 This same approach can be used to explore and explain subnational variation as a basis for deriving policy lessons. Reference Brixi, Lust and Woolcock Brixi, Lust, and Woolcock (2015) , for example, deploy data collected from household surveys to map the wide range of outcomes in public service delivery across countries in the Middle East and North Africa – countries which otherwise have highly centralized line ministries, which means roughly the same policies regarding (say) health and education apply across any given country. The wide variation in outcomes is thus largely a matter of factors shaping policy implementation , which are often highly contextual and thus much harder to assess via standard quantitative instruments. On the basis of the subnational variation maps, however, granular case studies were able to be prepared on those particular locations where unusually high (and low) outcomes were being obtained; the lessons from these cases, in turn, became inputs for a conversation with domestic policy-makers about where and how improvements might be sought. Here, the goal was not to seek policy reform by importing what researchers deemed “best practices” (as verified by “rigorous evidence”) from abroad but rather to use both household surveys and case studies to endogenize research tools into the ways in which local practitioners make difficult decisions about strategy, trade-offs, and feedback, doing so in ways regarded as legitimate and useful by providers and users of public services.
1.8 Ensuring Rigor in Case Studies: Foundations, Strategies, and Applications
There is general agreement on some of the standards that should govern qualitative case studies. Such studies should: Footnote 16
respond to a clear question that links to an important intellectual debate or policy problem
specify and define core concepts, terms, and metrics associated with the explanations
identify plausible explanations, articulating a main hypothesis and logical alternatives
offer data that allow us to evaluate the main ideas or discriminate between different possible causal mechanisms, including any that emerge as important in the course of the research
be selected according to clear and transparent criteria appropriate to the research objective
be amenable to replication – that is, other researchers ought to be able to check the results
Together, this book’s three parts – on Internal and External Validity Issues, Ensuring High-Quality Case Studies, and Applications to Development Practice – explore how the content and realization of these standards can be applied by those conducting case studies in development research and practice, and how, in turn, the fruits of their endeavors can contribute to a refinement and expansion of the “ecologies of evidence” on which inherently complex decisions in development are made.
We proceed as follows. Part I focuses on the relative strengths and weaknesses of qualitative cases versus frequentist observational studies (surveys, aggregate data analysis) and randomized controlled trials (RCTs). Its constituent chapters explore the logic of causal inference and the logic of generalization, often framed as problems of internal and external validity.
In Chapter 2 , philosopher of science Nancy Cartwright walks us through the logic behind RCTs on the one hand, and qualitative case studies on the other. RCTs have gained considerable prominence as a ‘gold standard’ for establishing whether a given policy intervention has a causal effect, but what do these experiments actually tell us and how useful is this information for policy-makers? Cartwright draws attention to two problems. First, an RCT only establishes a claim about average effects for the population enrolled in an experiment; it tells us little about what lies behind the average. The policy intervention studied might have changed nothing in some instances, while in others it triggered large shifts in behavior or health or whatever is under study. But, second, an RCT also tells us nothing about when we might expect to see the same effect size in a different population. To assess how a different population might respond requires other information of the sort that qualitative case studies often uncover. RCTs may help identify a cause, but identifying a cause is not the same as identifying something that is generally true, Cartwright notes. She then considers what information a policy-maker would need to predict whether a causal relationship will hold in a particular instance, which is often what we really want to know.
The singular qualitative case study has a role to play in addressing this need. Cartwright begins by asking what are the support factors that enable the intervention to work, and are they present in a particular situation? She suggests we should use various types of evidence, both indirect and direct. In the “direct” category are many of the elements that case studies can (and should) document: 1) Does O occur at the time, in the manner, and of the size to be expected that T caused it? 2) Are there symptoms of cause – by-products of the causal relationship? 3) Were requisite support factors present? (i.e., was everything in place that needed to be in order for T to produce O?), and 4) Were the expected intermediate steps (mediator variables) in place? Often these are the key elements we need to know in order to decide whether the effects observed in an experiment will scale.
Political scientist Christopher Achen also weighs the value of RCTs versus qualitative case studies with the aim of correcting what he perceives as an imbalance in favor of the former within contemporary social science. In Chapter 3 he shows that “the argument for experiments depends critically on emphasizing the central challenge of observational work – accounting for unobserved confounders – while ignoring entirely the central challenge of experimentation – achieving external validity.” Using the mathematics behind randomized controlled trials to make his point, he shows that once this imbalance is corrected, we are closer to Cartwright’s view than to the current belief that RCTs constitute the gold standard for good policy research.
As a pivot, Achen takes a 2014 essay, a classic statement about the failure of observational studies to generate learning and about the strengths of RCTs. The authors of that essay argued that
[t]he external validity of an experiment hinges on four factors: 1) whether the subjects in the study are as strongly influenced by the treatment as the population to which a generalization is made, 2) whether the treatment in the experiment corresponds to the treatment in the population of interest, 3) whether the response measure used in the experiment corresponds to the variable of interest in the population, and 4) how the effect estimates were derived statistically.
But Achen finds this list a little too short: “The difficulty is that those assumptions combine jaundiced cynicism about observational studies with gullible innocence about experiments,” he writes. “What is missing from this list are the two critical factors emphasized in the work of recent critics of RCTs: heterogeneity of treatment effects and the importance of context.” For example, in an experiment conducted with Michigan voters, there were no Louisianans, no Democrats, and no general election voters; “[h]ence, no within-sample statistical adjustments are available to accomplish the inferential leap” required for generalizing the result.
Achen concludes: “Causal inference of any kind is just plain hard. If the evidence is observational, patient consideration of plausible counterarguments, followed by the assembling of relevant evidence, can be, and often is, a painstaking process.” Well-structured qualitative case studies are one important tool; experiments, another.
In Chapter 4 , Andrew Bennett help us think about what steps are necessary to use case studies to identify causal relationships and draw contingent generalizations. He suggests that case study research employs Bayesian logic rather than frequentist logic: “Bayesian logic treats probabilities as degrees of belief in alternative explanations, and it updates initial degrees of belief (called ‘priors’) by using assessments of the probative value of new evidence vis-à-vis alternative explanations (the updated degree of belief is known as the ‘posterior’).”
Bennett’s chapter sketches four approaches: generalization from ‘typical’ cases, generalization from most- or least-likely cases, mechanism-based generalization, and typological theorizing, with special attention to the last two. Improved understanding of causal mechanisms permits generalizing to individuals, cases, or contexts outside the initial sample studied. In this regard, the study of deviant, or outlier, cases and cases that have high values on the independent variable of interest (theory of change) may prove helpful, Bennett suggests, aiding the identification of scope conditions, new explanations, and omitted variables.
In “Will it Work Here?” ( Chapter 5 ), Michael Woolcock focuses on the utility of qualitative case studies for addressing the decision-maker’s perennial external validity concern: What works there may not work here. He asks how to generate the facts that are important in determining whether an intervention can be scaled and replicated in a given setting. He focuses our attention on three categories. The first he terms causal density, or whether 1) there are numerous causal pathways and feedback loops that affect inputs, actions, and outcomes, and 2) there is greater or lesser openness to exogenous influence. Experiments are often helpful when causal density is low – deworming, use of malaria nets, classroom size – but they fail when causal density is high, as in parenting. To assess causal density, Woolcock suggests we pay special attention to how many person-to-person transactions are required; how much discretion is required of front-line implementing agents; how much pressure implementing agents face to do something other than respond constructively to the problem; and the extent to which implementing agents are required to deploy solutions from a known menu or to innovate in situ.
Woolcock’s two other categories of relevant fact include implementation capability and reasoned expectations about what can be achieved by when. With respect to the first, he urges us not to assume that implementation capacity is equally available in each setting. Who has the authority to act? Is there adequate management capacity? Are there adequately trained front-line personnel? Is there a clear point of delivery? A functional supply chain? His third category, reasoned expectations, focuses on having a grounded theory about what can be achieved by when. Should we anticipate that the elements of an intervention all show results at the same time, as we usually assume, or will some kinds of results materialize before others? Will some increase over time, while others dissipate? Deliberation about these matters on the basis of analytic case studies, Woolcock argues, are the main method available for assessing the generalizability of any given intervention. Woolcock supplements his discussion with examples and a series of useful summary charts.
Part II of the book builds upon these methodological concerns to examine practical strategies by which case studies in international development (and elsewhere) can be prepared to the highest standards. Although not exhaustive, these strategies, presented by three political scientists, can help elevate the quality and utility of case studies by focusing on useful analytical tools that can enhance the rigor of their methodological foundations.
In Chapter 6 , Jennifer Widner, who directs Princeton University’s Innovations for Successful Societies program, reflects on what she and others have learned about gathering reliable information from interviews. Case study researchers usually draw on many types of evidence, some qualitative and some quantitative. For understanding motivation/interest, anticipated challenges, strategic choices, steps taken, unexpected obstacles encountered, and other elements of implementation, interviews with people who were “in the room where it happens” are usually essential. There may be diary entries or meeting minutes to help verify personal recall, but often the documentary evidence is limited or screened from view by thirty-year rules. Subject matter, proximity to elections or other sensitive events, interviewer self-presentation, question sequence, probes, and ethics safeguards are among the factors that shape the reliability of information offered in an interview. Widner sketches ways to improve the accuracy of recall and the level of detail, and to guard against “spin,” drawing on her program’s experience as well as the work of survey researchers and anthropologists.
