15 Tricky SQL Interview Questions for Experienced Users
- sql interview questions
- Advanced SQL
Table of Contents

Interview Preparation as an Experienced SQL User
Question 1: select freelancers and their task info, question 2: what are outer joins and when do you use them, question 3: select freelancer and task info, part 2, question 4: select freelancer info for projects due in 2024, question 5: show all employees and their managers, question 6: show therapists and their first and second languages, question 7: show the number of freelancers with assigned tasks, question 8: show the number of tasks by task type and subtype, question 9: show the number of active tasks by task type and subtype, question 10: what’s wrong with this query, question 11: show all freelancers and the number of their tasks, question 12: show the number of completed tasks by completion date, question 13: show employees with their departments and salaries, question 14: what’s the difference between union and union all, question 15: show selected books with their author and subtitle, more interview resources for experienced sql users.
SQL interview questions for experienced users usually contain some trick(y) questions. Interviewers use them to test your gumption, which is typically a result of extensive experience and a high level of SQL knowledge.
I will show you 15 tricky SQL interview questions (mostly coding) in this article. Mind you, these are not necessarily complex questions. Actually, that’s their main characteristic: they seem very easy and straightforward, but that’s the interviewer trying to deceive you. But as an experienced SQL user, you should be able to recognize the traps and avoid them.
I’ll show you how to do that, but I can’t prepare for the interview instead of you. So, how should you approach interview preparation?
Solid foundations in SQL basic and intermediate topics are prerequisites for considering yourself an experienced SQL user. If you don’t know where you land on the SQL knowledge spectrum, we have something new for you: our SQL Skills Assessment . You can take the test and assess your level of SQL. It’s a free feature; you can take one test every 30 days. At the end of the test, you get an overall score on your SQL knowledge. There are detailed results for six competency areas: Basic SQL Queries, SQL JOINs, Standard SQL Functions, Basic SQL Reports, Intermediate SQL Reports, and Complex SQL Reports.