Political scientist Tommaso Pavone analyzes how our evolving understanding of case-based causal inference via process tracing should alter how we select cases for comparative inquiry ( Chapter 7 ). The chapter explicates perhaps the most influential and widely used means to conduct qualitative research involving two or more cases: Mill’s methods of agreement and difference. It then argues that the traditional use of Millian methods of case selection can lead us to treat cases as static units to be synchronically compared rather than as social processes unfolding over time. As a result, Millian methods risk prematurely rejecting and otherwise overlooking (1) ordered causal processes, (2) paced causal processes, and (3) equifinality, or the presence of multiple pathways that produce the same outcome. To address these issues, the chapter develops a set of recommendations to ensure the alignment of Millian methods of case selection with within-case sequential analysis. First, it outlines how the use of processualist theories can help reformulate Millian case selection designs to accommodate ordered and paced processes (but not equifinal processes). Second, it proposes a new, alternative approach to comparative case study research: the method of inductive case selection. By selecting cases for comparison after a causal process has been identified within a particular case, the method of inductive case selection enables researchers to assess (1) the generalizability of the causal sequences, (2) the logics of scope conditions on the causal argument, and (3) the presence of equifinal pathways to the same outcome. A number of concrete examples from development practice illustrate how the method of inductive case selection can be used by both scholars and policy practitioners alike.
One of the common criticisms of qualitative research is that a case is hard to replicate. Whereas quantitative researchers often share their research designs and their data and encourage one another to rerun their analyses, qualitative researchers cannot as easily do so. However, they can enhance reliability in other ways. In Chapter 8 , Andrew Moravcsik introduces new practices designed to enhance three dimensions of research transparency: data transparency , which stipulates that researchers should publicize the data and evidence on which their research rests; analytic transparency , which stipulates that researchers should publicize how they interpret and analyze evidence in order to generate descriptive and causal inferences; and production transparency , which stipulates that social scientists should publicize the broader set of design choices that underlie the research. To respond to these needs, Moravcsik couples technology with the practice of discursive footnotes common in law journals. He discusses the rationale for creating a digitally enabled appendix with annotated source materials, called Active Citation or the Annotation for Transparency Initiative.
Part III – this volume’s concluding section – explores the ways in which case studies are being used today to learn from and enhance effectiveness in different development agencies.
In Chapter 9 , Andrew Bennett explores how process tracing can be used in program evaluation. “Process tracing and program evaluation, or contribution analysis, have much in common, as they both involve causal inference on alternative explanations for the outcome of a single case,” Bennett says:
Evaluators are often interested in whether one particular explanation – the implicit or explicit theory of change behind a program – accounts for the outcome. Yet they still need to consider whether exogenous nonprogram factors … account for the outcome, whether the program generated the outcome through some process other than the theory of change, and whether the program had additional or unintended consequences, either good or bad.
Bennett discusses how to develop a process-tracing case study to meet these demands and walks the reader through several key elements of this enterprise, including types of confounding explanations and the basics of Bayesian analysis.
In Chapter 10 , with a focus on social services in the Middle East, political scientist Melani Cammett takes up the use of positive deviant cases – examples of sustained high performance in a context in which good results are uncommon – to identify and disentangle causal complexity and understand the role of context. Although the consensus view on the role of deviant cases is that they are most useful for exploratory purposes or discovery and theory building, Cammett suggests they can also generate insights into the identification and operation of causal mechanisms. She writes that “analyses of positive deviant cases among a field of otherwise similar cases that operate in the same context … can be a valuable way to identify potential explanatory variables for exceptional performance.” The hypothesized explanatory variables can then be incorporated in subsequent quantitative or qualitative studies in order to evaluate their effects across a broader range of observations. The chapter discusses how to approach selection of positive deviant cases systematically and then works through a real example.
In Chapter 11 , on “Analytical Narratives and Case Studies,” Margaret Levi and Barry Weingast focus on a particular type of case in which the focus is on an outcome that results from strategic interaction, when one person’s decision depends on what another does. “A weakness of case studies per se is that there typically exist multiple ways to interpret a given case,” they begin. “How are we to know which interpretation makes most sense? What gives us confidence in the particular interpretation offered?” An analytic narrative first elucidates the principal players, their preferences, key decision points and possible choices, and the rules of the game. It then builds a model of the sequence of interaction including predicted outcomes and evaluates the model through comparative statics and the testable implications the mode generates. An analytic narrative also models situations as an extensive-form game. “The advantage of the game is that it reveals the logic of why, in equilibrium, it is in the interest of the players to fulfill their threats or promises against those who leave the equilibrium path,” the authors explain. Although game theory is useful, there is no hard rule that requires us to formalize. The particular findings do not generalize to other contexts, but an analytic narrative points to the characteristics of situations to which a similar strategic logic applies.
The book’s final chapters focus on the use of case studies for refining development policy and practice – in short, for learning. In Chapter 12 , Sarah Glavery and her coauthors draw a distinction between explicit knowledge, which is easily identified and shared through databases and reports, and tacit knowledge – the less easily shared “know how” that comes with having carried out a task. The chapter explores ways to use case study preparation, as well as a case itself, as a vehicle for sharing “know how,” specifically with respect to program implementation. It considers the experiences of four different types of organizations that have used case studies as part of their decision-making as it pertains to development issues: a multilateral agency (the World Bank), a major bilateral agency (Germany’s GIZ), a leading think tank (Brookings), and a ministry of a large country (China’s Ministry of Finance), which are all linked through their involvement in the GDI.
Finally, in Chapter 13 , Maria Gonzalez and Jennifer Widner reflect more broadly on the intellectual history of a science of delivery and adaptive management, two interlinked approaches to improving public services, and the use of case studies to move these endeavors forward. They emphasize the ways in which case studies have become salient tools for front-line staff whose everyday work is trying to solve complex development challenges, especially those pertaining to the implementation of policies and projects, and how, in turn, case studies are informing a broader turn to explaining outcome variation and identifying strategies for responding to complex challenges and ultimately seeking to enhance development effectiveness. The chapter discusses seven qualities that make a case useful to practitioners, and then offers reflections on how to use cases in a group context to elucidate core ideas and spark innovation.
1.9 Conclusion
In both development research and practice, case studies provide unique insights into implementation successes and failures, and help to identify why and how a particular outcome occurred. The data collected through case studies is often richer and of greater depth than would normally be obtained by other research designs, which allows for (potentially) richer discussions regarding their generalizability beyond the defined context of the case being studied. The case study method facilitates the identification of patterns and provides practical insights on how to navigate complex delivery challenges. Case studies can also capture the contextual conditions surrounding the delivery case, trace the detailed dynamics of the implementation process, provide key lessons learned, and inform broader approaches to service delivery (e.g., by focusing attention on citizen outcomes, generating multidimensional responses, providing usable evidence to enhance real-time implementation, and supporting leadership for change).
The core idea behind recent initiatives seeking to expand, formalize, and catalogue case studies of development practice is that capturing implementation processes and building a cumulative body of operational knowledge and know-how can play a key role in helping development practitioners deliver better results. Systematically investigating delivery in its own right offers an opportunity to distill common delivery challenges, and to engage constructively with the nontechnical problems that often hinder development interventions and prevent countries and practitioners from translating technical solutions into results on the ground.
Doing this well, however, requires drawing on the full array of established and leading approaches to conducting case study research. As this volume seeks to show, the last twenty years have led to considerable refinements and extensions of prevailing practice, and renewed confidence among scholars of case study methods that they have not merely addressed (or at least identified defensible responses to) long-standing concerns regarding the veracity of case studies but actively advanced those domains of inquiry in which case studies enjoy a distinctive epistemological ‘comparative advantage’. In turn, the veritable explosion of case studies of development processes now being prepared by academic groups, domestic governments, and international agencies around the world offers unprecedented opportunities for researchers to refine still further the underlying techniques, methodological principles, and theory on which the case study itself ultimately rests. As such, the time is ripe for a mutually beneficial dialogue between scholars and practitioners of development – a dialogue we hope this volume can inspire.
The views expressed in this chapter are those of the authors alone, and should not be attributed to the organizations with which they are affiliated.
1 For example, see Reference Barma, Huybens and Viñuela Barma, Huybens, and Viñuela (2014) ; Reference Brixi, Lust and Woolcock Brixi, Lust, and Woolcock (2015) ; and Reference Woolcock Woolcock (2013) .
2 See https://successfulsocieties.princeton.edu/ .
3 GDI’s case studies are available (by clicking on “Case studies” under the search category “Resource type”) at www.effectivecooperation.org/search/resources .
4 Reference Van Noorden, Maher and Nuzzo Van Noorden et al. (2014) also provide a direct link to the dataset on which this empirical claim rests. As of this writing, according to Google Scholar, Yin’s book (across all six editions) has been cited over 220,000 times; see also Robert Stake’s The Art of Case Study Research ( Reference Stake 1995 ), which has been cited more than 51,000 times.
5 In addition to those already listed, other key texts on the theory and practice of case studies include Reference Feagin, Orum and Sjoberg Feagin, Orum and Sjoberg (1991) , Reference Ragin and Becker Ragin and Becker (1992) , Reference Bates, Avner Greif, Rosethal and Weingast Bates et al. (1998) , Reference Byrne and Ragin Byrne and Ragin (2009) , and Reference Gerring Gerring (2017) . See also Reference Flyvbjerg Flyvbjerg (2006) .
6 As such, this volume continues earlier dialogues between scholars and development practitioners in the fields of history ( Reference Bayly, Rao, Szreter and Woolcock Bayly et al. 2011 ), law ( Reference Tamanaha, Sage and Woolcock Tamanaha et al. 2012 ), and multilateralism ( Reference Singh and Woolcock Singh and Woolcock, forthcoming ).
7 The initial study in what has become a sequence is Reference Bliss and Stern Bliss and Stern (1982) ; for subsequent rounds, see Reference Lanjouw and Stern Lanjouw and Stern (1998) and Reference Lanjouw, Murgai and Stern Lanjouw, Murgai, and Stern (2013) . This study remains ongoing, and is now in its seventh decade.
8 Reference Glavey and Haas Glavey and Haas (2015) .
9 Reference Glavey and Haas Glavey and Haas (2015) .
10 For example, if it can be shown empirically that, in general, countries that exit from bilateral trade agreements show a subsequent improvement in their “rule of law” scores, does this provide warrant for advising (say) Senegal that if it wants to improve its “rule of law” then it should exit from all its bilateral trade agreements? We think not.
11 Reference Hima and Santibanez Hima and Santibanez (2015) .
12 Reference Estabridis and Nieto Estabridis and Nieto (2015) .
13 Reference Ortega Nieto and Parida Ortega Nieto and Parida (2015) .
14 In the best of all possible worlds, we would want to draw the cases systematically from a known universe or population, but the absence of such a dataset meant we had to satisfice and match organizations on function while varying context means. Conclusions reached thus need to be qualified by the recognition that there could be more cases “out there,” which, if included in the analysis, might alter the initial results.
15 The ISS program began with a similar aim. The questions at the heart of the program were “What makes the countries that pull off institutional transformation different from others? What have they done that others could do to increase government capacity? What can be learned from the positive deviants, in particular?” For a variety of reasons having to do with the nature of the subject matter, the program disaggregated the subject and focused on responses to particular kinds of strategic challenges within countries and why some had negotiated these successfully in some periods and places but not in others.
16 These general standards, importantly, are consistent with a recent interdisciplinary effort to define rigor in case study research, which took place under the auspices of the US National Science Foundation. See Report on the Workshop on Interdisciplinary Standards for Systematic Qualitative Research. Available at: https://oconnell.fas.harvard.edu/files/lamont/files/issqr_workshop_rpt.pdf .
Save book to Kindle
To save this book to your Kindle, first ensure [email protected] is added to your Approved Personal Document E-mail List under your Personal Document Settings on the Manage Your Content and Devices page of your Amazon account. Then enter the ‘name’ part of your Kindle email address below. Find out more about saving to your Kindle .
Note you can select to save to either the @free.kindle.com or @kindle.com variations. ‘@free.kindle.com’ emails are free but can only be saved to your device when it is connected to wi-fi. ‘@kindle.com’ emails can be delivered even when you are not connected to wi-fi, but note that service fees apply.
Find out more about the Kindle Personal Document Service .
- Using Case Studies to Enhance the Quality of Explanation and Implementation
- By Jennifer Widner , Michael Woolcock , Daniel Ortega Nieto
- Edited by Jennifer Widner , Princeton University, New Jersey , Michael Woolcock , Daniel Ortega Nieto
- Book: The Case for Case Studies
- Online publication: 05 May 2022
- Chapter DOI: https://doi.org/10.1017/9781108688253.002
Save book to Dropbox
To save content items to your account, please confirm that you agree to abide by our usage policies. If this is the first time you use this feature, you will be asked to authorise Cambridge Core to connect with your account. Find out more about saving content to Dropbox .
Save book to Google Drive
To save content items to your account, please confirm that you agree to abide by our usage policies. If this is the first time you use this feature, you will be asked to authorise Cambridge Core to connect with your account. Find out more about saving content to Google Drive .
Maintaining Data Quality from Multiple Sources Case Study

There is a wealth of data within the healthcare industry that can be used to drive innovation, direct care, change the way systems function, and create solutions to improve patient outcomes. But with all this information coming in from multiple unique sources that all have their own ways of doing things, ensuring data quality is more important than ever.
The COVID-19 pandemic highlighted breakthroughs in data sharing and interoperability advances in the past few years. However, that does not mean that there aren’t challenges when it comes to data quality.
“As we have seen, many organizations have created so many amazing solutions around data,” Mujeeb Basit, MD, associate chief medical informatics officer and associate director, Clinical Informatics Center, University of Texas Southwestern Medical Center said. “COVID really highlighted the innovations and what you can do with sophisticated data architectures and how that flow of data really helps us understand what's happening in our communities. Data has become even more important.”
Dr. Basit shared some of his organization’s experiences in creating strategies to improve data quality while making the process as seamless as possible for all stakeholders.
The medical center had four groups working together on solution co-development, including quality, clinical operations, information resources and analytics.
“It is the synergy of working together and aligning our goals that really helps us develop singular data pipelines as well as workflows and outcomes that we're all vested in,” Dr. Basit said.
Finding Errors
One of the problems the organization previously faced was that errors would slowly accumulate in their systems because of complicated processes or frequent updates. When an error was found, Dr. Basit noted it was usually fixed as a single entity, and sometimes a backlog is fixed.
“But what happens is, over time, this error rate redevelops. How do we take this knowledge gained in this reported error event and then make that a sustainable solution long term? And this becomes exceedingly hard because that relationship may be across multiple systems,” Dr. Basit said.
He shared an example of how this had happened while adding procedures into their system that become charges, which then get translated into claim files.
“But if that charge isn't appropriately flagged, we actually don't get that,” Dr. Basit said. “This is missing a rate and missing a charge, and therefore, we will not get revenue associated with it. So, we need to make sure that this flag is appropriately set and this code is appropriately captured.”
His team created a workaround for this data quality issue where they will use a user story in their development environment and fix the error, but this is just a band-aid solution to the problem.
“As additional analysts are hired, they may not know this requirement, and errors can reoccur. So how do you solve this globally and sustain that solution over time? And for us, the outcome is significantly lost work, lost reimbursement, as well as denials, and this is just unnecessary work that is creating a downstream problem for us,” Dr. Basit said.
Their solution? Apply analysis at regular intervals to keep error rates low.
“This is not sustainable by applying people to it, but it is by applying technology to it. We approach it as an early detection problem. No repeat failures, automate it so we don't have to apply additional resources for it, and therefore, it scales very, very well, as well as reduced time to resolution, and it is a trackable solution for us,” Dr. Basit said.
To accomplish this, they utilized a framework for integrated tests (FIT) and built a SQL server solution that intermittently runs to look for new errors. When one is found, a message is sent to an analyst to determine a solution.
“We have two types of automated testing. You have reactive where someone identifies the problem and puts in the error for a solution, and we have preventative,” Dr. Basit said.
The outcome of this solution means they are saving time and money—something the leadership within the University of Texas Southwestern Medical Center has taken notice of. They are now requesting FIT tests to ensure errors do not reoccur.
“This has now become a part of their vocabulary as we have a culture of data-driven approaches and quality,” Dr. Basit said.
Applying the Data Efficiently
Another challenge they faced was streamlining different types of information coming in through places like the patient portal and EHR while maintaining data quality.
“You can't guarantee 100% consistency in a real-time capture system. They would require a lot of guardrails in order to do that, and the clinicians will probably get enormously frustrated,” Dr. Basit said. “So we go for reasonable accuracy of the data. And then we leverage our existing technologies to drive this.”
He used an example from his organization about a rheumatology assessment to determine the day-to-day life of someone with the condition. They use a patient questionnaire to create a system scoring system, and providers also conduct an assessment.
“Those two data elements get linked together during the visit so that we can then get greater insight on it. From that, we're able to use alerting mechanisms to drive greater responsiveness to the patient,” Dr. Basit said.
Conducting this data quality technology at scale was a challenge, but Dr. Basit and his colleagues utilized the Agile methodology to help.
“We didn't have sufficient staff to complete our backlog. What would happen is somebody would propose a problem, and by the time we finally got to solve it, they'd not be interested anymore, or that faculty member has left, or that problem is no longer an issue, and we have failed our population,” Dr. Basit said. “So for us, success is really how quickly can we get that solution implemented, and how many people will actually use it, and how many patients will it actually benefit. And this is a pretty large goal.”
The Agile methodology focused on:
- Consistency
- Minimizing documentation
- Incremental work products that can be used as a single entity
They began backlog sprint planning, doing two-week sprints at a time.
“We want to be able to demonstrate that we're able to drive value and correct those problems that we talked about earlier in a very rapid framework. The key to that is really this user story, the lightweight requirement gathering to improve our workflow,” Dr. Basit said. “So you really want to focus as a somebody, and put yourself in the role of the user who's having this problem.”
An example of this would be a rheumatologist wanting to know if their patient is not on a disease-modifying anti-rheumatic drug (DMARD) so that their patient can receive optimal therapy for their rheumatoid arthritis.
“This is really great for us, and what we do is we take this user story and we digest it. And especially the key part here is everything that comes out for the ‘so that,’ and that really tells us what our success measures are for this project. This should only take an hour or two, but it tells so much information about what we want to do,” Dr. Basit said.
Acceptance criteria they look for include:
- Independent
- Estimatable
“And we try to really stick to this, and that has driven us to success in terms of leveraging our data quality and improving our overall workflow as much as possible,” Dr. Basit said.
With the rheumatology project, they were able to reveal that increased compliance to DMARD showed an increase in low acuity disease and a decrease in high acuity.
“That's what we really want to go for. These are small changes but could be quite significant to those people's lives who it impacted,” Dr. Basit said.
In the end, the systems he and his team have created high-value solutions that clinicians and executives at their medical center use often.
“And over time we have built a culture where data comes first. People always ask, ‘What does the data say?’ Instead of sitting and wasting time on speculating on that solution,” Dr. Basit said.
The views and opinions expressed in this content or by commenters are those of the author and do not necessarily reflect the official policy or position of HIMSS or its affiliates.
Machine Learning & AI for Healthcare Forum
December 14–15, 2021 | Digital
Machine learning and AI are full of possibilities to address some of healthcare’s biggest challenges. Learn how leading healthcare organizations have leveraged the power of machine learning and AI to improve patient care and where they see real ROI—better care, cost containment, and operational improvements and efficiencies.