After the assessment, you can go to our Advanced SQL track for more practice. It consists of three main interactive courses that cover details of window functions, GROUP BY extensions, and recursive queries. The topics are spread throughout 395 coding challenges, so you’ll write plenty of code – which has been shown to be the most efficient way of learning SQL. After the course, you’ll be at home with advanced SQL topics .
The learning track will give you knowledge, no doubt about that. However, employers rely on experienced users to leverage SQL in solving real-life problems. But in life, things are rarely straightforward; actual problems tend not to be SQL textbook examples tailored for learning. So, you should go beyond examples from the course. You need to work on flexibility and creativity, seeing potential pitfalls in advance and avoiding them in your SQL code. That’s what the interviewers are looking for from experienced users. Because of that, preparing for the interview with straightforward SQL questions is not enough. You should also brush up on the tricky questions, as the interviewers like to use them to try and catch you off guard.
Some of the common tricky SQL interview questions for experienced users are presented below.
Write a query that selects all freelancers along with their task info:
- Task type and subtype
Include freelancers that don’t have any tasks assigned.
Dataset: The dataset is of a company that employs freelancers on certain tasks. It consists of three tables. The first table is freelancer . You can find the script here .
| id | first_name | last_name |
|---|---|---|
| 1 | Bob | Franklin |
| 2 | Dionne | Ravanelli |
| 3 | Marek | Lewandowski |
| 4 | Francois | Cousteau |
| 5 | Emma | Biesa |
The second table is a dictionary of different task types named task_category . Here’s the script.
| id | task_type | task_subtype |
|---|---|---|
| 1 | Blog article | SQL |
| 2 | Blog article | Python |
| 3 | Blog article | Career |
| 4 | Social media post | |
| 5 | Social media post | Other social media |
The third table shows the details of the assigned work freelancers are doing for our company. The table is named task , with the script here .
| id | task_category_id | title | freelancer_id | date_assigned | due_date | completed_date |
|---|---|---|---|---|---|---|
| 1 | 2 | Working With Pandas in Python | 5 | 2023-11-30 | 2023-12-15 | 2023-12-15 |
| 2 | 4 | Promote Advanced SQL Learning Track | 4 | 2023-12-18 | 2023-12-20 | 2023-12-20 |
| 3 | 1 | Working With LEFT JOIN in SQL | 1 | 2023-12-08 | 2024-03-01 | NULL |
| 4 | 3 | What Does a Data Analyst Do? | 2 | 2023-12-20 | 2024-02-01 | 2024-02-10 |
| 5 | 4 | Promote Working With Pandas in Python | 4 | 2024-01-15 | 2024-01-18 | 2024-01-18 |
| 6 | 2 | Python Libraries You Should Know | 1 | 2024-01-15 | 2024-02-15 | 2024-02-15 |
| 7 | 1 | Using COUNT in SQL | 2 | 2024-01-20 | 2024-02-15 | 2024-02-15 |
| 8 | 1 | Filtering Data in SQL | 5 | 2024-02-20 | NULL | NULL |
Answer: This question tests your skills in joining three tables and choosing the correct join type.
Here’s the solution:
Explanation: To get all the required info, you need to join all three tables. First, join the tables freelancer and task on the freelancer ID. To add the third table, you again need to write the JOIN keyword. Then, state in the ON clause that you’re joining tables on the task category ID.
The join type you use must be JOIN . It’s because of the possibility that there are some freelancers who don’t have any tasks yet. You need only those who have.
Output: Here’s the query output:
| first_name | last_name | title | due_date | task_type | task_subtype |
|---|---|---|---|---|---|
| Emma | Biesa | Working With Pandas in Python | 2023-12-15 | Blog article | Python |
| Francois | Cousteau | Promote Advanced SQL Learning Track | 2023-12-20 | Social media post | |
| Bob | Franklin | Working With LEFT JOIN in SQL | 2024-03-01 | Blog article | SQL |
| Dionne | Ravanelli | What Does a Data Analyst Do? | 2024-02-01 | Blog article | Career |
| Francois | Cousteau | Promote Working With Pandas in Python | 2024-01-18 | Social media post | |
| Bob | Franklin | Python Libraries You Should Know | 2024-02-15 | Blog article | Python |
| Dionne | Ravanelli | Using COUNT in SQL | 2024-02-15 | Blog article | SQL |
| Emma | Biesa | Filtering Data in SQL | NULL | Blog article | SQL |
Answer: This question wants to see if you really understand how outer joins work and how they’re different from other joins.
OUTER JOIN s are one of the distinct join categories in SQL, along with INNER JOIN s and CROSS JOIN s.
The following joins belong to the OUTER JOIN family:
- LEFT (OUTER) JOIN
- RIGHT (OUTER) JOIN
- FULL (OUTER) JOIN
The main characteristic of all OUTER JOIN s is that they join tables in a way where one table is dominant, so all its data will be shown. The second table is subordinated so that the query will show only the matching rows from that table. If there are non-matching rows, they will appear as NULL .
So, OUTER JOIN s should be used when you want to show non-matching rows as well as matching rows within the tables.
Each of the above outer joins works on that principle, but here’s how they differ:
- LEFT JOIN shows all the data from the first (left) table and only the matching rows from the second (right) table. If there are non-matching rows, they are shown as NULL .
- RIGHT JOIN shows all the data from the second (right) table and only the matching rows from the first (left) table. The non-matching rows are shown as NULL .
- FULL JOIN combines a LEFT JOIN and RIGHT JOIN . It shows all the data from both tables. In other words, it will show all the rows – matching and non-matching rows from the left table. Then, it will add all the rows from the right table that can’t be found in the left table. Where there’s non-matched data, you will see NULL s.
Write a query that returns:
- Freelancers’ first and last names.
- The titles of their assigned tasks.
- Task type and subtype.
- Task due dates.
Include all freelancers, even those that don’t have any tasks.
Dataset: Same as Question 1.
Answer: Yet another SQL interview question for the experienced user. Here, you need to show that you understand the relationships between the tables. You need to use LEFT JOIN to join the three tables . You need to use LEFT JOIN as a first join. But you need to be aware that the relationship between the tables ‘forces’ you to use LEFT JOIN again as a second join.
Explanation: The query is very similar to the one in Question 1. So your first join is LEFT JOIN , as you need to output all the freelancers, not only those with a task assigned. In other words, the relationship is such that a task must have a freelancer assigned, but a freelancer doesn’t need to have a task assigned.
However, when you join the third table, you again need LEFT JOIN . Why is that? It’s because a task has to have a type and subtype. At the same time, each available task type doesn’t need to be among the assigned tasks. If you used INNER JOIN here instead, it would ‘cancel’ the first LEFT JOIN and skew your output.
Output : Here’s how your output should look:
| first_name | last_name | title | due_date | task_type | task_subtype |
|---|---|---|---|---|---|
| Emma | Biesa | Working With Pandas in Python | 2023-12-15 | Blog article | Python |
| Francois | Cousteau | Promote Advanced SQL Learning Track | 2023-12-20 | Social media post | |
| Bob | Franklin | Working With LEFT JOIN in SQL | 2024-03-01 | Blog article | SQL |
| Dionne | Ravanelli | What Does a Data Analyst Do? | 2024-02-01 | Blog article | Career |
| Francois | Cousteau | Promote Working With Pandas in Python | 2024-01-18 | Social media post | |
| Bob | Franklin | Python Libraries You Should Know | 2024-02-15 | Blog article | Python |
| Dionne | Ravanelli | Using COUNT in SQL | 2024-02-15 | Blog article | SQL |
| Emma | Biesa | Filtering Data in SQL | NULL | Blog article | SQL |
| Marek | Lewandowski | NULL | NULL | NULL | NULL |
Using INNER JOIN as the second join would remove this last row, which shows a freelancer without an assigned task. If there’s no task, there’s also no task type. And INNER JOIN doesn’t show non-matching rows. That’s why LEFT JOIN is needed here.
Write a query that selects:
- All freelancers
- Their task titles
- Tasks’ due dates
Include only projects with a due date in 2024.
Dataset: Same as in the previous question.
Solution: The question wants to lure you into writing a query that uses the WHERE clause to filter the data, as shown below:
But that’s not the correct answer. To get the required output, the filtering condition in WHERE has to be moved to a joining condition , like this:
Explanation: In the first query, using WHERE would return only the data for the tasks with the due date in 2024. That would exclude all the freelancers that don’t have an assigned task, but also the tasks that don’t have – for various reasons – a due date.
So, instead, we move the filtering condition to the ON clause. The first condition joins the tables on the freelancer ID. The second condition is added using the keyword AND . This way, you include all the freelancers but filter out the projects that were due in 2023.
Output: Here’s the correct output:
| first_name | last_name | title | due_date |
|---|---|---|---|
| Bob | Franklin | Working With LEFT JOIN in SQL | 2024-03-01 |
| Dionne | Ravanelli | What Does a Data Analyst Do? | 2024-02-01 |
| Francois | Cousteau | Promote Working With Pandas in Python | 2024-01-18 |
| Bob | Franklin | Python Libraries You Should Know | 2024-02-15 |
| Dionne | Ravanelli | Using COUNT in SQL | 2024-02-15 |
| Emma | Biesa | NULL | NULL |
| Marek | Lewandowski | NULL | NULL |
Despite Emma Biesa having a project titled ‘Filtering Data in SQL’, its due date is NULL , so the value in the column title is also NULL . In other words, Emma Biesa’s project doesn’t match the joining condition.
On the other hand, the output looks the same for Marek Lewandowski. This time, it’s because Marek doesn’t have a project assigned at all.
Dataset: The question provides you with the table employees . Here’s the script.
The table is a list of employees.
| id | first_name | last_name | manager_id |
|---|---|---|---|
| 1 | John | Borisov | 2 |
| 2 | Linda | Johnson | 8 |
| 3 | Frank | Ranieri | NULL |
| 4 | Nina | Bowie | 1 |
| 5 | Tamara | Felipe | NULL |
| 6 | Simon | Fyodorov | 8 |
| 7 | Lana | Hopkins | NULL |
| 8 | Tom | Bonfa | 1 |
| 9 | Maria | Fox | 1 |
| 10 | Victor | Ivanchich | 2 |
Solution: Since there’s only one table, you need to show you know that a table can be joined with itself . In other words, solve the question by applying a self-join .
This is done in the following way:
Explanation: Self-join is simply a table that’s joined with itself. Basically, by giving one table different aliases, you’re making SQL think you’ve joined two different tables.
Our ‘first’ table has the alias e . We will use it to show employees' names.
The ‘second’ joined table’s alias is m ; it will serve to show managers’ names.
In this case, you need to join them using LEFT JOIN because the question requires you to list all the employees. This also includes employees who have no managers. If you used INNER JOIN , you would get only employees that have a manager.
The table is self-joined on the condition that the manager’s ID is equal to the employee’s ID. That’s how you get the managers’ names of each employee.
Output: Here’s the list of employees and their superiors:
| employee_first_name | employee_last_name | manager_first_name | manager_last_name |
|---|---|---|---|
| John | Borisov | Linda | Johnson |
| Linda | Johnson | Tom | Bonfa |
| Frank | Ranieri | NULL | NULL |
| Nina | Bowie | John | Borisov |
| Tamara | Felipe | NULL | NULL |
| Simon | Fyodorov | Tom | Bonfa |
| Lana | Hopkins | NULL | NULL |
| Tom | Bonfa | John | Borisov |
| Maria | Fox | John | Borisov |
| Victor | Ivanchich | Linda | Johnson |
NULL s as manager’s names mean the respective employee doesn’t have a superior.
Write a query that returns all therapists with their first and second languages.
Dataset: This dataset is from a collective psychotherapy practice intended for ex-pats. Several therapists provide therapy, and they each do that in two languages.
The list of the languages is in the table language . Here’s the script.
| id | language_name |
|---|---|
| 1 | English |
| 2 | Dutch |
| 3 | Russian |
| 4 | Polish |
| 5 | Croatian |
The list of therapists can be found in the table therapist . Here’s the script.
| id | first_name | last_name | first_language_id | second_language_id |
|---|---|---|---|---|
| 1 | Maya | Hoekstra | 2 | 1 |
| 2 | Lana | Mayakovski | 3 | 1 |
| 3 | Marija | Abramović | 5 | 2 |
| 4 | Jan | Nowak | 4 | 1 |
| 5 | Francis | Gordon | 1 | 2 |
Solution: One of the many SQL interview questions for experienced users, this task requires you to showcase skills in joining three tables. However, here one table is joined twice. You need to recognize this, because the table therapist references the table language in two columns: first_language_id and second_language_id .
The solution should look like this:
Explanation: First, we join the table therapist with the table language , the latter being given the alias fl (as in ‘first language’). We’ll use it to show the therapist’s first language, i.e. their native language. That’s why the join condition looks for where the first language ID is the same as the language ID. This will result in the name of the first language being shown.
In the next step, we again join the table language . This time, it has the alias sl for ‘second language’. The join takes the second language ID and looks for it in language . That’s how we get the name of the second language.
To show the first and second language, we select the language_name column – once from the fl ‘table’ and the second time from the sl ‘table’ – and give the columns appropriate names.
Output: Here’s the output:
| first_name | last_name | first_language_name | second_language_name |
|---|---|---|---|
| Jan | Nowak | Polish | English |
| Lana | Mayakovski | Russian | English |
| Maya | Hoekstra | Dutch | English |
| Francis | Gordon | English | Dutch |
| Marija | Abramović | Croatian | Dutch |
Dataset: The freelancer dataset used in Questions 1, 3, and 4.
Solution: This tricky interview question leads you to use the COUNT() aggregate function . It seems very easy, with a simple query that uses only one table. But, the question wants you to be hasty and write the following query:
However, you need to show you’re smarter than that and write a query that uses COUNT(DISTINCT freelancer_id) instead of COUNT(freelancer_id) .
Explanation: Why is the first query wrong? Well, COUNT(freelancer_id) will count every instance of a freelancer's ID. This means it will also count duplicates as another freelancer. (Remember, each freelancer can have multiple tasks.)
To avoid this, just add DISTINCT in this expression. This will eliminate duplicates – i.e. each freelancer will be counted only once.
Output: The first query will return this:
| number_of_working_freelancers |
|---|
| 8 |
You know that’s wrong because you know your data. The table freelancer has only five freelancers listed, so it can’t be true that more freelancers are working than there are freelancers.
So, the correct output is the one below. There are four freelancers because we know one is unassigned, i.e. he’s not working.
| number_of_working_freelancers |
|---|
| 4 |
Dataset: Same as above.
Solution: Here, you must recognize that you need to use an aggregate function and group the output by two columns .
Explanation: To get the output, you need to join the tables task_category and task on the task category ID.
Then, select the task type and subtype, and use COUNT(*) , which will simply count the number of rows, which equals the number of tasks. Each row is one task.
After that, use GROUP BY to group data by task type. However, the question asks you to aggregate data on the task subtype level, too, so you need to add it in GROUP BY . All the columns in GROUP BY must be separated by a comma.
Output: The ‘Social media post’ task type appears only once, as there are no other subtypes in the active tasks.
On the other hand, the ‘Blog article’ task type appears three times, each with a different task subtype. The number_of_tasks column represents the number of tasks per subtype.
| task_type | task_subtype | number_of_tasks |
|---|---|---|
| Social media post | 2 | |
| Blog article | SQL | 3 |
| Blog article | Python | 2 |
| Blog article | Career | 1 |
Write a query that shows the number of active tasks by task type and subtype.
Include only those categories with more than two tasks.
Solution: This common SQL interview question will test if you recognize that you need to use HAVING instead of WHERE to filter the output. You might want to solve the question like this:
That’s wrong, so you need to replace WHERE with HAVING :
Explanation: This query is basically the same as the one from the previous question. The additional requirement is to show only task types and subtypes with more than two active tasks.
The first query won’t return anything except an error saying aggregate functions can’t be used in WHERE . That’s, of course, because WHERE filters data before aggregation.
So you first need to aggregate data using COUNT(*) to find the number of active tasks by type and subtype. Only after that can you look for those categories with more than two tasks.
In other words, you must use HAVING , as it filters data after aggregation. You simply use the aggregation from the column number_of_tasks and state a condition that the count must be greater than two.
| task_type | task_subtype | number_of_tasks |
|---|---|---|
| Blog article | SQL | 3 |
Solution: The question gives you a query:
Your answer should be that this query won’t work because the column task_subtype is not listed in the GROUP BY clause. The corrected query should look like this:
Explanation: Why must the column task_subtype appear in GROUP BY ? The rule in SQL is that all the columns (except those containing aggregate functions) must appear in GROUP BY . This is something you should know and be able to recognize in the query immediately.
Output: The corrected output will now work and return the following result. It shows freelancers and the number of their tasks by type and subtype.
| first_name | last_name | task_type | task_subtype | task_count |
|---|---|---|---|---|
| Emma | Biesa | Blog article | Python | 1 |
| Emma | Biesa | Blog article | SQL | 1 |
| Francois | Cousteau | Social media post | 2 | |
| Bob | Franklin | Blog article | Python | 1 |
| Bob | Franklin | Blog article | SQL | 1 |
| Dionne | Ravanelli | Blog article | Career | 1 |
| Dionne | Ravanelli | Blog article | SQL | 1 |
Solution: In this question, you could easily be drawn to writing a query that uses COUNT(*) to find the number of tasks, like so:
Yes, you wisely used LEFT JOIN to return freelancers without a task. However, you should use COUNT(task_category_id) instead of COUNT(*) …
… right?
Explanation: Don’t fall for that trick! I’m sure you’re aware that COUNT(*) shouldn’t be used in combination with LEFT JOIN .
You use LEFT JOIN to include freelancers without the task. Those freelancers will have no matching values in the right table, so they will be shown as NULL . Unfortunately, COUNT(*) doesn’t ignore NULL s, so they will be counted as regular values.
Instead, you need to use COUNT(task_category_id) . This way, you will count only non- NULL values.
Output: Take a look at the output of the first (incorrect) query:
| first_name | last_name | task_count |
|---|---|---|
| Dionne | Ravanelli | 2 |
| Marek | Lewandowski | 1 |
| Emma | Biesa | 2 |
| Bob | Franklin | 2 |
| Francois | Cousteau | 2 |
Marek Lewandowski has one task. But we know this can’t be right, as he has no tasks assigned. The output shows the count of one because COUNT(*) counted the NULL value (non-matching row).
The output of the solution query rightly shows that Marek’s task count is zero:
| first_name | last_name | task_count |
|---|---|---|
| Dionne | Ravanelli | 2 |
| Marek | Lewandowski | 0 |
| Emma | Biesa | 2 |
| Bob | Franklin | 2 |
| Francois | Cousteau | 2 |
Write a query that shows the number of completed tasks by completion date. Include NULL s as a separate date category.
Solution: This question tries to trick you into thinking that you somehow need to explicitly state a condition where all the tasks without the completion date will be counted together under the NULL category as a date.
But the solution is simpler than you think:
Explanation: As you can see, the above query doesn’t refer to NULL s in any way. It simply selects the completion date and uses COUNT() on the task ID column to count the number of completed tasks.
Of course, the output needs to be grouped by the completion date. It is also sorted from the oldest to the newest date, which is not necessary but looks nicer.
By writing such a query, you show an understanding that the NULL values are not counted separately. All the NULL values will be shown as one category – NULL .
Output: As you can see, all the tasks without the completion date are shown in one row:
| completed_date | completed_task_count |
|---|---|
| 2023-12-15 | 1 |
| 2023-12-20 | 1 |
| 2024-01-18 | 1 |
| 2024-02-10 | 1 |
| 2024-02-15 | 2 |
| NULL | 2 |
Write a query that shows employees, their departments, and their salaries.
Include only employees with a salary lower than their department average.
Dataset: This SQL interview question uses the table salaries . You can find the script here .
| id | first_name | last_name | department | salary |
|---|---|---|---|---|
| 1 | Benny | Gilhespy | Sales | 5,293.47 |
| 2 | Benetta | Featherstonhaugh | Engineering | 2,214.55 |
| 3 | Karla | Stiell | Sales | 2,070.45 |
| 4 | Sissie | Seabon | Accounting | 5,077.42 |
| 5 | Genna | Beche | Accounting | 7,451.65 |
| 6 | Kirsten | Fernandez | Engineering | 7,533.13 |
| 7 | Pen | Fredy | Sales | 7,867.54 |
| 8 | Tish | Calderbank | Sales | 4,103.19 |
| 9 | Gallard | Philipet | Accounting | 7,220.06 |
| 10 | Walsh | Kleinholz | Accounting | 4,000.18 |
| 11 | Carce | Wilkenson | Accounting | 3,991.00 |
| 12 | Tami | Langrish | Sales | 5,588.34 |
| 13 | Shayne | Dearn | Engineering | 2,785.92 |
| 14 | Merla | Ingilson | Engineering | 2,980.36 |
| 15 | Keely | Patifield | Sales | 2,877.92 |
Solution: The tricky part here is to recognize that the query can be very short if you know how to use correlated subqueries .
It should be done like this:
Explanation: So, the query first lists all the required columns from the table salaries . I’ve given the table an alias, s1 .
Then, I use the WHERE clause to compare each employee’s salary with the departmental average. The departmental average is calculated in the special type of a subquery – a correlated subquery.
What’s so special about it? Well, this subquery is correlated because it references the data from the main query. This happens in the WHERE clause of a subquery: the department from the s1 table (appearing in the main query) has to be the same as the department in the s2 table, which appears in the subquery. This condition will enable the AVG() aggregate function to calculate the departmental average of the department where this particular employee works.
Output: The table below shows only employees whose salaries are below the average of their respective departments' salaries.:
| id | first_name | last_name | department | salary |
|---|---|---|---|---|
| 2 | Benetta | Featherstonhaugh | Engineering | 2,214.55 |
| 3 | Karla | Stiell | Sales | 2,070.45 |
| 4 | Sissie | Seabon | Accounting | 5,077.42 |
| 8 | Tish | Calderbank | Sales | 4,103.19 |
| 10 | Walsh | Kleinholz | Accounting | 4,000.18 |
| 11 | Carce | Wilkenson | Accounting | 3,991.00 |
| 13 | Shayne | Dearn | Engineering | 2,785.92 |
| 14 | Merla | Ingilson | Engineering | 2,980.36 |
| 15 | Keely | Patifield | Sales | 2,877.92 |
Answer: To answer this, you obviously must know the difference between the two most common set operators in SQL.
Both operators vertically merge the outputs of two or more queries. UNION does that by excluding duplicate rows. In other words, if the same rows appear in both queries, they will be shown only once. You can think about it as DISTINCT in the set operators' world.
On the other hand, UNION ALL shows all the rows from both queries, including duplicates. You can read more about the difference between UNION and UNION ALL in our guide.
Write a query that selects a book’s author, title, and subtitle – but only for those books where the subtitle includes the word ‘woman’. Include books without subtitles.
Dataset: The table used in this example is books , and the script is here .
Solution: The straightforward part here is that you need to look for the word ‘woman’ in the subtitle. However, how do you also include books without subtitles – i.e. with NULL values?
The answer is you need to explicitly handle NULL s to include them in the output, like this:
Explanation: Your answer includes two conditions in WHERE . The first condition looks for the word ‘woman’ in the subtitle. You do that either using LIKE (if your database is case-insensitive) or ILIKE (if your database is case-sensitive, like PostgreSQL). To look for the word anywhere in a string, you need to surround it with ‘ % ’. Since you’re looking for a string, all that must be written in single quotes.
Now, you can add another filtering condition where you state that the subtitle must be NULL using the IS NULL operator. The two conditions are joined using the OR keyword, as they can’t be satisfied at the same time: if there’s no subtitle, it can’t contain the word ‘woman’.
Output: Here’s the output showing all the data that satisfies either condition:
| author | title | subtitle |
|---|---|---|
| Miljenko Jergović | Sarajevo Marlboro | NULL |
| Tilar J. Mazzeo | Irena's Children | The Extraordinary Story of the Woman Who Saved 2,500 Children from the Warsaw Ghetto |
| Olga Tokarczuk | Primeval and Other Times | NULL |
| Thomas Hardy | Tess of the d' Urbevilles | A Pure Woman Faithfully Presented |
| Sylvia Plath | Ariel | NULL |
| Toni Morrison | Jazz | NULL |
| Haben Girma | Haben | The Deafblind Woman Who Conquered Harvard Law |
These 15 exercises cover some of the most common ‘trick’ SQL interview questions for experienced users. Having all these solutions should make you aware of the traps set up for you and how to avoid them.
But you shouldn’t stop now! There’s no such thing as too much preparation for a job interview. So, I recommend looking at an additional 25 advanced SQL query examples or another 27 advanced SQL interview questions .
You should also practice what you’ve learned here. Here are some ideas about practicing advanced SQL with our courses and some advanced SQL practice exercises to get you started.
Use this in conjunction with our Advanced SQL track and Advanced SQL Practice track , and you’ll be well-prepared for your next job interview!
You may also like

How Do You Write a SELECT Statement in SQL?

What Is a Foreign Key in SQL?

Enumerate and Explain All the Basic Elements of an SQL Query
SQL Interview Questions: 3 Tech Screening Exercises For Data Analysts (in 2022)

- Tomi Mester
- May 31, 2022
I’ve been part of many job interviews – on both sides of the table. The most fun, but also the most feared, part of the process is the technical screening. In this article, I’ll show you three SQL test exercises that, in my experience, are quite typical in data analyst job interviews — as of 2022. (And hey, these are “sample” SQL interview questions but they are heavily based on reality!)
Before the tasks – What can you expect in an SQL technical screening?
There are two common ways an SQL tech screening can be done.