Register for the forum and get inspired

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- HHS Author Manuscripts
Single-Case Design, Analysis, and Quality Assessment for Intervention Research
Michele a. lobo.
1 Biomechanics & Movement Science Program, Department of Physical Therapy, University of Delaware, Newark, DE, USA
Mariola Moeyaert
2 Division of Educational Psychology & Methodology, State University of New York at Albany, Albany, NY, USA
Andrea Baraldi Cunha
Iryna babik, background and purpose.
The purpose of this article is to describe single-case studies, and contrast them with case studies and randomized clinical trials. We will highlight current research designs, analysis techniques, and quality appraisal tools relevant for single-case rehabilitation research.
Summary of Key Points
Single-case studies can provide a viable alternative to large group studies such as randomized clinical trials. Single case studies involve repeated measures, and manipulation of and independent variable. They can be designed to have strong internal validity for assessing causal relationships between interventions and outcomes, and external validity for generalizability of results, particularly when the study designs incorporate replication, randomization, and multiple participants. Single case studies should not be confused with case studies/series (ie, case reports), which are reports of clinical management of one patient or a small series of patients.
Recommendations for Clinical Practice
When rigorously designed, single-case studies can be particularly useful experimental designs in a variety of situations, even when researcher resources are limited, studied conditions have low incidences, or when examining effects of novel or expensive interventions. Readers will be directed to examples from the published literature in which these techniques have been discussed, evaluated for quality, and implemented.
Introduction
The purpose of this article is to present current tools and techniques relevant for single-case rehabilitation research. Single-case (SC) studies have been identified by a variety of names, including “n of 1 studies” and “single-subject” studies. The term “single-case study” is preferred over the previously mentioned terms because previous terms suggest these studies include only one participant. In fact, as will be discussed below, for purposes of replication and improved generalizability, the strongest SC studies commonly include more than one participant.
A SC study should not be confused with a “case study/series “ (also called “case report”. In a typical case study/series, a single patient or small series of patients is involved, but there is not a purposeful manipulation of an independent variable, nor are there necessarily repeated measures. Most case studies/series are reported in a narrative way while results of SC studies are presented numerically or graphically. 1 , 2 This article defines SC studies, contrasts them with randomized clinical trials, discusses how they can be used to scientifically test hypotheses, and highlights current research designs, analysis techniques, and quality appraisal tools that may be useful for rehabilitation researchers.
In SC studies, measurements of outcome (dependent variables) are recorded repeatedly for individual participants across time and varying levels of an intervention (independent variables). 1 – 5 These varying levels of intervention are referred to as “phases” with one phase serving as a baseline or comparison, so each participant serves as his/her own control. 2 In contrast to case studies and case series in which participants are observed across time without experimental manipulation of the independent variable, SC studies employ systematic manipulation of the independent variable to allow for hypothesis testing. 1 , 6 As a result, SC studies allow for rigorous experimental evaluation of intervention effects and provide a strong basis for establishing causal inferences. Advances in design and analysis techniques for SC studies observed in recent decades have made SC studies increasingly popular in educational and psychological research. Yet, the authors believe SC studies have been undervalued in rehabilitation research, where randomized clinical trials (RCTs) are typically recommended as the optimal research design to answer questions related to interventions. 7 In reality, there are advantages and disadvantages to both SC studies and RCTs that should be carefully considered in order to select the best design to answer individual research questions. While there are a variety of other research designs that could be utilized in rehabilitation research, only SC studies and RCTs are discussed here because SC studies are the focus of this article and RCTs are the most highly recommended design for intervention studies. 7
When designed and conducted properly, RCTs offer strong evidence that changes in outcomes may be related to provision of an intervention. However, RCTs require monetary, time, and personnel resources that many researchers, especially those in clinical settings, may not have available. 8 RCTs also require access to large numbers of consenting participants that meet strict inclusion and exclusion criteria that can limit variability of the sample and generalizability of results. 9 The requirement for large participant numbers may make RCTs difficult to perform in many settings, such as rural and suburban settings, and for many populations, such as those with diagnoses marked by lower prevalence. 8 To rely exclusively on RCTs has the potential to result in bodies of research that are skewed to address the needs of some individuals while neglecting the needs of others. RCTs aim to include a large number of participants and to use random group assignment to create study groups that are similar to one another in terms of all potential confounding variables, but it is challenging to identify all confounding variables. Finally, the results of RCTs are typically presented in terms of group means and standard deviations that may not represent true performance of any one participant. 10 This can present as a challenge for clinicians aiming to translate and implement these group findings at the level of the individual.
SC studies can provide a scientifically rigorous alternative to RCTs for experimentally determining the effectiveness of interventions. 1 , 2 SC studies can assess a variety of research questions, settings, cases, independent variables, and outcomes. 11 There are many benefits to SC studies that make them appealing for intervention research. SC studies may require fewer resources than RCTs and can be performed in settings and with populations that do not allow for large numbers of participants. 1 , 2 In SC studies, each participant serves as his/her own comparison, thus controlling for many confounding variables that can impact outcome in rehabilitation research, such as gender, age, socioeconomic level, cognition, home environment, and concurrent interventions. 2 , 11 Results can be analyzed and presented to determine whether interventions resulted in changes at the level of the individual, the level at which rehabilitation professionals intervene. 2 , 12 When properly designed and executed, SC studies can demonstrate strong internal validity to determine the likelihood of a causal relationship between the intervention and outcomes and external validity to generalize the findings to broader settings and populations. 2 , 12 , 13
Single Case Research Designs for Intervention Research
There are a variety of SC designs that can be used to study the effectiveness of interventions. Here we discuss: 1) AB designs, 2) reversal designs, 3) multiple baseline designs, and 4) alternating treatment designs, as well as ways replication and randomization techniques can be used to improve internal validity of all of these designs. 1 – 3 , 12 – 14
The simplest of these designs is the AB Design 15 ( Figure 1 ). This design involves repeated measurement of outcome variables throughout a baseline control/comparison phase (A ) and then throughout an intervention phase (B). When possible, it is recommended that a stable level and/or rate of change in performance be observed within the baseline phase before transitioning into the intervention phase. 2 As with all SC designs, it is also recommended that there be a minimum of five data points in each phase. 1 , 2 There is no randomization or replication of the baseline or intervention phases in the basic AB design. 2 Therefore, AB designs have problems with internal validity and generalizability of results. 12 They are weak in establishing causality because changes in outcome variables could be related to a variety of other factors, including maturation, experience, learning, and practice effects. 2 , 12 Sample data from a single case AB study performed to assess the impact of Floor Play intervention on social interaction and communication skills for a child with autism 15 are shown in Figure 1 .

An example of results from a single-case AB study conducted on one participant with autism; two weeks of observation (baseline phase A) were followed by seven weeks of Floor Time Play (intervention phase B). The outcome measure Circles of Communications (reciprocal communication with two participants responding to each other verbally or nonverbally) served as a behavioral indicator of the child’s social interaction and communication skills (higher scores indicating better performance). A statistically significant improvement in Circles of Communication was found during the intervention phase as compared to the baseline. Note that although a stable baseline is recommended for SC studies, it is not always possible to satisfy this requirement, as you will see in Figures 1 – 4 . Data were extracted from Dionne and Martini (2011) 15 utilizing Rohatgi’s WebPlotDigitizer software. 78
If an intervention does not have carry-over effects, it is recommended to use a Reversal Design . 2 For example, a reversal A 1 BA 2 design 16 ( Figure 2 ) includes alternation of the baseline and intervention phases, whereas a reversal A 1 B 1 A 2 B 2 design 17 ( Figure 3 ) consists of alternation of two baseline (A 1 , A 2 ) and two intervention (B 1 , B 2 ) phases. Incorporating at least four phases in the reversal design (i.e., A 1 B 1 A 2 B 2 or A 1 B 1 A 2 B 2 A 3 B 3 …) allows for a stronger determination of a causal relationship between the intervention and outcome variables, because the relationship can be demonstrated across at least three different points in time – change in outcome from A 1 to B 1 , from B 1 to A 2 , and from A 2 to B 2 . 18 Before using this design, however, researchers must determine that it is safe and ethical to withdraw the intervention, especially in cases where the intervention is effective and necessary. 12

An example of results from a single-case A 1 BA 2 study conducted on eight participants with stable multiple sclerosis (data on three participants were used for this example). Four weeks of observation (baseline phase A 1 ) were followed by eight weeks of core stability training (intervention phase B), then another four weeks of observation (baseline phase A 2 ). Forward functional reach test (the maximal distance the participant can reach forward or lateral beyond arm’s length, maintaining a fixed base of support in the standing position; higher scores indicating better performance) significantly improved during intervention for Participants 1 and 3 without further improvement observed following withdrawal of the intervention (during baseline phase A 2 ). Data were extracted from Freeman et al. (2010) 16 utilizing Rohatgi’s WebPlotDigitizer software. 78

An example of results from a single-case A 1 B 1 A 2 B 2 study conducted on two participants with severe unilateral neglect after a right-hemisphere stroke. Two weeks of conventional treatment (baseline phases A 1, A 2 ) alternated with two weeks of visuo-spatio-motor cueing (intervention phases B 1 , B 2 ). Performance was assessed in two tests of lateral neglect, the Bells Cancellation Test (Figure A; lower scores indicating better performance) and the Line Bisection Test (Figure B; higher scores indicating better performance). There was a statistically significant intervention-related improvement in participants’ performance on the Line Bisection Test, but not on the Bells Test. Data were extracted from Samuel at al. (2000) 17 utilizing Rohatgi’s WebPlotDigitizer software. 78
A recent study used an ABA reversal SC study to determine the effectiveness of core stability training in 8 participants with multiple sclerosis. 16 During the first four weekly data collections, the researchers ensured a stable baseline, which was followed by eight weekly intervention data points, and concluded with four weekly withdrawal data points. Intervention significantly improved participants’ walking and reaching performance ( Figure 2 ). 16 This A 1 BA 2 design could have been strengthened by the addition of a second intervention phase for replication (A 1 B 1 A 2 B 2 ). For instance, a single-case A 1 B 1 A 2 B 2 withdrawal design aimed to assess the efficacy of rehabilitation using visuo-spatio-motor cueing for two participants with severe unilateral neglect after a severe right-hemisphere stroke. 17 Each phase included 8 data points. Statistically significant intervention-related improvement was observed, suggesting that visuo-spatio-motor cueing might be promising for treating individuals with very severe neglect ( Figure 3 ). 17