The simpler but less common way is that you get a computer, a data set, and a task. While you are solving the task, the interviewers are listening and asking questions. A little trial-and-error is totally fine, as long as you can come up with the correct solution in a reasonable amount of time.
The other, more difficult (and by the way much more common) way is the whiteboard interview. In this case, you don’t get a computer. You have to solve the task and sketch up the code on a whiteboard. This means that you won’t get feedback (at least not from a computer) on whether you made a logical or a syntax error in your code. Of course, you can still solve the tasks by thinking iteratively. You can crack the different SQL problems one by one… But you have to be very confident with your SQL skills.
Additionally, usually, you have to solve the tasks on the fly. Maybe you will get 3-5 minutes of thinking time but that’s the maximum you can expect.
I know, this sounds stressful . And it is. But don’t worry, there is some good news, as well. Because companies know that this is a high-stress interview type, compared to the real-life challenges, you will get relatively simpler tasks. (See the difficulty level below!)
SQL tech assessments in 2022
There are several types of SQL tech assessments. The one that I described above (and for that, I’ll provide a few exercises below) is the most common one. When people say “SQL tech screening,” they usually refer to that. To be more precise, I like to call it “in-person SQL screening.”
But, in fact, there are four different types of SQL assessments:
- In-person SQL screening. The one that we discussed so far (and will discuss in the rest of the article).
- SQL quiz questions. For example: “What is a primary key?” Or “List the different types of JOIN s!” That’s a stupid type of SQL tech assessment — as it focuses on theory and not on practice. Still, some companies… you know.
- Take-home SQL assignment. You get a more complex task and you’ll have to write multiple SQL queries to solve it. The upside is that can work from home, as you get the task and the dataset by email. You get these on a workday you choose, and you’ll have ~12 hours to solve it and send the solution back (SQL queries and a short presentation). I like this assessment type, as it creates a less stressful environment for the applicant.
- Automated SQL screening. With the rise of remote work, automated SQL screening becomes more common. It’s usually a one-hour process with a few simpler SQL tasks – that you can solve from home via a browser. This interview type is not very personal, but I like it as it’s less stressful and more flexible (e.g. you can skip tasks and go back later).
When someone asks you to do an “SQL tech screening,” either of the above can come up. Still, the most common is the in-person SQL screening. So let’s see a few examples of that!
Test yourself!
Here are three SQL interview questions that are really close to what I actually got or gave on data analyst/scientist job interviews!
Try to solve all of them as if they were whiteboard interviews!
In the second half of the article, I’ll show you the solutions, too!
How to Become a Data Scientist (free 50-minute video course by Tomi Mester)
Just subscribe to the Data36 Newsletter here (it’s free)!
I accept Data36's Privacy Policy . (No spam. Only useful data science related content. When you subscribe, I’ll keep you updated with a couple emails per week. You'll get articles, courses, cheatsheets, tutorials and many cool stuff.)
You have successfully joined our subscriber list.
SQL Interview Question #1
Let’s say you have two SQL tables: authors and books . The authors dataset has 1M+ rows. Here’s a small sample, the first six rows:
| author_1 | book_1 |
| author_1 | book_2 |
| author_2 | book_3 |
| author_2 | book_4 |
| author_2 | book_5 |
| author_3 | book_6 |
| … | … |
The books dataset also has 1M+ rows and here’s the first six:
| book_1 | 1000 |
| book_2 | 1500 |
| book_3 | 34000 |
| book_4 | 29000 |
| book_5 | 40000 |
| book_6 | 4400 |
| … | … |
Create an SQL query that shows the TOP 3 authors who sold the most books in total!
(Note: Back in the days, I got almost this exact SQL interview question for a data scientist position at a very well-known Swedish IT company.)
SQL Interview Question #2
You work for a startup that makes an online presentation software. You have an event log that records every time a user inserted an image into a presentation. (One user can insert multiple images.) The event_log SQL table looks like this:
| 7494212 | 1535308430 |
| 7494212 | 1535308433 |
| 1475185 | 1535308444 |
| 6946725 | 1535308475 |
| 6946725 | 1535308476 |
| 6946725 | 1535308477 |
| … | … |
…and it has over one billion rows.
Note: If the event_date_time column’s format doesn’t look familiar, google “epoch timestamp”!
Write an SQL query to find out how many users inserted more than 1000 but less than 2000 images in their presentations!
(Note: I personally created and used this interview question to test data analysts when I was freelancing and my clients needed help in their hiring process.)
SQL Interview Question #3
You have two SQL tables!
The first table is called employees and it contains the employee names, the unique employee ids, and the department names of a company. Sample:
| Sales | 123 | John Doe |
| Sales | 211 | Jane Smith |
| HR | 556 | Billy Bob |
| Sales | 711 | Robert Hayek |
| Marketing | 235 | Edward Jorgson |
| Marketing | 236 | Christine Packard |
| … | … | … |
The second SQL table is called salaries . It holds the same employee names and the same employee ids – and the salaries for each employee. Sample:
| 500 | 123 | John Doe |
| 600 | 211 | Jane Smith |
| 1000 | 556 | Billy Bob |
| 400 | 711 | Robert Hayek |
| 1200 | 235 | Edward Jorgson |
| 200 | 236 | Christine Packard |
| … | … | … |
The company has 546 employees, so both tables have 546 rows.
Print every department where the average salary per employee is lower than $500!
(Note: I created this test question based on a real SQL interview question that I heard from a friend, who applied at one of the biggest social media companies (name starts with ‘F.’ ;))
Solution of SQL Interview Question #1
The solution code is:
And here is a short explanation:
1. First you have to initiate the JOIN . I joined the two tables by using:
2. After that, I used a SUM() function with a GROUP BY clause. This means that in the SELECT statement I had to replace the * with the author_name and sold_copies columns. (It’s not mandatory to indicate from which table you are selecting the columns, but it’s worth it. That’s why I used authors .author_name and books .sold_copies .)
3. Eventually, I ORDER ed the results in DESC ending order. (Just for my convenience, I also renamed the sum column to sold_sum using the AS sold_sum method in the SELECT statement.)
Solution of SQL Interview Question #2
The solution SQL query is:
The trick in this task is that you had to use the COUNT() function two times: first, you had to count the number of images per user, then the number of users (who fulfill the given condition). The easiest way to do that is to use a subquery.
- Write the inner query first! Run a simple COUNT() function with a GROUP BY clause on the event_log table.
- Make sure that you create an alias for the subquery ( AS image_per_user ). It’s a syntax requirement in SQL.
- Eventually, in an outer query, apply a WHERE filter and a COUNT() function on the result of the subquery.
Solution of SQL Interview Question #3
Note: You can solve this task using a subquery, too – but in an interview situation the interviewer will like the above solution better.
Brief explanation:
1. First JOIN the two tables:
Watch out! Use the employee_id column – not the employee_name . (You can always have two John Does at a company, but the employee id is unique!)
2. Then use the AVG() function with a GROUP BY clause — and replace the * with the appropriate columns. (Just like in the first task.)
3. And the last step is to use a HAVING clause to filter by the result of the AVG() function. (Remember: WHERE is not good here because it would be initiated before the AVG() function.) Watch out: in the HAVING line, you can’t refer to the alias – you have to use the whole function itself again!
Prepare for SQL tech screenings by practicing!
If you solved all these questions properly, you are probably ready for a junior or even a mid-level Data Analyst SQL technical screening.
If not, let me recommend my new online course: SQL for Aspiring Data Scientists (7-day online course) – where you can level up (or brush up) your SQL skills in only 7 days. When you finish the course, just come back to this article and I guarantee that you will be able to solve these questions!
And if you are just about to start with SQL, start with my SQL For Data Analysis series on the blog!
And ultimately, if you feel that you are ready for a junior data scientist position but you want to try out how it works before you apply for a job, take my 6-week data science course:
The Junior Data Scientist's First Month
A 100% practical online course. A 6-week simulation of being a junior data scientist at a true-to-life startup.
“Solving real problems, getting real experience – just like in a real data science job.”
The hard part of these SQL interview questions is that they are abstract. The tasks say to “imagine the data sets” and show only a few lines of them. When you get an exercise like that, it helps a lot if you have seen similar datasets and solved similar problems before. I hope solving the tasks in this article will boost your confidence!
If you have questions or alternative solutions, don’t hesitate to send them in via email and I’ll review them for you!
- If you want to learn more about how to become a data scientist, take my 50-minute video course: How to Become a Data Scientist. (It’s free!)
- Also check out my 6-week online course: The Junior Data Scientist’s First Month video course.
Cheers, Tomi Mester
privacy policy
Data36.com by Tomi Mester | © all rights reserved This website is operated by Adattenger Kft.
- SQL Cheat Sheet
- SQL Interview Questions
- MySQL Interview Questions
- PL/SQL Interview Questions
- Learn SQL and Database
- 30 OOPs Interview Questions and Answers (2024)
- C++ Interview Questions and Answers (2024)
- Top 100 C++ Coding Interview Questions and Answers (2024)
- Top 50+ Python Interview Questions and Answers (Latest 2024)
- Java Interview Questions and Answers
- Java Collections Interview Questions and Answers
- Java Multithreading Interview Questions and Answers
- Top 100 Data Structure and Algorithms DSA Interview Questions Topic-wise
- Top 50 Array Coding Problems for Interviews
- Most Asked Problems in Data Structures and Algorithms | Beginner DSA Sheet
- Top 10 Algorithms in Interview Questions
- Machine Learning Interview Question & Answers
- Top 50 Problems on Linked List Data Structure asked in SDE Interviews
- Top 50 Problems on Heap Data Structure asked in SDE Interviews
- Data Analyst Interview Questions and Answers
SQL Query Interview Questions
- Top Linux Interview Questions With Answer
- Top 50 Django Interview Questions and Answers
- Top 50 Plus Networking Interview Questions and Answers for 2024
- Software Testing Interview Questions
SQL or Structured Query Language is a standard language for relational databases. SQL queries are powerful tools used to, manipulate, and manage data stored in these databases like MySQL , Oracle , PostgreSQL , etc. Whether you’re fetching specific data points, performing complex analyses, or modifying database structures, SQL queries provide a standardized language for executing these tasks efficiently.
Here, we will cover 45+ MySQL interview questions with answers that are commonly asked during interviews for Data Analyst and Data Engineer positions at MAANG and other high-paying companies. Whether you are a fresher or an experienced professional with 5 , 8 , or 10 years of experience, this article gives you all the confidence you need to ace your next interview.
SQL Query Interview Questions and Answers
We have created three sample tables: Student Table, Program Table, and Scholarship Table. We will be using these tables to perform various query operations.
Student Table
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
| 202 | Umesh | Sharma | 8.44 | 2021-09-01 08:30:00 | Mathematics |
| 203 | Rakesh | Kumar | 5.60 | 2021-09-01 10:00:00 | Biology |
| 204 | Radha | Sharma | 9.20 | 2021-09-01 12:45:00 | Chemistry |
| 205 | Kush | Kumar | 7.85 | 2021-09-01 08:30:00 | Physics |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
| 208 | Navleen | Kaur | 7.00 | 2021-09-01 06:30:00 | Mathematics |
Program Table
| STUDENT_REF_ID | PROGRAM_NAME | PROGRAM_START_DATE |
|---|---|---|
| 201 | Computer Science | 2021-09-01 00:00:00 |
| 202 | Mathematics | 2021-09-01 00:00:00 |
| 208 | Mathematics | 2021-09-01 00:00:00 |
| 205 | Physics | 2021-09-01 00:00:00 |
| 204 | Chemistry | 2021-09-01 00:00:00 |
| 207 | Psychology | 2021-09-01 00:00:00 |
| 206 | History | 2021-09-01 00:00:00 |
| 203 | Biology | 2021-09-01 00:00:00 |
Scholarship Table
| STUDENT_REF_ID | SCHOLARSHIP_AMOUNT | SCHOLARSHIP_DATE |
|---|---|---|
| 201 | 5000 | 2021-10-15 00:00:00 |
| 202 | 4500 | 2022-08-18 00:00:00 |
| 203 | 3000 | 2022-01-25 00:00:00 |
| 201 | 4000 | 2021-10-15 00:00:00 |
Let us start by taking a look at some of the most asked SQL Query interview questions :
1. Write a SQL query to fetch “FIRST_NAME” from the Student table in upper case and use ALIAS name as STUDENT_NAME.
2. write a sql query to fetch unique values of major subjects from student table., 3. write a sql query to print the first 3 characters of first_name from student table., 4. write a sql query to find the position of alphabet (‘a’) int the first name column ‘shivansh’ from student table., 5. write a sql query that fetches the unique values of major subjects from student table and print its length..
| MAJOR | LENGTH(MAJOR) |
|---|---|
| Computer Science | 16 |
| Mathematics | 11 |
| Biology | 7 |
| Chemistry | 9 |
| Physics | 7 |
| History | 7 |
| English | 7 |
6. Write a SQL query to print FIRST_NAME from the Student table after replacing ‘a’ with ‘A’.
7. write a sql query to print the first_name and last_name from student table into single column complete_name., 8. write a sql query to print all student details from student table order by first_name ascending and major subject descending ..
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 205 | Kush | Kumar | 7.85 | 2021-09-01 08:30:00 | Physics |
| 208 | Navleen | Kaur | 7 | 2021-09-01 06:30:00 | Mathematics |
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
| 203 | Rakesh | Kumar | 5.6 | 2021-09-01 10:00:00 | Biology |
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
| 202 | Umesh | Sharma | 8.44 | 2021-09-01 08:30:00 | Mathematics |
9. Write a SQL query to print details of the Students with the FIRST_NAME as ‘Prem’ and ‘Shivansh’ from Student table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
10. Write a SQL query to print details of the Students excluding FIRST_NAME as ‘Prem’ and ‘Shivansh’ from Student table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 202 | Umesh | Sharma | 8.44 | 2021-09-01 08:30:00 | Mathematics |
| 203 | Rakesh | Kumar | 5.6 | 2021-09-01 10:00:00 | Biology |
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
| 205 | Kush | Kumar | 7.85 | 2021-09-01 08:30:00 | Physics |
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
| 208 | Navleen | Kaur | 7 | 2021-09-01 06:30:00 | Mathematics |
11. Write a SQL query to print details of the Students whose FIRST_NAME ends with ‘a’.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
12. Write an SQL query to print details of the Students whose FIRST_NAME ends with ‘a’ and contains six alphabets.
13. write an sql query to print details of the students whose gpa lies between 9.00 and 9.99..
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
14. Write an SQL query to fetch the count of Students having Major Subject ‘Computer Science’.
| MAJOR | TOTAL_COUNT |
|---|---|
| Computer Science | 1 |
15. Write an SQL query to fetch Students full names with GPA >= 8.5 and <= 9.5.
16. write an sql query to fetch the no. of students for each major subject in the descending order..
| MAJOR | COUNT(MAJOR) |
|---|---|
| Biology | 1 |
| Chemistry | 1 |
| Computer Science | 1 |
| English | 1 |
| History | 1 |
| Physics | 1 |
| Mathematics | 2 |
17. Display the details of students who have received scholarships, including their names, scholarship amounts, and scholarship dates.
| FIRST_NAME | LAST_NAME | SCHOLARSHIP_AMOUNT | SCHOLARSHIP_DATE |
|---|---|---|---|
| Shivansh | Mahajan | 5000 | 2021-10-15 00:00:00 |
| Umesh | Sharma | 4500 | 2022-08-18 00:00:00 |
| Rakesh | Kumar | 3000 | 2022-01-25 00:00:00 |
| Shivansh | Mahajan | 4000 | 2021-10-15 00:00:00 |
18. Write an SQL query to show only odd rows from Student table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
| 203 | Rakesh | Kumar | 5.6 | 2021-09-01 10:00:00 | Biology |
| 205 | Kush | Kumar | 7.85 | 2021-09-01 08:30:00 | Physics |
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
19. Write an SQL query to show only even rows from Student table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 202 | Umesh | Sharma | 8.44 | 2021-09-01 08:30:00 | Mathematics |
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 208 | Navleen | Kaur | 7 | 2021-09-01 06:30:00 | Mathematics |
20. List all students and their scholarship amounts if they have received any. If a student has not received a scholarship, display NULL for the scholarship details.
21. write an sql query to show the top n (say 5) records of student table order by descending gpa..
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
| 202 | Umesh | Sharma | 8.44 | 2021-09-01 08:30:00 | Mathematics |
22. Write an SQL query to determine the nth (say n=5) highest GPA from a table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 205 | Kush | Kumar | 7.85 | 2021-09-01 08:30:00 | Physics |

23. Write an SQL query to determine the 5th highest GPA without using LIMIT keyword.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
24. Write an SQL query to fetch the list of Students with the same GPA.
25. write an sql query to show the second highest gpa from a student table using sub-query., 26. write an sql query to show one row twice in results from a table., 27. write an sql query to list student_id who does not get scholarship., 28. write an sql query to fetch the first 50% records from a table., 29. write an sql query to fetch the major subject that have less than 4 people in it..
| MAJOR | MAJOR_COUNT |
|---|---|
| Biology | 1 |
| Chemistry | 1 |
| Computer Science | 1 |
| English | 1 |
| History | 1 |
| Mathematics | 2 |
| Physics | 1 |
30. Write an SQL query to show all MAJOR subject along with the number of people in there.
| MAJOR | ALL_MAJOR |
|---|---|
| Biology | 1 |
| Chemistry | 1 |
| Computer Science | 1 |
| English | 1 |
| History | 1 |
| Mathematics | 2 |
| Physics | 1 |
31. Write an SQL query to show the last record from a table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 208 | Navleen | Kaur | 7 | 2021-09-01 06:30:00 | Mathematics |
32. Write an SQL query to fetch the first row of a table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 201 | Shivansh | Mahajan | 8.79 | 2021-09-01 09:30:00 | Computer Science |
33. Write an SQL query to fetch the last five records from a table.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
| 205 | Kush | Kumar | 7.85 | 2021-09-01 08:30:00 | Physics |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
| 208 | Navleen | Kaur | 7 | 2021-09-01 06:30:00 | Mathematics |
34. Write an SQL query to fetch three max GPA from a table using co-related subquery.
35. write an sql query to fetch three min gpa from a table using co-related subquery., 36. write an sql query to fetch nth max gpa from a table., 37. write an sql query to fetch major subjects along with the max gpa in each of these major subjects..
| MAJOR | MAXGPA |
|---|---|
| Biology | 5.6 |
| Chemistry | 9.2 |
| Computer Science | 8.79 |
| English | 9.78 |
| History | 9.56 |
| Mathematics | 8.44 |
| Physics | 7.85 |
38. Write an SQL query to fetch the names of Students who has highest GPA.
| FIRST_NAME | GPA |
|---|---|
| Pankaj | 9.78 |
39. Write an SQL query to show the current date and time.
40. write a query to create a new table which consists of data and structure copied from the other table (say student) or clone the table named student., 41. write an sql query to update the gpa of all the students in ‘computer science’ major subject to 7.5., 42. write an sql query to find the average gpa for each major..
| MAJOR | AVERAGE_GPA |
|---|---|
| Biology | 5.6 |
| Chemistry | 9.2 |
| Computer Science | 4 |
| English | 9.78 |
| History | 9.56 |
| Mathematics | 7.72 |
| Physics | 7.85 |
43. Write an SQL query to show the top 3 students with the highest GPA.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 207 | Pankaj | Vats | 9.78 | 2021-09-01 02:30:00 | English |
| 206 | Prem | Chopra | 9.56 | 2021-09-01 09:24:00 | History |
| 204 | Radha | Sharma | 9.2 | 2021-09-01 12:45:00 | Chemistry |
44. Write an SQL query to find the number of students in each major who have a GPA greater than 7.5.
| MAJOR | HIGH_GPA_COUNT |
|---|---|
| Biology | 1 |
| Chemistry | 1 |
| Computer Science | 1 |
| English | 1 |
| History | 1 |
| Mathematics | 2 |
| Physics | 1 |
45. Write an SQL query to find the students who have the same GPA as ‘Shivansh Mahajan’.
| STUDENT_ID | FIRST_NAME | LAST_NAME | GPA | ENROLLMENT_DATE | MAJOR |
|---|---|---|---|---|---|
| 201 | Shivansh | Mahajan | 4 | 2021-09-01 09:30:00 | Computer Science |
In summary, mastering SQL query interview questions is essential for anyone looking to excel in roles such as data analysts, data engineers, and business analysts. This guide has provided a comprehensive collection of SQL query interview questions and answers designed to prepare you thoroughly for your interviews.
By understanding and practicing these queries, you can demonstrate your proficiency in SQL, a critical skill that underpins successful data manipulation and analysis in various tech-driven industries.
Please Login to comment...
Similar reads.
- interview-questions
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
41 Essential SQL Interview Questions *
Toptal sourced essential questions that the best sql developers and engineers can answer. driven from our community, we encourage experts to submit questions and offer feedback..
Interview Questions
What does UNION do? What is the difference between UNION and UNION ALL ?
UNION merges the contents of two structurally-compatible tables into a single combined table. The difference between UNION and UNION ALL is that UNION will omit duplicate records whereas UNION ALL will include duplicate records.
It is important to note that the performance of UNION ALL will typically be better than UNION , since UNION requires the server to do the additional work of removing any duplicates. So, in cases where is is certain that there will not be any duplicates, or where having duplicates is not a problem, use of UNION ALL would be recommended for performance reasons.
List and explain the different types of JOIN clauses supported in ANSI-standard SQL.
ANSI-standard SQL specifies five types of JOIN clauses as follows:
INNER JOIN (a.k.a. “simple join”): Returns all rows for which there is at least one match in BOTH tables. This is the default type of join if no specific JOIN type is specified.
LEFT JOIN (or LEFT OUTER JOIN ): Returns all rows from the left table, and the matched rows from the right table; i.e., the results will contain all records from the left table, even if the JOIN condition doesn’t find any matching records in the right table. This means that if the ON clause doesn’t match any records in the right table, the JOIN will still return a row in the result for that record in the left table, but with NULL in each column from the right table.
RIGHT JOIN (or RIGHT OUTER JOIN ): Returns all rows from the right table, and the matched rows from the left table. This is the exact opposite of a LEFT JOIN ; i.e., the results will contain all records from the right table, even if the JOIN condition doesn’t find any matching records in the left table. This means that if the ON clause doesn’t match any records in the left table, the JOIN will still return a row in the result for that record in the right table, but with NULL in each column from the left table.
FULL JOIN (or FULL OUTER JOIN ): Returns all rows for which there is a match in EITHER of the tables. Conceptually, a FULL JOIN combines the effect of applying both a LEFT JOIN and a RIGHT JOIN ; i.e., its result set is equivalent to performing a UNION of the results of left and right outer queries.
CROSS JOIN : Returns all records where each row from the first table is combined with each row from the second table (i.e., returns the Cartesian product of the sets of rows from the joined tables). Note that a CROSS JOIN can either be specified using the CROSS JOIN syntax (“explicit join notation”) or (b) listing the tables in the FROM clause separated by commas without using a WHERE clause to supply join criteria (“implicit join notation”).
Given the following tables:
What will be the result of the query below?
Explain your answer and also provide an alternative version of this query that will avoid the issue that it exposes.
Surprisingly, given the sample data provided, the result of this query will be an empty set. The reason for this is as follows: If the set being evaluated by the SQL NOT IN condition contains any values that are null, then the outer query here will return an empty set, even if there are many runner ids that match winner_ids in the races table.
Knowing this, a query that avoids this issue would be as follows:
Note, this is assuming the standard SQL behavior that you get without modifying the default ANSI_NULLS setting.
Apply to Join Toptal's Development Network
and enjoy reliable, steady, remote Freelance SQL Developer Jobs
Given two tables created and populated as follows:
What will the result be from the following query:
Explain your answer.
The result of the query will be as follows:
The EXISTS clause in the above query is a red herring. It will always be true since ID is not a member of dbo.docs . As such, it will refer to the envelope table comparing itself to itself!
The idnum value of NULL will not be set since the join of NULL will not return a result when attempting a match with any value of envelope .
Assume a schema of Emp ( Id, Name, DeptId ) , Dept ( Id, Name) .
If there are 10 records in the Emp table and 5 records in the Dept table, how many rows will be displayed in the result of the following SQL query:
The query will result in 50 rows as a “cartesian product” or “cross join”, which is the default whenever the ‘where’ clause is omitted.
Given two tables created as follows
Write a query to fetch values in table test_a that are and not in test_b without using the NOT keyword.
Note, Oracle does not support the above INSERT syntax, so you would need this instead:
In SQL Server, PostgreSQL, and SQLite, this can be done using the except keyword as follows:
In Oracle, the minus keyword is used instead. Note that if there are multiple columns, say ID and Name, the column should be explicitly stated in Oracle queries: Select ID from test_a minus select ID from test_b
MySQL does not support the except function. However, there is a standard SQL solution that works in all of the above engines, including MySQL:
Write a SQL query to find the 10th highest employee salary from an Employee table. Explain your answer.
(Note: You may assume that there are at least 10 records in the Employee table.)
This can be done as follows:
This works as follows:
First, the SELECT DISTINCT TOP (10) Salary FROM Employee ORDER BY Salary DESC query will select the top 10 salaried employees in the table. However, those salaries will be listed in descending order. That was necessary for the first query to work, but now picking the top 1 from that list will give you the highest salary not the the 10th highest salary.
Therefore, the second query reorders the 10 records in ascending order (which the default sort order) and then selects the top record (which will now be the lowest of those 10 salaries).
Not all databases support the TOP keyword. For example, MySQL and PostreSQL use the LIMIT keyword, as follows:
Or even more concisely, in MySQL this can be:
And in PostgreSQL this can be:
Write a SQL query using UNION ALL ( not UNION ) that uses the WHERE clause to eliminate duplicates. Why might you want to do this?
You can avoid duplicates using UNION ALL and still run much faster than UNION DISTINCT (which is actually same as UNION) by running a query like this:
The key is the AND a!=X part. This gives you the benefits of the UNION (a.k.a., UNION DISTINCT ) command, while avoiding much of its performance hit.
Write a query to to get the list of users who took the a training lesson more than once in the same day, grouped by user and training lesson, each ordered from the most recent lesson date to oldest date.
What is an execution plan? When would you use it? How would you view the execution plan?
An execution plan is basically a road map that graphically or textually shows the data retrieval methods chosen by the SQL server’s query optimizer for a stored procedure or ad hoc query. Execution plans are very useful for helping a developer understand and analyze the performance characteristics of a query or stored procedure, since the plan is used to execute the query or stored procedure.
In many SQL systems, a textual execution plan can be obtained using a keyword such as EXPLAIN , and visual representations can often be obtained as well. In Microsoft SQL Server, the Query Analyzer has an option called “Show Execution Plan” (located on the Query drop down menu). If this option is turned on, it will display query execution plans in a separate window when a query is run.
List and explain each of the ACID properties that collectively guarantee that database transactions are processed reliably.
ACID (Atomicity, Consistency, Isolation, Durability) is a set of properties that guarantee that database transactions are processed reliably. They are defined as follows:
- Atomicity. Atomicity requires that each transaction be “all or nothing”: if one part of the transaction fails, the entire transaction fails, and the database state is left unchanged. An atomic system must guarantee atomicity in each and every situation, including power failures, errors, and crashes.
- Consistency. The consistency property ensures that any transaction will bring the database from one valid state to another. Any data written to the database must be valid according to all defined rules, including constraints, cascades, triggers, and any combination thereof.
- Isolation. The isolation property ensures that the concurrent execution of transactions results in a system state that would be obtained if transactions were executed serially, i.e., one after the other. Providing isolation is the main goal of concurrency control. Depending on concurrency control method (i.e. if it uses strict - as opposed to relaxed - serializability), the effects of an incomplete transaction might not even be visible to another transaction.
- Durability. Durability means that once a transaction has been committed, it will remain so, even in the event of power loss, crashes, or errors. In a relational database, for instance, once a group of SQL statements execute, the results need to be stored permanently (even if the database crashes immediately thereafter). To defend against power loss, transactions (or their effects) must be recorded in a non-volatile memory.
Given a table dbo.users where the column user_id is a unique numeric identifier, how can you efficiently select the first 100 odd user_id values from the table?
(Assume the table contains well over 100 records with odd user_id values.)
SELECT TOP 100 user_id FROM dbo.users WHERE user_id % 2 = 1 ORDER BY user_id
What are the NVL and the NVL2 functions in SQL? How do they differ?
Both the NVL(exp1, exp2) and NVL2(exp1, exp2, exp3) functions check the value exp1 to see if it is null.
With the NVL(exp1, exp2) function, if exp1 is not null, then the value of exp1 is returned; otherwise, the value of exp2 is returned, but case to the same data type as that of exp1 .
With the NVL2(exp1, exp2, exp3) function, if exp1 is not null, then exp2 is returned; otherwise, the value of exp3 is returned.
How can you select all the even number records from a table? All the odd number records?
To select all the even number records from a table:
To select all the odd number records from a table:
What is the difference between the RANK() and DENSE_RANK() functions? Provide an example.
The only difference between the RANK() and DENSE_RANK() functions is in cases where there is a “tie”; i.e., in cases where multiple values in a set have the same ranking. In such cases, RANK() will assign non-consecutive “ranks” to the values in the set (resulting in gaps between the integer ranking values when there is a tie), whereas DENSE_RANK() will assign consecutive ranks to the values in the set (so there will be no gaps between the integer ranking values in the case of a tie).
For example, consider the set {25, 25, 50, 75, 75, 100} . For such a set, RANK() will return {1, 1, 3, 4, 4, 6} (note that the values 2 and 5 are skipped), whereas DENSE_RANK() will return {1,1,2,3,3,4} .
What is the difference between the WHERE and HAVING clauses?
When GROUP BY is not used, the WHERE and HAVING clauses are essentially equivalent.
However, when GROUP BY is used:
- The WHERE clause is used to filter records from a result. The filtering occurs before any groupings are made.
- The HAVING clause is used to filter values from a group (i.e., to check conditions after aggregation into groups has been performed).
Given a table Employee having columns empName and empId , what will be the result of the SQL query below?
“Order by 2” is only valid when there are at least two columns being used in select statement. However, in this query, even though the Employee table has 2 columns, the query is only selecting 1 column name, so “Order by 2” will cause the statement to throw an error while executing the above sql query.
What will be the output of the below query, given an Employee table having 10 records?
This query will return 10 records as TRUNCATE was executed in the transaction. TRUNCATE does not itself keep a log but BEGIN TRANSACTION keeps track of the TRUNCATE command.
- What is the difference between single-row functions and multiple-row functions?
- What is the group by clause used for?
- Single-row functions work with single row at a time. Multiple-row functions work with data of multiple rows at a time.
- The group by clause combines all those records that have identical values in a particular field or any group of fields.
Imagine a single column in a table that is populated with either a single digit (0-9) or a single character (a-z, A-Z). Write a SQL query to print ‘Fizz’ for a numeric value or ‘Buzz’ for alphabetical value for all values in that column.
['d', 'x', 'T', 8, 'a', 9, 6, 2, 'V']
…should output:
['Buzz', 'Buzz', 'Buzz', 'Fizz', 'Buzz','Fizz', 'Fizz', 'Fizz', 'Buzz']
What is the difference between char and varchar2 ?
When stored in a database, varchar2 uses only the allocated space. E.g. if you have a varchar2(1999) and put 50 bytes in the table, it will use 52 bytes.
But when stored in a database, char always uses the maximum length and is blank-padded. E.g. if you have char(1999) and put 50 bytes in the table, it will consume 2000 bytes.
Write an SQL query to display the text CAPONE as:
Or in other words, an SQL query to transpose text.
In Oracle SQL, this can be done as follows:
Can we insert a row for identity column implicitly?
Yes, like so:
Given this table:
What will be the output of below snippet?
Table is as follows:
| ID | C1 | C2 | C3 |
|---|---|---|---|
| 1 | Red | Yellow | Blue |
| 2 | NULL | Red | Green |
| 3 | Yellow | NULL | Violet |
Print the rows which have ‘Yellow’ in one of the columns C1, C2, or C3, but without using OR .
Write a query to insert/update Col2 ’s values to look exactly opposite to Col1 ’s values.
| Col1 | Col2 |
|---|---|
| 1 | 0 |
| 0 | 1 |
| 0 | 1 |
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
| 1 | 0 |
| 1 | 0 |
Or if the type is numeric:
How do you get the last id without the max function?
In SQL Server:
What is the difference between IN and EXISTS ?
- Works on List result set
- Doesn’t work on subqueries resulting in Virtual tables with multiple columns
- Compares every value in the result list
- Performance is comparatively SLOW for larger resultset of subquery
- Works on Virtual tables
- Is used with co-related queries
- Exits comparison when match is found
- Performance is comparatively FAST for larger resultset of subquery
Suppose in a table, seven records are there.
The column is an identity column.
Now the client wants to insert a record after the identity value 7 with its identity value starting from 10 .
Is it possible? If so, how? If not, why not?
Yes, it is possible, using a DBCC command:
How can you use a CTE to return the fifth highest (or Nth highest) salary from a table?
Given the following table named A :
Write a single query to calculate the sum of all positive values of x and he sum of all negative values of x .
Given the table mass_table :
| weight |
|---|
| 5.67 |
| 34.567 |
| 365.253 |
| 34 |
Write a query that produces the output:
| weight | kg | gms |
|---|---|---|
| 5.67 | 5 | 67 |
| 34.567 | 34 | 567 |
| 365.253 | 365 | 253 |
| 34 | 34 | 0 |
Consider the Employee table below.
| Emp_Id | Emp_name | Salary | Manager_Id |
|---|---|---|---|
| 10 | Anil | 50000 | 18 |
| 11 | Vikas | 75000 | 16 |
| 12 | Nisha | 40000 | 18 |
| 13 | Nidhi | 60000 | 17 |
| 14 | Priya | 80000 | 18 |
| 15 | Mohit | 45000 | 18 |
| 16 | Rajesh | 90000 | – |
| 17 | Raman | 55000 | 16 |
| 18 | Santosh | 65000 | 17 |
Write a query to generate below output:
| Manager_Id | Manager | Average_Salary_Under_Manager |
|---|---|---|
| 16 | Rajesh | 65000 |
| 17 | Raman | 62500 |
| 18 | Santosh | 53750 |
How do you copy data from one table to another table ?
Find the SQL statement below that is equal to the following: SELECT name FROM customer WHERE state = 'VA';
- SELECT name IN customer WHERE state IN ('VA');
- SELECT name IN customer WHERE state = 'VA';
- SELECT name IN customer WHERE state = 'V';
- SELECT name FROM customer WHERE state IN ('VA');
Given these contents of the Customers table:
Here is a query written to return the list of customers not referred by Jane Smith:
What will be the result of the query? Why? What would be a better way to write it?
Although there are 4 customers not referred by Jane Smith (including Jane Smith herself), the query will only return one: Pat Richards. All the customers who were referred by nobody at all (and therefore have NULL in their ReferredBy column) don’t show up. But certainly those customers weren’t referred by Jane Smith, and certainly NULL is not equal to 2, so why didn’t they show up?
SQL Server uses three-valued logic, which can be troublesome for programmers accustomed to the more satisfying two-valued logic (TRUE or FALSE) most programming languages use. In most languages, if you were presented with two predicates: ReferredBy = 2 and ReferredBy <> 2, you would expect one of them to be true and one of them to be false, given the same value of ReferredBy. In SQL Server, however, if ReferredBy is NULL, neither of them are true and neither of them are false. Anything compared to NULL evaluates to the third value in three-valued logic: UNKNOWN.
The query should be written in one of two ways:
Watch out for the following, though!
This will return the same faulty set as the original. Why? We already covered that: Anything compared to NULL evaluates to the third value in the three-valued logic: UNKNOWN. That “anything” includes NULL itself! That’s why SQL Server provides the IS NULL and IS NOT NULL operators to specifically check for NULL. Those particular operators will always evaluate to true or false.
Even if a candidate doesn’t have a great amount of experience with SQL Server, diving into the intricacies of three-valued logic in general can give a good indication of whether they have the ability learn it quickly or whether they will struggle with it.
Given a table TBL with a field Nmbr that has rows with the following values:
1, 0, 0, 1, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 1
Write a query to add 2 where Nmbr is 0 and add 3 where Nmbr is 1.
Suppose we have a Customer table containing the following data:
Write a single SQL statement to concatenate all the customer names into the following single semicolon-separated string:
This is close, but will have an undesired trailing ; . One way of fixing that could be:
In PostgreSQL one can also use this syntax to achieve the fully correct result:
How do you get the Nth-highest salary from the Employee table without a subquery or CTE?
This will give the third-highest salary from the Employee table. Accordingly we can find out Nth salary using LIMIT (N-1),1 .
But MS SQL Server doesn’t support that syntax, so in that case:
OFFSET ’s parameter corresponds to the (N-1) above.
How to find a duplicate record?
duplicate records with one field
duplicate records with more than one field
Considering the database schema displayed in the SQLServer-style diagram below, write a SQL query to return a list of all the invoices. For each invoice, show the Invoice ID, the billing date, the customer’s name, and the name of the customer who referred that customer (if any). The list should be ordered by billing date.
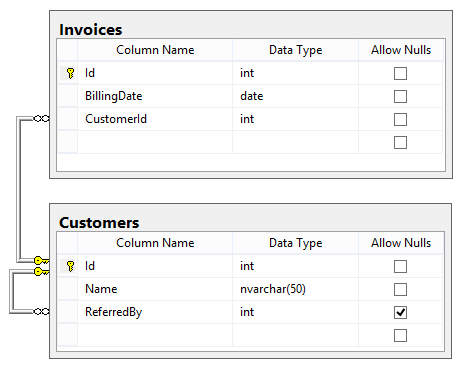
This question simply tests the candidate’s ability take a plain-English requirement and write a corresponding SQL query. There is nothing tricky in this one, it just covers the basics:
Did the candidate remember to use a LEFT JOIN instead of an inner JOIN when joining the customer table for the referring customer name? If not, any invoices by customers not referred by somebody will be left out altogether.
Did the candidate alias the tables in the JOIN? Most experienced T-SQL programmers always do this, because repeating the full table name each time it needs to be referenced gets tedious quickly. In this case, the query would actually break if at least the Customer table wasn’t aliased, because it is referenced twice in different contexts (once as the table which contains the name of the invoiced customer, and once as the table which contains the name of the referring customer).
Did the candidate disambiguate the Id and Name columns in the SELECT? Again, this is something most experienced programmers do automatically, whether or not there would be a conflict. And again, in this case there would be a conflict, so the query would break if the candidate neglected to do so.
Note that this query will not return Invoices that do not have an associated Customer. This may be the correct behavior for most cases (e.g., it is guaranteed that every Invoice is associated with a Customer, or unmatched Invoices are not of interest). However, in order to guarantee that all Invoices are returned no matter what, the Invoices table should be joined with Customers using LEFT JOIN:
There is more to interviewing than tricky technical questions, so these are intended merely as a guide. Not every “A” candidate worth hiring will be able to answer them all, nor does answering them all guarantee an “A” candidate. At the end of the day, hiring remains an art, a science — and a lot of work .
Tired of interviewing candidates? Not sure what to ask to get you a top hire?
Let Toptal find the best people for you.
Our Exclusive Network of SQL Developers
Looking to land a job as a SQL Developer?
Let Toptal find the right job for you.
Job Opportunities From Our Network
Submit an interview question
Submitted questions and answers are subject to review and editing, and may or may not be selected for posting, at the sole discretion of Toptal, LLC.
Looking for SQL Developers?
Looking for SQL Developers ? Check out Toptal’s SQL developers.