The reversal design can also incorporate a cross over design where each participant experiences more than one type of intervention. For instance, a B 1 C 1 B 2 C 2 design could be used to study the effects of two different interventions (B and C) on outcome measures. Challenges with including more than one intervention involve potential carry-over effects from earlier interventions and order effects that may impact the measured effectiveness of the interventions. 2 , 12 Including multiple participants and randomizing the order of intervention phase presentations are tools to help control for these types of effects. 19
When an intervention permanently changes an individual’s ability, a return to baseline performance is not feasible and reversal designs are not appropriate. Multiple Baseline Designs (MBDs) are useful in these situations ( Figure 4 ). 20 MBDs feature staggered introduction of the intervention across time: each participant is randomly assigned to one of at least 3 experimental conditions characterized by the length of the baseline phase. 21 These studies involve more than one participant, thus functioning as SC studies with replication across participants. Staggered introduction of the intervention allows for separation of intervention effects from those of maturation, experience, learning, and practice. For example, a multiple baseline SC study was used to investigate the effect of an anti-spasticity baclofen medication on stiffness in five adult males with spinal cord injury. 20 The subjects were randomly assigned to receive 5–9 baseline data points with a placebo treatment prior to the initiation of the intervention phase with the medication. Both participants and assessors were blind to the experimental condition. The results suggested that baclofen might not be a universal treatment choice for all individuals with spasticity resulting from a traumatic spinal cord injury ( Figure 4 ). 20

An example of results from a single-case multiple baseline study conducted on five participants with spasticity due to traumatic spinal cord injury. Total duration of data collection was nine weeks. The first participant was switched from placebo treatment (baseline) to baclofen treatment (intervention) after five data collection sessions, whereas each consecutive participant was switched to baclofen intervention at the subsequent sessions through the ninth session. There was no statistically significant effect of baclofen on viscous stiffness at the ankle joint. Data were extracted from Hinderer at al. (1990) 20 utilizing Rohatgi’s WebPlotDigitizer software. 78
The impact of two or more interventions can also be assessed via Alternating Treatment Designs (ATDs) . In ATDs, after establishing the baseline, the experimenter exposes subjects to different intervention conditions administered in close proximity for equal intervals ( Figure 5 ). 22 ATDs are prone to “carry-over effects” when the effects of one intervention influence the observed outcomes of another intervention. 1 As a result, such designs introduce unique challenges when attempting to determine the effects of any one intervention and have been less commonly utilized in rehabilitation. An ATD was used to monitor disruptive behaviors in the school setting throughout a baseline followed by an alternating treatment phase with randomized presentation of a control condition or an exercise condition. 23 Results showed that 30 minutes of moderate to intense physical activity decreased behavioral disruptions through 90 minutes after the intervention. 23 An ATD was also used to compare the effects of commercially available and custom-made video prompts on the performance of multi-step cooking tasks in four participants with autism. 22 Results showed that participants independently performed more steps with the custom-made video prompts ( Figure 5 ). 22

An example of results from a single case alternating treatment study conducted on four participants with autism (data on two participants were used for this example). After the observation phase (baseline), effects of commercially available and custom-made video prompts on the performance of multi-step cooking tasks were identified (treatment phase), after which only the best treatment was used (best treatment phase). Custom-made video prompts were most effective for improving participants’ performance of multi-step cooking tasks. Data were extracted from Mechling at al. (2013) 22 utilizing Rohatgi’s WebPlotDigitizer software. 78
Regardless of the SC study design, replication and randomization should be incorporated when possible to improve internal and external validity. 11 The reversal design is an example of replication across study phases. The minimum number of phase replications needed to meet quality standards is three (A 1 B 1 A 2 B 2 ), but having four or more replications is highly recommended (A 1 B 1 A 2 B 2 A 3 …). 11 , 14 In cases when interventions aim to produce lasting changes in participants’ abilities, replication of findings may be demonstrated by replicating intervention effects across multiple participants (as in multiple-participant AB designs), or across multiple settings, tasks, or service providers. When the results of an intervention are replicated across multiple reversals, participants, and/or contexts, there is an increased likelihood a causal relationship exists between the intervention and the outcome. 2 , 12
Randomization should be incorporated in SC studies to improve internal validity and the ability to assess for causal relationships among interventions and outcomes. 11 In contrast to traditional group designs, SC studies often do not have multiple participants or units that can be randomly assigned to different intervention conditions. Instead, in randomized phase-order designs , the sequence of phases is randomized. Simple or block randomization is possible. For example, with simple randomization for an A 1 B 1 A 2 B 2 design, the A and B conditions are treated as separate units and are randomly assigned to be administered for each of the pre-defined data collection points. As a result, any combination of A-B sequences is possible without restrictions on the number of times each condition is administered or regard for repetitions of conditions (e.g., A 1 B 1 B 2 A 2 B 3 B 4 B 5 A 3 B 6 A 4 A 5 A 6 ). With block randomization for an A 1 B 1 A 2 B 2 design, two conditions (e.g., A and B) would be blocked into a single unit (AB or BA), randomization of which to different time periods would ensure that each condition appears in the resulting sequence more than two times (e.g., A 1 B 1 B 2 A 2 A 3 B 3 A 4 B 4 ). Note that AB and reversal designs require that the baseline (A) always precedes the first intervention (B), which should be accounted for in the randomization scheme. 2 , 11
In randomized phase start-point designs , the lengths of the A and B phases can be randomized. 2 , 11 , 24 – 26 For example, for an AB design, researchers could specify the number of time points at which outcome data will be collected, (e.g., 20), define the minimum number of data points desired in each phase (e.g., 4 for A, 3 for B), and then randomize the initiation of the intervention so that it occurs anywhere between the remaining time points (points 5 and 17 in the current example). 27 , 28 For multiple-baseline designs, a dual-randomization, or “regulated randomization” procedure has been recommended. 29 If multiple-baseline randomization depends solely on chance, it could be the case that all units are assigned to begin intervention at points not really separated in time. 30 Such randomly selected initiation of the intervention would result in the drastic reduction of the discriminant and internal validity of the study. 29 To eliminate this issue, investigators should first specify appropriate intervals between the start points for different units, then randomly select from those intervals, and finally randomly assign each unit to a start point. 29
Single Case Analysis Techniques for Intervention Research
The What Works Clearinghouse (WWC) single-case design technical documentation provides an excellent overview of appropriate SC study analysis techniques to evaluate the effectiveness of intervention effects. 1 , 18 First, visual analyses are recommended to determine whether there is a functional relation between the intervention and the outcome. Second, if evidence for a functional effect is present, the visual analysis is supplemented with quantitative analysis methods evaluating the magnitude of the intervention effect. Third, effect sizes are combined across cases to estimate overall average intervention effects which contributes to evidence-based practice, theory, and future applications. 2 , 18
Visual Analysis
Traditionally, SC study data are presented graphically. When more than one participant engages in a study, a spaghetti plot showing all of their data in the same figure can be helpful for visualization. Visual analysis of graphed data has been the traditional method for evaluating treatment effects in SC research. 1 , 12 , 31 , 32 The visual analysis involves evaluating level, trend, and stability of the data within each phase (i.e., within-phase data examination) followed by examination of the immediacy of effect, consistency of data patterns, and overlap of data between baseline and intervention phases (i.e., between-phase comparisons). When the changes (and/or variability) in level are in the desired direction, are immediate, readily discernible, and maintained over time, it is concluded that the changes in behavior across phases result from the implemented treatment and are indicative of improvement. 33 Three demonstrations of an intervention effect are necessary for establishing a functional relation. 1
Within-phase examination
Level, trend, and stability of the data within each phase are evaluated. Mean and/or median can be used to report the level, and trend can be evaluated by determining whether the data points are monotonically increasing or decreasing. Within-phase stability can be evaluated by calculating the percentage of data points within 15% of the phase median (or mean). The stability criterion is satisfied if about 85% (80% – 90%) of the data in a phase fall within a 15% range of the median (or average) of all data points for that phase. 34
Between-phase examination
Immediacy of effect, consistency of data patterns, and overlap of data between baseline and intervention phases are evaluated next. For this, several nonoverlap indices have been proposed that all quantify the proportion of measurements in the intervention phase not overlapping with the baseline measurements. 35 Nonoverlap statistics are typically scaled as percent from 0 to 100, or as a proportion from 0 to 1. Here, we briefly discuss the Nonoverlap of All Pairs ( NAP ), 36 the Extended Celeration Line ( ECL ), the Improvement Rate Difference ( IRD) , 37 and the TauU and the TauU-adjusted, TauU adj , 35 as these are the most recent and complete techniques. We also examine the Percentage of Nonoverlapping Data ( PND ) 38 and the Two Standard Deviations Band Method, as these are frequently used techniques. In addition, we include the Percentage of Nonoverlapping Corrected Data ( PNCD ) – an index applying to the PND after controlling for baseline trend. 39
Nonoverlap of all pairs (NAP)
Each baseline observation can be paired with each intervention phase observation to make n pairs (i.e., N = n A * n B ). Count the number of overlapping pairs, n o , counting all ties as 0.5. Then define the percent of the pairs that show no overlap. Alternatively, one can count the number of positive (P), negative (N), and tied (T) pairs 2 , 36 :
Extended Celeration Line (ECL)
ECL or split middle line allows control for a positive Phase A trend. Nonoverlap is defined as the proportion of Phase B ( n b ) data that are above the median trend plotted from Phase A data ( n B< sub > Above Median trend A </ sub > ), but then extended into Phase B: ECL = n B Above Median trend A n b ∗ 100
As a consequence, this method depends on a straight line and makes an assumption of linearity in the baseline. 2 , 12
Improvement rate difference (IRD)
This analysis is conceptualized as the difference in improvement rates (IR) between baseline ( IR B ) and intervention phases ( IR T ). 38 The IR for each phase is defined as the number of “improved data points” divided by the total data points in that phase. IRD, commonly employed in medical group research under the name of “risk reduction” or “risk difference” attempts to provide an intuitive interpretation for nonoverlap and to make use of an established, respected effect size, IR B - IR B , or the difference between two proportions. 37
TauU and TauU adj
Each baseline observation can be paired with each intervention phase observation to make n pairs (i.e., n = n A * n B ). Count the number of positive (P), negative (N), and tied (T) pairs, and use the following formula: TauU = P - N P + N + τ
The TauU adj is an adjustment of TauU for monotonic trend in baseline. Each baseline observation can be paired with each intervention phase observation to make n pairs (i.e., n = n A * n B ). Each baseline observation can be paired with all later baseline observations (n A *(n A -1)/2). 2 , 35 Then the baseline trend can be computed: TauU adf = P - N - S trend P + N + τ ; S trend = P A – NA
Online calculators might assist researchers in obtaining the TauU and TauU adjusted coefficients ( http://www.singlecaseresearch.org/calculators/tau-u ).