Andrea Angiolini
Andrea's been working in hospitality technology for over 20 years and has been involved in almost every aspect of it: database administration, SQL reports, database development (PL/SQL), product management, project management, design of new products, implementation, process automation, support, training, and senior management. Andrea has delivered several projects involving coordinating teams, including OTA-based integrations, full end-to-end solutions, and a full customer intelligence database.

Jeremy Barrio
Jeremy is a Microsoft SQL Server database administrator and T-SQL developer offering nearly 15 years of experience working with SQL Server 2008-2019, developing T-SQL queries and stored procedures, managing database-related projects, monitoring and optimizing databases, and developing and maintaining recurring automated processes using SQL jobs, SSIS, and PowerShell. Jeremy enjoys learning new technologies and excels with replication, HA/DR, and clustering.

Pedro Correia
Pedro has been working with Microsoft technologies since the early days of MS-DOS and GW-BASIC when he became fascinated with DBMS and used SQL Server 6.5 for the first time. During the last 20 years, he's implemented numerous web and Windows solutions in .NET, using SQL Server on the back end. Also, he taught several official Microsoft courses where he shared his expertise in the field. In one sentence, Pedro is eager to learn, inspired by challenges, and motivated to share.
Toptal Connects the Top 3% of Freelance Talent All Over The World.
Join the Toptal community.

Top SQL Interview Questions to Practice

- Share article on Twitter
- Share article on Facebook
- Share article on LinkedIn
With an average pay of around $112,120 per year and a healthy job outlook, database positions , particularly those involving SQL skills, are a hot commodity. But, with high competition comes high pressure to ace the interview. Responding to questions with tangible examples and showing the best of your SQL abilities can give you a leg up on the competition.
A little prep can go a long way towards giving you the confidence you need to make the best possible impression during the interview process. Keep reading to learn the kinds of questions to expect during a SQL interview, how to answer them, and how our courses can help you prepare. Then, put your skills to the test in our updated Data Analyst and Data Scientist Interview Prep paths. You’ll answer open-ended questions on the spot and receive instant AI-generated feedback to help you identify and enhance areas of weakness.
Learn something new for free
- Intro to ChatGPT
Behavioral SQL job interview questions
During the interview process, you’ll likely have two different interviews — a technical interview and a behavioral interview. For the behavioral interview , sometimes called “situational,” you’ll be asked questions that evaluate your soft skills , not your technical ones. Here are common behavioral interview questions to prepare for.
Adaptability and ability to learn
Questions related to adaptability and learning give you a chance to show your interviewer that you can adjust to difficult situations and grasp new skills and concepts. You can go into as much detail as you’d like while answering these questions, but also keep in mind that direct, tangible examples from your past experience will help draw your audience in.
Describe a time when you had to learn a new programming language.
As you answer this question, try to showcase your ability to learn under pressure. If you’re new to coding, no problem. Discuss the reasons that drove you to learn and how you made sure you gained a working knowledge of the language.
Talk about a time when you had to incorporate feedback.
Being able to accept feedback while on a development team is sometimes more important than your coding knowledge. Before going into the interview, try to have at least one example in mind where you had to change what you did or alter your approach to a problem based on someone else’s ideas.
Communication skills
Have you ever had to incorporate input from upper management? These scenarios come up more often than you might think, and how you communicate and work with the management team to figure out a new solution is a great story to talk about during an interview.
This is your chance to show your interviewer that you know how to:
- Listen carefully
- Keep your eye on high-level objectives
- Incorporate abstract ideas or desires into your coding
- Produce products that serve the needs of both customers and the higher-ups
If you’re short on experiences like this, don’t worry. Even if all you had to do was speed up your process to meet a deadline, you can still share your experience, the challenges involved, and how you overcame them.
Describe a time when you disagreed with a team member.
Whether it was a difference of opinion regarding the business logic of code or how to present your final product, interactions like these can be powerful examples during your interview.
Not only can you use scenarios like these to explain how much you learned from a teammate, but you can also highlight how you communicated your opinions and advice during the situation as well. As you answer, be sure to acknowledge:
- Something you learned from your team member
- Something you learned from the experience, in general
- A way in which your thinking shifted based on what you learned from the interaction
These details show you’re introspective and humble when interacting with team members.
Technical SQL interview questions
Once you complete the behavioral interview, you’ll move on to the technical interview . In some cases, you may get a heads up about what questions to expect during the technical interview and the project you’ll be asked to complete. But, not always.
Here are some of the kinds of questions you should get comfortable answering before the interview.
Explain some of the different kinds of SQL indexes.
To answer this question, you’ll want to specifically outline indexes such as:
- Clustered index, which contains groups of data stored in the same area of a table so they can be retrieved together
- Non-clustered index, which is used when you need key-based queries, instead of ranges, which work better with clustered indices
Keep in mind that the majority of SQL databases will make the best index decision for you — based on your use case. It may be helpful to mention this as well.
What’s the difference between a cross join and a natural join?
A cross join will result in the Cartesian product between a set of two tables. You use it when you’re trying to make a combination using all of the rows from two different tables.
A natural join produces a table that combines columns of the same type and name. The shared columns between two tables will be eligible for this kind of join.
Describe a situation where you would decide to use a blank space or a zero instead of a NULL value within a row.
This question tests your knowledge of the difference between NULL, blank, and zero, which all output “nothing” for the end-user. Here’s a way to answer it.
When someone is filling out a form, for instance, NULL can indicate that someone may be able to provide an answer in a field but they choose not to. Zero, on the other hand, means there was no answer to be given, so the user had no choice but to enter “nothing.”
How to practice for the technical interview
To prepare for an SQL job or any database-related interview, you can rely on our skill paths. In our recently updated interview prep courses , you’ll get to practice answering free-response questions and receive AI-generated feedback:
- Data Analyst Interview Preparation . In addition to SQL, this will cover Python, statistics, A/B testing, data visualization, data cleaning, communication, and specific technical interview preparation .
- Data Scientist Interview Preparation . This course covers much of the same basic skills and concepts of the Data Analyst Interview Prep Skill Path (SQL, Python, data cleaning, and visualization), but it adds in algorithms and machine learning .
We also offer technical interview practice for:
So, whether you’ve just begun thinking about a career in SQL programming or already have the basic knowledge you need, you can use the tips above to impress whoever’s on the other side of the table. The courses, career paths, and skill paths we offer can put you in a position to confidently enter an interview ready to leave a great impression.
Remember to prepare ahead of time, throw in some fun practice sessions, and always use tangible examples to back up any claims you make about your skills or experience. To get you started on a new SQL journey, you can use Analyze Data with SQL , Analyze Business Data with SQL , Learn SQL , and How to Transform Tables with SQL .
This blog was originally published in October 2021 and has been updated to include details about our new AI interview prep features.
Related courses
Data analyst interview prep, data scientist interview prep, analyze data with sql, data scientist: analytics specialist, subscribe for news, tips, and more, related articles.