Percentage of nonoverlapping data (PND)
If anticipating an increase in the outcome, locate the highest data point in the baseline phase and then calculate the percent of the intervention phase data points that exceed it. If anticipating a decrease in the outcome, find the lowest data point in the baseline phase and then calculate the percent of the treatment phase data points that are below it: PND = n B Overlap A n b ∗ 100 . A PND < 50 would mark no observed effect, PND = 50–70 signifies a questionable effect, and PND > 70 suggests the intervention was effective. 40 The percentage of nonoverlapping (PNDC) corrected was proposed in 2009 as an extension of the PND. 39 Prior to applying the PND, a data correction procedure is applied eliminating pre-existing baseline trend. 38
Two Standard Deviation Band Method
When the stability criterion described above is met within phases, it is possible to apply the two standard deviation band method. 12 , 41 First, the mean of the data for a specific condition is calculated and represented with a solid line. In the next step, the standard deviation of the same data is computed and two dashed lines are represented: one located two standard deviations above the mean and the other – two standard deviations below. For normally distributed data, few points (less than 5%) are expected to be outside the two standard deviation bands if there is no change in the outcome score due to the intervention. However, this method is not considered a formal statistical procedure, as the data cannot typically be assumed to be normal, continuous, or independent. 41
Statistical Analysis
If the visual analysis indicates a functional relationship (i.e., three demonstrations of the effectiveness of the intervention effect), it is recommended to proceed with the quantitative analyses, reflecting the magnitude of the intervention effect. First, effect sizes are calculated for each participant (individual-level analysis). Moreover, if the research interest lies in the generalizability of the effect size across participants, effect sizes can be combined across cases to achieve an overall average effect size estimate (across-case effect size).
Note that quantitative analysis methods are still being developed in the domain of SC research 1 and statistical challenges of producing an acceptable measure of treatment effect remain. 14 , 42 , 43 Therefore, the WWC standards strongly recommend conducting sensitivity analysis and reporting multiple effect size estimators. If consistency across different effect size estimators is identified, there is stronger evidence for the effectiveness of the treatment. 1 , 18
Individual-level effect size analysis
The most common effect sizes recommended for SC analysis are: 1) standardized mean difference Cohen’s d ; 2) standardized mean difference with correction for small sample sizes Hedges’ g ; and 3) the regression-based approach which has the most potential and is strongly recommended by the WWC standards. 1 , 44 , 45 Cohen’s d can be calculated using following formula: d = X A ¯ - X B ¯ s p , with X A ¯ being the baseline mean, X B ¯ being the treatment mean, and s p indicating the pooled within-case standard deviation. Hedges’ g is an extension of Cohen’s d , recommended in the context of SC studies as it corrects for small sample sizes. The piecewise regression-based approach does not only reflect the immediate intervention effect, but also the intervention effect across time:
i stands for the measurement occasion ( i = 0, 1,… I ). The dependent variable is regressed on a time indicator, T , which is centered around the first observation of the intervention phase, D , a dummy variable for the intervention phase, and an interaction term of these variables. The equation shows that the expected score, Ŷ i , equals β 0 + β 1 T i in the baseline phase, and ( β 0 + β 2 ) + ( β 1 + β 3 ) T i in the intervention phase. β 0 , therefore, indicates the expected baseline level at the start of the intervention phase (when T = 0), whereas β 1 marks the linear time trend in the baseline scores. The coefficient β 2 can then be interpreted as an immediate effect of the intervention on the outcome, whereas β 3 signifies the effect of the intervention across time. The e i ’s are residuals assumed to be normally distributed around a mean of zero with a variance of σ e 2 . The assumption of independence of errors is usually not met in the context of SC studies because repeated measures are obtained within a person. As a consequence, it can be the case that the residuals are autocorrelated, meaning that errors closer in time are more related to each other compared to errors further away in time. 46 – 48 As a consequence, a lag-1 autocorrelation is appropriate (taking into account the correlation between two consecutive errors: e i and e i –1 ; for more details see Verbeke & Molenberghs, (2000). 49 In Equation 1 , ρ indicates the autocorrelation parameter. If ρ is positive, the errors closer in time are more similar; if ρ is negative, the errors closer in time are more different, and if ρ equals zero, there is no correlation between the errors.
Across-case effect sizes
Two-level modeling to estimate the intervention effects across cases can be used to evaluate across-case effect sizes. 44 , 45 , 50 Multilevel modeling is recommended by the WWC standards because it takes the hierarchical nature of SC studies into account: measurements are nested within cases and cases, in turn, are nested within studies. By conducting a multilevel analysis, important research questions can be addressed (which cannot be answered by single-level analysis of SC study data), such as: 1) What is the magnitude of the average treatment effect across cases? 2) What is the magnitude and direction of the case-specific intervention effect? 3) How much does the treatment effect vary within cases and across cases? 4) Does a case and/or study level predictor influence the treatment’s effect? The two-level model has been validated in previous research using extensive simulation studies. 45 , 46 , 51 The two-level model appears to have sufficient power (> .80) to detect large treatment effects in at least six participants with six measurements. 21
Furthermore, to estimate the across-case effect sizes, the HPS (Hedges, Pustejovsky, and Shadish) , or single-case educational design ( SCEdD)-specific mean difference, index can be calculated. 52 This is a standardized mean difference index specifically designed for SCEdD data, with the aim of making it comparable to Cohen’s d of group-comparison designs. The standard deviation takes into account both within-participant and between-participant variability, and is typically used to get an across-case estimator for a standardized change in level. The advantage of using the HPS across-case effect size estimator is that it is directly comparable with Cohen’s d for group comparison research, thus enabling the use of Cohen’s (1988) benchmarks. 53
Valuable recommendations on SC data analyses have recently been provided. 54 , 55 They suggest that a specific SC study data analytic technique can be chosen based on: (1) the study aims and the desired quantification (e.g., overall quantification, between-phase quantifications, randomization, etc.), (2) the data characteristics as assessed by visual inspection and the assumptions one is willing to make about the data, and (3) the knowledge and computational resources. 54 , 55 Table 1 lists recommended readings and some commonly used resources related to the design and analysis of single-case studies.
Recommend readings and resources related to the design and analysis of single-case studies.
| General Readings on Single-Case Research Design and Analysis | |
|---|---|
| 3rd ed. Needham Heights, MA: Allyn & Bacon; 2008. New York, NY: Oxford University Press; 2010. Hillsdale, NJ: Lawrence Erlbaum Associates; 1992. Washington, D.C.: American Psychological Association; 2014. Philadelphia, PA: F. A. Davis Company; 2015. | |
| Reversal Design | |
| Multiple Baseline Design | |
| Alternating Treatment Design | |
| Randomization | |
| Analysis | |
| Visual Analysis | |
| Percentage of Nonoverlapping Data (PND) | |
| Nonoverlap of All Pairs (NAP) | |
| Improvement Rate Difference (IRD) | |
| Tau-U/Piecewise Regression | |
| HLM | |
Quality Appraisal Tools for Single-Case Design Research
Quality appraisal tools are important to guide researchers in designing strong experiments and conducting high-quality systematic reviews of the literature. Unfortunately, quality assessment tools for SC studies are relatively novel, ratings across tools demonstrate variability, and there is currently no “gold standard” tool. 56 Table 2 lists important SC study quality appraisal criteria compiled from the most common scales; when planning studies or reviewing the literature, we recommend readers consider these criteria. Table 3 lists some commonly used SC quality assessment and reporting tools and references to resources where the tools can be located.
Summary of important single-case study quality appraisal criteria.
| Criteria | Requirements |
|---|---|
| 1. Design | The design is appropriate for evaluating the intervention. |
| 2. Method details | Participants’ characteristics, selection method, and testing setting specifics are adequately detailed to allow future replication. |
| 3. Independent variable , , , | The independent variable (i.e., the intervention) is thoroughly described to allow replication; fidelity of the intervention is thoroughly documented; the independent variable is systematically manipulated under the control of the experimenter. |
| 4. Dependent variable , , | Each dependent/outcome variable is quantifiable. Each outcome variable is measured systematically and repeatedly across time to ensure the acceptable 0.80–0.90 inter-assessor percent agreement (or ≥0.60 Cohen’s kappa) on at least 20% of sessions. |
| 5. Internal validity , , | The study includes at least three attempts to demonstrate an intervention effect at three different points in time or with three different phase replications. Design-specific recommendations: 1) for reversal designs, a study should have ≥4 phases with ≥5 points, 2) for alternating intervention designs, a study should have ≥5 points per condition with ≤2 points per phase, 3) for multiple baseline designs, a study should have ≥6 phases with ≥5 points to meet the WWC standards without reservations . Assessors are independent and blind to experimental conditions. |
| 6. External Validity | Experimental effects should be replicated across participants, settings, tasks, and/or service providers. |
| 7. Face Validity , , | The outcome measure should be clearly operationally defined, have a direct unambiguous interpretation, and measure a construct is was designed to measure. |
| 8. Social Validity , | Both the outcome variable and the magnitude of change in outcome due to an intervention should be socially important, the intervention should be practical and cost effective. |
| 9. Sample attrition , | The sample attrition should be low and unsystematic, since loss of data in SC designs due to overall or differential attrition can produce biased estimates of the intervention’s effectiveness if that loss is systematically related to the experimental conditions. |
| 10. Randomization , | If randomization is used, the experimenter should make sure that: 1) equivalence is established at the baseline, and 2) the group membership is determined through a random process. |
Quality assessment and reporting tools related to single-case studies.
| Quality Assessment & Reporting Tools | |
|---|---|
| What Works Clearinghouse Standards (WWC) | Kratochwill, T.R., Hitchcock, J., Horner, R.H., et al. Institute of Education Sciences: What works clearinghouse: Procedures and standards handbook. . Published 2010. Accessed November 20, 2016. |
| Quality indicators from Horner et al. | Horner, R.H., Carr, E.G., Halle, J., McGee, G., Odom, S., Wolery, M. The use of single-subject research to identify evidence-based practice in special education. Except Children. 2005;71(2):165–179. |
| Evaluative Method | Reichow, B., Volkmar, F., Cicchetti, D. Development of the evaluative method for evaluating and determining evidence-based practices in autism. J Autism Dev Disord. 2008;38(7):1311–1319. |
| Certainty Framework | Simeonsson, R., Bailey, D. Evaluating programme impact: Levels of certainty. In: Mitchell, D., Brown, R., eds. London, England: Chapman & Hall; 1991:280–296. |
| Evidence in Augmentative and Alternative Communication Scales (EVIDAAC) | Schlosser, R.W., Sigafoos, J., Belfiore, P. EVIDAAC comparative single-subject experimental design scale (CSSEDARS). . Published 2009. Accessed November 20, 2016. |
| Single-Case Experimental Design (SCED) | Tate, R.L., McDonald, S., Perdices, M., Togher, L., Schulz, R., Savage, S. Rating the methodological quality of single-subject designs and n-of-1 trials: Introducing the Single-Case Experimental Design (SCED) Scale. Neuropsychol Rehabil. 2008;18(4):385–401. |
| Logan et al. Scales | Logan, L.R., Hickman, R.R., Harris, S.R., Heriza, C.B. Single-subject research design: Recommendations for levels of evidence and quality rating. Dev Med Child Neurol. 2008;50:99–103. |
| Single-Case Reporting Guideline In BEhavioural Interventions (SCRIBE) | Tate, R.L., Perdices, M., Rosenkoetter, U., et al. The Single-Case Reporting guideline In BEhavioural interventions (SCRIBE) 2016 statement. J School Psychol. 2016;56:133–142. |
| Theory, examples, and tools related to multilevel data analysis | Van den Noortgate, W., Ferron, J., Beretvas, S.N., Moeyaert, M. Multilevel synthesis of single-case experimental data. Katholieke Universiteit Leuven web site. . |
| Tools for computing between-cases standardized mean difference ( -statistic) | Pustejovsky, J.E. scdhlm: A web-based calculator for between-case standardized mean differences (Version 0.2) [Web application]. . |
| Tools for computing NAP, IRD, Tau and other statistics | Vannest, K.J., Parker, R.I., Gonen, O. Single case research: Web based calculators for SCR analysis (Version 1.0) [Web-based application]. College Atation, TX: Texas A&M University. Published 2011. Accessed November 20, 2016. . |
| Tools for obtaining graphical representations, means, trend lines, PND | Wright, J. Intervention central. Accessed November 20, 2016. |
| Access to free Simulation Modeling Analysis (SMA) Software | Borckardt, J.J. SMA Simulation Modeling Analysis: Time Series Analysis Program for Short Time Series Data Streams. Published 2006. . |
When an established tool is required for systematic review, we recommend use of the What Works Clearinghouse (WWC) Tool because it has well-defined criteria and is developed and supported by leading experts in the SC research field in association with the Institute of Education Sciences. 18 The WWC documentation provides clear standards and procedures to evaluate the quality of SC research; it assesses the internal validity of SC studies, classifying them as “Meeting Standards”, “Meeting Standards with Reservations”, or “Not Meeting Standards”. 1 , 18 Only studies classified in the first two categories are recommended for further visual analysis. Also, WWC evaluates the evidence of effect, classifying studies into “Strong Evidence of a Causal Relation”, “Moderate Evidence of a Causal Relation”, or “No Evidence of a Causal Relation”. Effect size should only be calculated for studies providing strong or moderate evidence of a causal relation.
The Single-Case Reporting Guideline In BEhavioural Interventions (SCRIBE) 2016 is another useful SC research tool developed recently to improve the quality of single-case designs. 57 SCRIBE consists of a 26-item checklist that researchers need to address while reporting the results of SC studies. This practical checklist allows for critical evaluation of SC studies during study planning, manuscript preparation, and review.
Single-case studies can be designed and analyzed in a rigorous manner that allows researchers strength in assessing causal relationships among interventions and outcomes, and in generalizing their results. 2 , 12 These studies can be strengthened via incorporating replication of findings across multiple study phases, participants, settings, or contexts, and by using randomization of conditions or phase lengths. 11 There are a variety of tools that can allow researchers to objectively analyze findings from SC studies. 56 While a variety of quality assessment tools exist for SC studies, they can be difficult to locate and utilize without experience, and different tools can provide variable results. The WWC quality assessment tool is recommended for those aiming to systematically review SC studies. 1 , 18
SC studies, like all types of study designs, have a variety of limitations. First, it can be challenging to collect at least five data points in a given study phase. This may be especially true when traveling for data collection is difficult for participants, or during the baseline phase when delaying intervention may not be safe or ethical. Power in SC studies is related to the number of data points gathered for each participant so it is important to avoid having a limited number of data points. 12 , 58 Second, SC studies are not always designed in a rigorous manner and, thus, may have poor internal validity. This limitation can be overcome by addressing key characteristics that strengthen SC designs ( Table 2 ). 1 , 14 , 18 Third, SC studies may have poor generalizability. This limitation can be overcome by including a greater number of participants, or units. Fourth, SC studies may require consultation from expert methodologists and statisticians to ensure proper study design and data analysis, especially to manage issues like autocorrelation and variability of data. 2 Fifth, while it is recommended to achieve a stable level and rate of performance throughout the baseline, human performance is quite variable and can make this requirement challenging. Finally, the most important validity threat to SC studies is maturation. This challenge must be considered during the design process in order to strengthen SC studies. 1 , 2 , 12 , 58
SC studies can be particularly useful for rehabilitation research. They allow researchers to closely track and report change at the level of the individual. They may require fewer resources and, thus, can allow for high-quality experimental research, even in clinical settings. Furthermore, they provide a tool for assessing causal relationships in populations and settings where large numbers of participants are not accessible. For all of these reasons, SC studies can serve as an effective method for assessing the impact of interventions.
Acknowledgments
This research was supported by the National Institute of Health, Eunice Kennedy Shriver National Institute of Child Health & Human Development (1R21HD076092-01A1, Lobo PI) and the Delaware Economic Development Office (Grant #109).
Some of the information in this manuscript was presented at the IV Step Meeting in Columbus, OH, June 2016.
- All Headlines

Top 40 Most Popular Case Studies of 2021
Two cases about Hertz claimed top spots in 2021's Top 40 Most Popular Case Studies
Two cases on the uses of debt and equity at Hertz claimed top spots in the CRDT’s (Case Research and Development Team) 2021 top 40 review of cases.
Hertz (A) took the top spot. The case details the financial structure of the rental car company through the end of 2019. Hertz (B), which ranked third in CRDT’s list, describes the company’s struggles during the early part of the COVID pandemic and its eventual need to enter Chapter 11 bankruptcy.
The success of the Hertz cases was unprecedented for the top 40 list. Usually, cases take a number of years to gain popularity, but the Hertz cases claimed top spots in their first year of release. Hertz (A) also became the first ‘cooked’ case to top the annual review, as all of the other winners had been web-based ‘raw’ cases.
Besides introducing students to the complicated financing required to maintain an enormous fleet of cars, the Hertz cases also expanded the diversity of case protagonists. Kathyrn Marinello was the CEO of Hertz during this period and the CFO, Jamere Jackson is black.
Sandwiched between the two Hertz cases, Coffee 2016, a perennial best seller, finished second. “Glory, Glory, Man United!” a case about an English football team’s IPO made a surprise move to number four. Cases on search fund boards, the future of malls, Norway’s Sovereign Wealth fund, Prodigy Finance, the Mayo Clinic, and Cadbury rounded out the top ten.