Learning Python Had an Immense Impact on My Career as a Cancer Researcher
Today’s story is from Joshua Lange, a 31-year-old Research Scientist at a biotech company, living in Stockholm, Sweden.

How Customer Support Jobs Can Kick-Start Your Tech Career
Working in Customer Support gives you a front-row seat to how customers interact with a product (and coding experience isn’t required).

Looking For a Job in Tech? Start With These Job Boards
Ready to look for your next (or first) tech job? Here are the best job boards to check out.

Can You Be a Software Engineer Without Strong Math Skills?
Do you need to know math to become a Software Engineer? For most development projects, basic math is enough, but having a mathematics background can pay off.

Cool Job: I Analyze Pinterest Data Using SQL & Python
How an actuary with a knack for trivia became a data professional at Pinterest.

Cool Job: I Use Python to Analyze Esports Data for Evil Geniuses
Ivan Sheng uses Python and SQL to analyze esports metrics in games like League of Legends and Counter-Strike.

How I Went From Working At A Pub To Junior Full Stack Developer
Today’s story is from Gwen Bradbury, a 32-year-old Junior Full-Stack Developer at Bunches living in Nottingham, U.K.
Download Interview guide PDF
Sql interview questions, download pdf.

Are you preparing for your SQL developer interview?
Then you have come to the right place.
This guide will help you to brush up on your SQL skills, regain your confidence and be job-ready!
Here, you will find a collection of real-world Interview questions asked in companies like Google, Oracle, Amazon, and Microsoft, etc. Each question comes with a perfectly written answer inline, saving your interview preparation time.
It also covers practice problems to help you understand the basic concepts of SQL .
We've divided this article into the following sections:
PostgreSQL Interview Questions
In the end, multiple-choice questions are provided to test your understanding.
1. What is Pattern Matching in SQL?
SQL pattern matching provides for pattern search in data if you have no clue as to what that word should be. This kind of SQL query uses wildcards to match a string pattern, rather than writing the exact word. The LIKE operator is used in conjunction with SQL Wildcards to fetch the required information.
- Using the % wildcard to perform a simple search
The % wildcard matches zero or more characters of any type and can be used to define wildcards both before and after the pattern. Search a student in your database with first name beginning with the letter K:
- Omitting the patterns using the NOT keyword
Use the NOT keyword to select records that don't match the pattern. This query returns all students whose first name does not begin with K.
- Matching a pattern anywhere using the % wildcard twice
Search for a student in the database where he/she has a K in his/her first name.
- Using the _ wildcard to match pattern at a specific position
The _ wildcard matches exactly one character of any type. It can be used in conjunction with % wildcard. This query fetches all students with letter K at the third position in their first name.
- Matching patterns for a specific length
The _ wildcard plays an important role as a limitation when it matches exactly one character. It limits the length and position of the matched results. For example -
2. How to create empty tables with the same structure as another table?
Creating empty tables with the same structure can be done smartly by fetching the records of one table into a new table using the INTO operator while fixing a WHERE clause to be false for all records. Hence, SQL prepares the new table with a duplicate structure to accept the fetched records but since no records get fetched due to the WHERE clause in action, nothing is inserted into the new table.
3. What is a Recursive Stored Procedure?
A stored procedure that calls itself until a boundary condition is reached, is called a recursive stored procedure. This recursive function helps the programmers to deploy the same set of code several times as and when required. Some SQL programming languages limit the recursion depth to prevent an infinite loop of procedure calls from causing a stack overflow, which slows down the system and may lead to system crashes.
4. What is a Stored Procedure?
A stored procedure is a subroutine available to applications that access a relational database management system (RDBMS). Such procedures are stored in the database data dictionary. The sole disadvantage of stored procedure is that it can be executed nowhere except in the database and occupies more memory in the database server. It also provides a sense of security and functionality as users who can't access the data directly can be granted access via stored procedures.

5. What is Collation? What are the different types of Collation Sensitivity?
Collation refers to a set of rules that determine how data is sorted and compared. Rules defining the correct character sequence are used to sort the character data. It incorporates options for specifying case sensitivity, accent marks, kana character types, and character width. Below are the different types of collation sensitivity:
- Case sensitivity: A and a are treated differently.
- Accent sensitivity: a and á are treated differently.
- Kana sensitivity: Japanese kana characters Hiragana and Katakana are treated differently.
- Width sensitivity: Same character represented in single-byte (half-width) and double-byte (full-width) are treated differently.
Learn via our Video Courses
6. what are the differences between oltp and olap.
OLTP stands for Online Transaction Processing , is a class of software applications capable of supporting transaction-oriented programs. An important attribute of an OLTP system is its ability to maintain concurrency. OLTP systems often follow a decentralized architecture to avoid single points of failure. These systems are generally designed for a large audience of end-users who conduct short transactions. Queries involved in such databases are generally simple, need fast response times, and return relatively few records. A number of transactions per second acts as an effective measure for such systems.
OLAP stands for Online Analytical Processing , a class of software programs that are characterized by the relatively low frequency of online transactions. Queries are often too complex and involve a bunch of aggregations. For OLAP systems, the effectiveness measure relies highly on response time. Such systems are widely used for data mining or maintaining aggregated, historical data, usually in multi-dimensional schemas.

7. What is OLTP?
OLTP stands for Online Transaction Processing, is a class of software applications capable of supporting transaction-oriented programs. An essential attribute of an OLTP system is its ability to maintain concurrency. To avoid single points of failure, OLTP systems are often decentralized. These systems are usually designed for a large number of users who conduct short transactions. Database queries are usually simple, require sub-second response times, and return relatively few records. Here is an insight into the working of an OLTP system [ Note - The figure is not important for interviews ] -

8. What is User-defined function? What are its various types?
The user-defined functions in SQL are like functions in any other programming language that accept parameters, perform complex calculations, and return a value. They are written to use the logic repetitively whenever required. There are two types of SQL user-defined functions:
- Scalar Function: As explained earlier, user-defined scalar functions return a single scalar value.
- Inline: returns a table data type based on a single SELECT statement.
- Multi-statement: returns a tabular result-set but, unlike inline, multiple SELECT statements can be used inside the function body.
9. What is a UNIQUE constraint?
A UNIQUE constraint ensures that all values in a column are different. This provides uniqueness for the column(s) and helps identify each row uniquely. Unlike primary key, there can be multiple unique constraints defined per table. The code syntax for UNIQUE is quite similar to that of PRIMARY KEY and can be used interchangeably.
10. What is a Query?
A query is a request for data or information from a database table or combination of tables. A database query can be either a select query or an action query.
11. What is Data Integrity?
Data Integrity is the assurance of accuracy and consistency of data over its entire life-cycle and is a critical aspect of the design, implementation, and usage of any system which stores, processes, or retrieves data. It also defines integrity constraints to enforce business rules on the data when it is entered into an application or a database.
12. What is the difference between Clustered and Non-clustered index?
As explained above, the differences can be broken down into three small factors -
- Clustered index modifies the way records are stored in a database based on the indexed column. A non-clustered index creates a separate entity within the table which references the original table.
- Clustered index is used for easy and speedy retrieval of data from the database, whereas, fetching records from the non-clustered index is relatively slower.
- In SQL, a table can have a single clustered index whereas it can have multiple non-clustered indexes.
13. What is an Index? Explain its different types.
A database index is a data structure that provides a quick lookup of data in a column or columns of a table. It enhances the speed of operations accessing data from a database table at the cost of additional writes and memory to maintain the index data structure.
There are different types of indexes that can be created for different purposes:
- Unique and Non-Unique Index:
Unique indexes are indexes that help maintain data integrity by ensuring that no two rows of data in a table have identical key values. Once a unique index has been defined for a table, uniqueness is enforced whenever keys are added or changed within the index.
Non-unique indexes, on the other hand, are not used to enforce constraints on the tables with which they are associated. Instead, non-unique indexes are used solely to improve query performance by maintaining a sorted order of data values that are used frequently.
- Clustered and Non-Clustered Index:
Clustered indexes are indexes whose order of the rows in the database corresponds to the order of the rows in the index. This is why only one clustered index can exist in a given table, whereas, multiple non-clustered indexes can exist in the table.
The only difference between clustered and non-clustered indexes is that the database manager attempts to keep the data in the database in the same order as the corresponding keys appear in the clustered index.
Clustering indexes can improve the performance of most query operations because they provide a linear-access path to data stored in the database.
Write a SQL statement to create a UNIQUE INDEX "my_index" on "my_table" for fields "column_1" & "column_2".
14. what is a cross-join.
Cross join can be defined as a cartesian product of the two tables included in the join. The table after join contains the same number of rows as in the cross-product of the number of rows in the two tables. If a WHERE clause is used in cross join then the query will work like an INNER JOIN.

Write a SQL statement to CROSS JOIN 'table_1' with 'table_2' and fetch 'col_1' from table_1 & 'col_2' from table_2 respectively. Do not use alias.
Write a sql statement to perform self join for 'table_x' with alias 'table_1' and 'table_2', on columns 'col_1' and 'col_2' respectively., 15. what is a self-join.
A self JOIN is a case of regular join where a table is joined to itself based on some relation between its own column(s). Self-join uses the INNER JOIN or LEFT JOIN clause and a table alias is used to assign different names to the table within the query.
16. What is a Join? List its different types.
The SQL Join clause is used to combine records (rows) from two or more tables in a SQL database based on a related column between the two.

There are four different types of JOINs in SQL:
- (INNER) JOIN: Retrieves records that have matching values in both tables involved in the join. This is the widely used join for queries.
- LEFT (OUTER) JOIN: Retrieves all the records/rows from the left and the matched records/rows from the right table.
- RIGHT (OUTER) JOIN: Retrieves all the records/rows from the right and the matched records/rows from the left table.
- FULL (OUTER) JOIN: Retrieves all the records where there is a match in either the left or right table.
17. What is a Foreign Key?
A FOREIGN KEY comprises of single or collection of fields in a table that essentially refers to the PRIMARY KEY in another table. Foreign key constraint ensures referential integrity in the relation between two tables. The table with the foreign key constraint is labeled as the child table, and the table containing the candidate key is labeled as the referenced or parent table.
What type of integrity constraint does the foreign key ensure?
Write a sql statement to add a foreign key 'col_fk' in 'table_y' that references 'col_pk' in 'table_x'., 18. what is a subquery what are its types.
A subquery is a query within another query, also known as a nested query or inner query . It is used to restrict or enhance the data to be queried by the main query, thus restricting or enhancing the output of the main query respectively. For example, here we fetch the contact information for students who have enrolled for the maths subject:
There are two types of subquery - Correlated and Non-Correlated .
- A correlated subquery cannot be considered as an independent query, but it can refer to the column in a table listed in the FROM of the main query.
- A non-correlated subquery can be considered as an independent query and the output of the subquery is substituted in the main query.
Write a SQL query to update the field "status" in table "applications" from 0 to 1.
Write a sql query to select the field "app_id" in table "applications" where "app_id" less than 1000., write a sql query to fetch the field "app_name" from "apps" where "apps.id" is equal to the above collection of "app_id"., 19. what is a primary key.
The PRIMARY KEY constraint uniquely identifies each row in a table. It must contain UNIQUE values and has an implicit NOT NULL constraint. A table in SQL is strictly restricted to have one and only one primary key, which is comprised of single or multiple fields (columns).
write a sql statement to add primary key 't_id' to the table 'teachers'.
Write a sql statement to add primary key constraint 'pk_a' for table 'table_a' and fields 'col_b, col_c'., 20. what are constraints in sql.
Constraints are used to specify the rules concerning data in the table. It can be applied for single or multiple fields in an SQL table during the creation of the table or after creating using the ALTER TABLE command. The constraints are:
- NOT NULL - Restricts NULL value from being inserted into a column.
- CHECK - Verifies that all values in a field satisfy a condition.
- DEFAULT - Automatically assigns a default value if no value has been specified for the field.
- UNIQUE - Ensures unique values to be inserted into the field.
- INDEX - Indexes a field providing faster retrieval of records.
- PRIMARY KEY - Uniquely identifies each record in a table.
- FOREIGN KEY - Ensures referential integrity for a record in another table.
21. What are Tables and Fields?
A table is an organized collection of data stored in the form of rows and columns. Columns can be categorized as vertical and rows as horizontal. The columns in a table are called fields while the rows can be referred to as records.
22. What is the difference between SQL and MySQL?
SQL is a standard language for retrieving and manipulating structured databases. On the contrary, MySQL is a relational database management system, like SQL Server, Oracle or IBM DB2, that is used to manage SQL databases.

23. What is SQL?
SQL stands for Structured Query Language. It is the standard language for relational database management systems. It is especially useful in handling organized data comprised of entities (variables) and relations between different entities of the data.
24. What is RDBMS? How is it different from DBMS?
RDBMS stands for Relational Database Management System. The key difference here , compared to DBMS, is that RDBMS stores data in the form of a collection of tables, and relations can be defined between the common fields of these tables. Most modern database management systems like MySQL, Microsoft SQL Server, Oracle, IBM DB2, and Amazon Redshift are based on RDBMS.

25. What is DBMS?
DBMS stands for Database Management System. DBMS is a system software responsible for the creation, retrieval, updation, and management of the database. It ensures that our data is consistent, organized, and is easily accessible by serving as an interface between the database and its end-users or application software.
26. What is Database?
A database is an organized collection of data, stored and retrieved digitally from a remote or local computer system. Databases can be vast and complex, and such databases are developed using fixed design and modeling approaches.
27. What is the SELECT statement?
SELECT operator in SQL is used to select data from a database. The data returned is stored in a result table, called the result-set.
28. What are some common clauses used with SELECT query in SQL?
Some common SQL clauses used in conjuction with a SELECT query are as follows:
- WHERE clause in SQL is used to filter records that are necessary, based on specific conditions.
- ORDER BY clause in SQL is used to sort the records based on some field(s) in ascending ( ASC ) or descending order ( DESC) .
- GROUP BY clause in SQL is used to group records with identical data and can be used in conjunction with some aggregation functions to produce summarized results from the database.
- HAVING clause in SQL is used to filter records in combination with the GROUP BY clause. It is different from WHERE, since the WHERE clause cannot filter aggregated records.
29. What are UNION, MINUS and INTERSECT commands?
The UNION operator combines and returns the result-set retrieved by two or more SELECT statements. The MINUS operator in SQL is used to remove duplicates from the result-set obtained by the second SELECT query from the result-set obtained by the first SELECT query and then return the filtered results from the first. The INTERSECT clause in SQL combines the result-set fetched by the two SELECT statements where records from one match the other and then returns this intersection of result-sets.
Certain conditions need to be met before executing either of the above statements in SQL -
- Each SELECT statement within the clause must have the same number of columns
- The columns must also have similar data types
- The columns in each SELECT statement should necessarily have the same order
Write a SQL query to fetch "names" that are present in either table "accounts" or in table "registry".
Write a sql query to fetch "names" that are present in "accounts" but not in table "registry"., write a sql query to fetch "names" from table "contacts" that are neither present in "accounts.name" nor in "registry.name"., 30. what is cursor how to use a cursor.
A database cursor is a control structure that allows for the traversal of records in a database. Cursors, in addition, facilitates processing after traversal, such as retrieval, addition, and deletion of database records. They can be viewed as a pointer to one row in a set of rows.
Working with SQL Cursor:
- DECLARE a cursor after any variable declaration. The cursor declaration must always be associated with a SELECT Statement.
- Open cursor to initialize the result set. The OPEN statement must be called before fetching rows from the result set.
- FETCH statement to retrieve and move to the next row in the result set.
- Call the CLOSE statement to deactivate the cursor.
- Finally use the DEALLOCATE statement to delete the cursor definition and release the associated resources.
31. What are Entities and Relationships?
Entity : An entity can be a real-world object, either tangible or intangible, that can be easily identifiable. For example, in a college database, students, professors, workers, departments, and projects can be referred to as entities. Each entity has some associated properties that provide it an identity.
Relationships : Relations or links between entities that have something to do with each other. For example - The employee's table in a company's database can be associated with the salary table in the same database.

32. List the different types of relationships in SQL.
- One-to-One - This can be defined as the relationship between two tables where each record in one table is associated with the maximum of one record in the other table.
- One-to-Many & Many-to-One - This is the most commonly used relationship where a record in a table is associated with multiple records in the other table.
- Many-to-Many - This is used in cases when multiple instances on both sides are needed for defining a relationship.
- Self-Referencing Relationships - This is used when a table needs to define a relationship with itself.
33. What is an Alias in SQL?
An alias is a feature of SQL that is supported by most, if not all, RDBMSs. It is a temporary name assigned to the table or table column for the purpose of a particular SQL query. In addition, aliasing can be employed as an obfuscation technique to secure the real names of database fields. A table alias is also called a correlation name.
An alias is represented explicitly by the AS keyword but in some cases, the same can be performed without it as well. Nevertheless, using the AS keyword is always a good practice.
Write an SQL statement to select all from table "Limited" with alias "Ltd".
34. what is a view.
A view in SQL is a virtual table based on the result-set of an SQL statement. A view contains rows and columns, just like a real table. The fields in a view are fields from one or more real tables in the database.

35. What is Normalization?
Normalization represents the way of organizing structured data in the database efficiently. It includes the creation of tables, establishing relationships between them, and defining rules for those relationships. Inconsistency and redundancy can be kept in check based on these rules, hence, adding flexibility to the database.
36. What is Denormalization?
Denormalization is the inverse process of normalization, where the normalized schema is converted into a schema that has redundant information. The performance is improved by using redundancy and keeping the redundant data consistent. The reason for performing denormalization is the overheads produced in the query processor by an over-normalized structure.
37. What are the various forms of Normalization?
Normal Forms are used to eliminate or reduce redundancy in database tables. The different forms are as follows:
- First Normal Form: A relation is in first normal form if every attribute in that relation is a single-valued attribute . If a relation contains a composite or multi-valued attribute, it violates the first normal form. Let's consider the following students table. Each student in the table, has a name, his/her address, and the books they issued from the public library -
Students Table
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter), Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho), Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward), Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
As we can observe, the Books Issued field has more than one value per record, and to convert it into 1NF, this has to be resolved into separate individual records for each book issued. Check the following table in 1NF form -
Students Table (1st Normal Form)
| Student | Address | Books Issued | Salutation |
|---|---|---|---|
| Sara | Amanora Park Town 94 | Until the Day I Die (Emily Carpenter) | Ms. |
| Sara | Amanora Park Town 94 | Inception (Christopher Nolan) | Ms. |
| Ansh | 62nd Sector A-10 | The Alchemist (Paulo Coelho) | Mr. |
| Ansh | 62nd Sector A-10 | Inferno (Dan Brown) | Mr. |
| Sara | 24th Street Park Avenue | Beautiful Bad (Annie Ward) | Mrs. |
| Sara | 24th Street Park Avenue | Woman 99 (Greer Macallister) | Mrs. |
| Ansh | Windsor Street 777 | Dracula (Bram Stoker) | Mr. |
- Second Normal Form:
A relation is in second normal form if it satisfies the conditions for the first normal form and does not contain any partial dependency. A relation in 2NF has no partial dependency , i.e., it has no non-prime attribute that depends on any proper subset of any candidate key of the table. Often, specifying a single column Primary Key is the solution to the problem. Examples -
Example 1 - Consider the above example. As we can observe, the Students Table in the 1NF form has a candidate key in the form of [Student, Address] that can uniquely identify all records in the table. The field Books Issued (non-prime attribute) depends partially on the Student field. Hence, the table is not in 2NF. To convert it into the 2nd Normal Form, we will partition the tables into two while specifying a new Primary Key attribute to identify the individual records in the Students table. The Foreign Key constraint will be set on the other table to ensure referential integrity.
Students Table (2nd Normal Form)
| Student_ID | Student | Address | Salutation |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | Ms. |
| 2 | Ansh | 62nd Sector A-10 | Mr. |
| 3 | Sara | 24th Street Park Avenue | Mrs. |
| 4 | Ansh | Windsor Street 777 | Mr. |
Books Table (2nd Normal Form)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
Example 2 - Consider the following dependencies in relation to R(W,X,Y,Z)
Here, WX is the only candidate key and there is no partial dependency, i.e., any proper subset of WX doesn’t determine any non-prime attribute in the relation.
- Third Normal Form
A relation is said to be in the third normal form, if it satisfies the conditions for the second normal form and there is no transitive dependency between the non-prime attributes, i.e., all non-prime attributes are determined only by the candidate keys of the relation and not by any other non-prime attribute.
Example 1 - Consider the Students Table in the above example. As we can observe, the Students Table in the 2NF form has a single candidate key Student_ID (primary key) that can uniquely identify all records in the table. The field Salutation (non-prime attribute), however, depends on the Student Field rather than the candidate key. Hence, the table is not in 3NF. To convert it into the 3rd Normal Form, we will once again partition the tables into two while specifying a new Foreign Key constraint to identify the salutations for individual records in the Students table. The Primary Key constraint for the same will be set on the Salutations table to identify each record uniquely.
Students Table (3rd Normal Form)
| Student_ID | Student | Address | Salutation_ID |
|---|---|---|---|
| 1 | Sara | Amanora Park Town 94 | 1 |
| 2 | Ansh | 62nd Sector A-10 | 2 |
| 3 | Sara | 24th Street Park Avenue | 3 |
| 4 | Ansh | Windsor Street 777 | 1 |
Books Table (3rd Normal Form)
| Student_ID | Book Issued |
|---|---|
| 1 | Until the Day I Die (Emily Carpenter) |
| 1 | Inception (Christopher Nolan) |
| 2 | The Alchemist (Paulo Coelho) |
| 2 | Inferno (Dan Brown) |
| 3 | Beautiful Bad (Annie Ward) |
| 3 | Woman 99 (Greer Macallister) |
| 4 | Dracula (Bram Stoker) |
Salutations Table (3rd Normal Form)
| Salutation_ID | Salutation |
|---|---|
| 1 | Ms. |
| 2 | Mr. |
| 3 | Mrs. |
Example 2 - Consider the following dependencies in relation to R(P,Q,R,S,T)
For the above relation to exist in 3NF, all possible candidate keys in the above relation should be {P, RS, QR, T}.
- Boyce-Codd Normal Form
A relation is in Boyce-Codd Normal Form if satisfies the conditions for third normal form and for every functional dependency, Left-Hand-Side is super key. In other words, a relation in BCNF has non-trivial functional dependencies in form X –> Y, such that X is always a super key. For example - In the above example, Student_ID serves as the sole unique identifier for the Students Table and Salutation_ID for the Salutations Table, thus these tables exist in BCNF. The same cannot be said for the Books Table and there can be several books with common Book Names and the same Student_ID.
38. What are the TRUNCATE, DELETE and DROP statements?
DELETE statement is used to delete rows from a table.
TRUNCATE command is used to delete all the rows from the table and free the space containing the table.
DROP command is used to remove an object from the database. If you drop a table, all the rows in the table are deleted and the table structure is removed from the database.
Write a SQL statement to wipe a table 'Temporary' from memory.
Write a sql query to remove first 1000 records from table 'temporary' based on 'id'., write a sql statement to delete the table 'temporary' while keeping its relations intact., 39. what is the difference between drop and truncate statements.
If a table is dropped, all things associated with the tables are dropped as well. This includes - the relationships defined on the table with other tables, the integrity checks and constraints, access privileges and other grants that the table has. To create and use the table again in its original form, all these relations, checks, constraints, privileges and relationships need to be redefined. However, if a table is truncated, none of the above problems exist and the table retains its original structure.
40. What is the difference between DELETE and TRUNCATE statements?
The TRUNCATE command is used to delete all the rows from the table and free the space containing the table. The DELETE command deletes only the rows from the table based on the condition given in the where clause or deletes all the rows from the table if no condition is specified. But it does not free the space containing the table.
41. What are Aggregate and Scalar functions?
An aggregate function performs operations on a collection of values to return a single scalar value. Aggregate functions are often used with the GROUP BY and HAVING clauses of the SELECT statement. Following are the widely used SQL aggregate functions:
- AVG() - Calculates the mean of a collection of values.
- COUNT() - Counts the total number of records in a specific table or view.
- MIN() - Calculates the minimum of a collection of values.
- MAX() - Calculates the maximum of a collection of values.
- SUM() - Calculates the sum of a collection of values.
- FIRST() - Fetches the first element in a collection of values.
- LAST() - Fetches the last element in a collection of values.
Note: All aggregate functions described above ignore NULL values except for the COUNT function.
A scalar function returns a single value based on the input value. Following are the widely used SQL scalar functions:
- LEN() - Calculates the total length of the given field (column).
- UCASE() - Converts a collection of string values to uppercase characters.
- LCASE() - Converts a collection of string values to lowercase characters.
- MID() - Extracts substrings from a collection of string values in a table.
- CONCAT() - Concatenates two or more strings.
- RAND() - Generates a random collection of numbers of a given length.
- ROUND() - Calculates the round-off integer value for a numeric field (or decimal point values).
- NOW() - Returns the current date & time.
- FORMAT() - Sets the format to display a collection of values.
1. What is PostgreSQL?
PostgreSQL was first called Postgres and was developed by a team led by Computer Science Professor Michael Stonebraker in 1986. It was developed to help developers build enterprise-level applications by upholding data integrity by making systems fault-tolerant. PostgreSQL is therefore an enterprise-level, flexible, robust, open-source, and object-relational DBMS that supports flexible workloads along with handling concurrent users. It has been consistently supported by the global developer community. Due to its fault-tolerant nature, PostgreSQL has gained widespread popularity among developers.
2. What is the capacity of a table in PostgreSQL?
The maximum size of PostgreSQL is 32TB.
3. What is the importance of the TRUNCATE statement?
TRUNCATE TABLE name_of_table statement removes the data efficiently and quickly from the table. The truncate statement can also be used to reset values of the identity columns along with data cleanup as shown below:
We can also use the statement for removing data from multiple tables all at once by mentioning the table names separated by comma as shown below:
4. Define tokens in PostgreSQL?
A token in PostgreSQL is either a keyword, identifier, literal, constant, quotes identifier, or any symbol that has a distinctive personality. They may or may not be separated using a space, newline or a tab. If the tokens are keywords, they are usually commands with useful meanings. Tokens are known as building blocks of any PostgreSQL code.
5. What are partitioned tables called in PostgreSQL?
Partitioned tables are logical structures that are used for dividing large tables into smaller structures that are called partitions. This approach is used for effectively increasing the query performance while dealing with large database tables. To create a partition, a key called partition key which is usually a table column or an expression, and a partitioning method needs to be defined. There are three types of inbuilt partitioning methods provided by Postgres:
- Range Partitioning : This method is done by partitioning based on a range of values. This method is most commonly used upon date fields to get monthly, weekly or yearly data. In the case of corner cases like value belonging to the end of the range, for example: if the range of partition 1 is 10-20 and the range of partition 2 is 20-30, and the given value is 10, then 10 belongs to the second partition and not the first.
- List Partitioning: This method is used to partition based on a list of known values. Most commonly used when we have a key with a categorical value. For example, getting sales data based on regions divided as countries, cities, or states.
- Hash Partitioning: This method utilizes a hash function upon the partition key. This is done when there are no specific requirements for data division and is used to access data individually. For example, you want to access data based on a specific product, then using hash partition would result in the dataset that we require.
The type of partition key and the type of method used for partitioning determines how positive the performance and the level of manageability of the partitioned table are.
6. How can we start, restart and stop the PostgreSQL server?
- To start the PostgreSQL server, we run:
- Once the server is successfully started, we get the below message:
- To restart the PostgreSQL server, we run:
Once the server is successfully restarted, we get the message:
- To stop the server, we run the command:
Once stopped successfully, we get the message:
7. What is the command used for creating a database in PostgreSQL?
The first step of using PostgreSQL is to create a database. This is done by using the createdb command as shown below: createdb db_name After running the above command, if the database creation was successful, then the below message is shown:
8. How will you change the datatype of a column?
This can be done by using the ALTER TABLE statement as shown below:
9. How do you define Indexes in PostgreSQL?
Indexes are the inbuilt functions in PostgreSQL which are used by the queries to perform search more efficiently on a table in the database. Consider that you have a table with thousands of records and you have the below query that only a few records can satisfy the condition, then it will take a lot of time to search and return those rows that abide by this condition as the engine has to perform the search operation on every single to check this condition. This is undoubtedly inefficient for a system dealing with huge data. Now if this system had an index on the column where we are applying search, it can use an efficient method for identifying matching rows by walking through only a few levels. This is called indexing.
10. Define sequence.
A sequence is a schema-bound, user-defined object which aids to generate a sequence of integers. This is most commonly used to generate values to identity columns in a table. We can create a sequence by using the CREATE SEQUENCE statement as shown below:
To get the next number 101 from the sequence, we use the nextval() method as shown below:
We can also use this sequence while inserting new records using the INSERT command:
11. What are string constants in PostgreSQL?
They are character sequences bound within single quotes. These are using during data insertion or updation to characters in the database. There are special string constants that are quoted in dollars. Syntax: $tag$<string_constant>$tag$ The tag in the constant is optional and when we are not specifying the tag, the constant is called a double-dollar string literal.
12. How can you get a list of all databases in PostgreSQL?
This can be done by using the command \l -> backslash followed by the lower-case letter L.
13. How can you delete a database in PostgreSQL?
This can be done by using the DROP DATABASE command as shown in the syntax below:
If the database has been deleted successfully, then the following message would be shown:
14. What are ACID properties? Is PostgreSQL compliant with ACID?
ACID stands for Atomicity, Consistency, Isolation, Durability. They are database transaction properties which are used for guaranteeing data validity in case of errors and failures.
- Atomicity : This property ensures that the transaction is completed in all-or-nothing way.
- Consistency : This ensures that updates made to the database is valid and follows rules and restrictions.
- Isolation : This property ensures integrity of transaction that are visible to all other transactions.
- Durability : This property ensures that the committed transactions are stored permanently in the database.
PostgreSQL is compliant with ACID properties.
15. Can you explain the architecture of PostgreSQL?
- The architecture of PostgreSQL follows the client-server model.
- The server side comprises of background process manager, query processer, utilities and shared memory space which work together to build PostgreSQL’s instance that has access to the data. The client application does the task of connecting to this instance and requests data processing to the services. The client can either be GUI (Graphical User Interface) or a web application. The most commonly used client for PostgreSQL is pgAdmin.