Other year-end data for 2021 showed:
- Online “raw” case usage remained steady as compared to 2020 with over 35K users from 170 countries and all 50 U.S. states interacting with 196 cases.
- Fifty four percent of raw case users came from outside the U.S..
- The Yale School of Management (SOM) case study directory pages received over 160K page views from 177 countries with approximately a third originating in India followed by the U.S. and the Philippines.
- Twenty-six of the cases in the list are raw cases.
- A third of the cases feature a woman protagonist.
- Orders for Yale SOM case studies increased by almost 50% compared to 2020.
- The top 40 cases were supervised by 19 different Yale SOM faculty members, several supervising multiple cases.
CRDT compiled the Top 40 list by combining data from its case store, Google Analytics, and other measures of interest and adoption.
All of this year’s Top 40 cases are available for purchase from the Yale Management Media store .
And the Top 40 cases studies of 2021 are:
1. Hertz Global Holdings (A): Uses of Debt and Equity
2. Coffee 2016
3. Hertz Global Holdings (B): Uses of Debt and Equity 2020
4. Glory, Glory Man United!
5. Search Fund Company Boards: How CEOs Can Build Boards to Help Them Thrive
6. The Future of Malls: Was Decline Inevitable?
7. Strategy for Norway's Pension Fund Global
8. Prodigy Finance
9. Design at Mayo
10. Cadbury
11. City Hospital Emergency Room
13. Volkswagen
14. Marina Bay Sands
15. Shake Shack IPO
16. Mastercard
17. Netflix
18. Ant Financial
19. AXA: Creating the New CR Metrics
20. IBM Corporate Service Corps
21. Business Leadership in South Africa's 1994 Reforms
22. Alternative Meat Industry
23. Children's Premier
24. Khalil Tawil and Umi (A)
25. Palm Oil 2016
26. Teach For All: Designing a Global Network
27. What's Next? Search Fund Entrepreneurs Reflect on Life After Exit
28. Searching for a Search Fund Structure: A Student Takes a Tour of Various Options
30. Project Sammaan
31. Commonfund ESG
32. Polaroid
33. Connecticut Green Bank 2018: After the Raid
34. FieldFresh Foods
35. The Alibaba Group
36. 360 State Street: Real Options
37. Herman Miller
38. AgBiome
39. Nathan Cummings Foundation
40. Toyota 2010
IMAGES
VIDEO
COMMENTS
Estimating and predicting groundwater quality characteristics so that managers may make management decisions is one of the critical goals of water resource planners and managers. The complexity of groundwater networks makes it difficult to predict either the time or the location of groundwater. Many models have been created in this area, offering better management to preserve water quality ...
Before (2019-2020) and after (2021-2022) implementation of the chronic disease management information system, chronic respiratory diseases case management quality indicators (number of managed cases, number of patients accepting routine follow-up services, follow-up visit rate, pulmonary function test rate, admission rate for acute ...
A new study showcases a successful quality improvement program that significantly enhances surgical safety. By implementing a standardized handoff protocol, known as SHRIMPS, the study demonstrates how effective communication in operating rooms (OR) can reduce the risk of errors and improve patient care. The findings are published in the Journal of the American College of Surgeons (JACS).
Currently, China's river water quality evaluation adopts the "Environmental Quality Standards for Surface Water", while the seawater quality evaluation uses the "Seawater Quality Standard". However, estuarine areas, where rivers meet the sea, do not have evaluation standards, and most often, the "Seawater Quality Standard" is applied. At present, the water quality in the estuary ...
The current study assessed the water quality of the irrigation water derived from the Hartbeespoort and Roodeplaat Dams. The two dams are found in the Crocodile (West) and Marico catchment which is renowned for its poor water quality and hyper-eutrophication levels. ... Assessment of water quality using principal component analysis: A case ...
Purpose To evaluate the value of five indicators in predicting OVCF through a retrospective case-control study, and explore the internal correlation of different indicators. Method We retrospectively enrolled patients over 50 years of age who had been subjected to surgery for fragility OVCF at China Japan Friendship Hospital from January 2021 to September 2023. Demographic characteristics, T ...
Using Exploratory Data Analysis to Improve the Fresh Foods Ordering Process in Retail Stores. This case study presents a real-world example of how the thought processes of data scientists can contribute to quality practice. See how explorative data analysis and basic statistics helped a grocery chain reduce inefficiencies in its retail ...
Leadership & Managing People Magazine Article. Arden C. Sims. Bruce Rayner. Globe Metallurgical Inc., a $115 million supplier for specialty metals, is best known as the first small company to win ...
For case-control studies, it is important that if matching was performed during the selection or recruitment process, the variables used as matching criteria (e.g., age, gender, race) should be controlled for in the analysis. General Guidance for Determining the Overall Quality Rating of Case-Controlled Studies
Some criticize case study for its high level of flexibility, perceiving it as less rigorous, and maintain that it generates inadequate results. 8 Others have noted issues with quality and consistency in how case studies are conducted and reported. 9 Reporting is often varied and inconsistent, using a mix of approaches such as case reports, case ...
According to Teresa Whitacre, of international consulting firm ASQ, proper quality management also boosts a company's profitability. "Total quality management allows the company to look at their management system as a whole entity — not just an output of the quality department," she says. "Total quality means the organisation looks at ...
These templates include all the essential sections of a case study and high-quality content to help you create case studies that position your business as an industry leader. Get More Out Of Your Case Studies With Visme. Case studies are an essential tool for converting potential customers into paying customers. By following the tips in this ...
The quality of a case study does not only depend on the empirical material collection and analysis but also on its reporting (Denzin & Lincoln, 1998). A sound report structure, along with "story-like" writing is crucial to case study reporting. The following points should be taken into consideration while reporting a case study.
The successfulness of this system can be measured by assessing the consistency of the product quality. Coca Cola say that 'Our Company's Global Product Quality Index rating has consistently reached averages near 94 since 2007, with a 94.3 in 2010, while our Company Global Package Quality Index has steadily increased since 2007 to a 92.6 rating in 2010, our highest value to date'.
AHRQ's evidence-based tools and resources are used by organizations nationwide to improve the quality, safety, effectiveness, and efficiency of health care. The Agency's Impact Case Studies highlight these successes, describing the use and impact of AHRQ-funded tools by State and Federal policy makers, health systems, clinicians ...
Determining the quality of data in case study research requires careful planning and execution. It's crucial to ensure that the data is reliable, accurate, and relevant to the research question. This involves selecting appropriate methods of collecting data, properly training interviewers or observers, and systematically recording and storing ...
Accurate inspections enable companies to assess the quality, safety, and environmental practices of their business partners, and enable regulators to protect consumers, workers, and the environment. This study finds that inspectors are less stringent later in their workday and after visiting workplaces with fewer problems.
The ACS Quality Improvement Case Study Repository is a centralized platform of quality improvement projects implemented by participants of the ACS Quality Programs. Each of the curated projects in the repository has been formatted to follow the new ACS Quality Framework, allowing readers to easily understand the details of each project from ...
Assessments of Case Study Quality. Arising from the debates in other disciplines, various tools and approaches have been developed to assess the quality of case study research. Table 1 summarizes the characteristics of a selection of these, which give useful ideas on how case study quality can be evaluated.
AHRQ Quality Indicators Case Study: Johns Hopkins Health System Key Findings • The Johns Hopkins Hospital worked diligently to improve its performance for Postoperative Respiratory Failure (PSI 11). The effort started back in 2012 when only 30 percent were able to be removed from a ventilator within the desired timeframe.
1.1 Introduction . In recent years the development policy community has turned to case studies as an analytical and diagnostic tool. Practitioners are using case studies to discern the mechanisms underpinning variations in the quality of service delivery and institutional reform, to identify how specific challenges are addressed during implementation, and to explore the conditions under which ...
Quality Management Systems (QMS) & ISO 9001 - Case Studies. Implementing ISO 9001:2015 can help ensure that customers get consistent, high-quality products and services, which in turn can benefit your organization. The following ISO 9001:2015 case studies offer a look at the difference ISO 9001 can make for organizations in terms of process ...
Maintaining Data Quality from Multiple Sources Case Study. There is a wealth of data within the healthcare industry that can be used to drive innovation, direct care, change the way systems function, and create solutions to improve patient outcomes. But with all this information coming in from multiple unique sources that all have their own ...
The case study also addresses several of the change strategies in Key Driver 4: Create and support high functioning teams to deliver high-quality evidence-based care, including developing a shared sense of accountability, empowering team members through training, and establishing workflows and good communication protocols.
The 7 QC tools, when combined with the systematic approach of the PDCA cycle, can yield impressive results, as demonstrated in our case study. Addressing quality issues requires a methodical, data ...
Single-case studies can provide a viable alternative to large group studies such as randomized clinical trials. Single case studies involve repeated measures, and manipulation of and independent variable. They can be designed to have strong internal validity for assessing causal relationships between interventions and outcomes, and external ...
Fifty four percent of raw case users came from outside the U.S.. The Yale School of Management (SOM) case study directory pages received over 160K page views from 177 countries with approximately a third originating in India followed by the U.S. and the Philippines. Twenty-six of the cases in the list are raw cases.
A case study is one of the most commonly used methodologies of social research. This article attempts to look into the various dimensions of a case study research strategy, the different epistemological strands which determine the particular case study type and approach adopted in the field, discusses the factors which can enhance the effectiveness of a case study research, and the debate ...
Case study examples. Case studies are proven marketing strategies in a wide variety of B2B industries. Here are just a few examples of a case study: Amazon Web Services, Inc. provides companies with cloud computing platforms and APIs on a metered, pay-as-you-go basis. This case study example illustrates the benefits Thomson Reuters experienced ...