16. What do you understand by multi-version concurrency control?
MVCC or Multi-version concurrency control is used for avoiding unnecessary database locks when 2 or more requests tries to access or modify the data at the same time. This ensures that the time lag for a user to log in to the database is avoided. The transactions are recorded when anyone tries to access the content.
For more information regarding this, you can refer here .
17. What do you understand by command enable-debug?
The command enable-debug is used for enabling the compilation of all libraries and applications. When this is enabled, the system processes get hindered and generally also increases the size of the binary file. Hence, it is not recommended to switch this on in the production environment. This is most commonly used by developers to debug the bugs in their scripts and help them spot the issues. For more information regarding how to debug, you can refer here .
18. How do you check the rows affected as part of previous transactions?
SQL standards state that the following three phenomena should be prevented whilst concurrent transactions. SQL standards define 4 levels of transaction isolations to deal with these phenomena.
- Dirty reads : If a transaction reads data that is written due to concurrent uncommitted transaction, these reads are called dirty reads.
- Phantom reads : This occurs when two same queries when executed separately return different rows. For example, if transaction A retrieves some set of rows matching search criteria. Assume another transaction B retrieves new rows in addition to the rows obtained earlier for the same search criteria. The results are different.
- Non-repeatable reads : This occurs when a transaction tries to read the same row multiple times and gets different values each time due to concurrency. This happens when another transaction updates that data and our current transaction fetches that updated data, resulting in different values.
To tackle these, there are 4 standard isolation levels defined by SQL standards. They are as follows:
- Read Uncommitted – The lowest level of the isolations. Here, the transactions are not isolated and can read data that are not committed by other transactions resulting in dirty reads.
- Read Committed – This level ensures that the data read is committed at any instant of read time. Hence, dirty reads are avoided here. This level makes use of read/write lock on the current rows which prevents read/write/update/delete of that row when the current transaction is being operated on.
- Repeatable Read – The most restrictive level of isolation. This holds read and write locks for all rows it operates on. Due to this, non-repeatable reads are avoided as other transactions cannot read, write, update or delete the rows.
- Serializable – The highest of all isolation levels. This guarantees that the execution is serializable where execution of any concurrent operations are guaranteed to be appeared as executing serially.
The following table clearly explains which type of unwanted reads the levels avoid:
| Isolation levels | Dirty Reads | Phantom Reads | Non-repeatable reads |
|---|---|---|---|
| Read Uncommitted | Might occur | Might occur | Might occur |
| Read Committed | Won’t occur | Might occur | Might occur |
| Repeatable Read | Won’t occur | Might occur | Won’t occur |
| Serializable | Won’t occur | Won’t occur | Won’t occur |
19. What can you tell about WAL (Write Ahead Logging)?
Write Ahead Logging is a feature that increases the database reliability by logging changes before any changes are done to the database. This ensures that we have enough information when a database crash occurs by helping to pinpoint to what point the work has been complete and gives a starting point from the point where it was discontinued.
For more information, you can refer here .
20. What is the main disadvantage of deleting data from an existing table using the DROP TABLE command?
DROP TABLE command deletes complete data from the table along with removing the complete table structure too. In case our requirement entails just remove the data, then we would need to recreate the table to store data in it. In such cases, it is advised to use the TRUNCATE command.
21. How do you perform case-insensitive searches using regular expressions in PostgreSQL?
To perform case insensitive matches using a regular expression, we can use POSIX (~*) expression from pattern matching operators. For example:
22. How will you take backup of the database in PostgreSQL?
We can achieve this by using the pg_dump tool for dumping all object contents in the database into a single file. The steps are as follows:
Step 1 : Navigate to the bin folder of the PostgreSQL installation path.
Step 2: Execute pg_dump program to take the dump of data to a .tar folder as shown below:
The database dump will be stored in the sample_data.tar file on the location specified.
23. Does PostgreSQL support full text search?
Full-Text Search is the method of searching single or collection of documents stored on a computer in a full-text based database. This is mostly supported in advanced database systems like SOLR or ElasticSearch. However, the feature is present but is pretty basic in PostgreSQL.
24. What are parallel queries in PostgreSQL?
Parallel Queries support is a feature provided in PostgreSQL for devising query plans capable of exploiting multiple CPU processors to execute the queries faster.

25. Differentiate between commit and checkpoint.
The commit action ensures that the data consistency of the transaction is maintained and it ends the current transaction in the section. Commit adds a new record in the log that describes the COMMIT to the memory. Whereas, a checkpoint is used for writing all changes that were committed to disk up to SCN which would be kept in datafile headers and control files.
Conclusion:
SQL is a language for the database. It has a vast scope and robust capability of creating and manipulating a variety of database objects using commands like CREATE, ALTER, DROP, etc, and also in loading the database objects using commands like INSERT. It also provides options for Data Manipulation using commands like DELETE, TRUNCATE and also does effective retrieval of data using cursor commands like FETCH, SELECT, etc. There are many such commands which provide a large amount of control to the programmer to interact with the database in an efficient way without wasting many resources. The popularity of SQL has grown so much that almost every programmer relies on this to implement their application's storage functionalities thereby making it an exciting language to learn. Learning this provides the developer a benefit of understanding the data structures used for storing the organization's data and giving an additional level of control and in-depth understanding of the application.
PostgreSQL being an open-source database system having extremely robust and sophisticated ACID, Indexing, and Transaction supports has found widespread popularity among the developer community.
References and Resources:
- PostgreSQL Download
- PostgreSQL Tutorial
- SQL Server Interview Questions
- SQL Query Interview Questions and Answers
- SQL Interview Questions for Data Science
- MySQL Interview Questions
- DBMS Interview Questions
- PL SQL Interview Questions
- MongoDB Interview Questions
- Database Testing Interview Questions
- SQL Vs MySQL
- PostgreSQL vs MySQL
- Difference Between SQL and PLSQL
- Difference between RDBMS and DBMS
- SQL Vs NoSQL
- SQL Projects
- MySQL Commands
- OLTP vs OLAP
Coding Problems
An SQL query to delete a table from the database and memory while keeping the structure of the table intact?
What is a pre-requisite for creating a database in PostgreSQL?To create a database in PostgreSQL, you must have the special CREATEDB privilege or
Which of the following is known as a virtual table in SQL?
What is the main advantage of a clustered index over a non-clustered index?
SQL query used to fetch unique values from a field?
Which statement is used to update data in the database?
Which statement is false for the ORDER BY statement?
What statement is used for adding data to PostgreSQL?
Normalization which has neither composite values nor partial dependencies?
What does SQL stand for?
Which statement is true for a PRIMARY KEY constraint?
What is the order of results shown by default if the ASC or DESC parameter is not specified with the ORDER BY command?
What allows us to define how various tables are related to each other formally in a database?
What is the name of the component that requests data to the PostgreSQL server?
What languages are supported by PostgreSQL?
What command is used for restoring the backup of PostgreSQL which was created using pg_dump?
Query to select all records with "bar" in their name?
Which command is used to tell PostgreSQL to make all changes made to the database permanent?
Which statement is false for a FOREIGN KEY constraint?
What is a Query?
- Privacy Policy

- Practice Questions
- Programming
- System Design
- Fast Track Courses
- Online Interviewbit Compilers
- Online C Compiler
- Online C++ Compiler
- Online Java Compiler
- Online Javascript Compiler
- Online Python Compiler
- Interview Preparation
- Java Interview Questions
- Sql Interview Questions
- Python Interview Questions
- Javascript Interview Questions
- Angular Interview Questions
- Networking Interview Questions
- Selenium Interview Questions
- Data Structure Interview Questions
- Data Science Interview Questions
- System Design Interview Questions
- Hr Interview Questions
- Html Interview Questions
- C Interview Questions
- Amazon Interview Questions
- Facebook Interview Questions
- Google Interview Questions
- Tcs Interview Questions
- Accenture Interview Questions
- Infosys Interview Questions
- Capgemini Interview Questions
- Wipro Interview Questions
- Cognizant Interview Questions
- Deloitte Interview Questions
- Zoho Interview Questions
- Hcl Interview Questions
- Highest Paying Jobs In India
- Exciting C Projects Ideas With Source Code
- Top Java 8 Features
- Angular Vs React
- 10 Best Data Structures And Algorithms Books
- Best Full Stack Developer Courses
- Best Data Science Courses
- Python Commands List
- Data Scientist Salary
- Maximum Subarray Sum Kadane’s Algorithm
- Python Cheat Sheet
- C++ Cheat Sheet
- Javascript Cheat Sheet
- Git Cheat Sheet
- Java Cheat Sheet
- Data Structure Mcq
- C Programming Mcq
- Javascript Mcq
1 Million +
IMAGES
VIDEO
COMMENTS
Are you gearing up for a SQL interview? This article is packed with over 100 SQL interview questions and practical exercises, organized by topic, to help you prepare thoroughly and approach your interview with confidence.
Prepare for SQL interview questions for business analyst roles with our comprehensive guide. Master essential SQL queries and concepts to excel in your interview.
This comprehensive guide provides a curated list of SQL Server interview questions and answers, covering topics from basic concepts to advanced techniques, to help you prepare for your next data-related interview.
Learn from these 15 examples how SQL job interviewers will try to trick even an experienced SQL user into giving a wrong answer.
Tomi Mester. May 31, 2022. I’ve been part of many job interviews – on both sides of the table. The most fun, but also the most feared, part of the process is the technical screening. In this article, I’ll show you three SQL test exercises that, in my experience, are quite typical in data analyst job interviews — as of 2022.
Prepare for your SQL query interviews with confidence! Explore the top 30+ SQL query interview questions and expert answers for 2024. Enhance your skills and ace your SQL interviews effortlessly.
Prepare for the SQL portion of your interview with example questions and a framework for answering them. Being able to use SQL, or Structured Query Language, ranks among the most important skills for data analysts to have.
Interview Questions. 1. What does UNION do? What is the difference between UNION and UNION ALL? View answer. 2. List and explain the different types of JOIN clauses supported in ANSI-standard SQL. View answer. 3. Given the following tables: sql> SELECT * FROM runners; +----+--------------+. | id | name |. +----+--------------+.
Intro to ChatGPT. Learn SQL. Behavioral SQL job interview questions. During the interview process, you’ll likely have two different interviews — a technical interview and a behavioral interview. For the behavioral interview, sometimes called “situational,” you’ll be asked questions that evaluate your soft skills, not your technical ones.
Prepare for an SQL interview in 2023 with these most asked real-world SQL interview questions. Save time in Interview preparation. Get HIRED!